The Constraint Tax: Measuring Validity-Correctness Tradeoffs in Structured Outputs for Small Language Models
Pith reviewed 2026-06-30 17:36 UTC · model grok-4.3
The pith
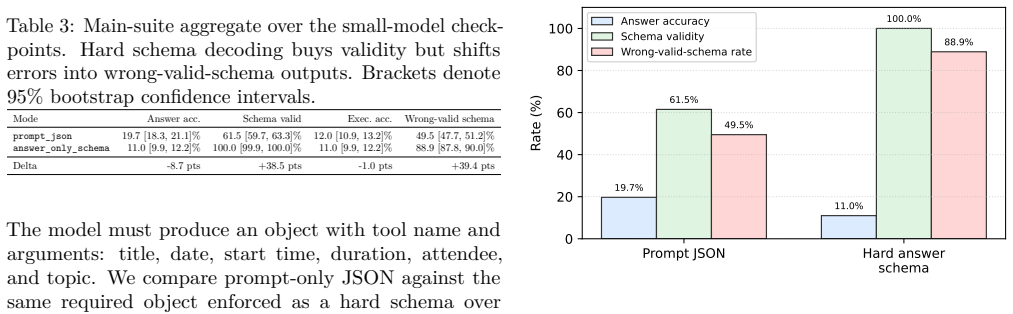
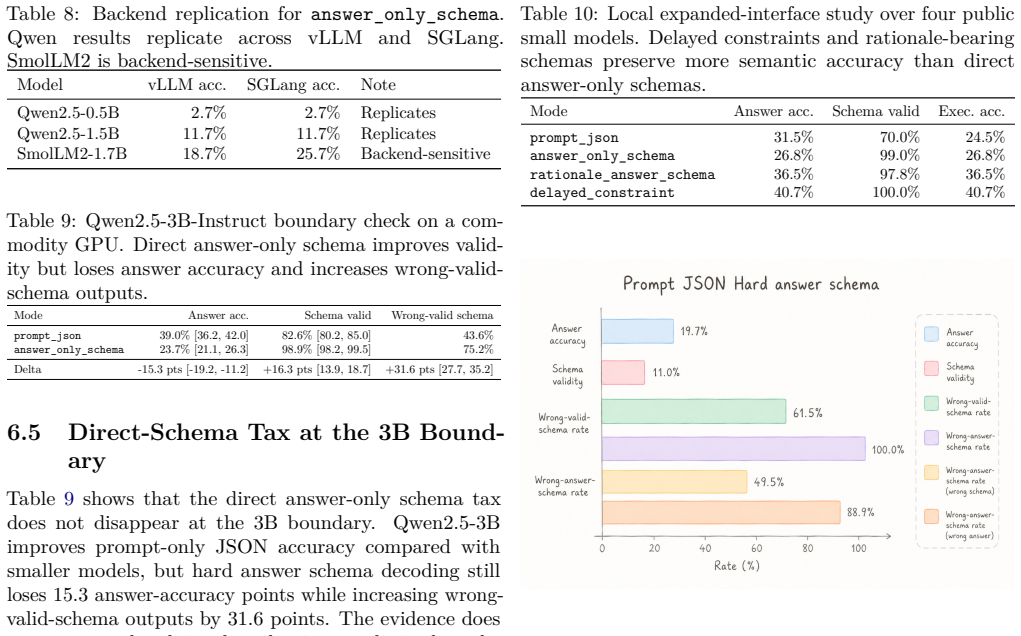
Hard schema constraints on small language models raise validity to 100% but cut answer accuracy from 19.7% to 11%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
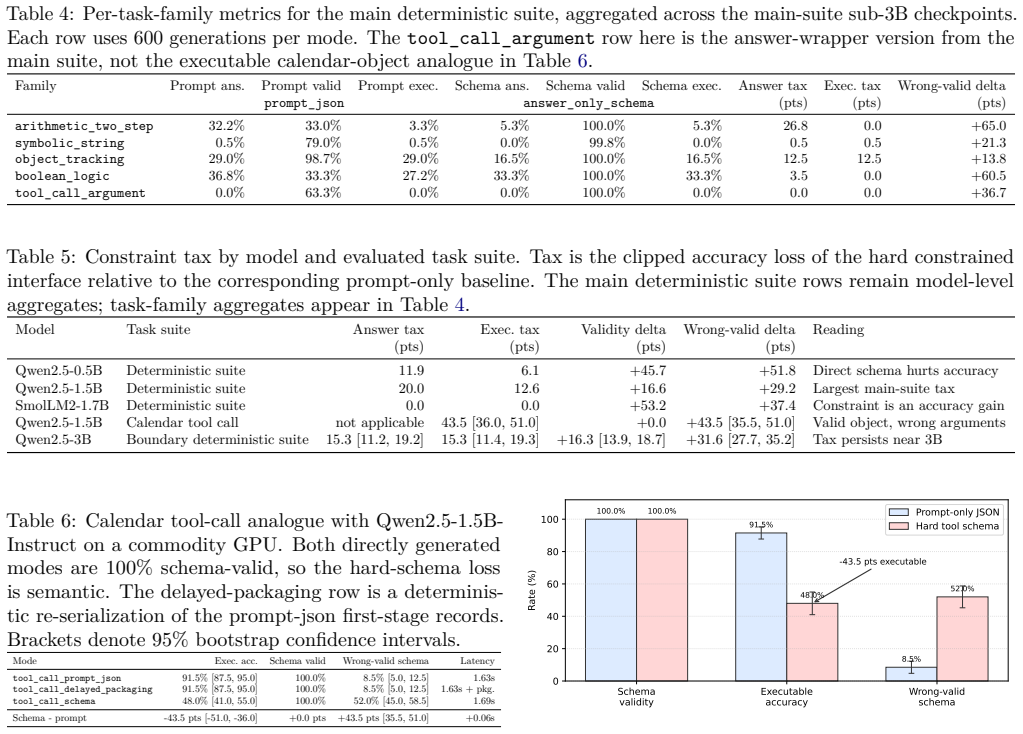
Hard answer-only schema decoding on Qwen2.5-0.5B, Qwen2.5-1.5B, and SmolLM2-1.7B lifts schema validity from 61.5% to 100.0% while lowering answer accuracy from 19.7% to 11.0% and raising the rate of wrong-valid-schema outputs from 49.5% to 88.9%; in a deterministic calendar tool-call task the same models drop from 91.5% to 48.0% executable accuracy even though both modes remain 100% schema-valid. The performance loss is semantic rather than structural, and the tax persists at the 3B scale though delayed packaging (reason first, constrain later) offers partial relief.
What carries the argument
The constraint tax, a protocol that isolates answer and executable accuracy loss by comparing prompt-only generation against hard schema-constrained decoding on identical models, tasks, and problem instances.
If this is right
- Production systems using sub-3B models should track schema validity, answer accuracy, executable accuracy, and wrong-valid-schema rate as four distinct quantities.
- Direct hard-schema use on small models increases the fraction of outputs that are structurally correct yet factually wrong.
- Reasoning without constraints followed by late packaging reduces the observed tax compared with enforcing the schema from the first token.
- The accuracy penalty remains measurable even for models approaching the 3B boundary.
Where Pith is reading between the lines
- Training regimes that explicitly penalize semantic drift under constraints could lower the tax without sacrificing validity.
- On-device applications that prioritize answer correctness over immediate machine readability may prefer prompt-only JSON with post-hoc validation.
- The same fixed-instance comparison method could be applied to larger models to test whether the tax scales with capacity.
Load-bearing premise
The measurement protocol isolates the answer and executable-accuracy loss caused by structured-output constraints at fixed model, fixed task distribution, and fixed problem instances.
What would settle it
Re-running the 15,000 generations on the same three models and tasks while applying hard schemas and finding no drop in answer accuracy or executable accuracy would falsify the central claim.
