Explaining Too Much? Understanding How Large Language Model Reasoning Traces Influence Performance and Metacognition
Pith reviewed 2026-06-29 20:38 UTC · model grok-4.3
The pith
Exposing summarized reasoning traces from LLMs raises user trust and appeal without improving task performance or self-assessment accuracy, while full traces can reduce performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
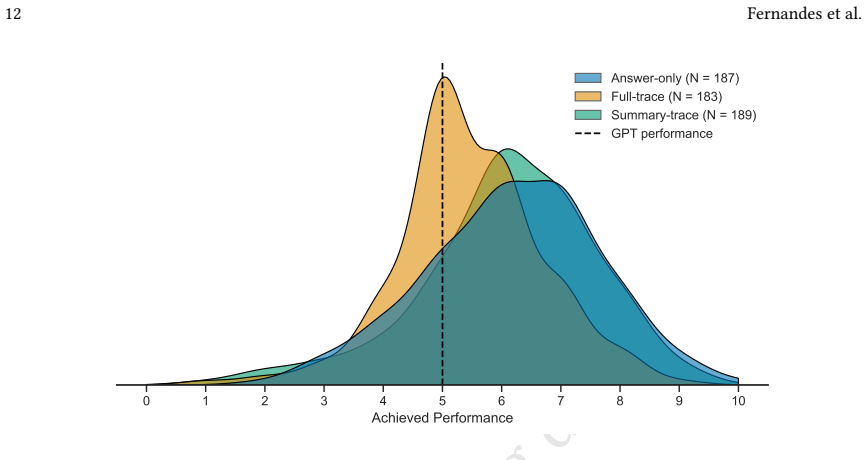
Reasoning traces function as user-facing interface artifacts that alter subjective appraisal rather than transparent windows into model cognition. Summaries preserve performance at the no-trace baseline while elevating trust and hedonic appeal. Full traces impair performance relative to answer-only under verbose open-weight models. Across conditions participants substantially overestimate their performance, and no trace format supports calibrated self-evaluation. Hedonic appeal, not trust, carries the indirect path to overestimation, consistent with a processing-fluency account.
What carries the argument
Between-subjects comparison of three trace formats (answer-only baseline, full trace revealed before answer, summary trace alongside answer) on LSAT-style reasoning problems, measuring objective performance, trust, hedonic appeal, and performance overestimation.
If this is right
- Summaries can be deployed to increase trust and appeal while maintaining baseline performance levels.
- Full verbose traces risk lowering accuracy when models produce lengthy intermediate steps.
- Trace exposure alone does not produce calibrated metacognition; users overestimate success in all formats.
- Hedonic appeal mediates the link between traces and overestimation via processing fluency.
- Traces are best treated as interface design choices rather than mechanisms for transparency or improved reasoning.
Where Pith is reading between the lines
- Interactions that first prompt users to generate their own reasoning before showing any trace could improve calibration where passive exposure does not.
- Effects observed on analytical logic tasks may differ for open-ended or creative tasks where fluency cues operate differently.
- Designers could test trace formats that deliberately reduce fluency to counteract overestimation.
- Longer-term use studies would reveal whether repeated exposure to summaries changes how users weigh model output over time.
Load-bearing premise
The assumption that LSAT-style reasoning problems and the chosen models and trace formats are representative enough for the observed effects on performance, trust, appeal, and metacognition to generalize to other real-world LLM use cases and user populations.
What would settle it
A replication using different problem domains such as arithmetic word problems or code debugging tasks that finds full traces improve accuracy or reduce overestimation would falsify the claim that traces do not support better performance or calibration.
