RePlan-Bot: Multi-Level Replanning for Embodied Instruction Following
Pith reviewed 2026-06-29 21:19 UTC · model grok-4.3
The pith
RePlan-Bot achieves state-of-the-art results on the ALFRED benchmark by using continuous multi-level replanning to handle long tasks and irreversible changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
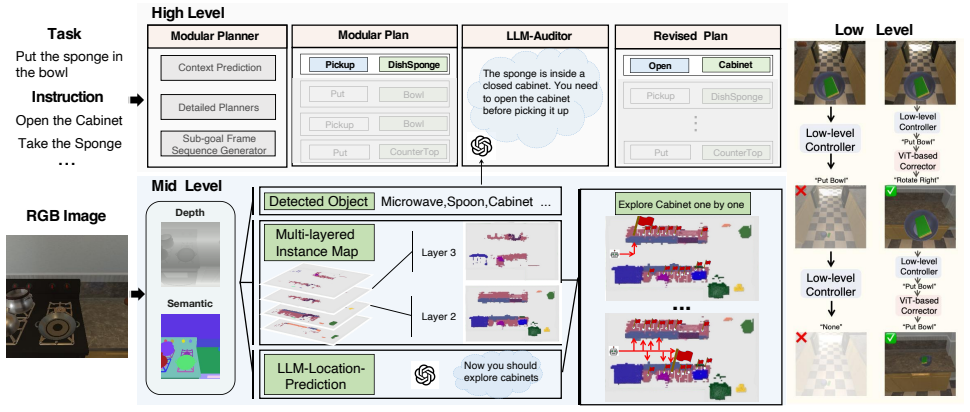
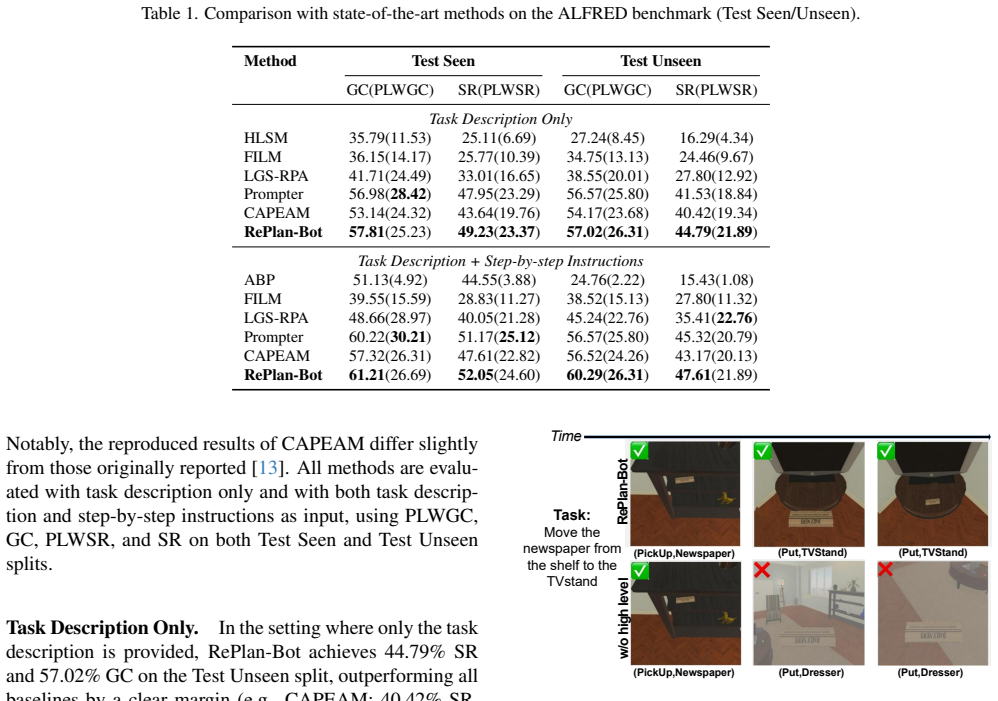
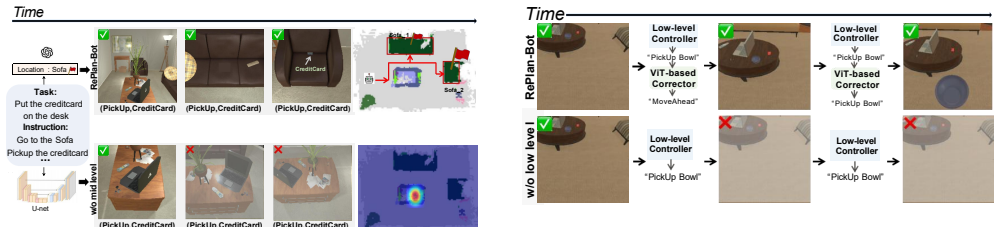
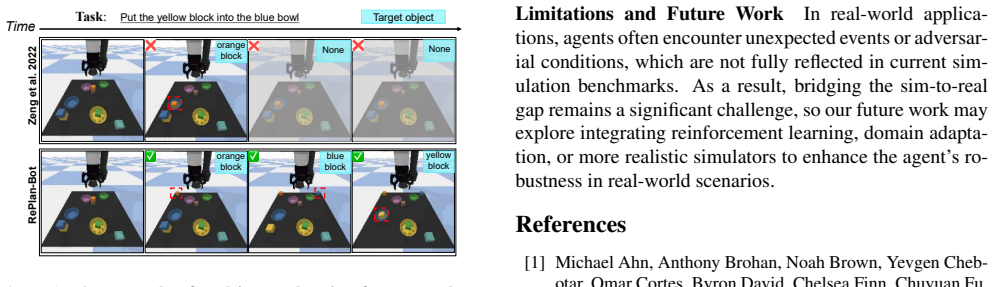
RePlan-Bot performs multi-level, continuous replanning throughout task execution. It integrates a high-level LLM-based auditor for dynamic sub-goal adjustments guided by environmental feedback, a commonsense-guided search mechanism based on a multi-layered instance map for precise object localization, and a lightweight ViT-based corrector to preemptively fix risky low-level actions, yielding state-of-the-art performance on the ALFRED benchmark in both seen and unseen environments.
What carries the argument
The multi-level replanning loop that couples an LLM auditor, a commonsense-guided multi-layered instance map search, and a ViT-based low-level corrector.
If this is right
- High-level sub-goals can be revised on the fly without restarting the entire plan.
- Object search becomes more structured and less prone to hallucination when guided by commonsense and layered maps.
- Low-level action errors are caught before execution, reducing the chance of permanent state damage.
- Performance gains hold in both seen and unseen rooms, pointing to improved robustness across environments.
Where Pith is reading between the lines
- The same layered replanning pattern could be tested on other embodied benchmarks that stress long sequences or irreversible effects.
- If the instance map remains compact, the approach might extend to larger or more cluttered scenes without proportional compute growth.
- Replacing the ViT corrector with a different vision model would isolate how much of the gain comes from the correction step versus the higher-level modules.
Load-bearing premise
The three components together will overcome the long-horizon planning failures and irreversible state changes that defeat existing methods.
What would settle it
A controlled test on an ALFRED-style task containing an irreversible action, such as pouring liquid that cannot be recovered, where the full RePlan-Bot pipeline still ends in failure at the same rate as prior single-level planners.
