DeGRe: Dense-supervised Generative Reranking for Recommendation
Pith reviewed 2026-06-29 20:15 UTC · model grok-4.3
The pith
DeGRe trains a generator with dense step-wise supervision from an offline evaluator so that a single greedy decoding pass approximates optimal reranking sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
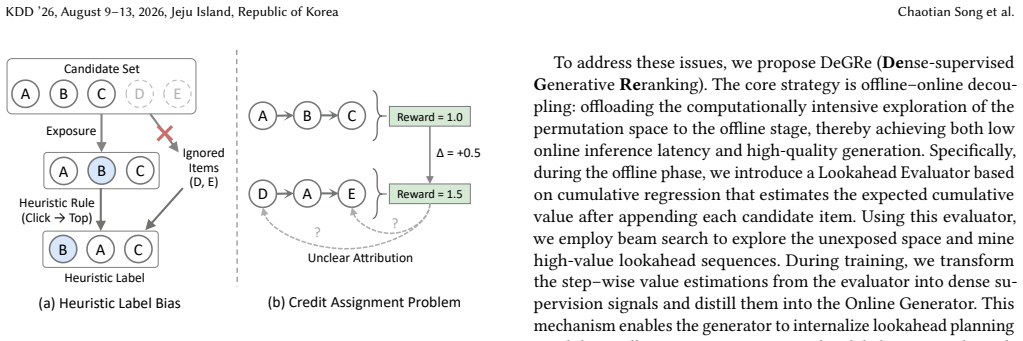
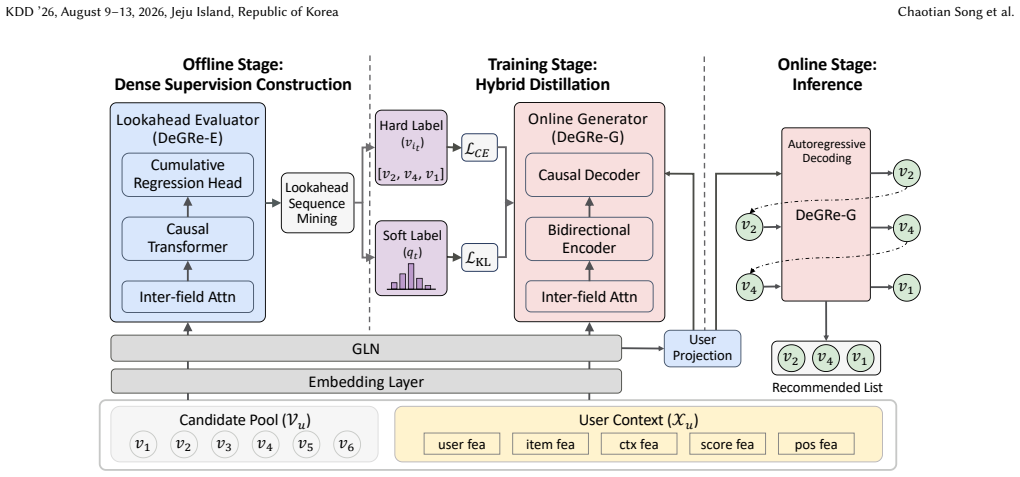
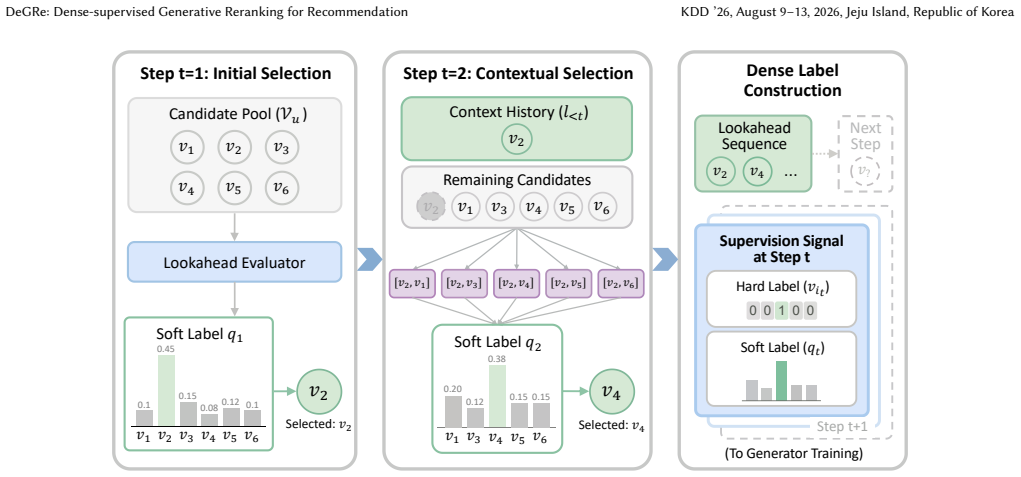
DeGRe decouples offline exploration from online inference by training an offline Lookahead Evaluator with cumulative regression and beam search to identify high-value sequences in unexposed space, then distilling the step-wise value estimates as dense supervision into the online generator to resolve heuristic label bias and credit assignment, so the generator internalizes planning and approximates the global optimum via greedy decoding.
