Forgetting in Language Models: Capacity, Optimization, and Self-Generated Replay
Pith reviewed 2026-06-29 23:13 UTC · model grok-4.3
The pith
Self-generated samples from a language model can serve as replay data that nearly eliminates forgetting on prior tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Self-generated samples serve as effective replay data, nearly eliminating forgetting. Forgetting nonetheless persists when the model has little remaining capacity: models pretrained close to saturation cannot absorb new information without overwriting prior knowledge. When capacity is not the limiting factor, low learning rates reduce forgetting but require substantially more training steps. Replay breaks this tradeoff, enabling fast, high-learning-rate finetuning without forgetting.
What carries the argument
self-generated replay using samples drawn from the model's own training distribution
If this is right
- High learning-rate finetuning becomes feasible without catastrophic forgetting once self-generated replay is used.
- Pretraining saturation level directly limits how much new information a model can acquire later.
- The number of training steps needed to reach a target performance can be reduced when replay removes the need for low learning rates.
- Continual learning pipelines no longer require storage of original task data if the model can generate its own replay buffer.
Where Pith is reading between the lines
- The result implies that continual-learning performance will improve as pretraining leaves more unused capacity rather than pushing models to saturation.
- The same self-generation approach might be tested in non-language domains where a model can also sample from an approximate training distribution.
- If generation quality improves with scale, the effectiveness of self-replay may increase for larger models even when they are trained closer to capacity.
Load-bearing premise
Samples the model generates from its own distribution remain close enough to the original prior-task data that they can substitute for stored exemplars without creating a distribution shift that reintroduces forgetting.
What would settle it
If finetuning with self-generated samples still produces the same accuracy drop on held-out prior-task data as training without any replay, the claim that these samples function as effective replay would be refuted.
