When LLM Rationales Become User-Facing: Effects on Trust Perception, Decision-Making, and Gaze Behaviors
Pith reviewed 2026-06-25 20:21 UTC · model grok-4.3
The pith
Incorrect LLM rationales lower trust in the system more than showing no rationale, while drawing extra attention to evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
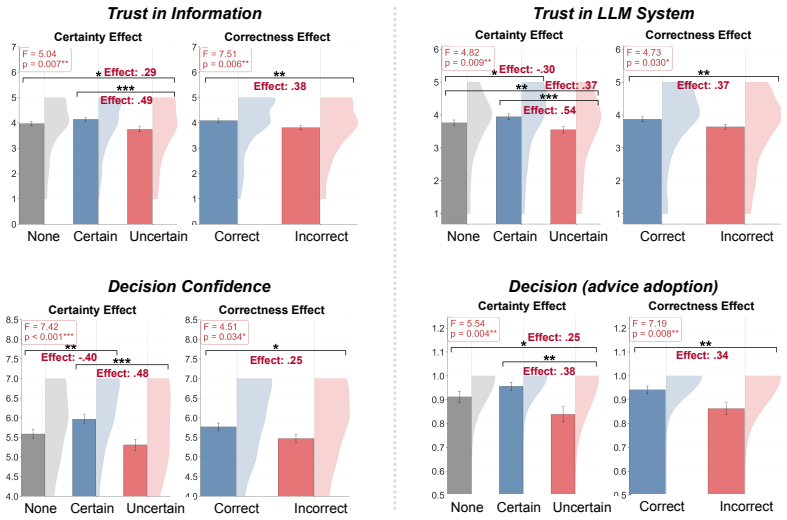
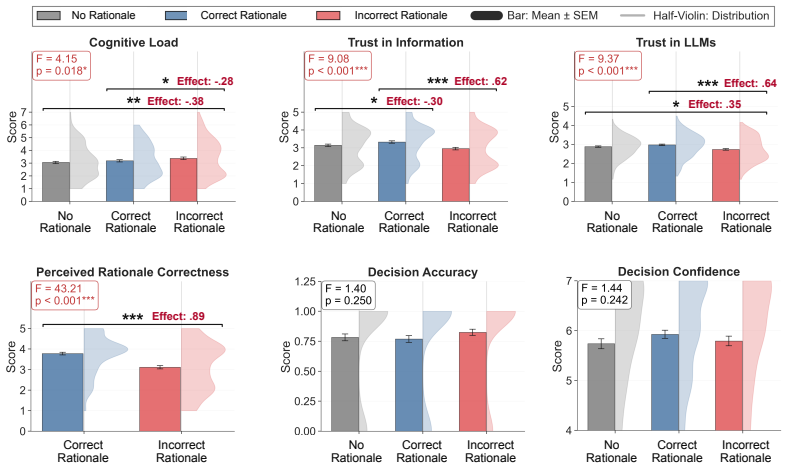
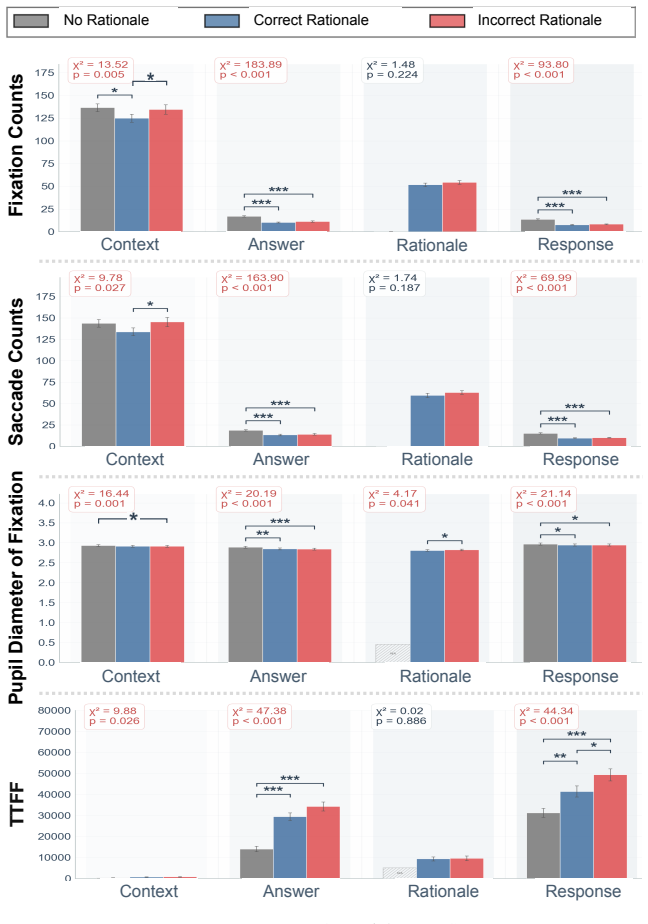
Rationale correctness and certainty framing influenced the trust in the information, trust in the LLM system, and decision confidence. Incorrect rationales drew more attention to the supporting evidence and larger pupil diameter while the rationale was viewed. Incorrect rationales also lowered trust in LLM system relative to showing no rationale, whereas the no-rationale difference was weaker for trust in information.
