Extreme Region Policy Distillation
Pith reviewed 2026-06-29 23:12 UTC · model grok-4.3
The pith
Extreme Region Policy Distillation extracts training signals via aggressive off-policy updates then distills them back under trust-region constraints to achieve comparable performance with less KL divergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
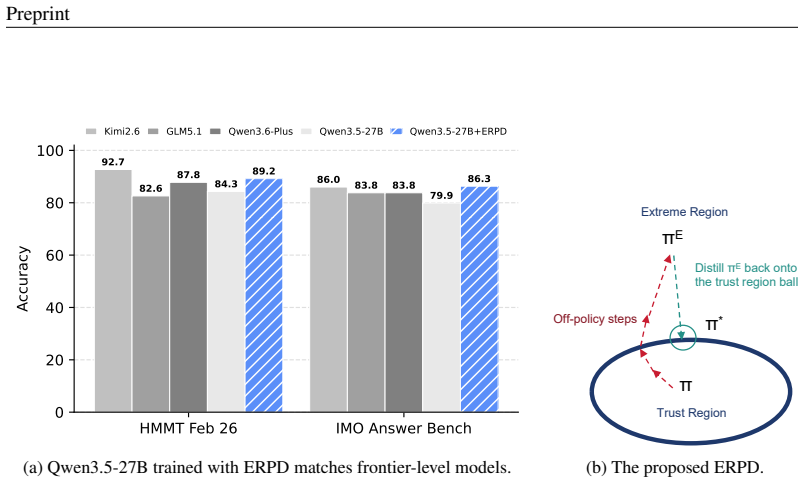
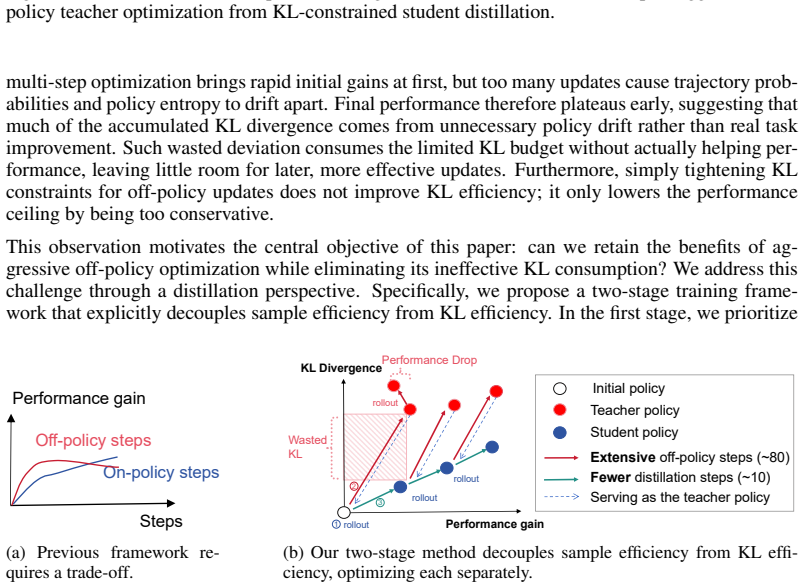
ERPD is a two-stage framework that decouples sample efficiency from KL efficiency: the first stage performs weakly constrained off-policy optimization on fixed data to maximally extract training signals, and the second stage distills the resulting token-level supervision into the base policy under trust-region constraints, yielding comparable or better performance with substantially smaller KL divergence.
What carries the argument
Extreme Region Policy Distillation (ERPD), a two-stage process that uses an aggressively optimized first-stage policy to supply token-level supervision for constrained distillation back into the base model.
If this is right
- On-policy training can continue to improve on tasks such as mathematical reasoning after standard methods plateau by incorporating signals extracted from fixed data.
- The total KL budget required to reach a given performance level is reduced because unnecessary drift is filtered out during distillation.