Figures



read the original abstract
Large Language Model interfaces are increasingly verbose, exposing intermediate reasoning traces alongside final answers. Traces are framed as transparency mechanisms, yet it is unclear how people use them to solve problems. We report a preregistered between-subjects study (N = 559) in which participants solved ten LSAT-style reasoning problems under one of three conditions: an Answer-only baseline, a Full-trace revealed before the answer, and a Summary-trace presented alongside the answer. Summaries preserved task performance at the no-trace baseline while significantly elevating trust and hedonic appeal, establishing that trace exposure shifts subjective appraisal of the interaction without bringing performance benefits. Under an open-weight reasoning model exposing verbose intermediate output, full traces additionally impaired performance relative to the answer-only baseline. Across all conditions, participants substantially overestimated their performance, and no trace format supported calibrated self-evaluation. Further analysis indicates that hedonic appeal, not trust, carries the indirect path to overestimation, consistent with a processing-fluency account. Reasoning traces are best understood as user-facing interface artifacts rather than transparent windows into model cognition, and calibration is unlikely to emerge from the traces themselves and may best be scaffolded by interactions that elicit users' own reasoning first.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a preregistered between-subjects experiment (N=559) in which participants solved ten LSAT-style reasoning problems under answer-only, full-trace, or summary-trace conditions. It claims that summary traces preserve performance at the answer-only baseline while raising trust and hedonic appeal, that full traces impair performance under a verbose open-weight model, that participants overestimate performance across all conditions with no format yielding calibrated metacognition, and that hedonic appeal (via fluency) rather than trust mediates overestimation. The authors conclude that reasoning traces function primarily as interface artifacts rather than transparency mechanisms and that calibration requires external scaffolding.
Significance. If the directional effects hold after fuller reporting, the work supplies concrete evidence that trace exposure can decouple subjective appraisal from objective performance and metacognitive accuracy on closed reasoning tasks. The preregistered design and between-subjects structure are strengths that reduce certain confounds; the mediation analysis linking hedonic appeal to overestimation offers a testable processing-fluency account with direct implications for LLM interface design.
major comments (3)
- [Methods] Methods: The manuscript does not report the full set of exclusion criteria, exact participant demographics, or the preregistration identifier and analysis plan deviations, which are required to verify that the N=559 sample supports the reported directional effects on performance, trust, and metacognition.
- [Results] Results: Full statistical reporting (exact p-values, effect sizes, confidence intervals, and model specifications for the open-weight versus closed model comparisons) is absent, preventing independent assessment of whether the performance impairment under full traces and the trust/appeal elevations under summaries are robust.
- [Discussion] Discussion: The interpretive claim that traces are 'best understood as user-facing interface artifacts' and that 'calibration is unlikely to emerge from the traces themselves' extrapolates beyond the LSAT-style closed problems tested; the paper provides no direct evidence or boundary conditions for how effects might change on open-ended or domain-specific tasks where cognitive load or trace utility could differ.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below, indicating where we will revise the manuscript to improve transparency and scoping.
read point-by-point responses
-
Referee: [Methods] Methods: The manuscript does not report the full set of exclusion criteria, exact participant demographics, or the preregistration identifier and analysis plan deviations, which are required to verify that the N=559 sample supports the reported directional effects on performance, trust, and metacognition.
Authors: We agree these details are essential for verification. The revised Methods section will include the full preregistration identifier and link, a complete table listing all exclusion criteria with counts, exact demographic statistics (age, gender, education, AI familiarity with means/SDs), and an explicit statement of any analysis plan deviations. These additions will allow direct assessment of the sample supporting the directional effects. revision: yes
-
Referee: [Results] Results: Full statistical reporting (exact p-values, effect sizes, confidence intervals, and model specifications for the open-weight versus closed model comparisons) is absent, preventing independent assessment of whether the performance impairment under full traces and the trust/appeal elevations under summaries are robust.
Authors: We acknowledge the need for complete reporting. The revision will add exact p-values, effect sizes (with interpretations), 95% confidence intervals for all primary comparisons, and full model specifications (including regression details) for the open-weight versus closed model analyses, either in the main Results or a new supplementary table. revision: yes
-
Referee: [Discussion] Discussion: The interpretive claim that traces are 'best understood as user-facing interface artifacts' and that 'calibration is unlikely to emerge from the traces themselves' extrapolates beyond the LSAT-style closed problems tested; the paper provides no direct evidence or boundary conditions for how effects might change on open-ended or domain-specific tasks where cognitive load or trace utility could differ.
