Towards Open-World Referring Expression Comprehension: A Benchmark with Training-free Multi-task Consistency Checker
Pith reviewed 2026-06-29 23:12 UTC · model grok-4.3
The pith
The OpenRef benchmark and training-free Multi-task Consistency Checker advance referring expression comprehension to complex open-world settings with multiple or absent targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
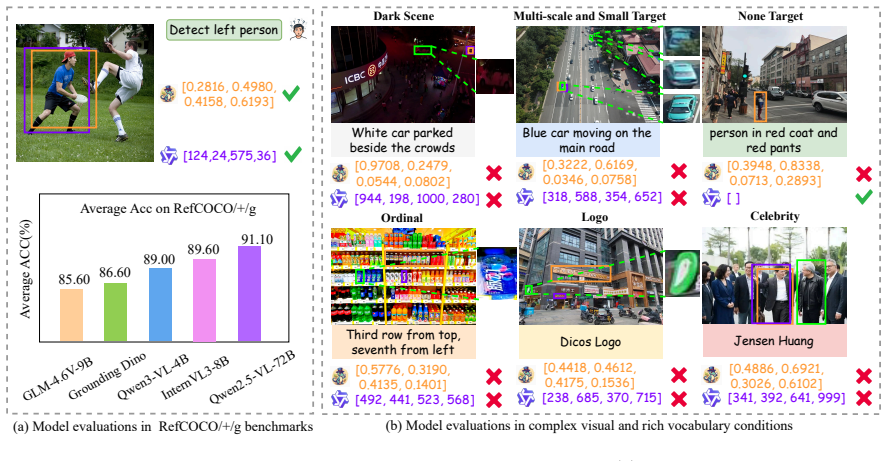
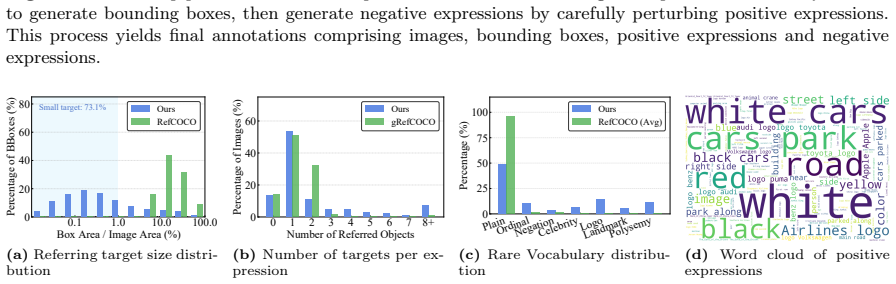
OpenRef supplies the first benchmark explicitly built for open-world REC by combining diverse visual domains, variable target counts, and linguistically rich expressions, while the Multi-task Consistency Checker supplies a training-free mechanism that raises the grounding performance of existing models on these harder cases.
What carries the argument
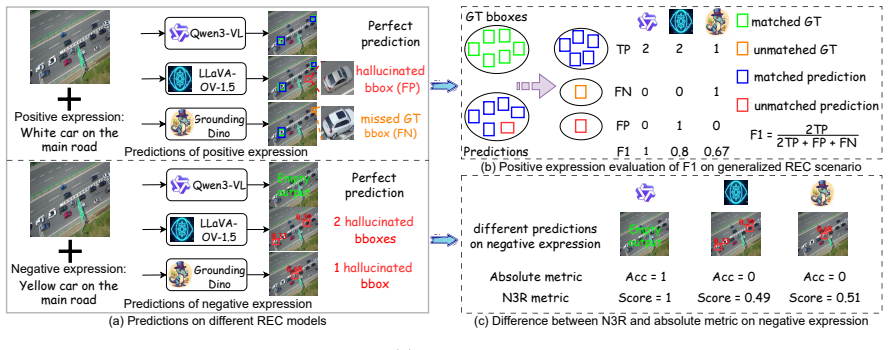
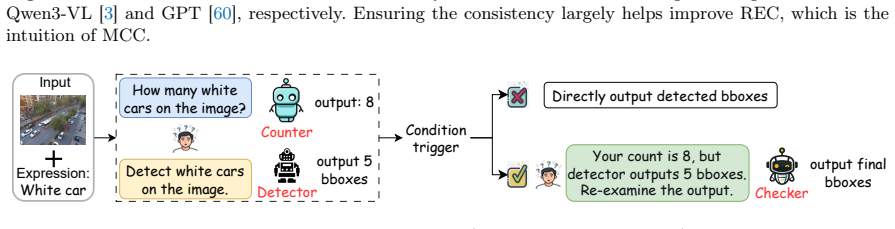
The Multi-task Consistency Checker (MCC), a training-free plug-and-play module that performs consistency self-verification across tasks to improve grounding decisions.