What carries the argument
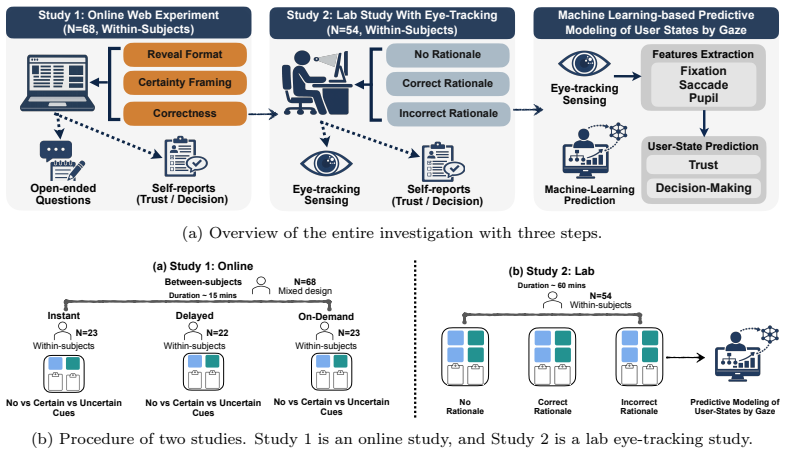
Experimental manipulation of rationale correctness (correct versus incorrect), certainty framing (none, certain, uncertain), and presentation format (instant, delayed, on demand), measured with self-report scales and eye-tracking metrics of gaze allocation and pupil diameter.
If this is right
- Rationale presentation format produces no reliable effects on trust or decisions compared with correctness and framing.
- Incorrect rationales reduce trust in the LLM system more sharply than omitting the rationale entirely.
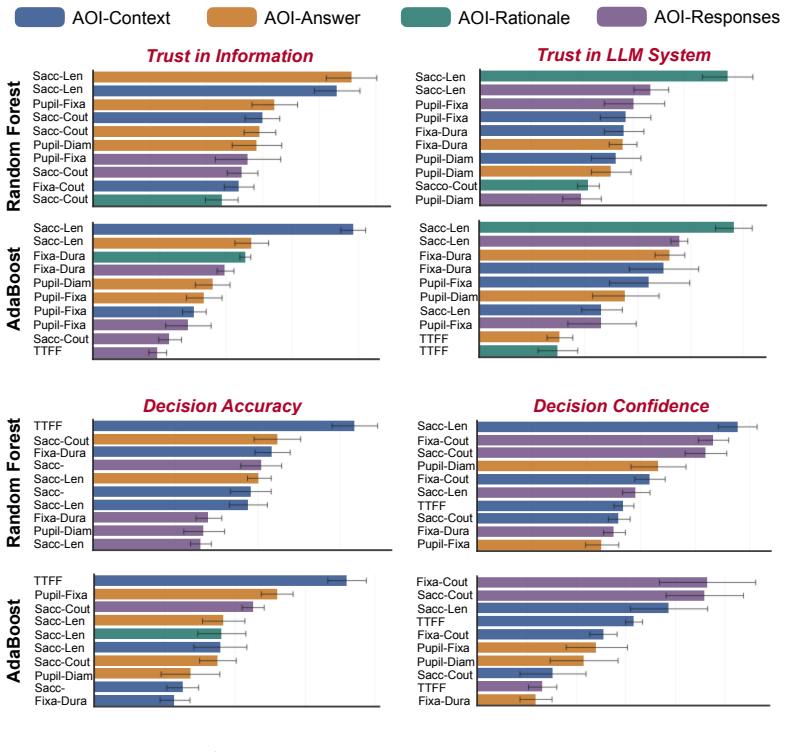
- Gaze features from eye tracking carry predictive information about users' trust and decision states.
- Designs should favor rationales that are selective, linked to verifiable evidence, and explicit about certainty.
Where Pith is reading between the lines
- Real-time gaze monitoring could allow interfaces to adapt whether to show or hide a rationale based on detected user effort.
- The pattern may extend to other explanation-heavy AI settings where users must decide whether to accept an output.
- Training models to generate only easily verifiable rationales could improve calibration without increasing overall explanation volume.
Load-bearing premise
Self-reported trust scores and eye-tracking measures such as pupil size and gaze patterns accurately reflect users' actual trust and cognitive effort in the factual verification task.
What would settle it
A replication study that finds no reliable difference in trust ratings or pupil dilation between correct-rationale and incorrect-rationale conditions would undermine the central results.