What carries the argument
The offline Lookahead Evaluator that uses beam search and cumulative regression to produce step-wise value estimations for dense supervision distillation into the generator.
If this is right
- The generator produces near-optimal sequences using only a single greedy decoding pass at inference time.
- Heuristic label bias is corrected because training targets now encode causal dependencies discovered by beam search.
- The credit assignment problem is resolved because every generation step receives an explicit value signal rather than a single list-level reward.
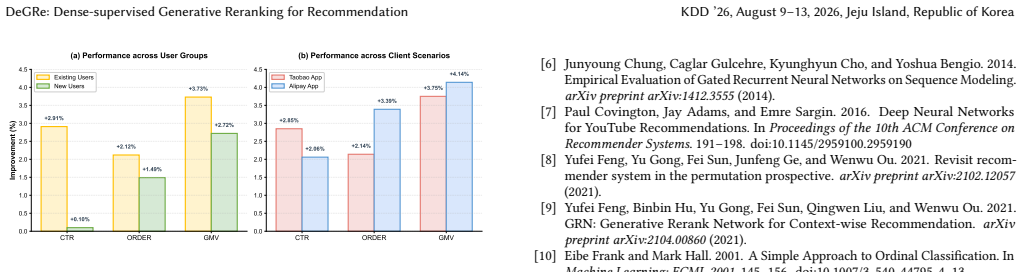
- The framework outperforms prior generative rerankers on both public benchmarks and industrial datasets.
- Deployment replaces expensive search with fast greedy inference while maintaining or improving recommendation quality.
Where Pith is reading between the lines
- The same offline-evaluator-plus-distillation pattern could be applied to other sequence-generation settings that currently rely on expensive test-time search.
- If the evaluator's value estimates prove reliable, the technique supplies a concrete way to turn sparse-reward reinforcement learning problems into dense-supervision problems without changing the online policy architecture.
- The approach separates the cost of exploration from the cost of serving, which may matter in any domain where list context affects downstream user behavior.
Load-bearing premise
The step-wise value estimates produced by the offline evaluator accurately reflect causal list dependencies and can be distilled into the generator without major distortion or loss of planning information.
What would settle it
Measuring list utility when the trained generator runs greedy decoding versus when the same model runs full beam search on the identical test set and finding no consistent gain for the greedy output would falsify the approximation claim.