If this is right
- Existing REC models achieve higher F1 scores on multi-target and none-target samples once MCC is applied.
- N3R provides a measurable way to compare how reliably different models reject expressions that match no object.
- Models tested on OpenRef must now handle proper nouns, polysemous words, and ordinal expressions in addition to standard language.
- Performance gains appear across ground views, drone views, dark scenes, and adverse weather without any model retraining.
Where Pith is reading between the lines
- The consistency-checking idea could be tested on other vision-language grounding tasks that also face ambiguous references.
- OpenRef could serve as a stress test for whether large vision-language models already possess implicit rejection ability before any checker is added.
- Developers might combine MCC with lightweight fine-tuning to see whether the two approaches compound.
- The emphasis on negative expressions suggests that future REC work should treat refusal to ground as a first-class output rather than an afterthought.
Load-bearing premise
The benchmark's chosen visual domains, target-count variations, and vocabulary types together with the N3R metric are sufficient to represent genuine open-world requirements, and that MCC improves consistency without creating new failure modes.
What would settle it
Applying the MCC to an existing REC model on the OpenRef test set and finding no gain (or a drop) in F1 or N3R scores on multi-target or negative-expression subsets would falsify the performance claim.
Figures


read the original abstract
Referring expression comprehension (REC) aims to localize a target object within an image based on a given expression. Although recent advances in vision-language models have led to substantial improvements in REC tasks, current REC benchmarks often hold simple scenarios and the assumption that each expression maps to a unique object. These limitations hinder the deployment of REC models in open-world environments. To fill this gap, we introduce OpenRef, a new benchmark for REC in complex visual and linguistic scenarios. OpenRef features three key advancements: 1) Diverse visual scenarios: spanning diverse visual domains, including ground views, drone views, dark scenes and adverse weather conditions; 2) Variable target counts: breaking the single-target limitation with multi-target and none-target samples; 3) Rich vocabulary types: incorporating proper nouns, polysemous words and ordinal terms to fit a wider range of expression needs. Furthermore, as traditional metrics are insufficient for open-world setting, we leverage F1 to measure grounding accuracy and propose N3R (Negative Relative Rejection Reliability) to assess relative rejection reliability against negative expressions. Finally, we introduce Multi-task Consistency Checker (MCC), a training-free but plug-and-play strategy that enhances model performance with one click by enforcing consistency self-verification. Extensive experiments demonstrate that this work significantly advances the performance of existing REC models in complex scenarios, paving the way for open-world REC. Project page: https://zongjianwu.github.io/openref
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address limitations in existing REC benchmarks by introducing OpenRef, which features diverse visual scenarios across domains like ground and drone views, dark scenes, and adverse weather; variable target counts including multi-target and none-target cases; and rich vocabulary with proper nouns, polysemous words, and ordinal terms. It proposes F1 for measuring grounding accuracy and N3R for negative relative rejection reliability. The paper also introduces the training-free Multi-task Consistency Checker (MCC) as a plug-and-play strategy to enhance REC models by enforcing multi-task consistency self-verification. Extensive experiments are claimed to show that this approach significantly advances existing REC models in complex open-world scenarios.
Significance. The work has potential significance in moving REC towards more realistic open-world settings by providing a benchmark that breaks the single-target assumption and includes challenging conditions. The training-free MCC is a practical contribution if it demonstrates consistent improvements. The new N3R metric addresses a gap in evaluating rejection reliability. These elements, if supported by rigorous experiments, could influence future research in vision-language grounding.
major comments (2)
- [Experiments] The central claim of significant performance advances by MCC relies on the experiments; however, the manuscript must provide quantitative comparisons (e.g., F1 and N3R scores) for base models versus MCC-enhanced versions across all benchmark dimensions, including ablations on multi-target and none-target cases in adverse conditions.
- [MCC and N3R] §4 (method) and experiments: The assumption that the training-free MCC enforces meaningful consistency without introducing new failure modes in high-uncertainty regimes needs explicit testing. An analysis of cases where base model confidence is low (adverse weather + none-target + polysemous terms) is required to confirm the gains are not limited to easier subsets.
minor comments (2)
- [Abstract] The abstract would benefit from including at least one key quantitative result to support the claim of significant advances.
