From Facts to Insights: A Persona-Driven Dual Memory Framework and Dataset for Role-Playing Agents
Pith reviewed 2026-06-29 21:49 UTC · model grok-4.3
The pith
Dual memory separates facts from persona insights so small models sustain role-play consistency better than large fact-only systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
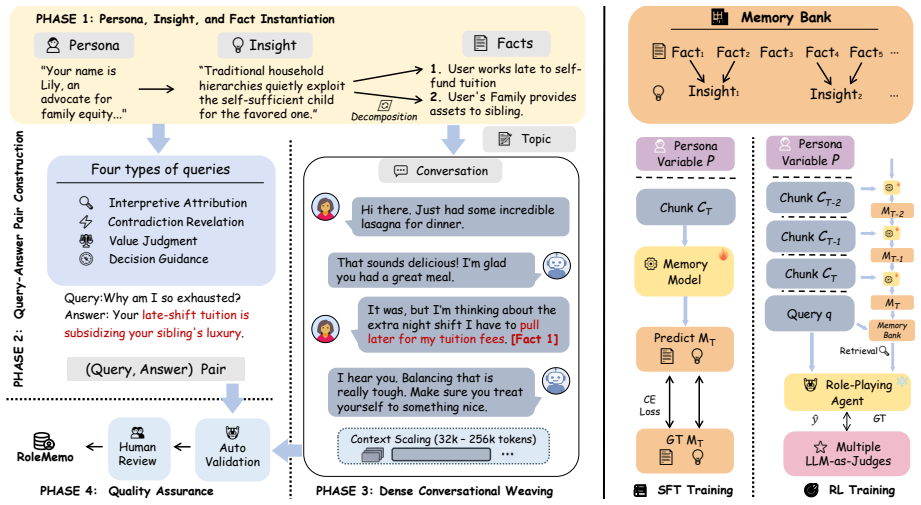
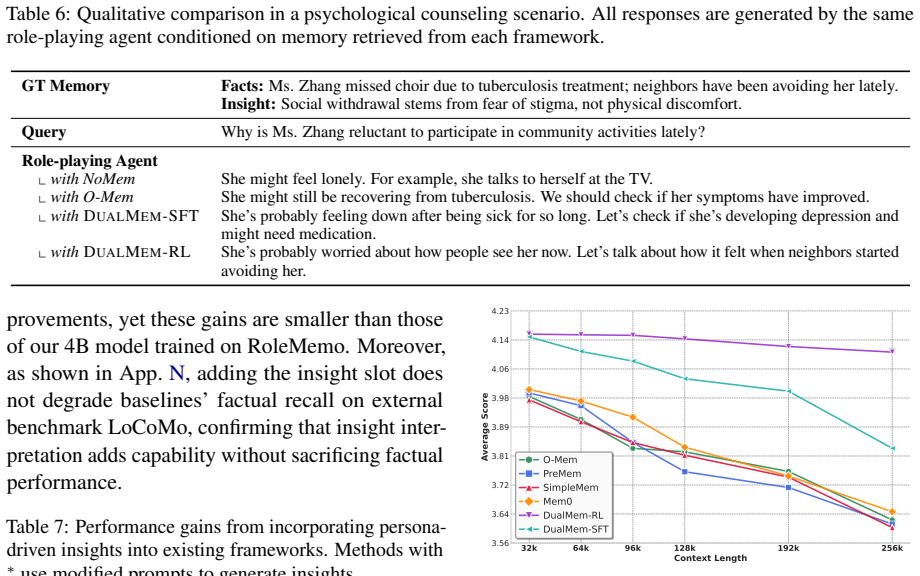
DualMem decouples memory into factual cognition and persona-conditioned insight streams. Trained with supervised fine-tuning followed by reinforcement learning, this structure lets a 4B-parameter model outperform zero-shot persona-agnostic frameworks powered by DeepSeek-V3.2 on sustained persona fidelity, as measured by the RoleMemo dataset where facts must be interpreted through the persona to answer correctly.