Figures

read the original abstract
In multi-stage recommender systems, reranking optimizes overall utility by capturing intra-list contextual dependencies, yet its central challenge lies in exploring optimal sequences within an exponentially large permutation space. Recent studies have shifted towards end-to-end generative frameworks, which typically leverage list-wise rewards or preference alignment to guide generator training. However, these methods still face two critical issues. First is the heuristic label bias. Existing methods often construct training targets based on simple rules, such as promoting clicked items to the top, while ignoring causal dependencies within the list context. Second is the credit assignment problem. Sparse list-level posterior rewards fail to directly guide intermediate steps in sequence generation, leading to ambiguous optimization directions. To address these issues, we propose DeGRe (Dense-supervised Generative Reranking), a generative reranking framework that bridges the gap between offline exploration and online efficiency through dense supervision. The core of DeGRe lies in its offline-online decoupled design. During the offline phase, we introduce a Lookahead Evaluator based on cumulative regression, which leverages beam search to actively mine high-value lookahead sequences in the unexposed space. During training, we transform the step-wise value estimations from the evaluator into dense supervision signals and distill them into a lightweight Online Generator. This mechanism enables the generator to internalize lookahead planning capabilities, requiring only a single efficient greedy decoding pass during online inference to approximate the global optimum. Experiments demonstrate that DeGRe outperforms baseline models on public benchmarks and industrial datasets. We have successfully deployed DeGRe on Taobao Flash Shopping, significantly improving online recommendations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DeGRe, a generative reranking framework for multi-stage recommender systems that decouples offline and online phases to address heuristic label bias and the credit assignment problem. An offline Lookahead Evaluator uses beam search over unexposed sequences combined with cumulative regression to produce step-wise value estimations; these are transformed into dense supervision signals and distilled into a lightweight online generator. The generator is thereby claimed to internalize lookahead planning, so that a single greedy decoding pass at inference approximates the global optimum found by the evaluator. Experiments on public benchmarks and industrial data are reported to show gains, with deployment on Taobao Flash Shopping.
Significance. If the distillation step successfully transfers the evaluator's lookahead planning into the generator without substantial loss, the offline-online design could offer a practical route to combining thorough sequence exploration with low-latency inference, which is valuable for industrial reranking where both accuracy and speed matter.
minor comments (2)
- The abstract states that step-wise values are 'transformed into dense supervision signals' but supplies no equations, loss formulation, or description of the regression target, making it impossible to verify whether the claimed correction of heuristic bias and credit assignment actually occurs.
- No implementation details, hyper-parameters, or ablation results are visible in the provided text, so the central claim that greedy decoding approximates the beam-searched optimum cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the careful summary of DeGRe and for acknowledging the potential practical value of the offline-online decoupled design for industrial reranking. We note that the report lists no specific major comments.
Circularity Check
No significant circularity
full rationale
The abstract describes an offline Lookahead Evaluator that uses beam search and cumulative regression to produce step-wise values, which are then transformed into dense supervision signals for distillation into the online generator. No equations, training objectives, or self-citations are present in the provided text that would reduce any claimed prediction or result to its inputs by construction. The central mechanism (distillation of lookahead values) is presented as an independent design choice targeting heuristic bias and credit assignment, with no evidence of self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations. This is the expected outcome for a high-level architectural description without verifiable reduction steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Lookahead Evaluator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qingyao Ai, Keping Bi, Jiafeng Guo, and W. Bruce Croft. 2018. Learning a Deep Listwise Context Model for Ranking Refinement. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 135–144. doi:10.1145/3209978.3209985
-
[2]
Irwan Bello, Sayali Kulkarni, Sagar Jain, Craig Boutilier, Ed Chi, Elad Eban, Xiyang Luo, Alan Mackey, and Ofer Meshi. 2018. Seq2Slate: Re-ranking and slate optimization with RNNs.arXiv preprint arXiv:1810.02019(2018)