Figures


read the original abstract
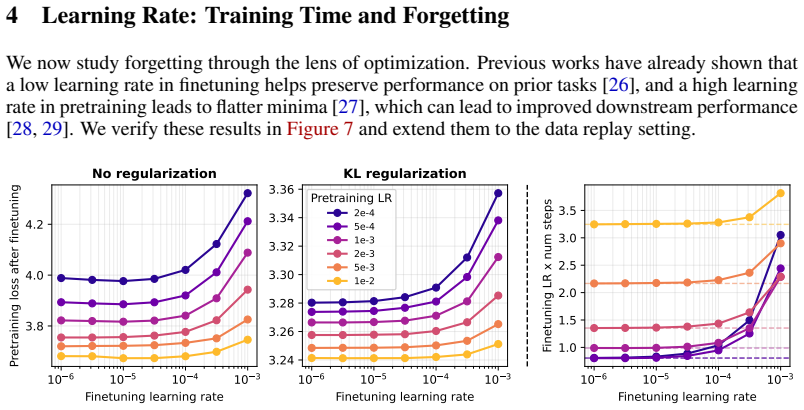
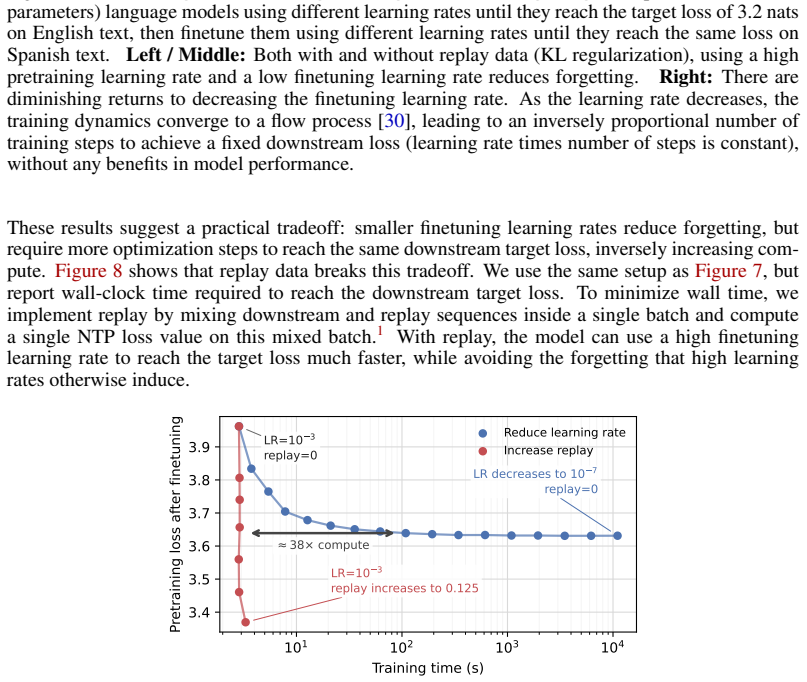
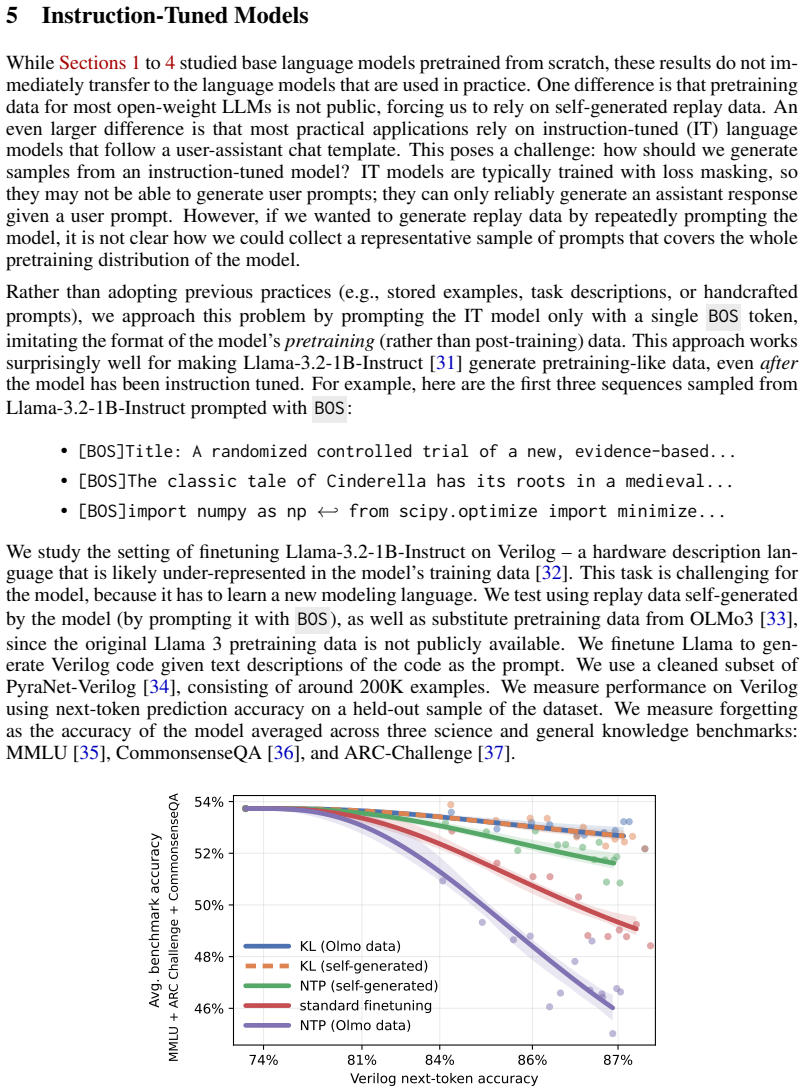
Models trained on a new task typically degrade on prior tasks, a phenomenon known as forgetting. Traditionally, mitigating forgetting has required replaying stored exemplars from prior tasks, which is often impractical. By contrast, language models can sample from their own training distribution, and we show that these self-generated samples serve as effective replay data, nearly eliminating forgetting. We find that forgetting nonetheless persists when the model has little remaining capacity: models pretrained close to saturation cannot absorb new information without overwriting prior knowledge. When capacity is not the limiting factor, low learning rates reduce forgetting but require substantially more training steps. Replay breaks this tradeoff, enabling fast, high-learning-rate finetuning without forgetting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that self-generated samples from language models can serve as effective replay data to nearly eliminate catastrophic forgetting when finetuning on new tasks. It further reports that forgetting persists when models are pretrained close to saturation (limited remaining capacity), and that replay enables high learning-rate finetuning without the usual tradeoff where low learning rates reduce forgetting only at the cost of substantially more training steps.
Significance. If substantiated with rigorous controls, the result would be significant for continual learning in language models, as it offers a storage-free and privacy-preserving alternative to traditional replay. The distinction between capacity-limited and optimization-limited regimes provides a useful conceptual separation. The work would benefit from explicit credit for any ablation studies isolating replay from generic regularization effects.
major comments (2)
- [Abstract] Abstract: the central claim that self-generated samples 'nearly eliminate forgetting' is load-bearing for the contribution, yet the provided text states empirical outcomes without any experimental details, metrics, baselines, or controls. This prevents evaluation of whether the observed stability arises from distributional replay or other factors.