Figures

read the original abstract
Production LLM systems increasingly require machine-readable outputs: JSON objects, typed traces, regex-constrained fields, and tool-call schemas. This paper targets on-device and low-cost small language model (SLM) deployments, where sub-3B models are attractive for privacy, latency, and commodity hardware but have limited capacity to satisfy schemas while solving tasks. The usual engineering assumption is that hard output constraints improve reliability without changing the underlying answer. We show that this assumption is unsafe for small models. We introduce \emph{constraint tax}, a measurement protocol for isolating the answer and executable-accuracy loss caused by structured-output constraints at fixed model, fixed task distribution, and fixed problem instances. Across 15,000 commodity-GPU generations with Qwen2.5-0.5B, Qwen2.5-1.5B, and SmolLM2-1.7B, hard answer-only schema decoding raises schema validity from 61.5\% to 100.0\%, but lowers answer accuracy from 19.7\% to 11.0\% and increases wrong-valid-schema outputs from 49.5\% to 88.9\%. The strongest industry analogue is a deterministic calendar tool-call task: Qwen2.5-1.5B achieves 91.5\% executable accuracy with prompt-only JSON but only 48.0\% under the same hard tool-call schema, while both modes are 100.0\% schema-valid. The error is semantic, not structural. We also show that the 3B boundary still pays a direct-schema tax and that delayed packaging supports a constructive design pattern: reason free, constrain late. The practical conclusion is direct: production systems should report schema validity, answer accuracy, executable accuracy, and wrong-valid-schema rate separately.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the 'constraint tax' as an empirical measurement protocol to quantify the trade-off between schema validity and answer/executable accuracy when applying hard structured-output constraints (e.g., JSON schemas, tool-call formats) to small language models (<3B parameters). Using 15,000 generations on Qwen2.5-0.5B, Qwen2.5-1.5B, and SmolLM2-1.7B, it reports that hard decoding raises validity from 61.5% to 100% but drops answer accuracy from 19.7% to 11.0% and increases wrong-valid outputs from 49.5% to 88.9%. A calendar tool-call task shows executable accuracy falling from 91.5% (prompt-only JSON) to 48.0% (hard schema) at 100% validity in both cases. The work concludes that production systems should track validity, accuracy, and wrong-valid rates separately and recommends 'reason free, constrain late' as a mitigation.