Figures



read the original abstract
Embodied instruction following (EIF) requires agents to understand and execute complex natural language commands within interactive 3D environments. Despite recent advances, existing methods often fail in long-horizon planning and handling irreversible state changes, resulting in low task success rates. To address these challenges, we introduce RePlan-Bot, a novel EIF agent that performs multi-level, continuous replanning throughout task execution. RePlan-Bot integrates a high-level LLM-based auditor for dynamic sub-goal adjustments guided by environmental feedback, a commonsense-guided search mechanism based on a multi-layered instance map for precise and structured object localization, and a lightweight ViT-based corrector to preemptively fix risky low-level actions. Evaluated on the ALFRED benchmark, RePlan-Bot achieves state-of-the-art performance in both seen and unseen environments, demonstrating superior adaptability and reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RePlan-Bot, an embodied instruction following (EIF) agent that performs multi-level continuous replanning. It integrates three components: a high-level LLM-based auditor for dynamic sub-goal adjustments based on environmental feedback, a commonsense-guided search mechanism using a multi-layered instance map for object localization, and a lightweight ViT-based corrector to preemptively fix risky low-level actions. The central claim is that this yields state-of-the-art performance on the ALFRED benchmark in both seen and unseen environments.
Significance. If the empirical results hold with proper validation, the multi-level replanning strategy could meaningfully advance EIF by mitigating failures in long-horizon planning and irreversible state changes. The explicit combination of LLM reasoning with structured commonsense mapping and vision correction is a timely integration of current techniques in embodied AI.
major comments (1)
- Abstract: The claim that RePlan-Bot 'achieves state-of-the-art performance in both seen and unseen environments' is presented without any quantitative results, baselines, error bars, ablation studies, or experimental protocol details. This directly undermines the central empirical contribution, as no evidence is supplied to support the SOTA assertion or the effectiveness of the three components in addressing the stated challenges.
