An Analysis Focused on Womens Safety: Can VAD Models Be Enhanced by a Multi-modal Dataset?
Pith reviewed 2026-06-29 22:10 UTC · model grok-4.3
The pith
Existing video anomaly detection datasets are insufficient to train models for women-centric anomalies such as chain snatching and stalking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
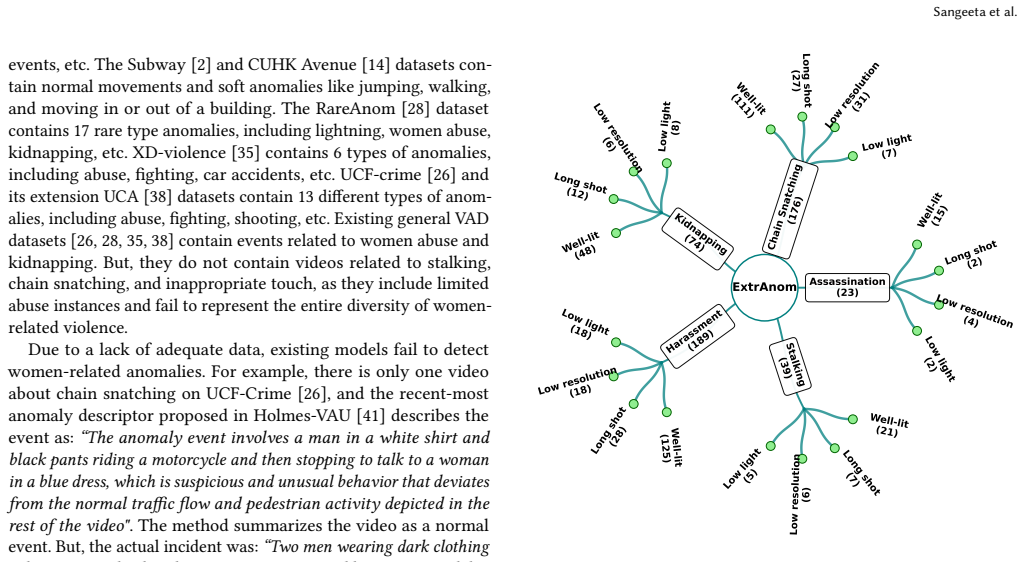
The ExtrAnom dataset provides 1001 videos split into normal and anomalous categories across five women-centric crime types, with 8 percent low-light, 13 percent low-resolution, and 15 percent long-shot footage plus four textual descriptions per video; benchmarking against XD-Violence, UCF-Crime, and UCA demonstrates that models trained on those prior datasets cannot adequately detect the women-centric anomalies represented here.
What carries the argument
The ExtrAnom dataset, a multi-modal collection of 1001 videos paired with human- and LLM-generated textual annotations for women-centric anomalies.
If this is right
- Models trained solely on XD-Violence or UCF-Crime will miss women-centric anomalies that appear in low-light or long-shot conditions.
- The four textual annotations per video enable cross-modal validation and VLM-based description generation for anomaly events.
- Coverage of specific anomalies such as stalking at 3.9 percent and chain snatching at 17.6 percent supplies targeted training examples absent from prior datasets.
- Benchmark results indicate that SOTA unimodal and multi-modal VAD methods require women-centric data to reach usable performance on these events.
Where Pith is reading between the lines
- Surveillance systems could incorporate ExtrAnom-style data to prioritize alerts for harassment or kidnapping over generic anomalies.
- The multi-modal format may support zero-shot anomaly flagging by feeding video clips and descriptions into existing vision-language models.
- Expanding the dataset with additional real-world camera feeds could test whether the current 64 percent daylight split generalizes to darker urban environments.
- Public safety applications might combine the textual annotations with audio cues to distinguish subtle crimes from normal activity.
Load-bearing premise
The videos and annotations collected in ExtrAnom are representative enough of real-world women-centric anomalies to improve VAD model performance when used for training.
What would settle it
Train a standard VAD model on ExtrAnom and evaluate it on an independent collection of real surveillance footage containing chain snatching or stalking events; if accuracy does not exceed that of the same model trained on XD-Violence or UCF-Crime, the claim does not hold.