Figures


read the original abstract
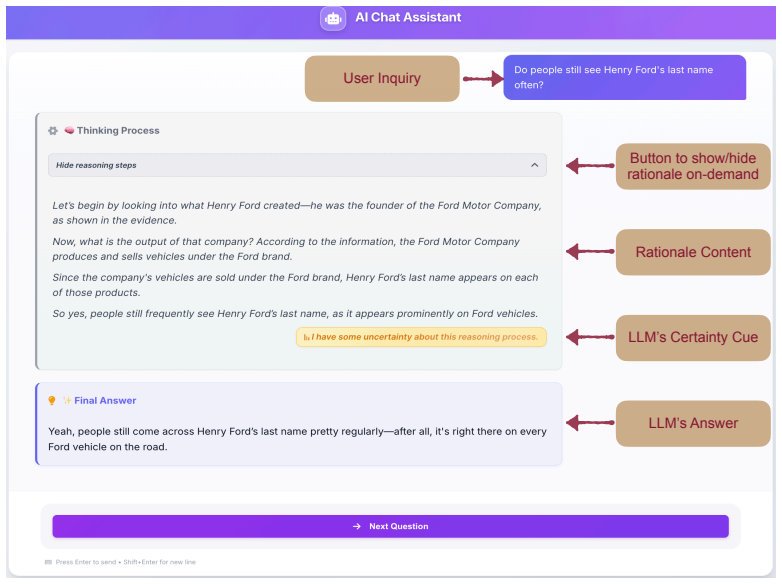
Large language models (LLMs) increasingly show step-by-step reasoning rationales alongside their answers, turning reasoning from an internal model capability into a user-facing interface feature. Yet it is unclear whether such rationales help users judge when trust is warranted or merely persuade through fluent reasoning. We address this gap through the lens of auditable trust calibration: user-facing rationales should help people inspect whether an answer is warranted by evidence. We test this framing in factual verification through two linked studies. Study 1, an online experiment (N=68), manipulated rationale presentation format (instant, delayed, on demand), rationale correctness (correct, incorrect), and certainty framing (none, certain, uncertain). Study 2, a controlled eye-tracking study (N=54), examined how no-, correct-, and incorrect-rationale conditions were associated with users' trust, decision-making, and eye-movement patterns. Study 1 showed no reliable presentation-format effects; instead, rationale correctness and certainty framing influenced the trust in the information, trust in the LLM system, and decision confidence. In Study 2, incorrect rationales drew more attention to the supporting evidence and larger pupil diameter while the rationale was viewed, consistent with greater cognitive effort. Incorrect rationales also lowered trust in LLM system relative to showing no rationale, whereas the no-rationale difference was weaker for trust in information. A post-hoc predictive modeling analysis of gaze data from Study 2 further showed that gaze features carried predictive signal for trust- and decision-related user states. This work challenges the assumption that more reasoning is always better and supports rationale designs that are selective, linked to evidence, calibrated in how they express certainty, and easier to verify.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in factual verification tasks, LLM rationale correctness and certainty framing affect users' trust in the information, trust in the LLM system, and decision confidence, while presentation format (instant/delayed/on-demand) shows no reliable effects. In an eye-tracking study, incorrect rationales drew more attention to supporting evidence, produced larger pupil diameter, lowered system trust relative to no-rationale conditions, and gaze features carried predictive signal for trust/decision states. The work concludes that rationales should be selective, evidence-linked, and certainty-calibrated rather than always providing more reasoning.
Significance. If the results hold, this contributes empirical multi-method evidence (online experiment + eye-tracking) to HCI on how user-facing LLM rationales shape trust calibration and cognitive effort. The post-hoc predictive modeling of gaze data is a clear strength, demonstrating that eye-movement features can forecast user states and opening avenues for adaptive interfaces. It supplies concrete design implications against the assumption that more reasoning is always better.
major comments (1)
- [Study 2] Study 2 results and discussion: the claim that incorrect rationales produce greater cognitive effort (via larger pupil diameter and increased gaze on evidence) and altered trust calibration rests on unanchored proxies. No independent behavioral measure (e.g., decision accuracy, Brier score on factual items, or willingness-to-act) is reported to validate that the metric shifts reflect the intended psychological constructs rather than luminance, arousal, or visual salience.
minor comments (1)
- [Abstract] Abstract: reports no effect sizes, confidence intervals, p-values, or power analysis, which is a presentation shortcoming that makes the strength of the reported influences difficult to assess from the summary.
Simulated Author's Rebuttal
Thank you for the referee's detailed and constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Study 2] Study 2 results and discussion: the claim that incorrect rationales produce greater cognitive effort (via larger pupil diameter and increased gaze on evidence) and altered trust calibration rests on unanchored proxies. No independent behavioral measure (e.g., decision accuracy, Brier score on factual items, or willingness-to-act) is reported to validate that the metric shifts reflect the intended psychological constructs rather than luminance, arousal, or visual salience.