Pith/arXiv arXiv 2018
-
[3]
Chi Chen, Hui Chen, Kangzhi Zhao, Junsheng Zhou, Li He, Hongbo Deng, Jian Xu, Bo Zheng, Yong Zhang, and Chunxiao Xing. 2022. EXTR: Click-Through Rate Prediction with Externalities in E-Commerce Sponsored Search. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2732–2740. doi:10.1145/3534678.3539053
-
[4]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah
-
[5]
InProceedings of the 1st Workshop on Deep Learning for Recommender Systems
Wide & Deep Learning for Recommender Systems. InProceedings of the 1st Workshop on Deep Learning for Recommender Systems. 7–10. doi:10.1145/2988450. 2988454
-
[6]
Kyunghyun Cho, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 1724–1734. doi:10.3115/v1/D14-1179
-
[7]
Junyoung Chung, Caglar Gulcehre, Kyunghyun Cho, and Yoshua Bengio. 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv preprint arXiv:1412.3555(2014)
Pith/arXiv arXiv 2014
-
[8]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems. 191–198. doi:10.1145/2959100.2959190
-
[9]
Yufei Feng, Yu Gong, Fei Sun, Junfeng Ge, and Wenwu Ou. 2021. Revisit recom- mender system in the permutation prospective.arXiv preprint arXiv:2102.12057 (2021)
arXiv 2021
-
[10]
Yufei Feng, Binbin Hu, Yu Gong, Fei Sun, Qingwen Liu, and Wenwu Ou. 2021. GRN: Generative Rerank Network for Context-wise Recommendation.arXiv preprint arXiv:2104.00860(2021)
arXiv 2021
-
[11]
Eibe Frank and Mark Hall. 2001. A Simple Approach to Ordinal Classification. In Machine Learning: ECML 2001. 145–156. doi:10.1007/3-540-44795-4_13
-
[12]
Xudong Gong, Qinlin Feng, Yuan Zhang, Jiangling Qin, Weijie Ding, Biao Li, Peng Jiang, and Kun Gai. 2022. Real-time Short Video Recommendation on Mobile Devices. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. 3103–3112. doi:10.1145/3511808.3557065
-
[13]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. InProceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17. 1725–1731. doi:10.24963/ijcai.2017/239
-
[14]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, Yueming Han, MengLei Zhou, Lei Yu, Chuan Liu, and Wei Lin. 2025. MTGR: Industrial-Scale Generative Recommendation Framework in Meituan. InProceedings of the 34th ACM In- ternational Conference on Information and Knowledge Management. 5731...
-
[15]
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning Deep Structured Semantic Models for Web Search Using Clickthrough Data. InProceedings of the 22nd ACM International Conference on Information and Knowledge Management. 2333–2338. doi:10.1145/2505515. 2505665
-
[16]
Zhenhao Jiang, Chenghao Chen, Hao Feng, Yu Yang, Jin Liu, Jie Zhang, Jia Jia, and Ning Hu. 2025. Pre-train and Fine-tune: Recommenders as Large Models. InCompanion Proceedings of the ACM on Web Conference 2025. 267–276. doi:10. 1145/3701716.3715255
arXiv 2025
-
[17]
Chao Li, Zhiyuan Liu, Mengmeng Wu, Yuchi Xu, Huan Zhao, Pipei Huang, Guoliang Kang, Qiwei Chen, Wei Li, and Dik Lun Lee. 2019. Multi-Interest Network with Dynamic Routing for Recommendation at Tmall. InProceedings of the 28th ACM International Conference on Information and Knowledge Management. 2615–2623. doi:10.1145/3357384.3357814
-
[18]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1754–1763. doi:10.1145/3219819.3220023
-
[19]
Xiao Lin, Xiaokai Chen, Chenyang Wang, Hantao Shu, Linfeng Song, Biao Li, and Peng Jiang. 2024. Discrete Conditional Diffusion for Reranking in Recom- mendation. InCompanion Proceedings of the ACM Web Conference 2024. 161–169. doi:10.1145/3589335.3648313
-
[20]
Zhijie Lin, Zhuofeng Li, Chenglei Dai, Wentian Bao, Shuai Lin, Enyun Yu, Haoxi- ang Zhang, and Liang Zhao. 2025. GReF: A Unified Generative Framework for Efficient Reranking via Ordered Multi-token Prediction. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5879–5887. doi:10.1145/3746252.3761540
-
[21]
Weiwen Liu, Yunjia Xi, Jiarui Qin, Fei Sun, Bo Chen, Weinan Zhang, Rui Zhang, and Ruiming Tang. 2022. Neural re-ranking in multi-stage recommender systems: A review.arXiv preprint arXiv:2202.06602(2022)
arXiv 2022
-
[22]
Peter McCullagh. 1980. Regression Models for Ordinal Data.Journal of the Royal Statistical Society: Series B (Methodological)42, 2 (1980), 109–127. doi:10.1111/j. 2517-6161.1980.tb01109.x
work page doi:10.1111/j 1980
-
[23]
Liang Pang, Jun Xu, Qingyao Ai, Yanyan Lan, Xueqi Cheng, and Jirong Wen. 2020. SetRank: Learning a Permutation-Invariant Ranking Model for Information Re- trieval. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 499–508. doi:10.1145/3397271.3401104
-
[24]
Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, Junfeng Ge, Wenwu Ou, and Dan Pei. 2019. Personalized re-ranking for recommendation. InProceedings of the 13th ACM Conference on Recommender Systems. 3–11. doi:10.1145/3298689.3347000
-
[25]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InAdvances in Neural Information Processing Systems, Vol. 36. 53728–53741. https://proceedings.neurips.cc/paper_files/paper/ 2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-...