Figures





read the original abstract
Women's safety and security are paramount for a modern society. Crimes against women occur in daylight as well as in low-light conditions. Often, such events are captured through real-world surveillance cameras that operate at lower resolutions. Despite substantial progress in CV-related research, video anomaly detection (VAD) focused on women's safety has not yet been adequately addressed. Existing video anomaly datasets contain well-lit, high-resolution, close-shot videos, and fail to represent women-centric anomalies such as chain snatching, stalking, inappropriate touch, and other subtle forms of crime against women. To address these problems, we propose the ExtrAnom dataset, a new multi-modal benchmark containing 1001 videos with textual descriptions, 500 normal and 501 anomalous, classified into 5 different types of women-centric crimes. The dataset comprises low-light (8%), low-resolution videos (13%), long-shot (15%), along with daylight (64%) anomalous videos. And it covers anomalous events like stalking (3.9%), chain snatching (17.6%), kidnapping (7.3%), assassinations (2.3%), harassment (18.9%), and normal (50%). Each video is supplemented with 4 textual annotations, including one human-generated and three LLM-generated descriptions, enabling cross-modal and VLM-based validations. The aim of creating a women-centric dataset is to accurately detect the women-centric anomaly patterns, which are possible to observe visually. The dataset supplements the VLMs to accurately generate video-level descriptions. ExtrAnom has been benchmarked against popular unimodal and multi-modal VAD datasets (e.g., XD-Violence, UCF-Crime, and UCA) and SOTA methods. Experiments reveal that the existing datasets are insufficient to train models for detecting women-centric anomalies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing VAD datasets (XD-Violence, UCF-Crime, UCA) are insufficient for detecting women-centric anomalies because they lack representation of subtle crimes such as chain snatching, stalking, inappropriate touch, kidnapping, and harassment. To address this, the authors introduce the ExtrAnom dataset: 1001 videos (500 normal, 501 anomalous) with multi-modal annotations consisting of one human-generated and three LLM-generated textual descriptions per video. The dataset includes a mix of acquisition conditions (low-light 8%, low-resolution 13%, long-shot 15%, daylight 64%) and is benchmarked by training SOTA unimodal and multi-modal VAD models on existing datasets and evaluating on ExtrAnom, with results showing poor performance taken as evidence of insufficiency.
Significance. If the performance degradation on ExtrAnom is shown to stem specifically from missing women-centric anomaly semantics rather than low-level visual domain differences, the dataset could support more targeted safety applications in surveillance VAD and enable better VLM-based video description. The inclusion of both human and LLM textual annotations is a constructive step toward cross-modal validation. However, the current experimental design does not yet isolate these factors, limiting the strength of the central claim.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments: The central claim that existing datasets are insufficient specifically for women-centric anomaly types rests on cross-dataset transfer results. However, ExtrAnom differs systematically in acquisition statistics (low-light 8%, low-resolution 13%, long-shot 15%) from the well-lit/high-resolution/close-shot characterization of XD-Violence/UCF-Crime/UCA. No ablation is described that holds visual domain factors constant while varying only anomaly semantics (e.g., by subsampling or style-transfer controls), so the performance drop cannot be unambiguously attributed to missing anomaly patterns versus domain shift.
- [Dataset] Dataset section: The manuscript provides no details on video collection methodology, source cameras, annotation protocol for the five crime categories, or validation of the 4 textual descriptions per video (e.g., inter-annotator agreement or LLM hallucination checks). These omissions are load-bearing because the claim of “women-centric” specificity depends on the dataset faithfully capturing the intended subtle anomalies rather than incidental visual artifacts.
minor comments (2)
- [Title] Title: “Womens Safety” should read “Women’s Safety”.