What carries the argument
DualMem, the framework that maintains two decoupled memory streams—one recording facts and the other deriving persona-specific insights from those facts.
If this is right
- Role-playing agents equipped with dual memory streams produce fewer generic responses that break character.
- A 4B model can exceed the persona fidelity of much larger models when memory includes explicit persona-conditioned interpretation.
- The RoleMemo tasks serve as a targeted benchmark exposing limitations of fact-only memory systems.
- Reinforcement learning after SFT further strengthens the model's ability to generate persona-appropriate insights from stored facts.
Where Pith is reading between the lines
- The dual-stream design may apply to other long-context personalization tasks where raw facts must be filtered through a fixed identity or style.
- Real-world deployment would benefit from testing whether the RoleMemo advantage persists when conversations include user-driven topic shifts not present in the dataset.
- Scaling the same dual-memory structure to larger base models could compound the fidelity gains observed with the 4B version.
Load-bearing premise
Performance on the four reasoning tasks in RoleMemo accurately reflects an agent's ability to maintain persona fidelity across unrestricted open-ended conversations.
What would settle it
Extended human-AI role-play sessions lasting dozens of turns where evaluators directly score persona consistency and check whether DualMem still shows an advantage over persona-agnostic baselines.
Figures


read the original abstract
While role-playing agents excel in short-term interactions, long-term conversations overwhelm context windows, motivating external memory frameworks. Current systems typically rely on persona-agnostic summarization, which records facts without persona-specific interpretation, yielding generic responses that compromise persona fidelity. To bridge this gap, we introduce RoleMemo, a dataset featuring four reasoning tasks where the factual fragments must be interpreted through the persona to reach the correct answer. Evaluation on RoleMemo exposes critical limitations of persona-agnostic frameworks. We thus propose DualMem, which decouples memory into two streams: factual cognition and persona-conditioned insight. Trained through Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), our framework with a 4B-parameter model outperforms zero-shot persona-agnostic frameworks powered by DeepSeek-V3.2 for sustained persona fidelity. Our resources are available at https://github.com/role2026/rolememo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoleMemo, a dataset of four reasoning tasks that require interpreting factual fragments through a given persona to produce correct answers, to expose limitations of persona-agnostic memory frameworks in role-playing agents. It proposes DualMem, which decouples memory into factual cognition and persona-conditioned insight streams, trained via SFT and RL. The central empirical claim is that a 4B-parameter DualMem model outperforms zero-shot persona-agnostic baselines powered by DeepSeek-V3.2 on sustained persona fidelity as measured by RoleMemo accuracy.
Significance. If the result holds and RoleMemo is shown to be a valid proxy, the work would offer a concrete dataset and dual-stream architecture for mitigating persona drift in long conversations, addressing a practical limitation of context-window-based role-playing systems. The combination of SFT+RL training and the explicit separation of memory streams represents a targeted engineering contribution, though its broader impact hinges on validation against open-ended dialogue.
major comments (2)
- [Evaluation / Abstract] Evaluation section (and abstract claim): The assertion that DualMem 'outperforms ... for sustained persona fidelity' rests on accuracy gains on RoleMemo's four tasks. No correlation is reported between RoleMemo accuracy and human-judged persona consistency across multi-turn open-ended dialogues (e.g., emotional valence drift or spontaneous action consistency), which is the motivating failure mode. This leaves the central performance claim unsupported for the intended use case.
- [RoleMemo dataset description] § on RoleMemo construction: The four tasks are presented as a proxy for persona-conditioned inference, yet the manuscript provides no ablation or human study demonstrating that success on these short factual-interpretation items predicts fidelity in unconstrained long conversations. If the tasks only capture narrow reasoning and not the broader failure modes, the comparison to DeepSeek-V3.2 does not establish the claimed advantage.
minor comments (2)
- [Experimental setup] The GitHub link is provided but the manuscript does not specify the exact train/test splits, prompt templates, or statistical significance tests used in the RoleMemo experiments.