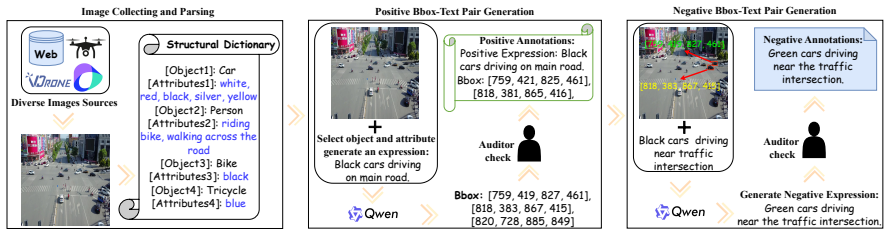
- [Benchmark description] Provide more details on how the OpenRef dataset was constructed, including the number of samples per category and annotation process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects for strengthening the experimental validation of MCC and the new metrics. We address each major comment below and commit to revisions that provide the requested quantitative breakdowns and analyses.
read point-by-point responses
-
Referee: [Experiments] The central claim of significant performance advances by MCC relies on the experiments; however, the manuscript must provide quantitative comparisons (e.g., F1 and N3R scores) for base models versus MCC-enhanced versions across all benchmark dimensions, including ablations on multi-target and none-target cases in adverse conditions.
Authors: We agree that the manuscript would benefit from more granular quantitative comparisons. The current experiments report aggregate results across the benchmark; we will revise Section 5 to include detailed tables with F1 and N3R scores comparing base models to MCC-enhanced versions, broken down by all benchmark dimensions. This will explicitly include ablations for multi-target and none-target cases under adverse weather and other challenging conditions. revision: yes
-
Referee: [MCC and N3R] §4 (method) and experiments: The assumption that the training-free MCC enforces meaningful consistency without introducing new failure modes in high-uncertainty regimes needs explicit testing. An analysis of cases where base model confidence is low (adverse weather + none-target + polysemous terms) is required to confirm the gains are not limited to easier subsets.
Authors: We recognize the value of targeted testing in high-uncertainty regimes. In the revision, we will add an explicit analysis (new subsection in experiments) of low-confidence cases, focusing on the intersection of adverse weather, none-target scenarios, and polysemous terms. This will report quantitative F1/N3R deltas, failure mode comparisons, and qualitative examples to verify that MCC does not introduce new errors and that gains are not confined to easier subsets. revision: yes
Circularity Check
No circularity: new benchmark, metric, and training-free checker are independent additions
full rationale
The paper introduces OpenRef as a new benchmark with explicitly enumerated features (diverse domains, multi/none-target cases, rich vocabulary), defines N3R as a new relative-rejection metric, and presents MCC as a plug-and-play consistency checker. No equations, fitted parameters, or derivations are described that reduce by construction to the inputs; claims rest on experimental results on the new benchmark rather than self-referential definitions or self-citation chains. This matches the default non-circular case for benchmark-plus-method papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Traditional metrics are insufficient for open-world REC with multi-target and none-target samples.
- ad hoc to paper Enforcing multi-task consistency self-verification via a training-free checker improves grounding accuracy and rejection reliability.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2005.01655 (2020)
Akula, A.R., Gella, S., Al-Onaizan, Y., Zhu, S.C., Reddy, S.: Words aren’t enough, their order matters: On the robustness of grounding visual referring expressions. arXiv preprint arXiv:2005.01655 (2020)
-
[2]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., Xie, Y., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y., Xu, S., Chen, C., Zhu, D., et al.: Llava-onevision-1.5: Fully open framework for democratized multimodal training. arXiv preprint arXiv:2509.23661 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X.H., Cheng, Z., Deng, L., Ding, W., Fang, R., Gao, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (2023)
Chen, J., Zhu, D., Shen, X., Li, X., Liu, Z., Peng, P., Fang, P., Yan, S., Ellis, H., Nazir, J., et al.: Minigpt- v2: large language model as a unified interface for vision-language multi-task learning. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (2023)
2023
-
[6]
Chen, Z., Wang, J., Cao, Z., Liu, B., Gao, J., et al.: Internvl2.5: Optimizing vision-language models with high-resolution and strong reasoning. arXiv preprint arXiv:2412.05271 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, Z., Wang, P., Ma, L., Wong, K.Y.K., Wu, Q.: Cops-ref: A new dataset and task on compositional referring expression comprehension. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10086–10095 (2020)
2020
-
[8]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Dai,M.,Li,J.,Zhuang,J.,Zhang,X.,Yang,W.:Multi-taskvisualgroundingwithcoarse-to-fineconsistency constraints. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2618–2626 (2025)