Significance. If the measurement protocol holds under scrutiny, the paper provides a useful, reproducible empirical framework for assessing structured-output costs in SLM deployments on commodity hardware. The fixed-model/fixed-instance design isolates semantic degradation from structural failures, and the calendar task offers a concrete industry-relevant demonstration. This challenges the common assumption that hard constraints are cost-free for reliability and supplies actionable guidance on metric reporting and delayed packaging.
major comments (2)
- [Abstract] Abstract and experimental protocol: The 15,000-generation results report specific percentages (e.g., 61.5% to 100% validity, 19.7% to 11.0% accuracy) but provide no details on task selection, instance sampling method, statistical tests, or error bars. This information is load-bearing for the central claim that the protocol isolates the constraint tax at fixed models, tasks, and instances.
- [Calendar tool-call task] Calendar tool-call task description: The executable-accuracy drop (91.5% to 48.0%) is presented as evidence of semantic cost, but the manuscript must explicitly define 'executable accuracy,' how it is computed in the deterministic calendar setting, and confirm that both arms achieve 100% schema validity without additional post-processing.
minor comments (1)
- The phrase 'wrong-valid-schema outputs' is used repeatedly; a single clear definition or example in the methods would improve readability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each of the major comments below, indicating the revisions we will make to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental protocol: The 15,000-generation results report specific percentages (e.g., 61.5% to 100% validity, 19.7% to 11.0% accuracy) but provide no details on task selection, instance sampling method, statistical tests, or error bars. This information is load-bearing for the central claim that the protocol isolates the constraint tax at fixed models, tasks, and instances.
Authors: We agree that the experimental protocol requires more explicit documentation to support the central claims. In the revised version, we will add a dedicated subsection in the methods describing the task selection process, the instance sampling method (including how the 15,000 generations were distributed across models and conditions), any statistical tests performed, and error bars or confidence intervals for the reported metrics. This will ensure the isolation of the constraint tax is fully transparent. revision: yes
-
Referee: [Calendar tool-call task] Calendar tool-call task description: The executable-accuracy drop (91.5% to 48.0%) is presented as evidence of semantic cost, but the manuscript must explicitly define 'executable accuracy,' how it is computed in the deterministic calendar setting, and confirm that both arms achieve 100% schema validity without additional post-processing.
Authors: We will revise the manuscript to include an explicit definition of executable accuracy for the calendar tool-call task. We will detail how it is computed in the deterministic setting (e.g., by checking if the generated tool call produces the correct calendar action when executed) and confirm that both the prompt-only JSON and hard schema conditions achieve 100% schema validity without any post-processing, as already indicated in the results. This clarification will better distinguish the semantic degradation from structural issues. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical measurement study. It reports observed validity, answer accuracy, and executable accuracy rates from 15,000 generations across fixed models, tasks, and instances under prompt-only vs. hard-schema conditions. No equations, derivations, fitted parameters, or self-citations appear in the provided text that would reduce any reported tax to an input quantity by construction. The measurement protocol isolates constraint effects without redefining or predicting quantities from the same data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected tasks (including calendar tool-call) and models (Qwen2.5-0.5B, 1.5B, SmolLM2-1.7B) are representative of production SLM deployments requiring structured outputs.
Forward citations
Cited by 2 Pith papers
-
Capacity, Not Format: Rethinking Structured Reasoning Failures
Empirical study across 4 models and 5 benchmarks finds that structured output formats degrade LLM reasoning performance primarily in capacity-limited models, with recovery via delayed formatting.
-
Constraint Tax in Open-Weight LLMs: An Empirical Study of Tool Calling Suppression Under Structured Output Constraints
Open-weight LLMs exhibit tool suppression under joint tool-calling and JSON-schema constraints due to grammar token masking; a two-pass inference method restores tool use.
Reference graph
Works this paper leans on
-
[1]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.NeurIPS, 2022.https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv:2110.14168, 2021. https://arxiv.org/abs/ 2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.ICLR, 2023.https: //arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Lan- guage models can teach themselves to use tools.NeurIPS, 2023. https://arxiv.org/abs/2302.04761
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Efficient Guided Generation for Large Language Models
Brandon T. Willard and Rémi Louf. Efficient guided generation for large language models. arXiv:2307.09702, 2023. https: //arxiv.org/abs/2307.09702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Prompting is programming: A query language for large lan- guage models
Luca Beurer-Kellner, Marc Fischer, and Martin Vechev. Prompting is programming: A query language for large lan- guage models. arXiv:2212.06094, 2022. https://arxiv.org/ abs/2212.06094
-
[7]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention.SOSP, 2023.https://arxiv.org/abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model pro- grams.NeurIPS, 2024.https://arxiv.org/abs/2312.07104
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
JSON Schema.https://json-schema.org/
-
[10]
Structured outputs documentation
vLLM Project. Structured outputs documentation. https: //docs.vllm.ai/en/latest/features/structured_outputs/
-
[11]
Structured outputs documenta- tion
SGLang Project. Structured outputs documenta- tion. https://docs.sglang.io/docs/advanced_features/ structured_outputs 8
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.