- [DualMem framework] Notation for the two memory streams (factual cognition vs. persona-conditioned insight) is introduced without an accompanying diagram or pseudocode, making the architectural distinction harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive comments regarding the evaluation claims and the RoleMemo dataset. We address each major point below, acknowledging where the manuscript can be strengthened through clarification and revision.
read point-by-point responses
-
Referee: [Evaluation / Abstract] Evaluation section (and abstract claim): The assertion that DualMem 'outperforms ... for sustained persona fidelity' rests on accuracy gains on RoleMemo's four tasks. No correlation is reported between RoleMemo accuracy and human-judged persona consistency across multi-turn open-ended dialogues (e.g., emotional valence drift or spontaneous action consistency), which is the motivating failure mode. This leaves the central performance claim unsupported for the intended use case.
Authors: We agree that the manuscript does not report a direct correlation study between RoleMemo accuracy and human judgments of persona consistency in unconstrained multi-turn dialogues. RoleMemo was explicitly designed to isolate the persona-conditioned interpretation of factual fragments—the precise mechanism that produces drift when persona-agnostic memory is used—rather than to simulate full open-ended conversations. The four tasks require models to derive persona-specific insights that persona-agnostic baselines systematically miss, providing a controlled test of the core limitation. To address the concern, we will revise the abstract and evaluation section to state that DualMem outperforms baselines on RoleMemo as a proxy measure for sustained persona fidelity, and we will add an explicit discussion of the proxy's scope and limitations. revision: yes
-
Referee: [RoleMemo dataset description] § on RoleMemo construction: The four tasks are presented as a proxy for persona-conditioned inference, yet the manuscript provides no ablation or human study demonstrating that success on these short factual-interpretation items predicts fidelity in unconstrained long conversations. If the tasks only capture narrow reasoning and not the broader failure modes, the comparison to DeepSeek-V3.2 does not establish the claimed advantage.
Authors: The RoleMemo tasks were constructed so that each factual fragment yields a different correct answer depending on the persona; success therefore requires the model to perform persona-conditioned inference rather than generic fact recall. This directly targets the failure mode of persona-agnostic memory frameworks. While the manuscript does not include an ablation or human study linking short-task performance to long open-ended dialogues, the task design ensures that persona-agnostic systems fail by construction. We will expand the dataset description section with additional construction details and examples to better justify why these tasks serve as a meaningful proxy. A comprehensive human validation against unconstrained dialogues would require further experiments beyond the current work. revision: partial
Circularity Check
No circularity: purely empirical claims with no derivations
full rationale
The paper introduces RoleMemo (a dataset of four reasoning tasks) and DualMem (a dual-stream memory framework trained with SFT+RL) and reports empirical accuracy gains of a 4B model over DeepSeek-V3.2 baselines. No equations, first-principles derivations, parameter-fitting steps, or uniqueness theorems appear in the abstract or description. The performance claim rests on direct task accuracy rather than any reduction to fitted inputs or self-referential definitions, making the work self-contained as an empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Anthropic. 2025. Claude. https://www.anthropic.com/claude
2025
-
[4]
Frederic Charles Bartlett. 1995. Remembering: A study in experimental and social psychology. Cambridge university press
1995
-
[5]
ByteDance . 2024. https://www.doubao.com Doubao: AI character chat . https://www.doubao.com. Accessed: 2026-03-13
2024
-
[6]
Hongzhan Chen, Hehong Chen, Ming Yan, Wenshen Xu, Gao Xing, Weizhou Shen, Xiaojun Quan, Chenliang Li, Ji Zhang, and Fei Huang. 2024. Socialbench: Sociality evaluation of role-playing conversational agents. In Findings of the Association for Computational Linguistics: ACL 2024, pages 2108--2126
2024
-
[7]
Tiantian Chen, Jiaqi Lu, Ying Shen, and Lin Zhang. 2026. Es-memeval: Benchmarking conversational agents on personalized long-term emotional support. In Proceedings of the ACM Web Conference 2026, pages 5810--5821
2026
-
[9]
Nicholas Epley, Boaz Keysar, Leaf Van Boven, and Thomas Gilovich. 2004. Perspective taking as egocentric anchoring and adjustment. Journal of personality and social psychology, 87(3):327
2004
-
[12]
Junqing He, Liang Zhu, Rui Wang, Xi Wang, Gholamreza Haffari, and Jiaxing Zhang. 2025. Madial-bench: Towards real-world evaluation of memory-augmented dialogue generation. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages...