- [Abstract] Abstract (and implied results): the effectiveness of self-generated replay requires that sampled data match the original prior-task distribution sufficiently to avoid mode collapse or shift. No mention of quantification (e.g., token-level KL, embedding MMD, or probe accuracy on original vs. generated data) appears, so the no-forgetting result could reduce to extra gradient steps or regularization rather than faithful replay.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater specificity in the abstract and for explicit evidence that self-generated samples provide distributional replay rather than generic regularization. We will revise the abstract accordingly and add the requested distributional analyses in the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that self-generated samples 'nearly eliminate forgetting' is load-bearing for the contribution, yet the provided text states empirical outcomes without any experimental details, metrics, baselines, or controls. This prevents evaluation of whether the observed stability arises from distributional replay or other factors.
Authors: We agree the abstract is too high-level. The full manuscript reports concrete metrics (prior-task accuracy), baselines (no-replay finetuning and stored-exemplar replay), and controls (learning-rate sweeps, capacity regimes). We will revise the abstract to include a brief statement of these elements, e.g., “measured by prior-task accuracy against no-replay and stored-replay baselines.” revision: yes
-
Referee: [Abstract] Abstract (and implied results): the effectiveness of self-generated replay requires that sampled data match the original prior-task distribution sufficiently to avoid mode collapse or shift. No mention of quantification (e.g., token-level KL, embedding MMD, or probe accuracy on original vs. generated data) appears, so the no-forgetting result could reduce to extra gradient steps or regularization rather than faithful replay.
Authors: The manuscript already shows that replay permits high learning rates without the usual forgetting penalty, an outcome not explained by extra steps or generic regularization alone (we equate total gradient steps across conditions). Nevertheless, we accept that explicit distributional fidelity checks are needed. In revision we will add quantification—probe accuracy on original data evaluated on generated samples and token-level distributional metrics—to confirm the generated data remain faithful to the prior-task distribution. revision: yes
Circularity Check
Empirical results on self-generated replay show no circularity in derivation chain
full rationale
The paper reports experimental findings on catastrophic forgetting in language models, demonstrating that self-generated samples can serve as effective replay to mitigate forgetting, with additional observations on capacity limits and learning rate tradeoffs. No equations, fitted parameters, or derivation steps are described that reduce a claimed prediction or result to its own inputs by construction. The central claims rest on empirical measurements rather than a mathematical chain, uniqueness theorems, or ansatzes imported via self-citation. The work is self-contained against external benchmarks via direct experiments, with no load-bearing self-citations or self-definitional constructs visible. This is the expected outcome for an empirical ML study without theoretical derivations.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
Larger models succeed on rare and complex tasks by reducing gradient interference from common tasks, allowing rare-task features to accumulate, as shown via synthetic task mixtures and OLMo pretraining from 4M to 4B p...
Reference graph
Works this paper leans on
-
[1]
Richter, Quentin Anthony, Eugene Belilovsky, Irina Rish, and Timothée Lesort
Kshitij Gupta, Benjamin Thérien, Adam Ibrahim, Mats L. Richter, Quentin Anthony, Eugene Belilovsky, Irina Rish, and Timothée Lesort. Continual pre-training of large language models: How to (re)warm your model?, 2023. URLhttps://arxiv.org/abs/2308.04014
-
[2]
Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catas- trophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):352...
