Augment Engineering: A Methodology for Multi-Tool AI Orchestration Across Professional Domains
Pith reviewed 2026-06-30 14:25 UTC · model grok-4.3
The pith
A single practitioner can orchestrate purpose-built AI tools across seven professional domains by treating prompt and context engineering as portable meta-skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
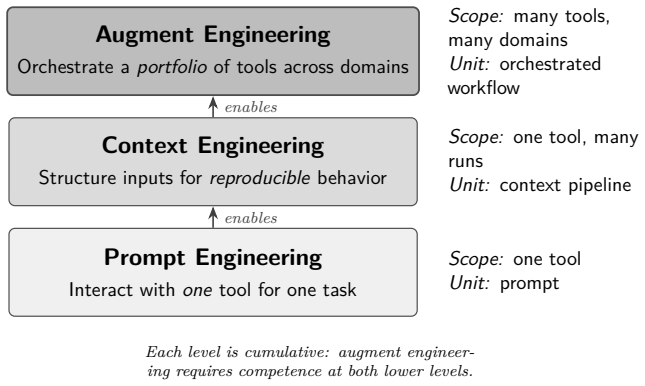
Augment Engineering completes a three-discipline progression: Prompt Engineering (one tool), Context Engineering (reproducible pipelines), Augment Engineering (a portfolio of tools across domains). It defines Augment Engineering as the discipline of orchestrating multiple purpose-built AI tools across distinct professional domains by applying prompt engineering at the interaction level and context engineering for structured input pipelines as portable competencies.
What carries the argument
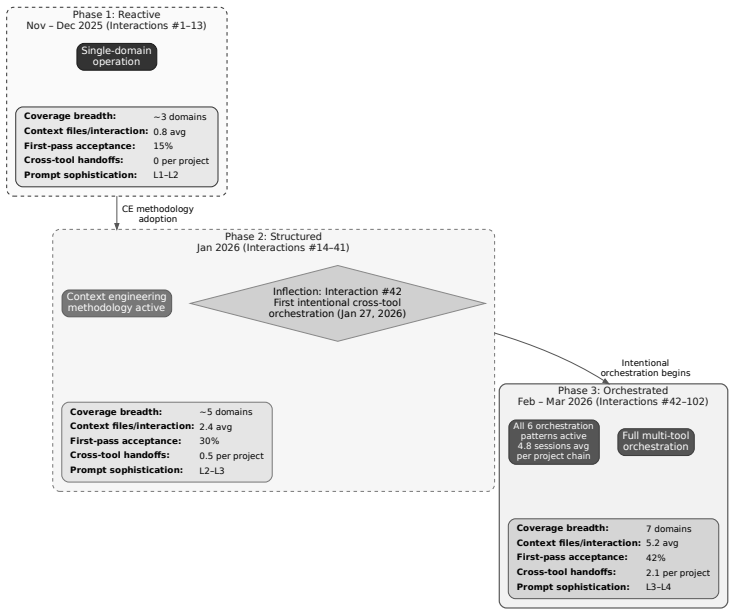
The six-phase orchestration methodology that coordinates prompt and context engineering across a ten-component stack spanning seven domains.
If this is right
- Organizations could replace multiple domain specialists with practitioners trained only in the portable meta-skills.
- Work products in separate professional domains become producible by one person through tool orchestration.
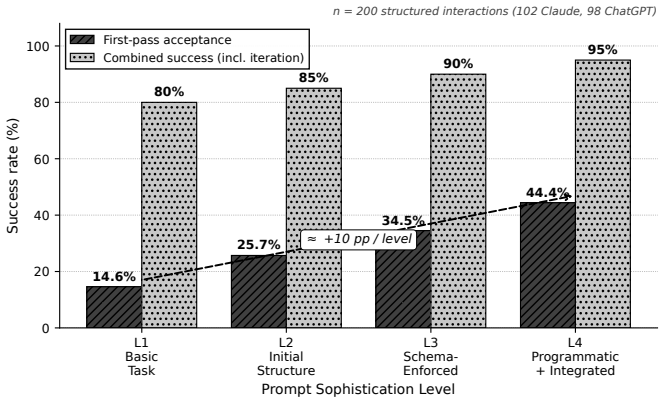
- First-pass acceptance rates increase as prompt sophistication rises, per the observed Cochran-Armitage trend.