- [Abstract] Abstract: The percentages for anomalous event types (stalking 3.9%, chain snatching 17.6%, etc.) and normal (50%) are presented without stating whether they are computed over the full 1001 videos or only the 501 anomalous videos; this should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments: The central claim that existing datasets are insufficient specifically for women-centric anomaly types rests on cross-dataset transfer results. However, ExtrAnom differs systematically in acquisition statistics (low-light 8%, low-resolution 13%, long-shot 15%) from the well-lit/high-resolution/close-shot characterization of XD-Violence/UCF-Crime/UCA. No ablation is described that holds visual domain factors constant while varying only anomaly semantics (e.g., by subsampling or style-transfer controls), so the performance drop cannot be unambiguously attributed to missing anomaly patterns versus domain shift.
Authors: We acknowledge the systematic differences in acquisition conditions between ExtrAnom and prior datasets. These conditions were deliberately included to reflect real-world surveillance footage relevant to women's safety applications, where low-light, low-resolution, and long-shot scenarios are common. The cross-dataset results show poor transfer performance, which we interpret as evidence that existing datasets lack the specific women-centric anomaly semantics (e.g., chain snatching, stalking). While domain shift may contribute, the distinguishing factor remains the anomaly types themselves. We will revise the Experiments and Discussion sections to explicitly address this potential confounding and clarify the role of semantic versus low-level differences. However, style-transfer or subsampling controls risk altering the very anomaly patterns under study, so we will focus on expanded discussion rather than new experiments. revision: partial
-
Referee: [Dataset] Dataset section: The manuscript provides no details on video collection methodology, source cameras, annotation protocol for the five crime categories, or validation of the 4 textual descriptions per video (e.g., inter-annotator agreement or LLM hallucination checks). These omissions are load-bearing because the claim of “women-centric” specificity depends on the dataset faithfully capturing the intended subtle anomalies rather than incidental visual artifacts.
Authors: We agree that the current manuscript lacks sufficient documentation on these aspects. In the revised version, the Dataset section will be expanded to detail the video collection methodology and sources, the annotation protocol for the five crime categories, and validation procedures for the textual descriptions, including steps taken to ensure consistency and reduce LLM hallucinations. revision: yes
Circularity Check
No circularity: empirical cross-dataset benchmarking against external sources
full rationale
The paper's core claim—that existing VAD datasets are insufficient for women-centric anomalies—is supported by training SOTA models on XD-Violence/UCF-Crime/UCA and evaluating on the newly introduced ExtrAnom dataset, with performance drops presented as evidence. This is a standard empirical comparison using externally defined datasets and models; it does not reduce any result to a self-definition, fitted parameter renamed as prediction, or self-citation chain. Dataset composition (low-light 8%, low-res 13%, etc.) and annotations are described directly without circular construction. No equations, ansatzes, or uniqueness theorems are invoked that collapse back to the paper's own inputs. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Andra Acsintoae, Andrei Florescu, Mariana-Iuliana Georgescu, Tudor Mare, Paul Sumedrea, Radu Tudor Ionescu, Fahad Shahbaz Khan, and Mubarak Shah. 2022. UBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 20111–20121
2022
-
[2]
Amit Adam, Ehud Rivlin, Ilan Shimshoni, and Daviv Reinitz. 2008. Robust Real- Time Unusual Event Detection using Multiple Fixed-Location Monitors.IEEE Transactions on Pattern Analysis and Machine Intelligence30, 3 (2008), 555–560
2008
-
[3]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. InProceedings An Analysis Focused on Women’s Safety: Can V AD Models Be Enhanced by a Multi-modal Dataset? of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ja...
2005
-
[4]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. 2024. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (C...