Authors: We accept the need to tighten scoping. We will revise the Discussion to explicitly limit claims to the LSAT-style closed tasks tested, add a limitations paragraph outlining potential boundary conditions (e.g., higher trace utility on open-ended tasks due to cognitive load differences), and frame the interface-artifact interpretation as supported within this paradigm while calling for future work on other task types. The core evidence-based conclusions will remain but with added caution. revision: partial
Circularity Check
No circularity: direct empirical reporting of preregistered experiment
full rationale
The paper reports results from a between-subjects experiment (N=559) with three conditions on LSAT-style problems. All central claims (performance preservation under summaries, impairment under full traces, overestimation across conditions, mediation via hedonic appeal) are direct statistical outcomes from participant data. No equations, parameter fitting presented as prediction, self-definitional constructs, or load-bearing self-citations appear. The derivation chain is absent; results are measurements, not reductions to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LSAT-style problems admit objective correctness scoring independent of the trace format.
- domain assumption Between-subjects random assignment isolates the causal effect of trace format on the measured outcomes.
Forward citations
Cited by 1 Pith paper
-
When LLM Rationales Become User-Facing: Effects on Trust Perception, Decision-Making, and Gaze Behaviors
Two linked user studies find that LLM rationale correctness and certainty framing affect trust and decision confidence while presentation format does not, and incorrect rationales increase gaze attention and pupil size.
Reference graph
Works this paper leans on
-
[1]
Rakefet Ackerman and Valerie A. Thompson. 2017. Meta-Reasoning: Monitoring and Control of Thinking and Reasoning.Trends in Cognitive Sciences21, 8 (2017), 607–617. doi:10.1016/j.tics.2017.05.004
-
[2]
Catherine Alberola, Götz Walter, and Henning Brau. 2018. Creation of a short version of the user experience questionnaire UEQ.i-com17, 1 (2018), 57–64. doi:10.1515/icom-2017-0032
-
[3]
Alter and Daniel M Oppenheimer
Adam L. Alter and Daniel M Oppenheimer. 2009. Uniting the tribes of fluency to form a metacognitive nation.Personality and social psychology review13, 3 (2009), 219–235. doi:10.1177/1088868309341564
-
[4]
Adam L. Alter, Daniel M. Oppenheimer, Nicholas Epley, and Rebecca N. Eyre. 2007. Overcoming intuition: Metacognitive difficulty activates analytic reasoning.Journal of Experimental Psychology: General136, 4 (2007), 569–576. doi:10.1037/0096-3445.136.4.569
-
[5]
Anthropic. 2025. Claude’s Extended Thinking. https://www.anthropic.com/news/visible-extended-thinking. Accessed: 2026-05-01
2025
-
[6]
Anthropic. 2025. The “Think” Tool: Enabling Claude to Stop and Think. https://www.anthropic.com/engineering/claude-think-tool. Accessed: 2026-05-01
2025
-
[7]
World Medical Association et al. 2013. World Medical Association Declaration of Helsinki: ethical principles for medical research involving human subjects.Jama310, 20 (2013), 2191–2194. doi:10.1001/jama.2013.281053
-
[8]
Aaron Bangor, Philip T Kortum, and James T Miller. 2008. An empirical evaluation of the system usability scale.Intl. Journal of Human–Computer Interaction24, 6 (2008), 574–594. doi:10.1080/10447310802205776
-
[9]
Gagan Bansal, Tongshuang Wu, Joyce Zhou, Raymond Fok, Besmira Nushi, Ece Kamar, Marco Tulio Ribeiro, and Daniel Weld. 2021. Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems(Yokohama, Japan)(CHI ’21). Association for Computing Mac...