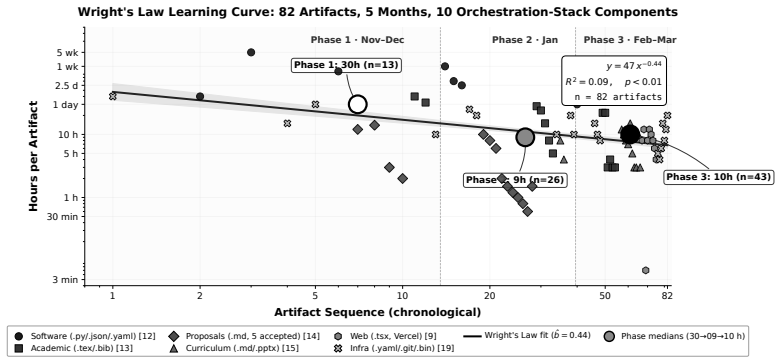
- Artifact production accelerates across the portfolio as measured by the Wright's Law fit on 82 artifacts.
Where Pith is reading between the lines
- The approach implies training programs could prioritize meta-skill instruction over domain-specific expertise.
- If portability holds, the same orchestration stack could extend to new AI tools in additional fields without relearning.
- Single-practitioner results generate the hypothesis that multi-practitioner teams might achieve similar coverage with shared meta-skills.
Load-bearing premise
The meta-skills of prompt engineering and context engineering transfer effectively across different AI tools and professional domains without meaningful loss of performance or the need for domain-specific retraining.
What would settle it
A multi-practitioner replication study that finds no rise in first-pass acceptance rates with increasing prompt sophistication across domains would falsify the portability claim.
Figures

read the original abstract
Organizations increasingly deploy separate purpose-built AI tools across professional domains, often hiring domain specialists for each, recreating the staffing models AI was expected to transform. Yet the meta-skills that make these tools effective, prompt engineering (interaction-level optimization) and context engineering (structured input pipeline design), are domain-portable: a practitioner who masters them can apply them to any purpose-built AI tool in any domain. This paper defines Augment Engineering as the discipline of orchestrating multiple purpose-built AI tools across distinct professional domains, applying prompt and context engineering as portable competencies that transfer across tool boundaries. We present a six-phase orchestration methodology and four portability metrics. A 5-month formative case study (November 2025 to March 2026) documents a single practitioner applying these skills across a ten-component orchestration stack spanning seven professional domains, producing work products that would traditionally involve separate domain specialists. Two quantitative observations are consistent with the framework's predictions: a Cochran-Armitage trend test (n = 200 interactions across two chat LLMs, p < 0.01) shows first-pass acceptance rising with prompt-sophistication level, and a Wright's Law fit (n = 82 artifacts, p < 0.01) shows production acceleration across the artifact portfolio. Because all observations come from a single practitioner, the inferential statistics are exploratory and hypothesis-generating rather than confirmatory; portability across the full portfolio awaits multi-practitioner replication. Augment Engineering completes a three-discipline progression: Prompt Engineering (one tool), Context Engineering (reproducible pipelines), Augment Engineering (a portfolio of tools across domains).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines Augment Engineering as the orchestration of multiple purpose-built AI tools across professional domains by treating prompt engineering and context engineering as portable meta-skills. It presents a six-phase methodology and four portability metrics, then reports a 5-month single-practitioner case study (n=200 interactions, n=82 artifacts) spanning seven domains and ten tools. Exploratory statistics (Cochran-Armitage trend test p<0.01; Wright's Law fit p<0.01) are offered as consistent with the framework, with explicit caveats that results are hypothesis-generating and require multi-practitioner replication.