Authors: We thank the referee for highlighting this limitation in our interpretation of the eye-tracking data. Study 2 was designed to link rationale conditions to self-reported trust, decision confidence, and gaze/pupil metrics; the latter were interpreted as proxies for cognitive effort and attention allocation. We agree that these proxies would be more robust if anchored to independent behavioral outcomes. Although decision accuracy was recorded as part of the factual verification task, it was not analyzed or reported in the original manuscript. In the revision we will add (1) descriptive statistics and condition comparisons for decision accuracy and (2) exploratory correlations between accuracy, trust, and the gaze/pupil measures. We will also expand the discussion to acknowledge alternative explanations such as visual salience or luminance and to qualify the strength of the cognitive-effort claims accordingly. revision: yes
Circularity Check
No circularity: purely empirical user studies with no derivations, equations, or fitted predictions
full rationale
The paper reports two linked empirical studies (online experiment N=68; eye-tracking N=54) that manipulate rationale presentation, correctness, and certainty framing, then measure self-reported trust, decision confidence, and eye-tracking metrics. No mathematical derivations, equations, parameters fitted to subsets of data, or predictions that reduce to inputs by construction appear in the abstract or described methods. The post-hoc predictive modeling of gaze data is a standard statistical analysis, not a self-referential claim. Self-citations, if present, are not load-bearing for any central result. The work is self-contained against external benchmarks as an empirical investigation; no step reduces to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-reported trust and confidence scales accurately reflect users' internal states in factual verification tasks
- domain assumption Pupil diameter and gaze duration reliably indicate cognitive effort when viewing rationales
Reference graph
Works this paper leans on
-
[1]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, D. Zhou, Chain-of-thought prompting elicits reasoning in large language models (2023). arXiv:2201.11903. URL https://arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2023
-
[2]
F. Xu, Q. Hao, Z. Zong, J. Wang, Y. Zhang, J. Wang, X. Lan, J. Gong, T. Ouyang, F. Meng, C. Shao, Y. Yan, Q. Yang, Y. Song, S. Ren, X. Hu, Y. Li, J. Feng, C. Gao, Y. Li, Towards large reasoning models: A survey of reinforced reasoning with large language models (2025). arXiv:2501.09686. URL https://arxiv.org/abs/2501.09686
Pith/arXiv arXiv 2025
-
[3]
C. Chen, X. Zhao, Let’s think step by step: Effects of chain-of-thought prompt coaching on users’ perceptions and trust in image generative ai tools, International Journal of Human–Computer Interaction (2025). doi:10.1080/10447318.2025.2530762. URL https://doi.org/10.1080/10447318.2025.2530762
-
[4]
R. R. Hoffman, M. Johnson, J. M. Bradshaw, A. Underbrink, Trust in automation, IEEE Intelligent Systems 28 (1) (2013) 84–88. doi:10.1109/MIS.2013.24. URL https://doi.org/10.1109/MIS.2013.24
-
[5]
M. Wischnewski, N. Krämer, E. Müller, Measuring and understand- ing trust calibrations for automated systems: A survey of the state-of- the-art and future directions, in: Proceedings of the 2023 CHI Con- ference on Human Factors in Computing Systems, CHI ’23, Associa- tion for Computing Machinery, New York, NY, USA, 2023, pp. 1–16. doi:10.1145/3544548.358...
-
[6]
Turpin, J
M. Turpin, J. Michael, E. Perez, S. R. Bowman, Language models don’t always say what they think: unfaithful explanations in chain-of-thought prompting, in: Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA, 2023, pp. 1–14. 46
2023
-
[7]
A. Madsen, S. Chandar, S. Reddy, Are self-explanations from large lan- guage models faithful?, in: L.-W. Ku, A. Martins, V. Srikumar (Eds.), Findings of the Association for Computational Linguistics: ACL 2024, Association for Computational Linguistics, Bangkok, Thailand, 2024, pp. 295–337. doi:10.18653/v1/2024.findings-acl.19. URL https://aclanthology.org...
-
[8]
A. Chen, J. Phang, A. Parrish, V. Padmakumar, C. Zhao, S. R. Bow- man, K. Cho, Two failures of self-consistency in the multi-step reasoning of llms (2024). arXiv:2305.14279. URL https://arxiv.org/abs/2305.14279
arXiv 2024
-
[9]
Z. Xu, T. Song, Y.-C. Lee, Confronting verbalized uncertainty: Under- standing how llm’s verbalized uncertainty influences users in ai-assisted decision-making, Int. J. Hum.-Comput. Stud. 197 (C) (Mar. 2025). doi:10.1016/j.ijhcs.2025.103455. URL https://doi.org/10.1016/j.ijhcs.2025.103455
-
[10]
J. Li, Y. Yang, Q. V. Liao, J. Zhang, Y.-C. Lee, As confidence aligns: Understanding the effect of ai confidence on human self-confidence in human-ai decision making, in: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25, ACM, New York, NY, USA, 2025, pp. 1–16. doi:10.1145/3706598.3713336. URL https://doi.org/10.1145/37...
-
[11]
S. S. Y. Kim, Q. V. Liao, M. Vorvoreanu, S. Ballard, J. W. Vaughan, "I’m Not Sure, But...": Examining the Impact of Large Language Mod- els’ Uncertainty Expression on User Reliance and Trust, in: Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Trans- parency, Association for Computing Machinery, New York, NY, USA, 2024, pp. 822–835...
-
[12]
C. Si, N. Goyal, T. Wu, C. Zhao, S. Feng, H. Daume III, J. Boyd-Graber, Large language models help humans verify truthfulness – except when they are convincingly wrong, in: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Association for ...