Simulated Author's Rebuttal
We thank the referee for highlighting this issue with the abstract. We agree that the SOTA claim requires supporting quantitative details even in the abstract to strengthen the presentation of the central contribution.
read point-by-point responses
-
Referee: [—] Abstract: The claim that RePlan-Bot 'achieves state-of-the-art performance in both seen and unseen environments' is presented without any quantitative results, baselines, error bars, ablation studies, or experimental protocol details. This directly undermines the central empirical contribution, as no evidence is supplied to support the SOTA assertion or the effectiveness of the three components in addressing the stated challenges.
Authors: We agree with this observation. The current abstract states the SOTA result without numerical support, which is a presentational weakness. In the revised version we will expand the final sentence of the abstract to include the key quantitative results (success rates on seen and unseen splits of ALFRED, comparison to the strongest baselines, and brief mention of the three components' contributions), while preserving conciseness. The full experimental details, ablations, and protocol remain in the body of the paper. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical architecture for embodied instruction following consisting of an LLM auditor, commonsense-guided map search, and ViT corrector, with performance claims resting on ALFRED benchmark results in seen and unseen environments. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. The central SOTA claim follows from experimental evaluation rather than any self-definitional reduction or imported uniqueness theorem. This is the expected non-finding for a purely empirical systems paper without load-bearing mathematical steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Cheb- otar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
A persistent spatial semantic representation for high-level natural language instruction execution
Valts Blukis, Chris Paxton, Dieter Fox, Animesh Garg, and Yoav Artzi. A persistent spatial semantic representation for high-level natural language instruction execution. InConfer- ence on Robot Learning, pages 706–717. PMLR, 2022. 2
2022
-
[3]
Jiaqi Chen, Bingqian Lin, Ran Xu, Zhenhua Chai, Xi- aodan Liang, and Kwan-Yee K Wong. Mapgpt: Map- guided prompting with adaptive path planning for vision- and-language navigation.arXiv preprint arXiv:2401.07314,
-
[4]
Yaran Chen, Wenbo Cui, Yuanwen Chen, Mining Tan, Xinyao Zhang, Dongbin Zhao, and He Wang. Robogpt: an intelligent agent of making embodied long-term decisions for daily instruction tasks.arXiv preprint arXiv:2311.15649,
-
[5]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 2
2019
-
[6]
Embod- ied concept learner: Self-supervised learning of concepts and mapping through instruction following
Mingyu Ding, Yan Xu, Zhenfang Chen, David Daniel Cox, Ping Luo, Joshua B Tenenbaum, and Chuang Gan. Embod- ied concept learner: Self-supervised learning of concepts and mapping through instruction following. InConference on robot learning, pages 1743–1754. PMLR, 2023. 2
2023
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
Mask r-cnn
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn. InProceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017. 4
2017
-
[9]
Yuki Inoue and Hiroki Ohashi. Prompter: Utilizing large language model prompting for a data efficient embodied in- struction following.arXiv preprint arXiv:2211.03267, 2022. 1, 2, 3, 5
-
[10]
Object-centric world model for language-guided ma- nipulation, 2025
Youngjoon Jeong, Junha Chun, Soonwoo Cha, and Taesup Kim. Object-centric world model for language-guided ma- nipulation, 2025. 2 8
2025
-
[11]
Agent with the big picture: Perceiving surroundings for interactive instruction following
Byeonghwi Kim, Suvaansh Bhambri, Kunal Pratap Singh, Roozbeh Mottaghi, and Jonghyun Choi. Agent with the big picture: Perceiving surroundings for interactive instruction following. InEmbodied AI Workshop CVPR, page 12, 2021. 1, 2
2021
-
[12]
Context-aware planning and environment-aware memory for instruction following em- bodied agents
Byeonghwi Kim, Jinyeon Kim, Yuyeong Kim, Cheolhong Min, and Jonghyun Choi. Context-aware planning and environment-aware memory for instruction following em- bodied agents. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 10936–10946,
-
[13]
Pre-emptive action revision by environmen- tal feedback for embodied instruction following agents