-
[3]
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning, 2025. URL https://arxiv.org/abs/2308.08747
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Scaling laws for forgetting during finetuning with pretraining data injection, 2025
Louis Bethune, David Grangier, Dan Busbridge, Eleonora Gualdoni, Marco Cuturi, and Pierre Ablin. Scaling laws for forgetting during finetuning with pretraining data injection, 2025. URL https://arxiv.org/abs/2502.06042
-
[5]
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Hen- derson. Fine-tuning aligned language models compromises safety, even when users do not intend to! InInternational Conference on Learning Representations, volume 2024, pages 30988–31043, 2024
2024
-
[6]
A comprehensive survey of forget- ting in deep learning beyond continual learning, 2024
Zhenyi Wang, Enneng Yang, Li Shen, and Heng Huang. A comprehensive survey of forget- ting in deep learning beyond continual learning, 2024. URLhttps://arxiv.org/abs/2307. 09218. 9
2024
-
[7]
Zhizhong Li and Derek Hoiem. Learning without forgetting, 2017. URLhttps://arxiv. org/abs/1606.09282
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Replaying pre-training data improves fine-tuning, 2026
Suhas Kotha and Percy Liang. Replaying pre-training data improves fine-tuning, 2026. URL https://arxiv.org/abs/2603.04964
-
[9]
Bagdanov, and Joost van de Weijer
Marc Masana, Xialei Liu, Bartlomiej Twardowski, Mikel Menta, Andrew D. Bagdanov, and Joost van de Weijer. Class-incremental learning: survey and performance evaluation on image classification, 2022. URLhttps://arxiv.org/abs/2010.15277
-
[10]
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy P. Lillicrap, and Greg Wayne. Expe- rience replay for continual learning, 2019. URLhttps://arxiv.org/abs/1811.11682
-
[11]
Martial Mermillod, Aurélia Bugaiska, and Patrick BONIN. The stability-plasticity dilemma: investigating the continuum from catastrophic forgetting to age-limited learning effects.Fron- tiers in Psychology, V olume 4 - 2013, 2013. ISSN 1664-1078. doi: 10.3389/fpsyg. 2013.00504. URLhttps://www.frontiersin.org/journals/psychology/articles/10. 3389/fpsyg.2013.00504
-
[12]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[13]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo, Hynek Kydlí ˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024. URLhttps://arxiv.org/abs/2406.17557
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Nemotron-cc-math: A 133 billion-token-scale high quality math pretraining dataset, 2025
Rabeeh Karimi Mahabadi, Sanjeev Satheesh, Shrimai Prabhumoye, Mostofa Patwary, Mo- hammad Shoeybi, and Bryan Catanzaro. Nemotron-cc-math: A 133 billion-token-scale high quality math pretraining dataset, 2025. URLhttps://arxiv.org/abs/2508.15096
-
[15]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. URLhttps://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
1999
-
[17]
Catastrophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pages 109–165. Elsevier, 1989
1989
-
[18]
Mitigating catastrophic forgetting in large language models with self- synthesized rehearsal, 2024
Jianheng Huang, Leyang Cui, Ante Wang, Chengyi Yang, Xinting Liao, Linfeng Song, Junfeng Yao, and Jinsong Su. Mitigating catastrophic forgetting in large language models with self- synthesized rehearsal, 2024. URLhttps://arxiv.org/abs/2403.01244
-
[19]
Physics of language models: Part 3.3, knowledge capacity scaling laws, 2024
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.3, knowledge capacity scaling laws, 2024. URLhttps://arxiv.org/abs/2404.05405
-
[20]
Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G
John X. Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G. Edward Suh, Alexan- der M. Rush, Kamalika Chaudhuri, and Saeed Mahloujifar. How much do language models memorize?, 2025. URLhttps://arxiv.org/abs/2505.24832
-
[21]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10, 2022. URL https://arxiv.org/abs/2203.15556
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Hyperparame- ter transfer enables consistent gains of matrix-preconditioned optimizers across scales
Shikai Qiu, Zixi Chen, Hoang Phan, Qi Lei, and Andrew Gordon Wilson. Hyperparame- ter transfer enables consistent gains of matrix-preconditioned optimizers across scales. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=Ei6IsmxYrb. 10
2026
-
[23]
Scaling laws and compute-optimal training beyond fixed training durations
Alexander Hägele, Elie Bakouch, Atli Kosson, Loubna Ben allal, Leandro V on Werra, and Martin Jaggi. Scaling laws and compute-optimal training beyond fixed training durations. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=Y13gSfTjGr
2024
-
[24]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023. URLhttps://arxiv.org/abs/1910.10683
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
A scalable measure of loss landscape curvature for analyzing the training dynamics of llms, 2026