-
[10]
Fazl Barez, Tung-Yu Wu, Iván Arcuschin, Michael Lan, Vincent Wang, Noah Siegel, Nicolas Collignon, Clement Neo, Isabelle Lee, Alasdair Paren, et al
-
[11]
https://aigi.ox.ac.uk/publications/chain-of-thought-is-not-explainability/
Chain-of-thought is not explainability.Preprint, alphaXiv(2025), v1. https://aigi.ox.ac.uk/publications/chain-of-thought-is-not-explainability/
2025
-
[12]
Hamsa Bastani, Osbert Bastani, Alp Sungu, Haosen Ge, Özge Kabakcı, and Rei Mariman. 2024. Generative AI Can Harm Learning.A vailable at SSRN 48954864895486 (2024). doi:10.2139/ssrn.4895486
-
[13]
Astrid Bertrand, Rafik Belloum, James R. Eagan, and Winston Maxwell. 2022. How Cognitive Biases Affect XAI-assisted Decision-making: A Systematic Review. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society(Oxford, United Kingdom)(AIES ’22). Association for Computing Machinery, New York, NY, USA, 78–91. doi:10.1145/3514094.3534164
-
[14]
John Brooke et al. 1996. SUS-A quick and dirty usability scale.Usability evaluation in industry189, 194 (1996), 4–7. https://digital.ahrq.gov/sites/ default/files/docs/survey/systemusabilityscale%2528sus%2529_comp%255B1%255D.pdf
1996
-
[15]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z. Gajos. 2021. To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI-assisted Decision-making.Proc. ACM Hum.-Comput. Interact.5, CSCW1, Article 188 (April 2021), 21 pages. doi:10.1145/3449287
work page internal anchor Pith review doi:10.1145/3449287 2021
-
[16]
Paluch, Finale Doshi-Velez, and Krzysztof Z
Zana Buçinca, Siddharth Swaroop, Amanda E. Paluch, Finale Doshi-Velez, and Krzysztof Z. Gajos. 2025. Contrastive Explanations That Anticipate Human Misconceptions Can Improve Human Decision-Making Skills. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Articl...
-
[17]
Victoria Clarke and Virginia Braun. 2017. Thematic analysis.The journal of positive psychology12, 3 (2017), 297–298. doi:10.1080/17439760.2016. 1262613
-
[18]
Clara Colombatto and Stephen Fleming. 2023. Illusions of confidence in artificial systems. (09 2023). doi:10.31234/osf.io/mjx2v
-
[19]
Clara Colombatto, Sean Rintel, and Lev Tankelevitch. 2025. Metacognition and Confidence Dynamics in Advice Taking from Generative AI.arXiv preprint arXiv:2510.26508(2025). doi:10.48550/arXiv.2510.26508 Preprint 2026-05-26 02:19. Page 24 of 1–27. Unpublished working draft.Not for distribution. Explaining Too Much? Understanding How Large Language Model Rea...