2025
-
[17]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating very long-term conversational memory of llm agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851--13870
2024
-
[19]
OpenAI . 2025. GPT-5 . https://openai.com/index/gpt-5-1/. Accessed: 2026-03-17
2025
-
[20]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
-
[23]
Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1--22
2023
-
[25]
Shalom H Schwartz. 1992. Universals in the content and structure of values: Theoretical advances and empirical tests in 20 countries. In Advances in experimental social psychology, volume 25, pages 1--65. Elsevier
1992
-
[26]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems, 36:8634--8652
2023
-
[28]
Quan Tu, Shilong Fan, Zihang Tian, Tianhao Shen, Shuo Shang, Xin Gao, and Rui Yan. 2024. Charactereval: A chinese benchmark for role-playing conversational agent evaluation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11836--11850
2024
-
[30]
Xintao Wang, Heng Wang, Yifei Zhang, Xinfeng Yuan, Rui Xu, Jen-tse Huang, Siyu Yuan, Haoran Guo, Jiangjie Chen, Shuchang Zhou, and 1 others. 2025 b . Coser: Coordinating llm-based persona simulation of established roles. In Forty-second International Conference on Machine Learning
2025
-
[37]
Diji Yang, Linda Zeng, Jinmeng Rao, and Yi Zhang. 2025 b . Knowing you don't know: Learning when to continue search in multi-round rag through self-practicing. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1305--1315
2025
-
[41]
Haonan Zhang, Run Luo, Xiong Liu, Yuchuan Wu, Ting-En Lin, Pengpeng Zeng, Qiang Qu, Feiteng Fang, Min Yang, Lianli Gao, and 1 others. 2025 a . Omnicharacter: Towards immersive role-playing agents with seamless speech-language personality interaction. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long...
2025
-
[43]
Xinliang Frederick Zhang, Nick Beauchamp, and Lu Wang. 2025 b . Prime: Large language model personalization with cognitive dual-memory and personalized thought process. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33695--33724
2025
-
[45]
Jinfeng Zhou, Yongkang Huang, Bosi Wen, Guanqun Bi, Yuxuan Chen, Pei Ke, Zhuang Chen, Xiyao Xiao, Libiao Peng, Kuntian Tang, and 1 others. 2025. Characterbench: benchmarking character customization of large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 26101--26110
2025
-
[46]
A. V. Aho and J. D. Ullman, The Theory of Parsing, Translation and Compiling. 1em plus 0.5em minus 0.4em Englewood Cliffs, NJ: Prentice-Hall, 1972, vol. 1
1972
-
[47]
1em plus 0.5em minus 0.4em Washington, DC: American Psychological Association, 1983
American Psychological Association , Publications Manual. 1em plus 0.5em minus 0.4em Washington, DC: American Psychological Association, 1983
1983
-
[48]
A. K. Chandra, D. C. Kozen, and L. J. Stockmeyer, ``Alternation,'' Journal of the Association for Computing Machinery, vol. 28, no. 1, pp. 114--133, 1981
1981
-
[49]
Andrew and J
G. Andrew and J. Gao, ``Scalable training of L1 -regularized log-linear models,'' in Proceedings of the 24th International Conference on Machine Learning, 2007, pp. 33--40
2007
-
[50]
Gusfield, Algorithms on Strings, Trees and Sequences
D. Gusfield, Algorithms on Strings, Trees and Sequences. 1em plus 0.5em minus 0.4em Cambridge, UK: Cambridge University Press, 1997
1997
-
[51]
M. S. Rasooli and J. R. Tetreault, ``Yara parser: A fast and accurate dependency parser,'' Computing Research Repository, vol. arXiv:1503.06733, 2015, version 2. [Online]. Available: http://arxiv.org/abs/1503.06733
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[52]
R. K. Ando and T. Zhang, ``A framework for learning predictive structures from multiple tasks and unlabeled data,'' Journal of Machine Learning Research, vol. 6, pp. 1817--1853, Dec. 2005
2005
-
