AdvantageFlow: Advantage-Weighted Least Squares for RL in Flow Models
Pith reviewed 2026-06-29 22:42 UTC · model grok-4.3
The pith
AdvantageFlow optimizes an advantage-weighted forward-process prediction loss for rectified flow models and stabilizes it with rollout policy regularization to outperform prior RL methods on image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
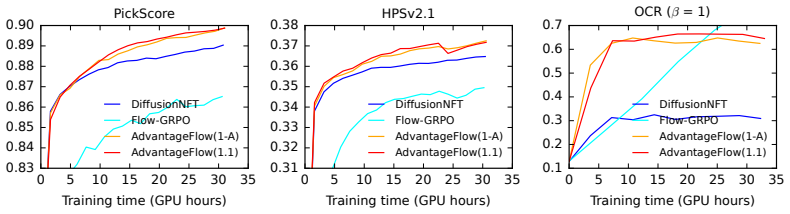
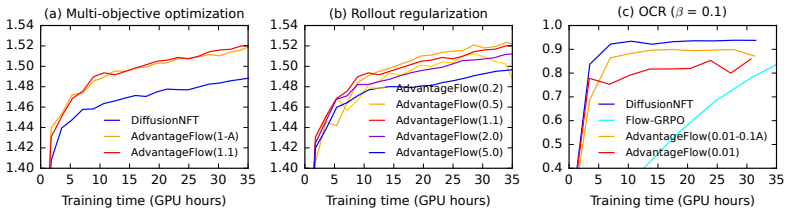
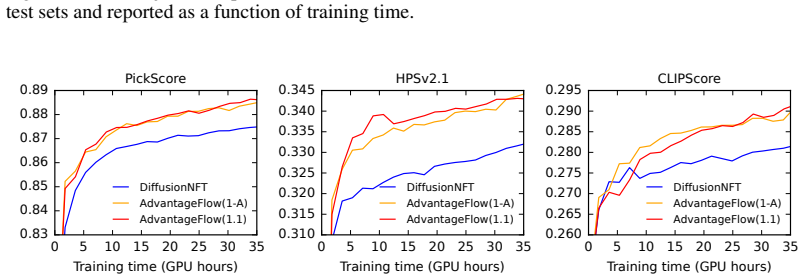
AdvantageFlow is a forward-process reinforcement learning algorithm for rectified flow models. It minimizes an advantage-weighted least-squares prediction loss on the forward process. When advantages are negative the resulting optimization problem is non-convex and unstable; rollout policy regularization stabilizes it by reducing variance and corresponding to a local reward-improving target distribution. On image generation tasks with Stable Diffusion 3.5 Medium the method outperforms both the reverse-process Flow-GRPO algorithm and a state-of-the-art forward-process baseline based on negative-aware fine-tuning.
What carries the argument
Advantage-weighted forward-process prediction loss stabilized by rollout policy regularization
If this is right
- Enables stable advantage-weighted optimization of flow models on the forward process even when some advantages are negative.
- Reduces variance in the non-convex loss through the derived regularization term.
- Produces higher performance than reverse-process RL on the tested image generation tasks.
- Offers a concrete alternative to negative-aware fine-tuning for forward-process RL in flow models.
Where Pith is reading between the lines
- The same regularization idea could apply to other non-convex advantage-weighted objectives in generative modeling beyond flows.
- If the local target distribution view holds, it may suggest ways to design variance-reducing targets for RL in other sequential generative processes.
- The forward-process formulation might allow tighter integration of reward signals during the sampling trajectory itself.
Load-bearing premise
The rollout policy regularization term is sufficient to stabilize the non-convex advantage-weighted loss when advantages are negative.
What would settle it
Running the same Stable Diffusion 3.5 image generation experiments without the rollout policy regularization term and observing that performance collapses or the loss diverges would falsify the stabilization claim.
