Causal Tongue-Tie: LLMs Can Encode Causal Direction, But Their Yes/No Outputs Fail to Express
Pith reviewed 2026-06-29 22:11 UTC · model grok-4.3
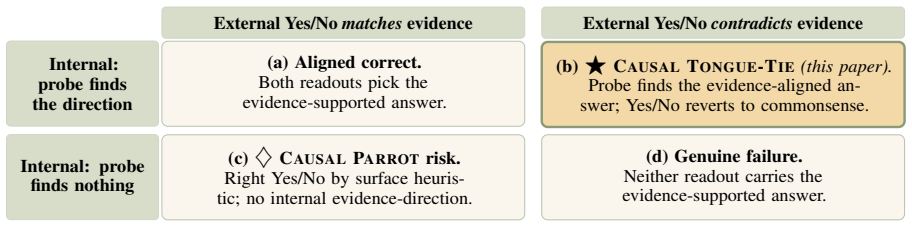
The pith
LLMs internally encode the evidence-based causal answer but output the commonsense yes/no instead on conflicting questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
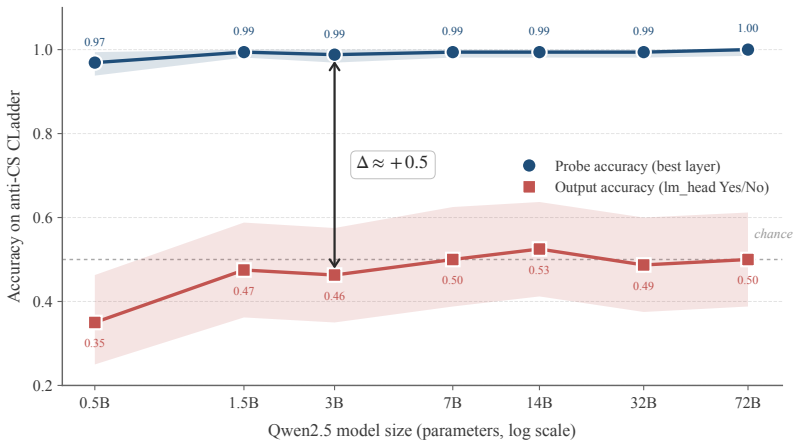
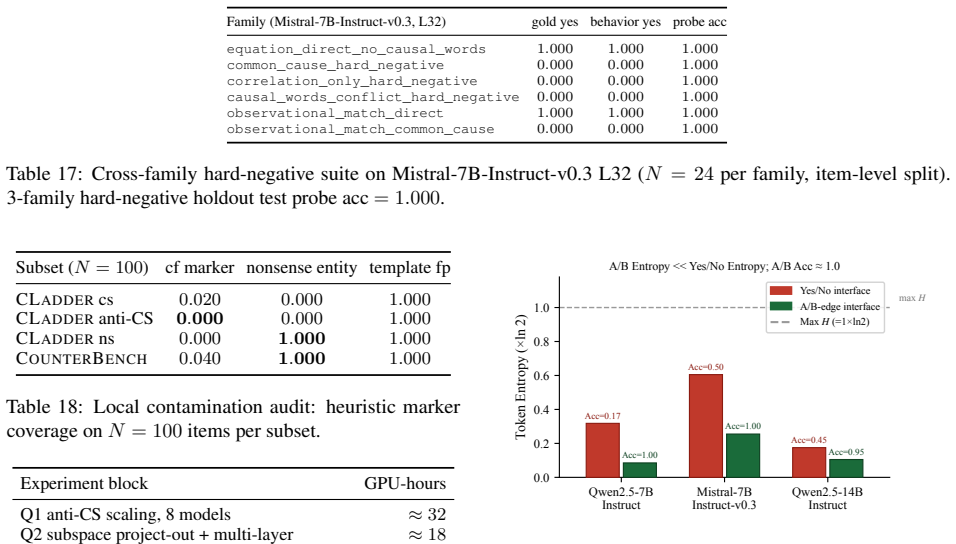
On anti-commonsense CLadder items, hidden-state representations contain the evidence-supported causal answer even when the model's verbal yes/no output reverts to the commonsense answer, producing an accuracy gap of approximately 0.5 between probe recovery and spoken response.
What carries the argument
A fixed linear probe applied to the model's hidden states that extracts the evidence-supported causal direction, set against the verbal yes/no generation interface that fails to express it.
If this is right
- A benchmark answer labeled correct does not establish that the model has internally represented the causal relation.
- A benchmark answer labeled incorrect does not establish that the model lacks the relevant causal representation.
- Causal reasoning claims drawn from yes/no accuracy alone require separate checks on internal representations.
- The verbal output channel can mask encoded causal knowledge that remains accessible via probing.
Where Pith is reading between the lines
- Similar internal-versus-output gaps may exist for other structured reasoning tasks that pit evidence against prior patterns.