2025
-
[9]
In: Proceedings of the IEEE/CVF international conference on computer vision
Deng, J., Yang, Z., Chen, T., Zhou, W., Li, H.: Transvg: End-to-end visual grounding with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1769–1779 (2021)
2021
-
[10]
IEEE transactions on pattern analysis and machine intelligence45(11), 13636–13652 (2023)
Deng, J., Yang, Z., Liu, D., Chen, T., Zhou, W., Zhang, Y., Li, H., Ouyang, W.: Transvg++: End-to-end visual grounding with language conditioned vision transformer. IEEE transactions on pattern analysis and machine intelligence45(11), 13636–13652 (2023)
2023
-
[11]
In: Proceedings of the IEEE/CVF international conference on computer vision workshops
Du, D., Zhu, P., Wen, L., Bian, X., Lin, H., Hu, Q., Peng, T., Zheng, J., Wang, X., Zhang, Y., et al.: Visdrone-det2019: The vision meets drone object detection in image challenge results. In: Proceedings of the IEEE/CVF international conference on computer vision workshops. pp. 0–0 (2019)
2019
-
[12]
In: Findings of the Association for Computational Linguistics: ACL 2023
Fan, Y., Chen, W., Jiang, T., Zhou, C., Zhang, Y., Wang, X.: Aerial vision-and-dialog navigation. In: Findings of the Association for Computational Linguistics: ACL 2023. pp. 3043–3061 (2023)
2023
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Goto, K., Hirose, T., Ukai, M., Kurita, S., Inoue, N.: Referring expression comprehension for small objects. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21231–21242 (2025)
2025
-
[14]
IEEE Robotics and Automation Letters (2024)
Honerkamp, D., Büchner, M., Despinoy, F., Welschehold, T., Valada, A.: Language-grounded dynamic scene graphs for interactive object search with mobile manipulation. IEEE Robotics and Automation Letters (2024)
2024
-
[15]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Hu, Y., Tian, Z., Qi, X., Su, C., Yang, B., Yin, J., Sun, M., Zhang, M., Sun, Z.: Remerec: Relation- aware and multi-entity referring expression comprehension. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 4010–4019 (2025)
2025
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Huang, H., Chen, X., Chen, Y., Li, H., Han, X., Wang, Z., Wang, T., Pang, J., Zhao, Z.: Roboground: Robotic manipulation with grounded vision-language priors. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22540–22550 (2025)
2025
-
[17]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Jiang, C., Wang, A., Jagersand, M.: Robot manipulation in salient vision through referring image segmen- tation and geometric constraints. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 11141–11147. IEEE (2025) 11
2025
-
[18]
IEEE Transactions on Image Processing31, 3920–3934 (2022)
Jiang, W., Zhu, M., Fang, Y., Shi, G., Zhao, X., Liu, Y.: Visual cluster grounding for image captioning. IEEE Transactions on Image Processing31, 3920–3934 (2022)
2022
-
[19]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kamath, A., Singh, M., LeCun, Y., Synnaeve, G., Misra, I., Carion, N.: Mdetr-modulated detection for end-to-end multi-modal understanding. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1780–1790 (2021)
2021
-
[20]
In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP)
Kazemzadeh, S., Ordonez, V., Matten, M., Berg, T.: Referitgame: Referring to objects in photographs of natural scenes. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). pp. 787–798 (2014)
2014
-
[21]
In: European Conference on Computer Vision (ECCV)
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common objects in context. In: European Conference on Computer Vision (ECCV). pp. 740–755. Springer (2014)
2014
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, C., Ding, H., Jiang, X.: Gres: Generalized referring expression segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 23592–23601 (2023)
2023
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, C., Li, X., Ding, H.: Referring image editing: Object-level image editing via referring expressions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13128–13138 (2024)
2024
-
[24]
arXiv preprint arXiv:2409.14750 (2024)
Liu, J., Yang, X., Li, W., Wang, P.: Finecops-ref: A new dataset and task for fine-grained compositional referring expression comprehension. arXiv preprint arXiv:2409.14750 (2024)
-
[25]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
2024
-
[26]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, S., Zhang, H., Qi, Y., Wang, P., Zhang, Y., Wu, Q.: Aerialvln: Vision-and-language navigation for uavs. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15384–15394 (2023)
2023
-