Jinyeon Kim, Cheolhong Min, Byeonghwi Kim, and Jonghyun Choi. Pre-emptive action revision by environmen- tal feedback for embodied instruction following agents. In 8th Annual Conference on Robot Learning, 2024. 6
2024
-
[14]
Multi-modal grounded planning and efficient replanning for learning embodied agents with a few examples
Taewoong Kim, Byeonghwi Kim, and Jonghyun Choi. Multi-modal grounded planning and efficient replanning for learning embodied agents with a few examples. InAAAI,
-
[15]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Guanxing Lu, Ziwei Wang, Changliu Liu, Jiwen Lu, and Yansong Tang. Thinkbot: Embodied instruction fol- lowing with thought chain reasoning.arXiv preprint arXiv:2312.07062, 2023. 2
-
[17]
Multimodal procedural planning via dual text-image prompting.arXiv preprint arXiv:2305.01795, 2023
Yujie Lu, Pan Lu, Zhiyu Chen, Wanrong Zhu, Xin Eric Wang, and William Yang Wang. Multimodal procedural planning via dual text-image prompting.arXiv preprint arXiv:2305.01795, 2023. 2
-
[18]
Replanvlm: Replanning robotic tasks with visual lan- guage models, 2024
Aoran Mei, Guo-Niu Zhu, Huaxiang Zhang, and Zhongxue Gan. Replanvlm: Replanning robotic tasks with visual lan- guage models, 2024. 2
2024
-
[19]
So Yeon Min, Devendra Singh Chaplot, Pradeep Ravikumar, Yonatan Bisk, and Ruslan Salakhutdinov. Film: Follow- ing instructions in language with modular methods.arXiv preprint arXiv:2110.07342, 2021. 1, 2, 4, 5
-
[20]
Embodiedgpt: Vision-language pre-training via embodied chain of thought, 2023
Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. Embodiedgpt: Vision-language pre-training via embodied chain of thought, 2023. 2
2023
-
[21]
Following natural lan- guage instructions for household tasks with landmark guided search and reinforced pose adjustment.IEEE Robotics and Automation Letters, 7(3):6870–6877, 2022
Michael Murray and Maya Cakmak. Following natural lan- guage instructions for household tasks with landmark guided search and reinforced pose adjustment.IEEE Robotics and Automation Letters, 7(3):6870–6877, 2022. 1, 2, 5
2022
-
[22]
Van-Quang Nguyen, Masanori Suganuma, and Takayuki Okatani. Look wide and interpret twice: Improving per- formance on interactive instruction-following tasks.arXiv preprint arXiv:2106.00596, 2021. 2
-
[23]
Episodic transformer for vision-and-language navigation
Alexander Pashevich, Cordelia Schmid, and Chen Sun. Episodic transformer for vision-and-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15942–15952, 2021. 1, 2
2021
-
[24]
March in chat: Interactive prompting for remote embodied referring expression
Yanyuan Qiao, Yuankai Qi, Zheng Yu, Jing Liu, and Qi Wu. March in chat: Interactive prompting for remote embodied referring expression. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 15758– 15767, 2023. 2
2023
-
[25]
Planning with large language models via corrective re-prompting
Shreyas Sundara Raman, Vanya Cohen, Eric Rosen, Ifrah Idrees, David Paulius, and Stefanie Tellex. Planning with large language models via corrective re-prompting. In NeurIPS 2022 Foundation Models for Decision Making Workshop, 2022. 2
2022
-
[26]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015. 4
2015
-
[27]
A fast marching level set method for monotonically advancing fronts.Proceedings of the National Academy of Sciences, 93(4):1591–1595, 1996
James A Sethian. A fast marching level set method for monotonically advancing fronts.Proceedings of the National Academy of Sciences, 93(4):1591–1595, 1996. 5
1996
-
[28]
Lm- nav: Robotic navigation with large pre-trained models of lan- guage, vision, and action
Dhruv Shah, Bła ˙zej Osi ´nski, Sergey Levine, et al. Lm- nav: Robotic navigation with large pre-trained models of lan- guage, vision, and action. InConference on robot learning, pages 492–504. PMLR, 2023. 2
2023
-
[29]
Socratic planner: Inquiry-based zero-shot planning for embodied instruction following
Suyeon Shin, Sujin Jeon, Junghyun Kim, Gi-Cheon Kang, and Byoung-Tak Zhang. Socratic planner: Inquiry-based zero-shot planning for embodied instruction following. CoRR, 2024. 1
2024
-
[30]
Socratic planner: Self-qa-based zero-shot planning for embodied instruction following, 2025
Suyeon Shin, Sujin jeon, Junghyun Kim, Gi-Cheon Kang, and Byoung-Tak Zhang. Socratic planner: Self-qa-based zero-shot planning for embodied instruction following, 2025. 2
2025
-
[31]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740–10749, 2020. 1, 2, 5
2020
-
[32]
Progprompt: Generating situated robot task plans using large language models
Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. Progprompt: Generating situated robot task plans using large language models. In2023 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 11523–11530. IEEE, 2023. 2
2023
-
[33]
Replan: Robotic replanning with perception and language models.arXiv preprint arXiv:2401.04157, 2024
Marta Skreta, Zihan Zhou, Jia Lin Yuan, Kourosh Darvish, Al´an Aspuru-Guzik, and Animesh Garg. Replan: Robotic replanning with perception and language models.arXiv preprint arXiv:2401.04157, 2024. 2
-
[34]
One step at a time: Long-horizon vision-and-language navigation with milestones
Chan Hee Song, Jihyung Kil, Tai-Yu Pan, Brian M Sadler, Wei-Lun Chao, and Yu Su. One step at a time: Long-horizon vision-and-language navigation with milestones. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15482–15491, 2022. 2
2022
-
[35]
Llm-planner: Few-shot grounded planning for embodied agents with large language models
Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 2998–3009, 2023. 1, 2, 3
2023
-
[36]
Alessandro Suglia, Qiaozi Gao, Jesse Thomason, Govind Thattai, and Gaurav Sukhatme. Embodied bert: A trans- 9 former model for embodied, language-guided visual task completion.arXiv preprint arXiv:2108.04927, 2021. 1, 2
-
[37]
Instruction- augmented long-horizon planning: Embedding grounding mechanisms in embodied mobile manipulation
Fangyuan Wang, Shipeng Lyu, Peng Zhou, Anqing Duan, Guodong Guo, and David Navarro-Alarcon. Instruction- augmented long-horizon planning: Embedding grounding mechanisms in embodied mobile manipulation. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 14690–14698, 2025. 2
2025
-
[38]
Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xi- aojian Ma, and Yitao Liang. Describe, explain, plan and select: Interactive planning with large language mod- els enables open-world multi-task agents.arXiv preprint arXiv:2302.01560, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Embodied task planning with large language models
Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, and Haibin Yan. Embodied task planning with large language models. arXiv preprint arXiv:2307.01848, 2023. 2
-
[40]
Embod- ied instruction following in unknown environments.arXiv preprint arXiv:2406.11818, 2024
Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Hang Yin, Yinan Liang, Angyuan Ma, Jiwen Lu, and Haibin Yan. Embod- ied instruction following in unknown environments.arXiv preprint arXiv:2406.11818, 2024. 2
-
[41]
Yuxiao Yang, Shenao Zhang, Zhihan Liu, Huaxiu Yao, and Zhaoran Wang. Hindsight planner: A closed-loop few-shot planner for embodied instruction following.arXiv preprint arXiv:2412.19562, 2024. 1
-
[42]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in Neural Information Processing Systems, 37:5285–5307, 2024
Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, and Jiwen Lu. Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in Neural Information Processing Systems, 37:5285–5307, 2024. 2
2024
-
[43]
Takuma Yoneda, Jiading Fang, Peng Li, Huanyu Zhang, Tianchong Jiang, Shengjie Lin, Ben Picker, David Yunis, Hongyuan Mei, and Matthew R. Walter. Statler: State- maintaining language models for embodied reasoning, 2024. 2
2024
-
[44]
L3mvn: Leveraging large language models for visual target naviga- tion
Bangguo Yu, Hamidreza Kasaei, and Ming Cao. L3mvn: Leveraging large language models for visual target naviga- tion. In2023 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 3554–3560. IEEE,
-
[45]
Socratic mod- els: Composing zero-shot multimodal reasoning with lan- guage.arXiv, 2022
Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Choro- manski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, and Pete Florence. Socratic mod- els: Composing zero-shot multimodal reasoning with lan- guage.arXiv, 2022. 8
2022
-
[46]
Yichi Zhang and Joyce Chai. Hierarchical task learning from language instructions with unified transformers and self-monitoring.arXiv preprint arXiv:2106.03427, 2021. 2
-
[47]
Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models
Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7641–7649, 2024. 2
2024
-
[48]
Xizhou Zhu, Yuntao Chen, Hao Tian, Chenxin Tao, Weijie Su, Chenyu Yang, Gao Huang, Bin Li, Lewei Lu, Xiaogang Wang, Yu Qiao, Zhaoxiang Zhang, and Jifeng Dai. Ghost in the minecraft: Generally capable agents for open-world envi- ronments via large language models with text-based knowl- edge and memory.arXiv preprint arXiv:2305.17144, 2023. 2 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.