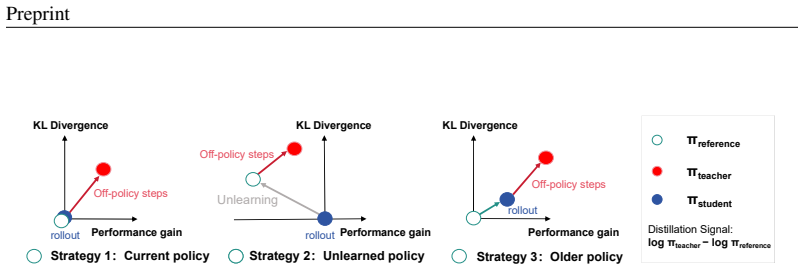
- Distillation remains effective even when the teacher policy from aggressive optimization is no stronger than the base policy, using alternative signal construction if needed.
Where Pith is reading between the lines
- Trust-region methods may be discarding recoverable gradient information that distillation can restore without violating the constraint.
- The separation of aggressive signal extraction from constrained update could be tested in non-language-model RL domains that face similar off-policy reuse limits.
- New divergence measures focused only on harmful changes could be developed once the paper shows that much observed KL movement is non-contributory.
Load-bearing premise
The token-level supervision produced by the first-stage policy remains useful and non-harmful when distilled into the base policy under trust-region constraints.
What would settle it
Apply the second-stage distillation and observe that the resulting policy underperforms a version that simply stops the first-stage optimization at its early performance peak without any distillation step.
Figures
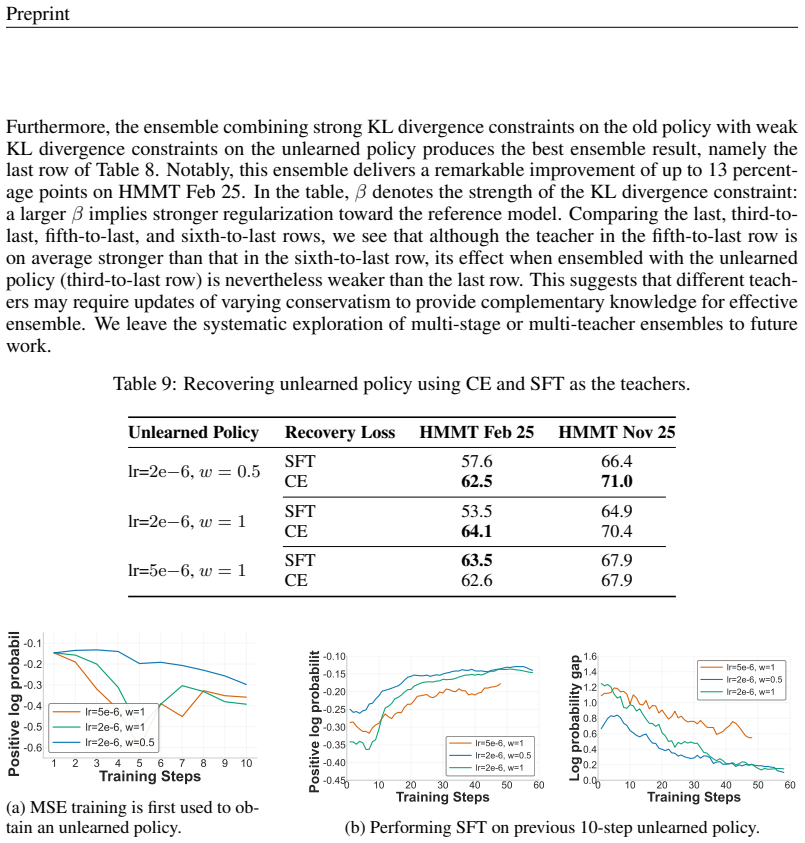
read the original abstract
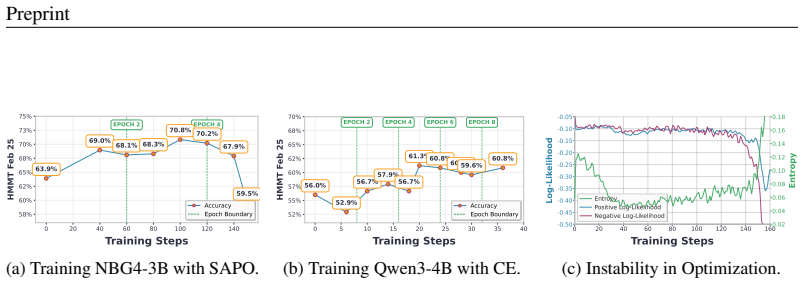
Reinforcement learning for large language models faces a fundamental trade-off between sample efficiency and asymptotic performance: strictly on-policy methods discard trajectories after a single update, while off-policy reuse introduces distribution mismatch that existing trust-region techniques mitigate primarily by enforcing conservative optimization, often leaving rich training signals underutilized. To investigate this, we perform extensive off-policy updates on fixed data. Our experiments reveal that aggressive multi-step optimization brings rapid initial gains, but excessive updates cause trajectory probabilities to deviate and entropy to collapse, with performance plateauing early. Tightening KL constraints merely lowers the ceiling without resolving the degradation. This motivates Extreme Region Policy Distillation (ERPD), a two-stage framework that decouples sample efficiency from KL efficiency. The first stage performs weakly constrained off-policy optimization on fixed data to maximally extract training signals. The resulting policy provides token-level supervision. In the second stage, we distill these signals into the base policy under trust-region constraints, filtering harmful drift while preserving useful signals. The distilled policy achieves comparable or better performance with substantially smaller KL divergence, indicating that much of the first-stage divergence was spent on unnecessary drift rather than genuine improvement. Crucially, ERPD accommodates both strong and weak