2024
-
[5]
DeepSeek-AI et al. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Jia-Chang Feng, Fa-Ting Hong, and Wei-Shi Zheng. 2021. MIST: Multiple Instance Self-Training Framework for Video Anomaly Detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14009– 14018
2021
-
[7]
Ziming Huang, Xurui Li, Haotian Liu, Feng Xue, Yuzhe Wang, and Yu Zhou. 2025. AnomalyNCD: Towards Novel Anomaly Class Discovery in Industrial Scenarios. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR). 4755–4765
2025
-
[8]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, De- vendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Hyekang Kevin Joo, Khoa Vo, Kashu Yamazaki, and Ngan Le. 2023. CLIP-TSA: Clip-Assisted Temporal Self-Attention for Weakly-Supervised Video Anomaly Detection. In2023 IEEE International Conference on Image Processing (ICIP). 3230– 3234
2023
-
[10]
Weixin Li, Vijay Mahadevan, and Nuno Vasconcelos. 2014. Anomaly Detection and Localization in Crowded Scenes.IEEE Transactions on Pattern Analysis and Machine Intelligence36, 1 (2014), 18–32
2014
-
[11]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-LLaVA: Learning United Visual Representation by Alignment Before Pro- jection. arXiv:2311.10122 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81
2004
-
[13]
Kun Liu and Huadong Ma. 2019. Exploring Background-bias for Anomaly Detection in Surveillance Videos. InProceedings of the 27th ACM International Conference on Multimedia(Nice, France)(MM ’19). Association for Computing Machinery, New York, NY, USA, 1490–1499
2019
-
[14]
Cewu Lu, Jianping Shi, and Jiaya Jia. 2013. Abnormal Event Detection at 150 FPS in MATLAB. In2013 IEEE International Conference on Computer Vision. 2720– 2727
2013
-
[15]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. 2024. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational L...
2024
-
[16]
Shishir Shah
Pranav Mantini, Zhenggang Li, and K. Shishir Shah. 2021. A Day on Campus - An Anomaly Detection Dataset for Events in a Single Camera. InComputer Vision – ACCV 2020, Hiroshi Ishikawa, Cheng-Lin Liu, Tomas Pajdla, and Jianbo Shi (Eds.). Springer International Publishing, Cham, 619–635
2021
-
[17]
UNODC’s media team. 2024. One woman is killed every 10 minutes by their intimate partners or other family members. https://www.unodc.org/unodc/en/ press/releases/2024/November/one-woman-is-killed-every-10-minutes-by- their-intimate-partners-or-other-family-members.html. [Online; accessed 25-November-2024]
2024
-
[18]
Jingke Meng, Huilin Tian, Ge Lin, Jian-Fang Hu, and Wei-Shi Zheng. 2025. Audio- Visual Collaborative Learning for Weakly Supervised Video Anomaly Detection. IEEE Transactions on Multimedia(2025), 1–12
2025
-
[19]
OpenAI et al. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Arabinda Panda, Debi Prosad Dogra, and Partha Pratim Dey. 2025. Prediction of Urban Traffic Patterns by Analyzing Real-World Videos Using Clustering and Markov Model. InPattern Recognition. ICPR 2024 International Workshops and Challenges, Shivakumara Palaiahnakote, Stephanie Schuckers, Jean-Marc Ogier, Prabir Bhattacharya, Umapada Pal, and Saumik Bhattac...
2025
-
[21]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Pierre Isabelle, Eugene Charniak, and Dekang Lin (Eds.). Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, 311–318
2002
-
[22]
Kot, and Anderson Rocha
Mauricio Perez, Alex C. Kot, and Anderson Rocha. 2019. Detection of Real-world Fights in Surveillance Videos. InICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2662–2666
2019
-
[23]
Bharathkumar Ramachandra and Michael J. Jones. 2020. Street Scene: A new dataset and evaluation protocol for video anomaly detection. In2020 IEEE Winter Conference on Applications of Computer Vision (W ACV). 2558–2567
2020
-
[24]
K. K. Santhosh, D. P. Dogra, and P. P. Roy. 2020. Anomaly Detection in Road Traffic Using Visual Surveillance: A Survey.ACM Comput. Surv.53, 6, Article 119 (Dec. 2020), 26 pages
2020
-
[25]
Yukun Su, Guosheng Lin, Jinhui Zhu, and Qingyao Wu. 2020. Human Interac- tion Learning on 3D Skeleton Point Clouds for Video Violence Recognition. In Computer Vision – ECCV 2020, Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm (Eds.). Springer International Publishing, Cham, 74–90