Figures




read the original abstract
We introduce AdvantageFlow, a forward-process reinforcement learning algorithm for rectified flow models. Unlike Flow-GRPO, which optimizes the reverse process, we optimize an advantage-weighted forward-process prediction loss. This optimization problem is unstable when advantages are negative and the loss becomes non-convex. We stabilize it by rollout policy regularization, which reduces variance and arises from fitting a local reward-improving target distribution. We evaluate AdvantageFlow on image generation tasks with Stable Diffusion 3.5 Medium. It outperforms both Flow-GRPO and a state-of-the-art forward-process RL baseline based on negative-aware fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AdvantageFlow, a forward-process RL algorithm for rectified flow models. It optimizes an advantage-weighted least-squares prediction loss on the forward process (in contrast to Flow-GRPO's reverse-process optimization) and stabilizes the resulting non-convex objective (when advantages are negative) via a rollout-policy regularization term that is claimed to reduce variance and correspond to a local reward-improving target. Experiments on image-generation tasks with Stable Diffusion 3.5 Medium report outperformance relative to Flow-GRPO and a negative-aware fine-tuning baseline.
Significance. If the regularization demonstrably prevents divergence or poor local minima across the encountered advantage distribution, the method would supply a concrete algorithmic alternative for applying RL to flow-based generative models, potentially improving training stability for high-dimensional tasks. The explicit treatment of the non-convexity issue and the use of a contemporary base model (SD 3.5 Medium) are positive aspects of the empirical component.
major comments (1)
- [Abstract] Abstract (optimization-problem paragraph): the claim that rollout-policy regularization suffices to stabilize the non-convex advantage-weighted loss when advantages are negative is presented without a supporting convexity argument, variance bound, or stability diagnostic (e.g., loss curves or divergence rates stratified by advantage sign). This assumption is load-bearing for the headline empirical claim of outperformance versus Flow-GRPO and negative-aware fine-tuning.
minor comments (2)
- The abstract refers to 'rectified flow models' and 'forward-process prediction loss' without defining the precise form of the loss or the advantage estimator; these should be stated explicitly in §2 or §3 with equation numbers.
- No error bars, number of seeds, or statistical significance tests are mentioned for the image-generation results; these details are needed to assess whether the reported gains are reliable.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the stabilization claim. We agree that additional supporting evidence strengthens the presentation and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (optimization-problem paragraph): the claim that rollout-policy regularization suffices to stabilize the non-convex advantage-weighted loss when advantages are negative is presented without a supporting convexity argument, variance bound, or stability diagnostic (e.g., loss curves or divergence rates stratified by advantage sign). This assumption is load-bearing for the headline empirical claim of outperformance versus Flow-GRPO and negative-aware fine-tuning.
Authors: We agree the abstract states the stabilization effect without an accompanying convexity argument or variance bound. The full manuscript provides empirical outperformance on SD 3.5 Medium, but does not include stratified loss curves or divergence diagnostics by advantage sign. In revision we will add these diagnostics (loss curves and per-sign divergence rates) to the experiments section, include a brief local-neighborhood analysis of the regularization term in the method section, and update the abstract to reference the new evidence. This directly addresses the load-bearing concern while preserving the core algorithmic contribution. revision: yes
Circularity Check
No significant circularity; algorithmic contribution is self-contained
full rationale
The paper introduces AdvantageFlow as a forward-process RL algorithm that optimizes an advantage-weighted prediction loss stabilized via rollout policy regularization. The abstract and description contain no equations, no claimed first-principles derivations, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. The central claims rest on the empirical evaluation on Stable Diffusion 3.5 Medium and the stated stabilization heuristic, both of which are independent of any circular reduction to inputs. This is the expected outcome for an algorithmic methods paper without a closed-form derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
Jiajun Fan, Chaoran Cheng, Shuaike Shen, Xiangxin Zhou, and Ge Liu. Fine-tuning flow matching generative models with intermediate feedback.arXiv preprint arXiv:2510.18072, 2025a. Jiajun Fan, Shuaike Shen, Chaoran Cheng, Yuxin Chen, Chumeng Liang, and Ge Liu. Online reward-weighted fine-tuning of flow matching with Wasserstein regularization. InICLR, 2025b...