teachers: when aggressive optimization yields no stronger policy, even degenerate teachers provide effective supervision via alternative signal construction strategies. We validate ERPD on mathematical reasoning, showing gains for strong base models where on-policy training plateaus, and reliable improvements with weak teachers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that aggressive off-policy updates on fixed data in RL for LLMs yield rapid initial gains followed by probability deviation, entropy collapse, and early plateauing, with tighter KL constraints only lowering performance ceilings. It proposes Extreme Region Policy Distillation (ERPD), a two-stage method: stage one uses weakly constrained off-policy optimization on fixed data to extract token-level supervision signals, while stage two distills these into the base policy under trust-region constraints. The distilled policy reportedly achieves comparable or better performance with substantially smaller KL divergence on mathematical reasoning tasks, even when using weak or degenerate teachers via alternative signal constructions.
Significance. If the empirical results hold, ERPD offers a practical decoupling of sample efficiency from KL efficiency in LLM RL, allowing fuller use of training signals without unnecessary drift or entropy collapse. This could improve methods like RLHF where on-policy training plateaus, and the accommodation of weak teachers is a notable strength for robustness.
major comments (2)
- [Abstract] Abstract: the central claim that the distilled policy achieves 'comparable or better performance with substantially smaller KL divergence' is load-bearing but unsupported by any quantitative metrics, baseline comparisons, statistical tests, or experiment details in the provided text; this leaves the evidence for 'unnecessary drift' unverified.
- [Abstract] Abstract: the description of token-level supervision and 'alternative signal construction strategies' for weak teachers is central to the framework but lacks any equations, pseudocode, or concrete construction details, making it impossible to assess whether the signals are non-harmful as assumed.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments on the abstract below. Both concerns can be addressed by targeted revisions that reference the quantitative results and methodological details already present in the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the distilled policy achieves 'comparable or better performance with substantially smaller KL divergence' is load-bearing but unsupported by any quantitative metrics, baseline comparisons, statistical tests, or experiment details in the provided text; this leaves the evidence for 'unnecessary drift' unverified.