-
[13]
S. S. Y. Kim, J. W. Vaughan, Q. V. Liao, T. Lombrozo, O. Russakovsky, Fostering appropriate reliance on large language models: The role of ex- planations, sources, and inconsistencies, in: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, Associa- tion for Computing Machinery, New York, NY, USA, 2025, pp. 1–19. doi:10.1145/3706...
-
[14]
A. B. Arrieta, N. Díaz-Rodríguez, J. D. Ser, A. Bennetot, S. Tabik, A. Barbado, S. García, S. Gil-López, D. Molina, R. Benjamins, R. Chatila, F. Herrera, Explainable artificial intelligence (xai): Con- cepts, taxonomies, opportunities and challenges toward responsible ai (2019). arXiv:1910.10045. URL https://arxiv.org/abs/1910.10045
arXiv 2019
-
[15]
Y. Zhang, Q. V. Liao, R. K. E. Bellamy, Effect of confidence and expla- nation on accuracy and trust calibration in ai-assisted decision making, in: Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, FAT* ’20, ACM, New York, NY, USA, 2020, p. 295–305. doi:10.1145/3351095.3372852. URL https://doi.org/10.1145/3351095.3372852
-
[16]
A. Taudien, A. Fügener, A. Gupta, W. Ketter, The effect of ai advice on human confidence in decision-making, in: Proceedings of the 55th Hawaii International Conference on System Sciences, 2022. doi:10.24251/HICSS.2022.029
-
[17]
K. Bauer, M. von Zahn, O. Hinz, Expl(ai)ned: The im- pact of explainable artificial intelligence on users’ informa- tion processing, Information Systems Research 34 (4) (2023) 1582–1602. arXiv:https://doi.org/10.1287/isre.2023.1199, doi:10.1287/isre.2023.1199. URL https://doi.org/10.1287/isre.2023.1199
-
[18]
H. Vasconcelos, M. Jörke, M. Grunde-McLaughlin, T. Gerstenberg, M. S. Bernstein, R. Krishna, Explanations can reduce overreliance on ai systems during decision-making, Proc. ACM Hum.-Comput. Interact. 7 (CSCW1) (apr 2023). doi:10.1145/3579605. URL https://doi.org/10.1145/3579605 48
-
[19]
G. Bansal, T. Wu, J. Zhou, R. Fok, B. Nushi, E. Kamar, M. T. Ribeiro, D. S. Weld, E. Horvitz, Does the whole exceed its parts? the effect of ai explanations on complementary team performance, in: Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Association for Computing Machinery, New York, NY, USA, 2021, pp. 1–16. doi:10.1145...
-
[20]
M. Schemmer, N. Kuehl, C. Benz, A. Bartos, G. Satzger, Appropriate reliance on ai advice: Conceptualization and the effect of explanations, in: Proceedings of the 28th International Conference on Intelligent User Interfaces, Association for Computing Machinery, New York, NY, USA, 2023, pp. 410–422. doi:10.1145/3581641.3584066
-
[21]
URL https://dl.acm.org/doi/10.1145/3461702
U. Bhatt, J. Antoran, Y. Zhang, Q. V. Liao, P. Sattigeri, R. Fogliato, et al., Uncertainty as a form of transparency: Measuring, com- municating, and using uncertainty, in: Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, Association for Computing Machinery, New York, NY, USA, 2021, pp. 401–413. doi:10.1145/3461702.3462571
-
[22]
In: 2015 International Conference on Healthcare Informatics
A. Bussone, S. Stumpf, D. O’Sullivan, The role of explanations on trust and reliance in clinical decision support systems, in: 2015 Interna- tional Conference on Healthcare Informatics, IEEE, 2015, pp. 160–169. doi:10.1109/ICHI.2015.26
-
[23]
Q. Liao, S. S. Sundar, Designing for responsible trust in ai systems: A communication perspective, in: Proceedings of the 2022 ACM Confer- ence on Fairness, Accountability, and Transparency, FAccT ’22, ACM, New York, NY, USA, 2022, p. 1257–1268. doi:10.1145/3531146.3533182. URL https://doi.org/10.1145/3531146.3533182
-
[24]
S. C. Kohn, E. J. de Visser, E. Wiese, Y.-C. Lee, T. H. Shaw, Measure- ment of trust in automation: A narrative review and reference guide, Front Psychol 12 (2021) 604977
2021
-
[25]
Holmqvist, M
K. Holmqvist, M. Nystrom, R. Andersson, R. Dewhurst, H. Jarodzka, J. Van de Weijer, Eye tracking: A comprehensive guide to methods and measures, Oxford University Press, United States, 2011. 49
2011
-
[26]
N. Wang, D. V. Pynadath, S. G. Hill, Trust calibration within a human- robot team: Comparing automatically generated explanations, in: 2016 11thACM/IEEEInternationalConferenceonHuman-RobotInteraction (HRI), 2016, pp. 109–116. doi:10.1109/HRI.2016.7451741
-
[27]
Romeo, D
G. Romeo, D. Conti, Exploring automation bias in human–AI collabora- tion: a review and implications for explainable AI, AI Soc. (Jul. 2025)
2025
-
[28]
R. C. Mayer, J. H. Davis, F. D. Schoorman, An integrative model of organizational trust, The Academy of Management Review 20 (3) (1995) 709–734. URL http://www.jstor.org/stable/258792
1995
-
[29]
J. D. Lee, K. A. See, Trust in automation: designing for appropriate reliance, Hum. Factors 46 (1) (2004) 50–80
2004
-
[30]
K. A. Hoff, M. Bashir, Trust in automation: Integrating empirical ev- idence on factors that influence trust, Human Factors 57 (3) (2015). doi:10.1177/0018720814547570
-
[31]
O. Vereschak, F. Alizadeh, G. Bailly, B. Caramiaux, Trust in ai- assisted decision making: Perspectives from those behind the system and those for whom the decision is made, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, CHI ’24, Association for Computing Machinery, New York, NY, USA, 2024. doi:10.1145/3613904.3642018. URL ht...