-
[4]
TempFlow-GRPO: When Timing Matters for GRPO in Flow Models
Xiaoxuan He, Siming Fu, Yuke Zhao, Wanli Li, Jian Yang, Dacheng Yin, Fengyun Rao, and Bo Zhang. TempFlow-GRPO: When timing matters for GRPO in flow models.arXiv preprint arXiv:2508.04324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
CLIPScore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing,
2021
-
[6]
Aligning Text-to-Image Models using Human Feedback
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. Aligning text-to-image models using human feedback.arXiv preprint arXiv:2302.12192,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
10 Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Yiming Cheng, Miles Yang, Zhao Zhong, and Liefeng Bo. MixGRPO: Unlocking flow-based GRPO efficiency with mixed ODE-SDE.arXiv preprint arXiv:2507.21802, 2025a. Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. BranchGRPO: Stable and efficient GRPO with structured...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online RL.arXiv preprint arXiv:2505.05470, 2025a. Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Aligning text-to-image diffusion models with reward backpropagation.arXiv preprint arXiv:2310.03739,
Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, and Katerina Fragkiadaki. Aligning text-to-image diffusion models with reward backpropagation.arXiv preprint arXiv:2310.03739,
-
[10]
Stepwise credit assignment for GRPO on flow-matching models.arXiv preprint arXiv:2603.28718,
Yash Savani, Branislav Kveton, Yuchen Liu, Yilin Wang, Jing Shi, Subhojyoti Mukherjee, Nikos Vlassis, and Krishna Kumar Singh. Stepwise credit assignment for GRPO on flow-matching models.arXiv preprint arXiv:2603.28718,
-
[11]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Masatoshi Uehara, Yulai Zhao, Tommaso Biancalani, and Sergey Levine. Understanding rein- forcement learning-based fine-tuning of diffusion models: A tutorial and review.arXiv preprint arXiv:2407.13734,
-
[13]
Shuchen Xue, Chongjian Ge, Shilong Zhang, Yichen Li, and Zhi-Ming Ma. Advantage weighted matching: Aligning RL with pretraining in diffusion models.arXiv preprint arXiv:2509.25050, 2025a. Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, and Ping Luo. DanceGRPO: Unleashing GRPO on visua...
-
[14]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
arXiv:2509.16117. 11 Yujie Zhou, Pengyang Ling, Jiazi Bu, Yibin Wang, Yuhang Zang, Jiaqi Wang, Li Niu, and Guangtao Zhai. Fine-grained GRPO for precise preference alignment in flow models.arXiv preprint arXiv:2510.01982,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Diffusion reinforcement learning via centered reward distillation.arXiv preprint arXiv:2603.14128,
Yuanzhi Zhu, Xi Wang, Stéphane Lathuilière, and Vicky Kalogeiton. Diffusion reinforcement learning via centered reward distillation.arXiv preprint arXiv:2603.14128,
-
[16]
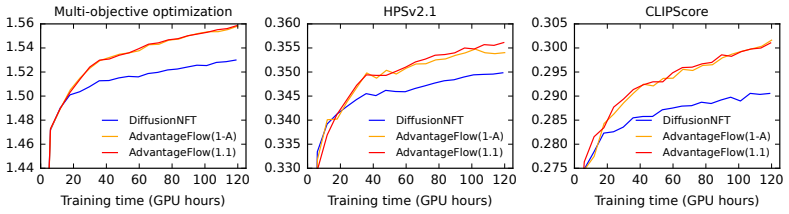
We report the combined reward, as well as HPSv2.1 and CLIPScore
12 0 20 40 60 80 100 120 Training time (GPU hours) 1.44 1.46 1.48 1.50 1.52 1.54 1.56 Multi-objective optimization DiffusionNFT AdvantageFlow(1-A) AdvantageFlow(1.1) 0 20 40 60 80 100 120 Training time (GPU hours) 0.330 0.335 0.340 0.345 0.350 0.355 0.360 HPSv2.1 DiffusionNFT AdvantageFlow(1-A) AdvantageFlow(1.1) 0 20 40 60 80 100 120 Training time (GPU h...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.