Authors: The abstract provides a high-level summary of the central claim. The full manuscript contains the supporting evidence in the experimental evaluation on mathematical reasoning tasks, including direct performance comparisons against on-policy and off-policy baselines, measured KL divergence values, and ablation studies demonstrating that the distilled policy achieves comparable or superior task performance at substantially lower KL. We will revise the abstract to incorporate one or two concrete quantitative examples (e.g., average reward and KL values) along with a pointer to the relevant tables and figures. revision: partial
-
Referee: [Abstract] Abstract: the description of token-level supervision and 'alternative signal construction strategies' for weak teachers is central to the framework but lacks any equations, pseudocode, or concrete construction details, making it impossible to assess whether the signals are non-harmful as assumed.
Authors: The token-level supervision mechanism and the alternative signal construction strategies (including those that remain effective with degenerate teachers) are formally defined with equations and filtering criteria in Section 3, accompanied by pseudocode in Algorithm 1. These constructions explicitly incorporate reward-based selection and entropy regularization to avoid harmful drift. We will expand the abstract with a single additional sentence that briefly characterizes the signal extraction process and references the methods section for full details. revision: yes
Circularity Check
No significant circularity; empirical procedure is self-contained
full rationale
The paper presents ERPD as a two-stage empirical algorithm motivated by observed training dynamics (rapid gains followed by degradation under aggressive off-policy updates). The central claim—that first-stage divergence largely reflects unnecessary drift—follows directly from the reported experimental outcome of comparable or better performance at lower KL divergence after distillation. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the derivation chain; the method is an algorithmic proposal validated on mathematical reasoning tasks rather than a mathematical reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Aggressive multi-step optimization on fixed data extracts training signals that can be usefully distilled even when the intermediate policy exhibits high divergence and entropy collapse.
Reference graph
Works this paper leans on
-
[1]
github.io/blog/2025/Polaris
URLhttps://hkunlp. github.io/blog/2025/Polaris. 19 Preprint Mislav Balunovi´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´c, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions.Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmark,
2025
-
[2]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Soft Adaptive Policy Optimization
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization.arXiv preprint arXiv:2511.20347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025a. Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
URLhttps: //arxiv.org/abs/2511.01846. Youssef Mroueh. Reinforcement learning with verifiable rewards: Grpo’s effective loss, dynamics, and success amplification.arXiv preprint arXiv:2503.06639,
-
[6]
Fromrtoq∗: Your language model is secretly a q-function.arXiv preprint arXiv:2404.12358,
20 Preprint Rafael Rafailov, Joey Hejna, Ryan Park, and Chelsea Finn. Fromrtoq∗: Your language model is secretly a q-function.arXiv preprint arXiv:2404.12358,
-
[7]
Nicolas Le Roux, Marc G Bellemare, Jonathan Lebensold, Arnaud Bergeron, Joshua Greaves, Alex Fr ´echette, Carolyne Pelletier, Eric Thibodeau-Laufer, S ´andor Toth, and Sam Work. Ta- pered off-policy reinforce: Stable and efficient reinforcement learning for llms.arXiv preprint arXiv:2503.14286,
-
[8]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training
URLhttps://arxiv. org/abs/2602.10693. ModelScope Team. EvalScope: Evaluation framework for large models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URLhttps: //github.com/modelscope/evalscope. Zhiheng Xi, Xin Guo, Yang Nan, Enyu Zhou, Junrui Shen, Wenxiang Chen, Jiaqi Liu, Jixuan Huang, Zhihao Zhang, Honglin Guo, et al. Bapo: Stabilizing off-policy reinforcement learning for llms via balanced policy optimization with adaptive clipping.arXiv preprint arXiv:2510.18927,
-
[12]
Chen Yang, Guangyue Peng, Jiaying Zhu, Ran Le, Ruixiang Feng, Tao Zhang, Wei Ruan, Xiaoqi Liu, Xiaoxue Cheng, Xiyun Xu, et al. Nanbeige4-3b technical report: Exploring the frontier of small language models.arXiv preprint arXiv:2512.06266,
-
[13]
Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free process rewards without process labels.Proceedings of Machine Learn- ing Research, 267:73511–73525, 2025a. Yufeng Yuan, Yu Yue, Ruofei Zhu, Tiantian Fan, and Lin Yan. What’s behind ppo’s collapse in long-cot? value optimization holds the secre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.