[27]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A.L., Murphy, K.: Generation and comprehension of unambiguous object descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 11–20 (2016)
2016
-
[28]
In: Proceedings of the 30th ACM international conference on multimedia
Mao, Y., Chen, L., Jiang, Z., Zhang, D., Zhang, Z., Shao, J., Xiao, J.: Rethinking the reference-based distinctive image captioning. In: Proceedings of the 30th ACM international conference on multimedia. pp. 4374–4384 (2022)
2022
-
[29]
Mistral AI: Mistral small 3.2: Advanced 24b model with multimodal capabilities.https://mistral.ai/ news/mistral-small-3-2/(2025), released June 2025
2025
-
[30]
arXiv preprint arXiv:2506.03448 (2025)
Pathiraja, B., Patel, M., Singh, S., Yang, Y., Baral, C.: Refedit: A benchmark and method for improving instruction-based image editing model on referring expressions. arXiv preprint arXiv:2506.03448 (2025)
-
[31]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Peng, R., He, H., Wei, Y., Wen, Y., Hu, D.: Patch matters: Training-free fine-grained image caption enhancement via local perception. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 3963–3973 (2025)
2025
-
[32]
arXiv preprint arXiv:2306.14665 (2023)
Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Wei, F.: Kosmos-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14665 (2023)
-
[33]
In: Proceedings of the IEEE international conference on computer vision
Plummer,B.A.,Wang,L.,Cervantes,C.M.,Caicedo,J.C.,Hockenmaier,J.,Lazebnik,S.:Flickr30kentities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In: Proceedings of the IEEE international conference on computer vision. pp. 2641–2649 (2015)
2015
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rasheed, H., Maaz, M., Shaji, S., Shaker, A., Khan, S., Cholakkal, H., Anwer, R.M., Xing, E., Yang, M.H., Khan, F.S.: Glamm: Pixel grounding large multimodal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13009–13018 (2024)
2024
-
[35]
In: European Conference on Computer Vision
Rohrbach, A., Rohrbach, M., Hu, R., Darrell, T., Schiele, B.: Grounding of textual phrases in images by reconstruction. In: European Conference on Computer Vision. pp. 817–834. Springer (2016)
2016
-
[36]
arXiv preprint arXiv:2502.00392 (2025)
Sun, Z., Liu, Y., Zhu, H., Gu, Y., Zou, Y., Liu, Z., Xia, G.S., Du, B., Xu, Y.: Refdrone: A challenging benchmark for referring expression comprehension in drone scenes. arXiv preprint arXiv:2502.00392 (2025)
-
[37]
arXiv preprint arXiv:2506.03569 (2025)
Team, X.L.C.: Mimo-vl technical report: Scaling compact vision-language models with mixed on-policy reinforcement learning. arXiv preprint arXiv:2506.03569 (2025)
-
[38]
Team, Z.A.: Glm-4.5v and glm-4.6v: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, Z., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: To see the world from a narrower tongue. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition
Wang, P., Wu, Q., Cao, J., Shen, C., Gao, L., Hengel, A.v.d.: Neighbourhood watch: Referring expression comprehension via language-guided graph attention networks. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. pp. 1960–1968 (2019)
1960
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (2024)
Wang, W., Lv, Q., Yu, W., Wen, W., Qi, P., Hou, L., Li, J., Tang, J.: Cogvlm: Visual expert for pretrained multi-modal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (2024)
2024
-
[42]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., et al.: Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025) 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu,C., Lin,Z., Cohen,S., Bui,T.,Maji,S.:Phrasecut: Language-basedimagesegmentationin thewild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10216–10225 (2020)
2020
-
[44]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Xiao, L., Yang, X., Peng, F., Wang, Y., Xu, C.: Hivg: Hierarchical multimodal fine-grained modulation for visual grounding. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 5460–5469 (2024)
2024
-
[45]
Advances in Neural Information Processing Systems37, 139854– 139885 (2024)
Xiao, L., Yang, X., Peng, F., Wang, Y., Xu, C.: Oneref: Unified one-tower expression grounding and seg- mentation with mask referring modeling. Advances in Neural Information Processing Systems37, 139854– 139885 (2024)
2024
-
[46]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, Y., Kong, J., Wang, J., Pan, X., Lin, B., Liu, Q.: Insightedit: Towards better instruction following for image editing. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2694–2703 (2025)
2025
-
[47]
arXiv preprint arXiv:2509.01563 (2025)
Yang, B., Wen, B., Ding, B., Liu, C., Chu, C., Song, C., Rao, C., Yi, C., Li, D., Zang, D., et al.: Kwai keye-vl 1.5 technical report. arXiv preprint arXiv:2509.01563 (2025)