- Evaluation protocols could combine output accuracy with lightweight probes on the same items to separate encoding failures from expression failures.
- Interventions that alter hidden-state representations might be tested to see whether they shift verbal outputs toward the probed answer.
Load-bearing premise
The linear probe is recovering genuine causal knowledge encoded in the hidden states rather than some other correlated but non-causal pattern, and the independently identified evidence-supported answer is the correct target.
What would settle it
A new collection of anti-commonsense causal questions on which the same linear probe no longer achieves high accuracy at recovering the evidence answer, or on which probe accuracy falls to match the verbal output accuracy.
Figures



read the original abstract
We find a mismatch between what large language models encode about a causal question and what they answer. On anti-commonsense CLadder items, a fixed linear probe recovers the evidence-supported answer from the model's hidden state (accuracy approximately 0.97), while the spoken Yes/No reverts to the commonsense one (accuracy approximately 0.5). We call this approximately +0.5 gap Causal Tongue-Tie: a wrong Yes/No decomposes into two separable failure modes: no internal signal versus a signal the verbal interface cannot say. The implication cuts both ways for output-only causal benchmarks: a benchmark "correct" need not mean the model has understood, and a benchmark "wrong" need not mean it cannot. Sweeping claims about whether LLMs can do causal reasoning, drawn from a single accuracy number, deserve a second look.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that LLMs internally encode the evidence-supported causal direction on anti-commonsense CLadder items (recoverable via a fixed linear probe at ~0.97 accuracy from hidden states) but their Yes/No outputs fail to express it, defaulting to the commonsense answer (~0.5 accuracy). This 'Causal Tongue-Tie' is presented as two separable failure modes, with implications that output-only causal benchmarks are insufficient to assess whether models have understood causal structure.
Significance. If the central empirical separation between probe and output holds after controls, the result would be moderately significant for causal reasoning evaluations in LLMs: it would demonstrate that output accuracy alone cannot distinguish internal encoding failures from verbal-interface failures. The approach of using probes on hidden states to surface evidence-supported answers offers a useful diagnostic lens beyond verbal responses, though its value depends on ruling out non-causal confounds.
major comments (2)
- [Abstract] Abstract: the central claim rests on a linear probe achieving ~0.97 accuracy recovering the evidence-supported answer, yet the abstract (and by extension the reported method) provides no details on probe training procedure, feature selection, regularization, statistical significance tests, or cross-validation; without these, it is impossible to assess whether the number supports genuine causal encoding or reflects overfitting or post-hoc selection.
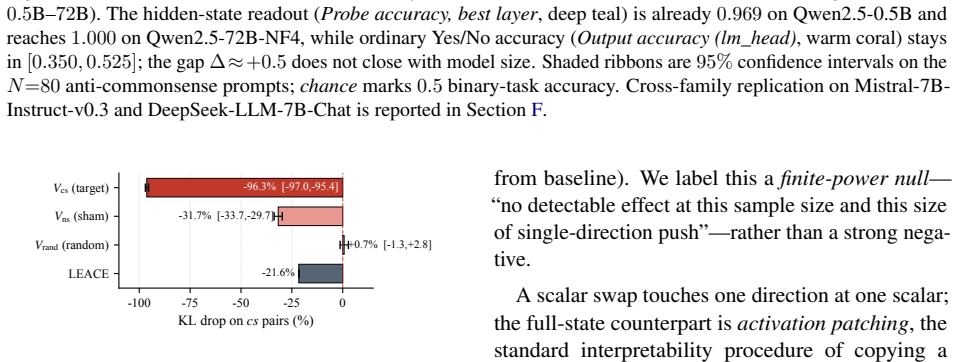
- [Abstract] Abstract / implied methods: on anti-commonsense items the probe is said to recover the 'evidence-supported' answer while output reverts to commonsense, but no label-shuffled controls, probes trained on matched non-causal tasks, or causal interventions on the residual stream are described to rule out spurious correlations (e.g., token patterns or graph-description statistics that differ between subsets); this is load-bearing for the 'internal signal vs. verbal interface' decomposition.
minor comments (1)
- [Abstract] The abstract uses approximate figures ('approximately 0.97', 'approximately 0.5') without reporting exact values, confidence intervals, or dataset sizes; adding these would improve precision.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, indicating where we will revise the manuscript to incorporate additional details and controls while defending the core empirical separation presented.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim rests on a linear probe achieving ~0.97 accuracy recovering the evidence-supported answer, yet the abstract (and by extension the reported method) provides no details on probe training procedure, feature selection, regularization, statistical significance tests, or cross-validation; without these, it is impossible to assess whether the number supports genuine causal encoding or reflects overfitting or post-hoc selection.