-
[32]
A. Gupta, D. Basu, R. Ghantasala, S. Qiu, U. Gadiraju, To trust or not to trust: How a conversational interface affects trust in a decision support system, in: Proceedings of the ACM Web Conference 2022, WWW ’22, Association for Computing Machinery, New York, NY, USA, 2022, p. 3531–3540. doi:10.1145/3485447.3512248. URL https://doi.org/10.1145/3485447.3512248
-
[33]
A. Papenmeier, G. Englebienne, C. Seifert, How model accuracy and explanation fidelity influence user trust (2019). arXiv:1907.12652. URL https://arxiv.org/abs/1907.12652
arXiv 2019
-
[34]
J. Kunkel, T. Donkers, L. Michael, C.-M. Barbu, J. Ziegler, Let me explain: Impact of personal and impersonal explanations on trust 50 in recommender systems, in: Proceedings of the 2019 CHI Confer- ence on Human Factors in Computing Systems, CHI ’19, Associa- tion for Computing Machinery, New York, NY, USA, 2019, p. 1–12. doi:10.1145/3290605.3300717. URL...
-
[35]
X. Wang, Y. Yang, D. Tao, T. Zhang, The impact of ai transparency and reliability on human-ai collaborative decision-making, in: AHFE International, AHFE International, 2023
2023
-
[36]
Ebermann, M
C. Ebermann, M. Selisky, S. Weibelzahl, Explainable ai: The effect of contradictory decisions and explanations on users’ acceptance of ai systems, International Jour- nal of Human–Computer Interaction 39 (9) (2023) 1807–
2023
-
[37]
arXiv:https://doi.org/10.1080/10447318.2022.2126812, doi:10.1080/10447318.2022.2126812
-
[38]
K. Morrison, P. Spitzer, V. Turri, M. Feng, N. Kühl, A. Perer, The impactofimperfectxaionhuman-aidecision-making, Proc.ACMHum.- Comput. Interact. 8 (CSCW1) (Apr. 2024). doi:10.1145/3641022. URL https://doi.org/10.1145/3641022
-
[39]
H. Lakkaraju, O. Bastani, "how do i fool you?": Manipulating user trust via misleading black box explanations, in: Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, AIES ’20, Asso- ciation for Computing Machinery, New York, NY, USA, 2020, p. 79–85. doi:10.1145/3375627.3375833. URL https://doi.org/10.1145/3375627.3375833
-
[40]
A. M. Salih, Z. Raisi-Estabragh, I. B. Galazzo, P. Radeva, S. E. Pe- tersen, K. Lekadir, G. Menegaz, A perspective on explainable artificial intelligence methods: Shap and lime, Advanced Intelligent Systems 7 (1) (Jun. 2024). doi:10.1002/aisy.202400304. URL http://dx.doi.org/10.1002/aisy.202400304
-
[41]
Bachmann, Efficient xai: A low-cost data reduction approach to shap interpretability, J
S. Bachmann, Efficient xai: A low-cost data reduction approach to shap interpretability, J. Artif. Int. Res. (Aug. 2025). doi:10.1613/jair.1.18325. URL https://doi.org/10.1613/jair.1.18325 51
-
[42]
Walden, Reasoning models will blatantly lie about their reasoning (2026)
W. Walden, Reasoning models will blatantly lie about their reasoning (2026). arXiv:2601.07663. URL https://arxiv.org/abs/2601.07663
Pith/arXiv arXiv 2026
-
[43]
J. Yao, H. Sun, N. Xue, Fact-checking ai-generated news reports: Can llms catch their own lies? (2025). arXiv:2503.18293. URL https://arxiv.org/abs/2503.18293
arXiv 2025
-
[44]
F. Leiser, S. Eckhardt, M. Knaeble, A. Maedche, G. Schwabe, A. Sun- yaev, From chatgpt to factgpt: A participatory design study to mit- igate the effects of large language model hallucinations on users, in: Proceedings of Mensch Und Computer 2023, MuC ’23, Association for Computing Machinery, New York, NY, USA, 2023, p. 81–90. doi:10.1145/3603555.3603565....