2023
-
[26]
Yuxin Ren, Qiya Yang, Yichun Wu, Wei Xu, Yalong Wang, and Zhiqiang Zhang
-
[27]
InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Non-autoregressive Generative Models for Reranking Recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5625–5634. doi:10.1145/3637528.3671645 KDD ’26, August 9–13, 2026, Jeju Island, Republic of Korea Chaotian Song et al
-
[28]
Xiaowen Shi, Fan Yang, Ze Wang, Xiaoxu Wu, Muzhi Guan, Guogang Liao, Yongkang Wang, Xingxing Wang, and Dong Wang. 2023. PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4823–4831. doi:10.1145/3580305.3599886
-
[29]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. At- tention is All You Need. InAdvances in Neural Information Process- ing Systems, Vol. 30. https://proceedings.neurips.cc/paper/2017/hash/ 3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
2017
-
[30]
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. 2015. Pointer Networks. In Advances in Neural Information Processing Systems, Vol. 28. https://proceedings. neurips.cc/paper/2015/hash/29921001f2f04bd3baee84a12e98098f-Abstract.html
arXiv 2015
-
[31]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. InProceedings of the ADKDD’17. 1–7. doi:10.1145/ 3124749.3124754
arXiv 2017
-
[32]
Shuli Wang, Xue Wei, Senjie Kou, Chi Wang, Wenshuai Chen, Qi Tang, Yinhua Zhu, Xiong Xiao, and Xingxing Wang. 2025. NLGR: Utilizing Neighbor Lists for Generative Rerank in Personalized Recommendation Systems. InCompanion Proceedings of the ACM on Web Conference 2025. 530–537. doi:10.1145/3701716. 3715251
-
[33]
Yunjia Xi, Weiwen Liu, Xinyi Dai, Ruiming Tang, Qing Liu, Weinan Zhang, and Yong Yu. 2024. Utility-Oriented Reranking with Counterfactual Context.ACM Trans. Knowl. Discov. Data18, 8 (2024), 193. doi:10.1145/3671004
-
[34]
Yunjia Xi, Weiwen Liu, Jieming Zhu, Xilong Zhao, Xinyi Dai, Ruiming Tang, Weinan Zhang, Rui Zhang, and Yong Yu. 2022. Multi-Level Interaction Reranking with User Behavior History. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1336–1346. doi:10.1145/3477495.3532026
-
[35]
Kaike Zhang, Xiaobei Wang, Shuchang Liu, Hailan Yang, Xiang Li, Lantao Hu, Han Li, Qi Cao, Fei Sun, and Kun Gai. 2025. Goalrank: Group-relative optimization for a large ranking model.arXiv preprint arXiv:2509.22046(2025)
arXiv 2025
-
[36]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep Interest Evolution Network for Click-Through Rate Prediction.Proceedings of the AAAI Conference on Artificial Intelligence33, 01 (2019), 5941–5948. doi:10.1609/aaai.v33i01.33015941
-
[37]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click- Through Rate Prediction. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1059–1068. doi:10.1145/ 3219819.3219823
arXiv 2018
-
[38]
Han Zhu, Xiang Li, Pengye Zhang, Guozheng Li, Jie He, Han Li, and Kun Gai
-
[39]
InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery Data Mining
Learning Tree-based Deep Model for Recommender Systems. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1079–1088. doi:10.1145/3219819.3219826
-
[40]
Tao Zhuang, Wenwu Ou, and Zhirong Wang. 2018. Globally Optimized Mutual Influence Aware Ranking in E-Commerce Search. InProceedings of the Twenty- Seventh International Joint Conference on Artificial Intelligence, IJCAI-18. 3725–
2018
-
[41]
doi:10.24963/ijcai.2018/518
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.