Significance. If multi-practitioner studies later confirm that prompt and context engineering transfer across tool and domain boundaries without substantial retraining, the framework could alter how organizations assemble AI-augmented teams by reducing the need for separate domain specialists. The explicit labeling of the statistics as exploratory and the call for replication constitute a strength in scope management. The work positions itself as completing a three-discipline progression from prompt engineering to context engineering to multi-tool orchestration.
major comments (2)
- [Case study section] Case study section: the Cochran-Armitage trend test (n=200 interactions across two chat LLMs) and Wright's Law fit (n=82 artifacts) are both computed on interactions and artifacts generated inside the same 5-month case study used to develop and instantiate the Augment Engineering framework, so the supporting observations are not independent of the framework's application.
- [Central claim] Central claim (abstract and discussion): the assertion that prompt and context engineering transfer effectively across seven professional domains and tool boundaries without meaningful domain-specific retraining or performance loss rests on evidence from a single practitioner. This design cannot separate the claimed portable competencies from the individual's prior expertise, selection effects, or idiosyncratic aptitude.
Simulated Author's Rebuttal
We thank the referee for these precise observations on the case study design and the scope of the central claim. Both comments correctly identify limitations inherent to a single-practitioner formative study. We respond to each point below and indicate the revisions that will be made.
read point-by-point responses
-
Referee: [Case study section] Case study section: the Cochran-Armitage trend test (n=200 interactions across two chat LLMs) and Wright's Law fit (n=82 artifacts) are both computed on interactions and artifacts generated inside the same 5-month case study used to develop and instantiate the Augment Engineering framework, so the supporting observations are not independent of the framework's application.
Authors: We agree that the quantitative observations are generated within the same case study in which the framework was developed and applied, and therefore lack independence from the framework itself. The manuscript already labels these results as exploratory and hypothesis-generating. In revision we will expand the case study and limitations sections to state this non-independence more explicitly and to discuss its consequences for interpreting the trend tests and power-law fits. revision: yes
-
Referee: [Central claim] Central claim (abstract and discussion): the assertion that prompt and context engineering transfer effectively across seven professional domains and tool boundaries without meaningful domain-specific retraining or performance loss rests on evidence from a single practitioner. This design cannot separate the claimed portable competencies from the individual's prior expertise, selection effects, or idiosyncratic aptitude.
Authors: The manuscript already qualifies the portability claim by noting that results are from a single practitioner and that multi-practitioner replication is required. We accept that the present design cannot isolate portable meta-skills from individual factors. We will revise the abstract, introduction, and discussion to reframe the central claim as a hypothesis that is consistent with the observed data rather than a confirmed result, and we will strengthen the language calling for future multi-practitioner studies. revision: yes
Circularity Check
Case-study observations labeled as 'framework predictions' but generated inside the same single-practitioner application used to define the framework
specific steps
-
fitted input called prediction
[Abstract]
"Two quantitative observations are consistent with the framework's predictions: a Cochran-Armitage trend test (n = 200 interactions across two chat LLMs, p < 0.01) shows first-pass acceptance rising with prompt-sophistication level, and a Wright's Law fit (n = 82 artifacts, p < 0.01) shows production acceleration across the artifact portfolio. Because all observations come from a single practitioner, the inferential statistics are exploratory and hypothesis-generating rather than confirmatory."
The n=200 interactions and n=82 artifacts are the direct output of the single-practitioner case study that was used both to develop the Augment Engineering methodology and to apply it across seven domains; therefore the trend test and power-law fit are computed on the same data that instantiate the framework rather than serving as out-of-sample predictions of portability.
full rationale
The paper's central claim is that prompt/context engineering are portable meta-skills enabling cross-domain orchestration. The only empirical support consists of a Cochran-Armitage test and Wright's Law fit performed on the identical set of 200 interactions and 82 artifacts produced during the 5-month formative case study that instantiated the six-phase methodology. The paper itself states these statistics are 'exploratory and hypothesis-generating' and require multi-practitioner replication, so the load-bearing quantitative support reduces to a description of the same data rather than an independent test of transfer. No self-citation chain or definitional loop exists; the circularity is limited to the 'predictions' step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompt engineering and context engineering skills are domain-portable across different purpose-built AI tools and professional domains.