-
[45]
C. Gomez, S. M. Cho, S. Ke, C.-M. Huang, M. Unberath, Human- ai collaboration is not very collaborative yet: a taxonomy of in- teraction patterns in ai-assisted decision making from a systematic review, Frontiers in Computer Science Volume 6 - 2024 (2025). doi:10.3389/fcomp.2024.1521066. URL https://www.frontiersin.org/journals/computer-science/articles/ ...
-
[46]
A. Springer, S. Whittaker, Progressive disclosure: When, why, and how do users want algorithmic transparency information?, ACM Trans. In- teract. Intell. Syst. 10 (4) (Oct. 2020). doi:10.1145/3374218. URL https://doi.org/10.1145/3374218
-
[47]
D. Fernandes, D. Buschek, L. Tankelevitch, T. Kosch, R. Welsch, Explaining too much? understanding how large language model reasoning traces influence performance and metacognition (2026). arXiv:2605.25856. URL https://arxiv.org/abs/2605.25856
Pith/arXiv arXiv 2026
-
[48]
X. Sun, R. Ma, S. Wei, P. Cesar, J. A. Bosch, A. El Ali, Understanding trust toward human versus ai-generated health in- formation through behavioral and physiological sensing, Interna- tional Journal of Human-Computer Studies 209 (2026) 103714. doi:https://doi.org/10.1016/j.ijhcs.2025.103714. 52 URL https://www.sciencedirect.com/science/article/pii/S1071...
-
[49]
J. Štěpán Novák, J. Masner, P. Benda, P. Šimek, V. Merunka, Eye tracking, usability, and user experience: A systematic review, In- ternational Journal of Human–Computer Interaction 40 (17) (2024) 4484–4500. arXiv:https://doi.org/10.1080/10447318.2023.2221600, doi:10.1080/10447318.2023.2221600. URL https://doi.org/10.1080/10447318.2023.2221600
-
[50]
J. Z. Lim, J. Mountstephens, J. Teo, Eye-tracking feature extraction for biometric machine learning, Front Neurorobot 15 (2022) 796895
2022
-
[51]
Wedel, R
M. Wedel, R. Pieters, R. van der Lans, Modeling eye movements during decision making: A review, Psychometrika 88 (2) (2023) 697–729
2023
-
[52]
D. Toker, C. Conati, Leveraging pupil dilation measures for understand- ing users’ cognitive load during visualization processing, in: Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization, UMAP ’17, Association for Computing Machinery, New York, NY, USA, 2017, p. 267–270. doi:10.1145/3099023.3099059. URL https://doi....
-
[53]
L. Wang, J. A. Stern, Saccade initiation and accuracy in gaze shifts are affected by visual stimulus significance, Psychophysiology 38 (1) (2001) 64–75
2001
-
[54]
N. Boonprakong, X. Chen, C. Davey, B. Tag, T. Dingler, Bias-aware sys- tems: Exploring indicators for the occurrences of cognitive biases when facing different opinions, in: Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, CHI ’23, ACM, New York, NY, USA, 2023, pp. 1–19. doi:10.1145/3544548.3580917. URL https://doi.org/10.1145...
-
[55]
K. Ji, D. Hettiachchi, F. D. Salim, F. Scholer, D. Spina, Characteriz- ing information seeking processes with multiple physiological signals, in: Proceedings of the 47th International ACM SIGIR Conference on Re- search and Development in Information Retrieval, Vol. 5 of SIGIR 2024, ACM, 2024, p. 1006–1017. doi:10.1145/3626772.3657793. URL http://dx.doi.or...
-
[56]
Y. Abdrabou, E. Karypidou, F. Alt, M. Hassib, Investigating user be- havior towards fake news on social media using gaze and mouse move- ments, in: Proceedings 2023 Symposium on Usable Security, 2023. doi:10.14722/usec.2023.232041
-
[57]
I. B. Ajenaghughrure, S. C. Da Costa Sousa, D. Lamas, Psychophysio- logical modelling of trust in technology: Comparative analysis of algo- rithm ensemble methods, in: 2021 IEEE 19th World Symposium on Ap- plied Machine Intelligence and Informatics (SAMI), 2021, pp. 000161– 000168. doi:10.1109/SAMI50585.2021.9378655
-
[58]
H. N. Green, T. Iqbal, Using physiological measures, gaze, and facial expressions to model human trust in a robot partner, in: 2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 11868–11875. doi:10.1109/ICRA55743.2025.11127472
-
[59]
Chiossi, E
F. Chiossi, E. R. Stepanova, B. Tag, M. Perusquia-Hernandez, A. Kit- son, A. Dey, S. Mayer, A. El Ali, Physiochi: Towards best practices for integrating physiological signals in hci, in: Extended Abstracts of the 2024 CHI Conference on Human Factors in Computing Systems, CHI EA ’24, Association for Computing Machinery, New York, NY, USA,
2024
-
[60]
URL https://doi.org/10.1145/3613905.3636286
doi:10.1145/3613905.3636286. URL https://doi.org/10.1145/3613905.3636286
-
[61]
Ömer Sümer, E. Bozkir, T. Kübler, S. Grüner, S. Utz, E. Kas- neci, Fakenewsperception: An eye movement dataset on the per- ceived believability of news stories, Data in Brief 35 (2021) 106909. doi:https://doi.org/10.1016/j.dib.2021.106909
-
[62]
I. Ghosh, K. Jayarajah, N. Waytowich, N. Roy, Augmenting personal- ized memory via practical multimodal wearable sensing in visual search and wayfinding navigation, in: Proceedings of the 33rd ACM Confer- ence on User Modeling, Adaptation and Personalization, UMAP ’25, Association for Computing Machinery, New York, NY, USA, 2025, p. 11–21. doi:10.1145/369...