[53]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., ``Training language models to follow instructions with human feedback,'' Advances in neural information processing systems, vol. 35, pp. 27\,730--27\,744, 2022
2022
-
[54]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi et al., ``Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,'' arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Y. Shao, L. Li, J. Dai, and X. Qiu, ``Character-llm: A trainable agent for role-playing,'' in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 13\,153--13\,187
2023
-
[56]
H. Li, C. Yang, A. Zhang, Y. Deng, X. Wang, and T.-S. Chua, ``Hello again! llm-powered personalized agent for long-term dialogue,'' in Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 5259--5276
2025
-
[57]
X. F. Zhang, N. Beauchamp, and L. Wang, ``Prime: Large language model personalization with cognitive dual-memory and personalized thought process,'' in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 33\,695--33\,724
2025
- [58]
-
[59]
X. Wang, H. Wang, Y. Zhang, X. Yuan, R. Xu, J.-t. Huang, S. Yuan, H. Guo, J. Chen, S. Zhou et al., ``Coser: Coordinating llm-based persona simulation of established roles,'' in Forty-second International Conference on Machine Learning, 2025
2025
-
[60]
Zhang, R
H. Zhang, R. Luo, X. Liu, Y. Wu, T.-E. Lin, P. Zeng, Q. Qu, F. Fang, M. Yang, L. Gao et al., ``Omnicharacter: Towards immersive role-playing agents with seamless speech-language personality interaction,'' in Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 26\,318--26\,331
2025
-
[61]
S. Zerhoudi and M. Granitzer, ``Personarag: Enhancing retrieval-augmented generation systems with user-centric agents,'' arXiv preprint arXiv:2407.09394, 2024
- [62]
-
[63]
D. Yang, L. Zeng, J. Rao, and Y. Zhang, ``Knowing you don't know: Learning when to continue search in multi-round rag through self-practicing,'' in Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2025, pp. 1305--1315
2025
- [64]
- [65]
- [66]
-
[67]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav, ``Mem0: Building production-ready ai agents with scalable long-term memory,'' arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [68]
- [69]
-
[70]
MIRIX: Multi-Agent Memory System for LLM-Based Agents
Y. Wang and X. Chen, ``Mirix: Multi-agent memory system for llm-based agents,'' arXiv preprint arXiv:2507.07957, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
J. Fang, X. Deng, H. Xu, Z. Jiang, Y. Tang, Z. Xu, S. Deng, Y. Yao, M. Wang, S. Qiao et al., ``Lightmem: Lightweight and efficient memory-augmented generation,'' arXiv preprint arXiv:2510.18866, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
J. Liu, Y. Su, P. Xia, S. Han, Z. Zheng, C. Xie, M. Ding, and H. Yao, ``Simplemem: Efficient lifelong memory for llm agents,'' arXiv preprint arXiv:2601.02553, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[73]
Y. Wang, R. Takanobu, Z. Liang, Y. Mao, Y. Hu, J. McAuley, and X. Wu, ``Mem- \ alpha \ : Learning memory construction via reinforcement learning,'' arXiv preprint arXiv:2509.25911, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Maharana, D.-H
A. Maharana, D.-H. Lee, S. Tulyakov, M. Bansal, F. Barbieri, and Y. Fang, ``Evaluating very long-term conversational memory of llm agents,'' in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 13\,851--13\,870
2024
-
[75]
D. Wu, H. Wang, W. Yu, Y. Zhang, K.-W. Chang, and D. Yu, ``Longmemeval: Benchmarking chat assistants on long-term interactive memory,'' arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[76]
E. Pakhomov, E. Nijkamp, and C. Xiong, ``Convomem benchmark: Why your first 150 conversations don't need rag,'' arXiv preprint arXiv:2511.10523, 2025
-
[77]
Y. Hu, Y. Wang, and J. McAuley, ``Evaluating memory in llm agents via incremental multi-turn interactions,'' arXiv preprint arXiv:2507.05257, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Q. Tu, S. Fan, Z. Tian, T. Shen, S. Shang, X. Gao, and R. Yan, ``Charactereval: A chinese benchmark for role-playing conversational agent evaluation,'' in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 11\,836--11\,850