- [20]
-
[21]
Fiona Draxler, Anna Werner, Florian Lehmann, Matthias Hoppe, Albrecht Schmidt, Daniel Buschek, and Robin Welsch. 2024. The AI Ghostwriter Effect: When Users do not Perceive Ownership of AI-Generated Text but Self-Declare as Authors.ACM Trans. Comput.-Hum. Interact.31, 2, Article 25 (2 2024), 40 pages. doi:10.1145/3637875
-
[22]
Malin Eiband, Daniel Buschek, Alexander Kremer, and Heinrich Hussmann. 2019. The impact of placebic explanations on trust in intelligent systems. InExtended abstracts of the 2019 CHI conference on human factors in computing systems. 1–6. doi:10.1145/3290607.3312787
-
[23]
Douglas C Engelbart. 1962. Augmenting human intellect: A conceptual framework.Menlo Park, CA(1962), 21
1962
-
[24]
Daniela Fernandes, Steeven Villa, Salla Nicholls, Otso Haavisto, Daniel Buschek, Albrecht Schmidt, Thomas Kosch, Chenxinran Shen, and Robin Welsch. 2026. AI makes you smarter but none the wiser: The disconnect between performance and metacognition.Computers in Human Behavior 175 (2026), 108779. doi:10.1016/j.chb.2025.108779
-
[25]
Klaus Fiedler, Rakefet Ackerman, and Chiara Scarampi. 2019. Metacognition: Monitoring and Controlling One’s Own Knowledge, Reasoning and Decisions. InThe Psychology of Human Thought: An Introduction, Robert J. Sternberg and Joachim Funke (Eds.). Heidelberg University Publishing, 89–111. doi:10.17885/heiup.470.c6669
-
[26]
Matthew Fisher and Daniel M Oppenheimer. 2021. Harder than you think: How outside assistance leads to overconfidence.Psychological Science32, 4 (2021), 598–610. doi:10.1177/0956797620975779
-
[27]
Stephen Fleming. 2024. Metacognition and confidence: A review and synthesis.Annual Review of Psychology75 (2024), 241–268. doi:10.1146/annurev- psych-022423-032425
-
[28]
Alon Jacovi and Yoav Goldberg. 2020. Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness?. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 4198–4205. ...
-
[29]
Johnson, Shahin Hashtroudi, and D
Marcia K. Johnson, Shahin Hashtroudi, and D. Stephen Lindsay. 1993. Source monitoring.Psychological Bulletin114, 1 (1993), 3–28. doi:10.1037/0033- 2909.114.1.3 Publisher: American Psychological Association (APA)
-
[30]
Daniel Martin Katz, Michael James Bommarito, Shang Gao, and Pablo Arredondo. 2024. Gpt-4 passes the bar exam.Philosophical Transactions of the Royal Society A382, 2270 (2024), 20230254. doi:10.1098/rsta.2023.0254
-
[31]
William L. Kelemen, Peter J. Frost, and Charles A. Weaver. 2000. Individual differences in metacognition: Evidence against a general metacognitive ability.Memory & Cognition28, 1 (Jan. 2000), 92–107. doi:10.3758/BF03211579
-
[32]
Sunnie S. Y. Kim, Q. Vera Liao, Mihaela Vorvoreanu, Stephanie Ballard, and Jennifer Wortman Vaughan. 2024. "I’m Not Sure, But... ": Examining the Impact of Large Language Models’ Uncertainty Expression on User Reliance and Trust. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency(Rio de Janeiro, Brazil)(FAccT ’24). Asso...
-
[33]
AI enhances our performance, I have no doubt this one will do the same
Agnes Mercedes Kloft, Robin Welsch, Thomas Kosch, and Steeven Villa. 2024. "AI enhances our performance, I have no doubt this one will do the same": The Placebo effect is robust to negative descriptions of AI. InProceedings of the CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA)(Chi ’24). Association for Computing Machinery, New Yo...
-
[34]
If the Machine Is As Good As Me, Then What Use Am I?
Charlotte Kobiella, Yarhy Said Flores López, Franz Waltenberger, Fiona Draxler, and Albrecht Schmidt. 2024. "If the Machine Is As Good As Me, Then What Use Am I?" – How the Use of ChatGPT Changes Young Professionals’ Perception of Productivity and Accomplishment. InProceedings of the CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(...