Dayal Singh Kalra, Jean-Christophe Gagnon-Audet, Andrey Gromov, Ishita Mediratta, Kelvin Niu, Alexander H Miller, and Michael Shvartsman. A scalable measure of loss landscape curvature for analyzing the training dynamics of llms, 2026. URLhttps://arxiv.org/abs/ 2601.16979
-
[27]
Jeremy Cohen, Alex Damian, Ameet Talwalkar, J Zico Kolter, and Jason D. Lee. Under- standing optimization in deep learning with central flows. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id= sIE2rI3ZPs
2025
-
[28]
Pre-training llm without learning rate decay enhances supervised fine-tuning, 2026
Kazuki Yano, Shun Kiyono, Sosuke Kobayashi, Sho Takase, and Jun Suzuki. Pre-training llm without learning rate decay enhances supervised fine-tuning, 2026. URLhttps://arxiv. org/abs/2603.16127
-
[29]
Training dynamics impact post- training quantization robustness, 2026
Albert Catalan-Tatjer, Niccolò Ajroldi, and Jonas Geiping. Training dynamics impact post- training quantization robustness, 2026. URLhttps://arxiv.org/abs/2510.06213
-
[30]
A qualitative study of the dynamic behavior for adaptive gradient algorithms, 2021
Chao Ma, Lei Wu, and Weinan E. A qualitative study of the dynamic behavior for adaptive gradient algorithms, 2021. URLhttps://arxiv.org/abs/2009.06125
-
[31]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. URLhttps://arxiv.org/ abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Nathaniel Pinckney, Christopher Batten, Mingjie Liu, Haoxing Ren, and Brucek Khailany. Revisiting verilogeval: A year of improvements in large-language models for hardware code generation, 2025. URLhttps://arxiv.org/abs/2408.11053
-
[33]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heine- man, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Pyranet: A multi-layered hierarchical dataset for verilog
Bardia Nadimi, Ghali Omar Boutaib, and Hao Zheng. Pyranet: A multi-layered hierarchical dataset for verilog. In2025 62nd ACM/IEEE Design Automation Conference (DAC), page 1–7. IEEE, 2025. doi: 10.1109/dac63849.2025.11133406. URLhttp://dx.doi.org/10.1109/ DAC63849.2025.11133406
-
[35]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021. URLhttps: //arxiv.org/abs/2009.03300. 11
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[36]
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge, 2019. URLhttps: //arxiv.org/abs/1811.00937
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[37]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018. URLhttps://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Memory Aware Synapses: Learning what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuyte- laars. Memory aware synapses: Learning what (not) to forget, 2018. URLhttps://arxiv. org/abs/1711.09601
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. icarl: Incremental classifier and representation learning, 2017. URLhttps://arxiv.org/ abs/1611.07725
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Continual Learning with Deep Generative Replay
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay, 2017. URLhttps://arxiv.org/abs/1705.08690
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Grow, don’t overwrite: Fine-tuning without forgetting, 2026
Dyah Adila, Hanna Mazzawi, Benoit Dherin, and Xavier Gonzalvo. Grow, don’t overwrite: Fine-tuning without forgetting, 2026. URLhttps://arxiv.org/abs/2603.08647
-
[42]
Der: Dynamically expandable representation for class incremental learning, 2021
Shipeng Yan, Jiangwei Xie, and Xuming He. Der: Dynamically expandable representation for class incremental learning, 2021. URLhttps://arxiv.org/abs/2103.16788
-
[43]
Foster: Feature boosting and compression for class-incremental learning, 2022
Fu-Yun Wang, Da-Wei Zhou, Han-Jia Ye, and De-Chuan Zhan. Foster: Feature boosting and compression for class-incremental learning, 2022. URLhttps://arxiv.org/abs/2204. 04662
2022
- [44]
-
[45]
Forget forgetting: Continual learning in a world of abundant memory, 2026
Dongkyu Cho, Taesup Moon, Rumi Chunara, Kyunghyun Cho, and Sungmin Cha. Forget forgetting: Continual learning in a world of abundant memory, 2026. URLhttps://arxiv. org/abs/2502.07274
-
[46]
Loss of plasticity in deep continual learning.Nature, 632 (8026):768–774, 2024
Shibhansh Dohare, J Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A Rupam Mahmood, and Richard S Sutton. Loss of plasticity in deep continual learning.Nature, 632 (8026):768–774, 2024. URLhttps://www.nature.com/articles/s41586-024-07711-7
2024
-
[47]
Continual learning should move beyond incremental classification, 2025
Rupert Mitchell, Antonio Alliegro, Raffaello Camoriano, Dustin Carrión-Ojeda, Antonio Carta, Georgia Chalvatzaki, Nikhil Churamani, Carlo D’Eramo, Samin Hamidi, Robin Hesse, Fabian Hinder, Roshni Ramanna Kamath, Vincenzo Lomonaco, Subarnaduti Paul, Francesca Pistilli, Tinne Tuytelaars, Gido M van de Ven, Kristian Kersting, Simone Schaub-Meyer, and Martin ...