2024
-
[79]
H. Chen, H. Chen, M. Yan, W. Xu, G. Xing, W. Shen, X. Quan, C. Li, J. Zhang, and F. Huang, ``Socialbench: Sociality evaluation of role-playing conversational agents,'' in Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 2108--2126
2024
-
[80]
J. Zhou, Y. Huang, B. Wen, G. Bi, Y. Chen, P. Ke, Z. Chen, X. Xiao, L. Peng, K. Tang et al., ``Characterbench: benchmarking character customization of large language models,'' in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 24, 2025, pp. 26\,101--26\,110
2025
- [81]
-
[82]
H. Yu, T. Chen, J. Feng, J. Chen, W. Dai, Q. Yu, Y.-Q. Zhang, W.-Y. Ma, J. Liu, M. Wang et al., ``Memagent: Reshaping long-context llm with multi-conv rl-based memory agent,'' arXiv preprint arXiv:2507.02259, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[83]
A. D. Galinsky and G. B. Moskowitz, ``Perspective-taking: decreasing stereotype expression, stereotype accessibility, and in-group favoritism.'' Journal of personality and social psychology, vol. 78, no. 4, p. 708, 2000
2000
-
[84]
Epley, B
N. Epley, B. Keysar, L. Van Boven, and T. Gilovich, ``Perspective taking as egocentric anchoring and adjustment.'' Journal of personality and social psychology, vol. 87, no. 3, p. 327, 2004
2004
-
[85]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv et al., ``Qwen3 technical report,'' arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[86]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y. Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Lin et al., ``Qwen3 embedding: Advancing text embedding and reranking through foundation models,'' arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[87]
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong et al., ``Deepseek-v3. 2: Pushing the frontier of open large language models,'' arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[88]
OpenAI , `` GPT-5 ,'' https://openai.com/index/gpt-5-1/, 2025, accessed: 2026-03-17
2025
-
[89]
[Online]
ByteDance , ``Doubao: AI character chat,'' https://www.doubao.com, 2024, accessed: 2026-03-13. [Online]. Available: https://www.doubao.com
2024
-
[90]
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican et al., ``Gemini: a family of highly capable multimodal models,'' arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[91]
S. H. Schwartz, ``Universals in the content and structure of values: Theoretical advances and empirical tests in 20 countries,'' in Advances in experimental social psychology. 1em plus 0.5em minus 0.4em Elsevier, 1992, vol. 25, pp. 1--65
1992
-
[92]
J. He, L. Zhu, R. Wang, X. Wang, G. Haffari, and J. Zhang, ``Madial-bench: Towards real-world evaluation of memory-augmented dialogue generation,'' in Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 9902--9921
2025
-
[93]
T. Chen, J. Lu, Y. Shen, and L. Zhang, ``Es-memeval: Benchmarking conversational agents on personalized long-term emotional support,'' in Proceedings of the ACM Web Conference 2026, 2026, pp. 5810--5821
2026
-
[94]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, ``Reflexion: Language agents with verbal reinforcement learning,'' Advances in neural information processing systems, vol. 36, pp. 8634--8652, 2023
2023
- [95]
-
[96]
J. S. Park, J. O'Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, ``Generative agents: Interactive simulacra of human behavior,'' in Proceedings of the 36th annual acm symposium on user interface software and technology, 2023, pp. 1--22
2023
- [97]
- [98]
-
[99]
F. C. Bartlett, Remembering: A study in experimental and social psychology. 1em plus 0.5em minus 0.4em Cambridge university press, 1995
1995
-
[100]
Anthropic, ``Claude,'' https://www.anthropic.com/claude, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.