invented entities (1)
-
Augment Engineering
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Context Engineering: A Practitioner Methodology for Structured Human-AI Collaboration
E. Calboreanu, Context engineering: A methodology for structured human-AI collaboration, Working Paper v3.1, Capitol Technology Uni- versity, preprint: arXiv:2604.04258 (2026). ORCID:https://orcid. org/0009-0008-9194-0589. (Apr. 2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
J. White, Q. Fu, S. Hays, et al., A prompt pattern catalog to enhance prompt engineering with ChatGPT, arXiv preprint arXiv:2302.11382 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [3]
-
[4]
E. Calboreanu, LATTICE: Layered architecture for trusted and trans- parent intelligence in constrained environments, SSRN,https://ssrn. com/abstract=6151128(Jan. 2026).doi:10.2139/ssrn.6151128. 49
-
[5]
E. Calboreanu, TRACE: Trusted runtime for autonomous contain- ment and evidence, SSRN,https://ssrn.com/abstract=6212818 (Feb. 2026).doi:10.2139/ssrn.6212818
-
[6]
E. Calboreanu, MANDATE: Multi-agent nominal decomposition for autonomous task execution, SSRN,https://ssrn.com/abstract= 6170328(Feb. 2026).doi:10.2139/ssrn.6170328
-
[7]
Calboreanu, Closed-loop autonomous software development via jira- integrated backlog orchestration, Tech
E. Calboreanu, Closed-loop autonomous software development via jira- integrated backlog orchestration, Tech. rep., Swift North AI Lab, in preparation, targeting theAutomated Software Engineering(Springer) special issue, 2026. Preprint available from the corresponding author upon request (2026)
2026
-
[8]
S. Peng, E. Kalliamvakou, P. Cihon, M. Demirer, The impact of AI on developer productivity: Evidence from GitHub Copilot, arXiv preprint arXiv:2302.06590 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
J. Yang, C. E. Jimenez, A. Wettig, et al., SWE-agent: Agent- computer interfaces enable automated software engineering, arXiv preprint arXiv:2405.15793 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Chase, LangChain: Building applications with LLMs through com- posability, GitHub repository,https://github.com/langchain-ai/ langchain(2023)
H. Chase, LangChain: Building applications with LLMs through com- posability, GitHub repository,https://github.com/langchain-ai/ langchain(2023)
2023
-
[11]
T. B. Richards, Auto-GPT: An autonomous GPT-4 experiment, GitHub repository,https://github.com/Significant-Gravitas/ Auto-GPT(2023)
2023
-
[12]
J. a. Moura, CrewAI: Framework for orchestrating role-playing, autonomous AI agents, GitHub repository,https://github.com/ crewAIInc/crewAI(2024)
2024
-
[13]
S. Hong, M. Zhuge, J. Chen, et al., MetaGPT: Meta programming for a multi-agent collaborative framework, arXiv preprint arXiv:2308.00352 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Guidelines for Human-AI Interaction,
S. Amershi, D. Weld, M. Vorvoreanu, et al., Guidelines for human-AI interaction, in: Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, 2019.doi:10.1145/3290605.3300233. 50
-
[15]
G. Bansal, T. Wu, J. Zhou, et al., Does the whole exceed its parts? the effect of AI explanations on complementary team performance, Pro- ceedings of the 2021 CHI Conference on Human Factors in Computing Systems (2021).doi:10.1145/3411764.3445717
-
[16]
V. Lai, C. Chen, A. Smith-Renner, et al., Towards a science of human- AI decision making: An overview of design space in empirical human- subject studies, Proceedings of the 2023 ACM Conference on Fair- ness, Accountability, and Transparency (2023).doi:10.1145/3593013. 3594087
-
[17]
J. Wei, X. Wang, D. Schuurmans, et al., Chain-of-thought prompting elicits reasoning in large language models, Advances in Neural Informa- tion Processing Systems 35 (2022)
2022
- [18]
-
[19]
D. H. Autor, Why are there still so many jobs? the history and future of workplace automation, Journal of Economic Perspectives 29 (3) (2015) 3–30
2015
-
[20]
Acemoglu, P