-
[48]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Yang, J., Li, H., Li, F., Liu, S., et al.: Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yang, S., Li, G., Yu, Y.: Dynamic graph attention for referring expression comprehension. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4644–4653 (2019)
2019
-
[50]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, S., Li, G., Yu, Y.: Graph-structured referring expression reasoning in the wild. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9952–9961 (2020)
2020
-
[51]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Yang, X., Liu, J., Wang, P., Wang, G., Yang, Y., Shen, H.T.: New dataset and methods for fine-grained compositional referring expression comprehension via specialist-mllm collaboration. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[52]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yang, Z., Gong, B., Wang, L., Huang, W., Yu, D., Luo, J.: A fast and accurate one-stage approach to visual grounding. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4683–4693 (2019)
2019
-
[53]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yao, Y., Liu, P., Zhao, T., Zhang, Q., Liao, J., Fang, C., Lee, K., Wang, Q.: How to evaluate the gener- alization of detection? a benchmark for comprehensive open-vocabulary detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 6630–6638 (2024)
2024
-
[54]
arXiv preprint arXiv:2509.04321 (2025)
Yao, Y., Yu, W., et al.: Minicpm-v 4.5: A compact and powerful vision-language model with 3d-resampler. arXiv preprint arXiv:2509.04321 (2025)
-
[55]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Yu, L., Lin, Z., Shen, X., Yang, J., Lu, X., Bansal, M., Berg, T.L.: Mattnet: Modular attention network for referring expression comprehension. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1307–1315 (2018)
2018
-
[56]
Yu,L.,Poirson,P.,Yang,S.,Berg,A.C.,Berg,T.L.:Modelingcontextinreferringexpressions.In:European conference on computer vision. pp. 69–85. Springer (2016)
2016
-
[57]
IEEE Transactions on Geoscience and Remote Sensing61, 1–13 (2023)
Zhan, Y., Xiong, Z., Yuan, Y.: Rsvg: Exploring data and models for visual grounding on remote sensing data. IEEE Transactions on Geoscience and Remote Sensing61, 1–13 (2023)
2023
-
[58]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, H., Niu, Y., Chang, S.F.: Grounding referring expressions in images by variational context. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4158–4166 (2018)
2018
-
[59]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zheng, S., Zhao, P., Zheng, Z., He, P., Cheng, H., Cai, Y., Huang, Q.: Look around before locating: Con- sidering content and structure information for visual grounding. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 1656–1664 (2025)
2025
-
[60]
Zhou, H., Hu, C., Yuan, Y., Cui, Y., Jin, Y., Chen, C., Wu, H., Yuan, D., Jiang, L., Wu, D., et al.: Large language model (llm) for telecommunications: A comprehensive survey on principles, key techniques, and opportunities. IEEE Communications Surveys & Tutorials27(3), 1955–2005 (2024) 13 Towards Open-World Referring Expression Comprehension: A Benchmark...
1955
-
[61]
Detect query. Return result in JSON list with ’bbox_2d’ and ’label’. If not found, output ’None’
Standalone REC (Baseline) "Detect query. Return result in JSON list with ’bbox_2d’ and ’label’. If not found, output ’None’."
-
[62]
How many query are in the image? Answer with an integer
Multi-task Consistency Checker (MCC) To evaluate and enforce consistency between referring counting and REC, we employ a three-stage loop: Referring Counting Phase:"How many query are in the image? Answer with an integer." Detection Phase (REC):"Detect all query and output boxes in [[xmin, ymin, xmax, ymax]] format." ConsistencyCheck(Checker):"Youcountedc...
-
[63]
Detect query. Return result in JSON list with ’bbox_2d’
Repetitive Dual-Inference (RDI) For experiments involving direct repetition and self-correction without explicit count matching: 16 First Pass:"Detect query. Return result in JSON list with ’bbox_2d’." Second Pass (Refinement):"Are you sure? Double check and add missing or remove wrong objects."
-
[64]
Settings of Qwen2.5-VL-7B and Qwen2.5-VL-32B.For Standalone REC, we use
Explicit Counting Alignment (ECA) We force the model to align its detection output with a specific numerical prior (predicted count from referring counting task): First Pass:"Directly output the number of query in the image. Answer with a single integer. SecondPass(Observation):Thereareexactlyexp_countinstancesofqueryhere.Pleaseprovide the bounding boxes ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.