-
[35]
Thomas Kosch, Robin Welsch, Lewis Chuang, and Albrecht Schmidt. 2023. The Placebo Effect of Artificial Intelligence in Human–Computer Interaction.ACM Transactions on Computer-Human Interaction29, 6 (2023), 1–32. doi:10.1145/3529225
-
[36]
Todd Kulesza, Simone Stumpf, Margaret Burnett, Sherry Yang, Irwin Kwan, and Weng-Keen Wong. 2013. Too much, too little, or just right? Ways explanations impact end users’ mental models. In2013 IEEE Symposium on Visual Languages and Human Centric Computing. 3–10. doi:10.1109/ VLHCC.2013.6645235
-
[37]
Jack Lindsey, Wes Gurnee, Emmanuel Ameisen, Brian Chen, Adam Pearce, Nicholas L. Turner, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
2025
-
[38]
Tim Miller. 2019. Explanation in artificial intelligence: Insights from the social sciences.Artificial Intelligence267 (2019), 1–38. doi:10.1016/j.artint. 2018.07.007
-
[39]
Mahsan Nourani, Chiradeep Roy, Jeremy E Block, Donald R Honeycutt, Tahrima Rahman, Eric Ragan, and Vibhav Gogate. 2021. Anchoring Bias Affects Mental Model Formation and User Reliance in Explainable AI Systems. InProceedings of the 26th International Conference on Intelligent User Interfaces(College Station, TX, USA)(IUI ’21). Association for Computing Ma...
-
[40]
OpenAI. 2024. Learning to Reason with LLMs. https://openai.com/index/learning-to-reason-with-llms/. Accessed: 2026-05-01
2024
-
[41]
OpenAI. 2025. Evaluating Chain-of-Thought Monitorability. https://openai.com/index/evaluating-chain-of-thought-monitorability/. Accessed: 2026-05-01. 2026-05-26 02:19. Page 25 of 1–27. Preprint Unpublished working draft.Not for distribution. 26 Fernandes et al
2025
-
[42]
Janet Rafner, Dominik Dellermann, Arthur Hjorth, Dora Veraszto, Constance Kampf, Wendy MacKay, and Jacob Sherson. 2022. Deskilling, upskilling, and reskilling: a case for hybrid intelligence.Morals & Machines1, 2 (2022), 24–39. doi:10.5771/2747-5174-2021-2-24
-
[43]
Dobromir Rahnev. 2025. A comprehensive assessment of current methods for measuring metacognition.Nature Communications16, 1 (2025), 701. doi:10.1038/s41467-025-56117-0
-
[44]
Shri Harini Ramesh, Foroozan Daneshzand, Babak Rashidi, Shriti Raj, Hariharan Subramonyam, and Fateme Rajabiyazdi. 2026. Metacognitive Demands and Strategies While Using Off-The-Shelf AI Conversational Agents for Health Information Seeking. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI ’26). Association for Computing ...
-
[45]
Leonid Rozenblit and Frank Keil. 2002. The misunderstood limits of folk science: an illusion of explanatory depth.Cognitive Science26, 5 (2002), 521–562. https://www.sciencedirect.com/science/article/pii/S0364021302000782
2002
-
[46]
Marjorie M Shultz and Sheldon Zedeck. 2011. Predicting lawyer effectiveness: Broadening the basis for law school admission decisions.Law & Social Inquiry36, 3 (2011), 620–661. doi:10.1111/j.1747-4469.2011.01245.x
-
[47]
Chenglei Si, Navita Goyal, Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daumé Iii, and Jordan Boyd-Graber. 2024. Large Language Models Help Humans Verify Truthfulness – Except When They Are Convincingly Wrong. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume...