D. Acemoglu, P. Restrepo, Automation and new tasks: How technology displaces and reinstates labor, Journal of Economic Perspectives 33 (2) (2019) 3–30
2019
-
[21]
E. Brynjolfsson, D. Li, L. R. Raymond, Generative AI at work, Quar- terly Journal of Economics 140 (2) (2025) 889–942.doi:10.1093/qje/ qjae044
-
[22]
A. Sahay, A. Indamutsa, D. Di Ruscio, A. Pierantonio, Supporting the understanding and comparison of low-code development platforms, in: Proceedings of the 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), 2020, pp. 171–178.doi:10.1109/ SEAA51224.2020.00036
-
[23]
Hutter, Learning curve theory, arXiv preprint arXiv:2102.04074 (2021)
M. Hutter, Learning curve theory, arXiv preprint arXiv:2102.04074 (2021)
-
[24]
T. Viering, M. Loog, The shape of learning curves: A review, IEEE Transactions on Pattern Analysis and Machine Intelligence 51 44 (12) (2022) 9578–9597, arXiv:2103.10948.doi:10.1109/TPAMI.2021. 3120763
-
[25]
Y. Kim, K. Gu, C. Park, et al., Towards a science of scaling agent systems, arXiv preprint arXiv:2512.08296 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
2024.doi:10.48550/arXiv.2407.19098
G. Fragiadakis, et al., Evaluating human-AI collaboration: A review and methodological framework, arXiv preprint arXiv:2407.19098 (2024)
-
[27]
T. P. Wright, Factors affecting the cost of airplanes, Journal of the Aeronautical Sciences 3 (4) (1936) 122–128.doi:10.2514/8.155
- [28]
-
[29]
A. Millinghoffer, B. Bolgár, P. Antal, Characterization of transfer using multi-task learning curves, arXiv preprint arXiv:2512.24866 (2025)
- [30]
- [31]
- [32]
-
[33]
J. Su, et al., Difficulty-aware agent orchestration in LLM-powered work- flows, in: arXiv preprint arXiv:2509.11079, 2025
-
[34]
Y. Shao, et al., Future of work with AI agents: Auditing automation and augmentation potential across the U.S. workforce, arXiv preprint arXiv:2506.06576 (2025)
-
[35]
H. Xu, et al., The evolution of tool use in LLM agents: From single-tool call to multi-tool orchestration, arXiv preprint arXiv:2603.22862 (2026). 52
-
[36]
National Institute of Standards and Technology, Artificial intelligence risk management framework (AI RMF 1.0), Special Publication 100-1, NIST (2023).doi:10.6028/NIST.AI.100-1
-
[37]
Chapman, How long does it take to create learning?, Tech
B. Chapman, How long does it take to create learning?, Tech. rep., Chap- man Alliance, research study on e-learning and instructor-led training development ratios (2010)
2010
-
[38]
C. Wohlin, P. Runeson, M. Höst, M. C. Ohlsson, B. Regnell, A. Wesslén, Experimentation in Software Engineering, Springer, Berlin, Heidelberg, 2012.doi:10.1007/978-3-642-29044-2
-
[39]
E. L. Thorndike, R. S. Woodworth, The influence of improvement in one mental function upon the efficiency of other functions, Psychological Review 8 (3) (1901) 247–261
1901
-
[40]
S. M. Barnett, S. J. Ceci, When and where do we apply what we learn? a taxonomy for far transfer, Psychological Bulletin 128 (4) (2002) 612–637. doi:10.1037/0033-2909.128.4.612
-
[41]
S. Noy, W. Zhang, Experimental evidence on the productivity effects of generative artificial intelligence, Science 381 (6654) (2023) 187–192. doi:10.1126/science.adh2586
-
[42]
A. Merali, Scaling laws for economic productivity: Experimental ev- idence in LLM-assisted translation, arXiv preprint arXiv:2409.02391 (2024)
-
[43]
M. Chiodo, et al., Formalising human-in-the-loop: Computational re- ductions, failure modes, and legal-moral responsibility, arXiv preprint arXiv:2505.10426 (2025)
-
[44]
arXiv preprint arXiv:2601.20245 , year =
J. H. Shen, A. Tamkin, How AI impacts skill formation, arXiv preprint arXiv:2601.20245 (2026). 53 Table 3: Orchestration stack inventory for the case study practitioner: fiveAI tools, where prompt and context engineering skills are the primary mode of operation, and fiveinfrastructure components, whose adoption follows traditional learning curves but whic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.