-
[63]
J. T. Cacioppo, L. G. Tassinary, G. G. Berntson, Strong inference in psychophysiological science, in: J. T. Cacioppo, L. G. Tassinary, G. G. 54 Berntson (Eds.), Handbookof Psychophysiology, Cambridge Handbooks in Psychology, Cambridge University Press, 2016, pp. 3–15
2016
-
[64]
K. Akash, W.-L. Hu, N. Jain, T. Reid, A classification model for sensing human trust in machines using eeg and gsr, ACM Trans. Interact. Intell. Syst. 8 (4) (nov 2018). doi:10.1145/3132743. URL https://doi.org/10.1145/3132743
-
[65]
M. Ahmad, A. Alzahrani, Crucial clues: Investigating psychophysio- logical behaviors for measuring trust in human-robot interaction, in: Proceedings of the 25th International Conference on Multimodal In- teraction, ICMI ’23, ACM, New York, NY, USA, 2023, p. 135–143. doi:10.1145/3577190.3614148. URL https://doi.org/10.1145/3577190.3614148
-
[66]
S. S. Parikh, Eye gaze feature classification for predicting levels of learn- ing, 2018. URL https://api.semanticscholar.org/CorpusID:53471366
2018
-
[67]
Z. Zhang, K. Tsiakas, C. Schneegass, Explaining the wait: How jus- tifying chatbot response delays impact user trust, in: Proceedings of the 6th ACM Conference on Conversational User Interfaces, CUI ’24, Association for Computing Machinery, New York, NY, USA, 2024. doi:10.1145/3640794.3665550. URL https://doi.org/10.1145/3640794.3665550
-
[68]
M. Geva, D. Khashabi, E. Segal, T. Khot, D. Roth, J. Berant, Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies (2021). arXiv:2101.02235. URL https://arxiv.org/abs/2101.02235
arXiv 2021
-
[69]
O. Vereschak, G. Bailly, B. Caramiaux, How to evaluate trust in ai-assisted decision making? a survey of empirical methodolo- gies, Proc. ACM Hum.-Comput. Interact. 5 (CSCW2) (Oct. 2021). doi:10.1145/3476068. URL https://doi.org/10.1145/3476068
- [70]
-
[71]
J. Liu, Y. Zhang, Y. Kim, Consumer health information quality, cred- ibility, and trust: An analysis of definitions, measures, and conceptual dimensions, in: Proceedings of the 2023 Conference on Human Informa- tion Interaction and Retrieval, CHIIR ’23, ACM, New York, NY, USA, 2023, p. 197–210. doi:10.1145/3576840.3578331. URL https://doi.org/10.1145/3576...
-
[72]
S. A. C. Perrig, N. Scharowski, F. Brühlmann, Trust issues with trust scales: Examining the psychometric quality of trust measures in the context of ai, in: Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, CHI EA ’23, ACM, New York, NY, USA, 2023, pp. 1–7. doi:10.1145/3544549.3585808. URL https://doi.org/10.1145/3544549.3585808
-
[73]
F. Faul, E. Erdfelder, A.-G. Lang, A. Buchner, G*Power 3: a flexi- ble statistical power analysis program for the social, behavioral, and biomedical sciences, Behav. Res. Methods 39 (2) (2007) 175–191
2007
-
[74]
Prolific (2014). [link]. URL https://www.prolific.com
2014
-
[75]
E. R. Girden, ANOVA: Repeated measures, no. 84, Sage, 1992
1992
-
[76]
A. Ross, V. L. Willson, Paired Samples T-Test, SensePublishers, Rot- terdam, 2017, pp. 17–19. doi:10.1007/978-94-6351-086-8_4
-
[77]
S. Elo, H. Kyngäs, The qualitative content analysis process, Journal of Advanced Nursing 62 (1) (2008) 107–115
2008
-
[78]
N. McDonald, S. Schoenebeck, A. Forte, Reliability and inter-rater re- liability in qualitative research: Norms and guidelines for cscw and hci practice, Proc. ACM Hum.-Comput. Interact. 3 (CSCW) (Nov. 2019). doi:10.1145/3359174
-
[79]
Tobii AB, Tobii Pro Lab (Version 1.2xx) (2024)
2024
-
[80]
Peirce, J
J. Peirce, J. R. Gray, S. Simpson, M. MacAskill, R. Höchenberger, H. Sogo, E. Kastman, J. K. Lindeløv, PsychoPy2: Experiments in be- havior made easy, Behavior Research Methods 51 (1) (2019) 195–203. 56
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.