2020
-
[26]
Waqas Sultani, Chen Chen, and Mubarak Shah. 2018. Real-World Anomaly Detection in Surveillance Videos. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6479–6488
2018
-
[27]
Gemini Team et al . 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Kamalakar Vijay Thakare, Debi Prosad Dogra, Heeseung Choi, Haksub Kim, and Ig-Jae Kim. 2023. RareAnom: A Benchmark Video Dataset for Rare Type Anomalies.Pattern Recognition140 (2023), 109567
2023
-
[29]
Kamalakar Vijay Thakare, Yash Raghuwanshi, Debi Prosad Dogra, Heeseung Choi, and Ig-Jae Kim. 2023. DyAnNet: A Scene Dynamicity Guided Self-Trained Video Anomaly Detection Network. In2023 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). 5530–5539
2023
-
[30]
Verjans, and Gustavo Carneiro
Yu Tian, Guansong Pang, Yuanhong Chen, Rajvinder Singh, Johan W. Verjans, and Gustavo Carneiro. 2021. Weakly-Supervised Video Anomaly Detection With Robust Temporal Feature Magnitude Learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4975–4986
2021
-
[31]
Lawrence Zitnick, and Devi Parikh
Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. 2015. CIDEr: Consensus-based image description evaluation. In2015 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR). 4566–4575
2015
-
[32]
Jue Wang and Anoop Cherian. 2019. GODS: Generalized One-Class Discrimina- tive Subspaces for Anomaly Detection. In2019 IEEE/CVF International Conference on Computer Vision (ICCV). 8200–8210
2019
-
[33]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. arXiv:2409.12191 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
WHO. 2024. Violence against women. https://www.who.int/news-room/fact- sheets/detail/violence-against-women. [Online; accessed 25-March-2024]
2024
-
[35]
Peng Wu, Jing Liu, Yujia Shi, Yujia Sun, Fangtao Shao, Zhaoyang Wu, and Zhiwei Yang. 2020. Not only Look, But Also Listen: Learning Multimodal Violence Detection Under Weak Supervision. InComputer Vision – ECCV 2020, Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm (Eds.). Springer International Publishing, Cham, 322–339
2020
-
[36]
Peng Wu, Xuerong Zhou, Guansong Pang, Lingru Zhou, Qingsen Yan, Peng Wang, and Yanning Zhang. 2024. VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection.Proceedings of the AAAI Conference on Artificial Intelligence38, 6 (Mar. 2024), 6074–6082
2024
-
[37]
Chen Xu, Chunguo Li, and Hongjie Xing. 2025. Discriminative Score Suppression for Weakly Supervised Video Anomaly Detection. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). 9587–9596
2025
-
[38]
Tongtong Yuan, Xuange Zhang, Kun Liu, Bo Liu, Chen Chen, Jian Jin, and Zhen- zhen Jiao. 2024. Towards Surveillance Video-and-Language Understanding: New Dataset, Baselines, and Challenges. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 22052–22061
2024
-
[39]
Luca Zanella, Willi Menapace, Massimiliano Mancini, Yiming Wang, and Elisa Ricci. 2024. Harnessing Large Language Models for Training-free Video Anomaly Detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18527–18536
2024
-
[40]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. arXiv:2306.02858 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Huaxin Zhang, Xiaohao Xu, Xiang Wang, Jialong Zuo, Xiaonan Huang, Changxin Gao, Shanjun Zhang, Li Yu, and Nong Sang. 2025. Holmes-VAU: Towards Long- term Video Anomaly Understanding at Any Granularity. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13843– 13853
2025
-
[42]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore: Evaluating Text Generation with BERT. arXiv:1904.09675 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[43]
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chun- yuan Li. 2025. LLaVA-Video: Video Instruction Tuning With Synthetic Data. arXiv:2410.02713 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Wenbing Zhu, Lidong Wang, Ziqing Zhou, Chengjie Wang, Yurui Pan, Ruoyi Zhang, Zhuhao Chen, Linjie Cheng, Bin-Bin Gao, Jiangning Zhang, Zhenye Gan, Yuxie Wang, Yulong Chen, Shuguang Qian, Mingmin Chi, Bo Peng, and Lizhuang Ma. 2025. Real-IAD D3: A Real-World 2D/Pseudo-3D/3D Dataset for Industrial Anomaly Detection. InProceedings of the Computer Vision and ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.