-
[48]
Continual learning for large language models: A survey.arXiv preprint arXiv:2402.01364, 2024
Tongtong Wu, Linhao Luo, Yuan-Fang Li, Shirui Pan, Thuy-Trang Vu, and Gholamreza Haffari. Continual learning for large language models: A survey, 2024. URLhttps: //arxiv.org/abs/2402.01364
-
[49]
Peer pressure: Model-to-model regular- ization for single source domain generalization, 2025
Dong Kyu Cho, Inwoo Hwang, and Sanghack Lee. Peer pressure: Model-to-model regular- ization for single source domain generalization, 2025. URLhttps://arxiv.org/abs/2505. 12745
2025
-
[50]
Task-agnostic continual learning with hybrid probabilistic models
Polina Kirichenko, Mehrdad Farajtabar, Dushyant Rao, Balaji Lakshminarayanan, Nir Levine, Ang Li, Huiyi Hu, Andrew Gordon Wilson, and Razvan Pascanu. Task-agnostic continual learning with hybrid probabilistic models. InICML Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models, 2021. URLhttps://openreview.net/ forum?id=...
2021
-
[51]
Self-generated replay memories for continual neural ma- chine translation, 2024
Michele Resta and Davide Bacciu. Self-generated replay memories for continual neural ma- chine translation, 2024. URLhttps://arxiv.org/abs/2403.13130. 12
-
[52]
Continual pre-training of language models, 2023
Zixuan Ke, Yijia Shao, Haowei Lin, Tatsuya Konishi, Gyuhak Kim, and Bing Liu. Continual pre-training of language models, 2023. URLhttps://arxiv.org/abs/2302.03241
-
[53]
Larsen, Jason Chan Lee, Katherine L
Christina Baek, Ricardo Pio Monti, David Schwab, Amro Abbas, Rishabh Adiga, Cody Blak- eney, Maximilian Böther, Paul Burstein, Aldo Gael Carranza, Alvin Deng, Parth Doshi, Vi- neeth Dorna, Alex Fang, Tony Jiang, Siddharth Joshi, Brett W. Larsen, Jason Chan Lee, Katherine L. Mentzer, Luke Merrick, Haakon Mongstad, Fan Pan, Anshuman Suri, Darren Teh, Jason ...
-
[54]
Buckley, Ja- son Phang, Samuel R
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Ja- son Phang, Samuel R. Bowman, and Ethan Perez. Pretraining language models with human preferences, 2023. URLhttps://arxiv.org/abs/2302.08582
-
[55]
Overtrained language models are harder to fine-tune, 2025
Jacob Mitchell Springer, Sachin Goyal, Kaiyue Wen, Tanishq Kumar, Xiang Yue, Sadhika Malladi, Graham Neubig, and Aditi Raghunathan. Overtrained language models are harder to fine-tune, 2025. URLhttps://arxiv.org/abs/2503.19206
-
[56]
Same pre-training loss, better downstream: Implicit bias matters for language models, 2022
Hong Liu, Sang Michael Xie, Zhiyuan Li, and Tengyu Ma. Same pre-training loss, better downstream: Implicit bias matters for language models, 2022. URLhttps://arxiv.org/ abs/2210.14199
-
[57]
Sharpness-Aware Pretraining Mitigates Catastrophic Forgetting
Ishaan Watts, Catherine Li, Sachin Goyal, Jacob Mitchell Springer, and Aditi Raghu- nathan. Sharpness-aware pretraining mitigates catastrophic forgetting.arXiv preprint arXiv:2605.02105, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Knowledge entropy decay during language model pre- training hinders new knowledge acquisition, 2025
Jiyeon Kim, Hyunji Lee, Hyowon Cho, Joel Jang, Hyeonbin Hwang, Seungpil Won, Youbin Ahn, Dohaeng Lee, and Minjoon Seo. Knowledge entropy decay during language model pre- training hinders new knowledge acquisition, 2025. URLhttps://arxiv.org/abs/2410. 01380
2025
-
[59]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[60]
Root mean square layer normalization.Advances in Neural Information Processing Systems, 32, 2019
Biao Zhang and Rico Sennrich. Root mean square layer normalization.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[61]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[62]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URLhttps: //arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[63]
Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings
Norm Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian Towles, et al. Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings. InProceedings of the 50th annual international symposium on computer architecture, pages 1–14, 2023
2023
-
[64]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URLhttp: //github.com/jax-ml/jax. 13 A Method Details A.1 Self-generated Replay. We generate replay data from th...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.