-
[48]
Sidra Sidra and Claire Mason. 2026. Generative AI in Human-AI Collaboration: Validation of the Collaborative AI Literacy and Collaborative AI Metacognition Scales for Effective Use.International Journal of Human–Computer Interaction42, 7 (2026), 5084–5108. doi:10.1080/10447318.2025. 2543997
-
[49]
Matthias Stadler, Maria Bannert, and Michael Sailer. 2024. Cognitive ease at a cost: LLMs reduce mental effort but compromise depth in student scientific inquiry.Computers in Human Behavior160 (2024), 108386. doi:10.1016/j.chb.2024.108386
-
[50]
Mark Steyvers, Heliodoro Tejeda, Gavin Kerrigan, and Padhraic Smyth. 2022. Bayesian modeling of human–AI complementarity.Proceedings of the National Academy of Sciences119, 11 (March 2022), e2111547119. doi:10.1073/pnas.2111547119 Publisher: Proceedings of the National Academy of Sciences
-
[51]
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, et al. 2025. Stop overthinking: A survey on efficient reasoning for large language models.arXiv preprint arXiv:2503.16419(2025). doi:10.48550/arXiv.2503.16419
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.16419 2025
-
[52]
Lev Tankelevitch, Elena L Glassman, Jessica He, Aniket Kittur, Mina Lee, Srishti Palani, Advait Sarkar, Gonzalo Ramos, Yvonne Rogers, and Hari Subramonyam. 2025. Understanding, Protecting, and Augmenting Human Cognition with Generative AI: A Synthesis of the CHI 2025 Tools for Thought Workshop.arXiv preprint arXiv:2508.21036(2025). doi:10.48550/arXiv.2508.21036
-
[53]
Lev Tankelevitch, Viktor Kewenig, Auste Simkute, Ava Elizabeth Scott, Advait Sarkar, Abigail Sellen, and Sean Rintel. 2024. The Metacognitive Demands and Opportunities of Generative AI. InProceedings of the CHI Conference on Human Factors in Computing Systems, Vol. 57. ACM, 1–24. doi:10.1145/3613904.3642902
-
[54]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Language models don’t always say what they think: unfaithful explanations in chain-of-thought prompting. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA) (NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 3275...
2023
-
[55]
Michelle Vaccaro, Abdullah Almaatouq, and Thomas Malone. 2024. When combinations of humans and AI are useful: A systematic review and meta-analysis.Nature Human Behaviour(2024), 1–11. doi:10.1038/s41562-024-02024-1
-
[56]
Helena Vasconcelos, Matthew Jörke, Madeleine Grunde-McLaughlin, Tobias Gerstenberg, Michael S Bernstein, and Ranjay Krishna. 2023. Explanations can reduce overreliance on ai systems during decision-making.Proceedings of the ACM on Human-Computer Interaction7, Cscw1 (2023), 1–38. doi:10.1145/3579605
-
[57]
Steeven Villa, Thomas Kosch, Felix Grelka, Albrecht Schmidt, and Robin Welsch. 2023. The placebo effect of human augmentation: Anticipating cognitive augmentation increases risk-taking behavior.Computers in Human Behavior146 (2023), 107787. doi:10.1016/j.chb.2023.107787
-
[58]
Moritz Von Zahn, Lena Liebich, Ekaterina Jussupow, Oliver Hinz, and Kevin Bauer. 2025. Knowing (Not) to Know: Explainable Artificial Intelligence and Human Metacognition.Information Systems Research(2025), isre.2024.1431. doi:10.1287/isre.2024.1431
-
[59]
Howard Wainer. 1995. Precision and differential item functioning on a testlet-based test: The 1991 Law School Admissions Test as an example. Applied Measurement in Education8, 2 (1995), 157–86. doi:10.1207/s15324818ame0802_4
-
[60]
Xinru Wang and Ming Yin. 2021. Are Explanations Helpful? A Comparative Study of the Effects of Explanations in AI-Assisted Decision-Making. 318–328. doi:10.1145/3397481.3450650
-
[61]
Tim Zindulka, Sven Goller, Daniela Fernandes, Robin Welsch, and Daniel Buschek. 2026. The AI Memory Gap: Users Misremember What They Created With AI or Without. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems(Barcelona, Spain)(CHI ’26). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3772318.3791494
-
[62]
Wazeer Deen Zulfikar, Samantha Chan, and Pattie Maes. 2024. Memoro: Using Large Language Models to Realize a Concise Interface for Real-Time Memory Augmentation. InProceedings of the CHI Conference on Human Factors in Computing Systems (Chi ’24). Association for Computing Machinery, New York, NY, USA, 1–18. doi:10.1145/3613904.3642450 Preprint 2026-05-26 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.