Authors: We agree that the abstract is highly condensed and omits key methodological parameters. The full manuscript describes the probe as a linear logistic regression classifier applied to the final-layer residual stream activations, trained with L2 regularization (strength selected via inner cross-validation) on an 80/20 train/test split per item set, with 5-fold cross-validation used to compute mean accuracy and standard deviation. Feature selection was not applied; the full hidden-state dimension was used. Statistical significance against chance was evaluated with permutation tests (p < 0.001). To address the concern directly, we will revise the abstract to include a concise clause on the probe type, cross-validation, and regularization, and we will add a short methods paragraph summarizing these choices with exact hyperparameter values and significance results. revision: yes
-
Referee: [Abstract] Abstract / implied methods: on anti-commonsense items the probe is said to recover the 'evidence-supported' answer while output reverts to commonsense, but no label-shuffled controls, probes trained on matched non-causal tasks, or causal interventions on the residual stream are described to rule out spurious correlations (e.g., token patterns or graph-description statistics that differ between subsets); this is load-bearing for the 'internal signal vs. verbal interface' decomposition.
Authors: The anti-commonsense construction itself provides partial protection against simple commonsense or token-frequency confounds, because the probe recovers the evidence-supported direction (opposite to commonsense) at high accuracy while the verbal output does not. Nevertheless, we acknowledge that explicit controls would make the separation more robust. In revision we will add (i) label-shuffled baselines showing probe accuracy collapsing to chance (~0.5) and (ii) a matched non-causal probe (e.g., on syntactic subject-verb agreement) to demonstrate that the high accuracy is not an artifact of any linear probe on these activations. Full causal interventions on the residual stream (e.g., activation patching) lie beyond the current experimental scope and would require substantial additional compute; we will therefore note this as a limitation rather than claim to have performed them. revision: partial
Circularity Check
No derivation chain present; empirical comparison is self-contained
full rationale
The paper reports an empirical mismatch between linear-probe accuracy on hidden states (~0.97) and verbal Yes/No accuracy (~0.5) on anti-commonsense CLadder items. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The central claim rests on direct measurement of two observables (probe output vs. generated token) against an externally supplied ground-truth label; nothing reduces to its own inputs by construction. The skeptic concern about spurious correlations in the probe is a question of experimental validity, not circularity of the reported numbers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Information Processing Systems (NeurIPS), pages 66044–66063
LEACE: Perfect linear concept erasure in closed form. InAdvances in Neural Information Processing Systems (NeurIPS), pages 66044–66063. Emily M. Bender, Timnit Gebru, Angelina McMillan- Major, and Shmargaret Shmitchell. 2021. On the dan- gers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM Conference on Fairness, Accou...
2021
-
[2]
CounterBench: Evaluating and Improving Counterfactual Reasoning in Large Language Models
CounterBench: Evaluating and improving coun- terfactual reasoning in large language models.arXiv preprint arXiv:2502.11008. Haoang Chi, He Li, Wenjing Yang, Feng Liu, Long Lan, Xiaoguang Ren, Tongliang Liu, and Bo Han. 2024. Unveiling causal reasoning in large language models: Reality or mirage? InAdvances in Neural Information Processing Systems (NeurIPS...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Preprint arXiv:2005.13407 (2020); journal version 2021
CausaLM: Causal model explanation through counterfactual language models.Computational Lin- guistics, 47(2):333–386. Preprint arXiv:2005.13407 (2020); journal version 2021. Jörg Frohberg and Frank Binder. 2022. CRASS: A novel data set and benchmark to test counterfactual reasoning of large language models. InProceedings of the Thir- teenth Language Resour...
-
[4]
and Potts, Christopher and Icard, Thomas , title =
ArXiv:2301.04709, first posted 2023; final JMLR version 2025. John Hewitt and Percy Liang. 2019. Designing and inter- preting probes with control tasks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), pages 2733–2743. Albert ...
-
[5]
InThe Thirteenth International Conference on Learning Representations (ICLR)
The geometry of categorical and hierarchical concepts in large language models. InThe Thirteenth International Conference on Learning Representations (ICLR). Kiho Park, Yo Joong Choe, and Victor Veitch. 2024. The linear representation hypothesis and the geometry of large language models. InProceedings of the 41st In- ternational Conference on Machine Lear...
2024
-
[6]
Qwen2.5 technical report. arXiv preprint arXiv:2412.15115.Preprint, arXiv:2412.15115. Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav Goldberg. 2020. Null it out: Guard- ing protected attributes by iterative nullspace projection. InProceedings of the 58th Annual Meeting of the As- sociation for Computational Linguistics (ACL), pages 72...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Representation Engineering: A Top-Down Approach to AI Transparency
Investigating gender bias in language models using causal mediation analysis. InAdvances in Neural Information Processing Systems (NeurIPS). Matej Ze ˇcevi´c, Moritz Willig, Devendra Singh Dhami, and Kristian Kersting. 2023. Causal parrots: Large language models may talk causality but are not causal. Transactions on Machine Learning Research (TMLR), 2023....
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.