RepoMirage: Probing Repository Context Reasoning in Code Agents with Perturbations
Pith reviewed 2026-06-29 20:51 UTC · model grok-4.3
The pith
Code agents lose most of their issue-solving ability when repository structure is perturbed while meaning stays intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
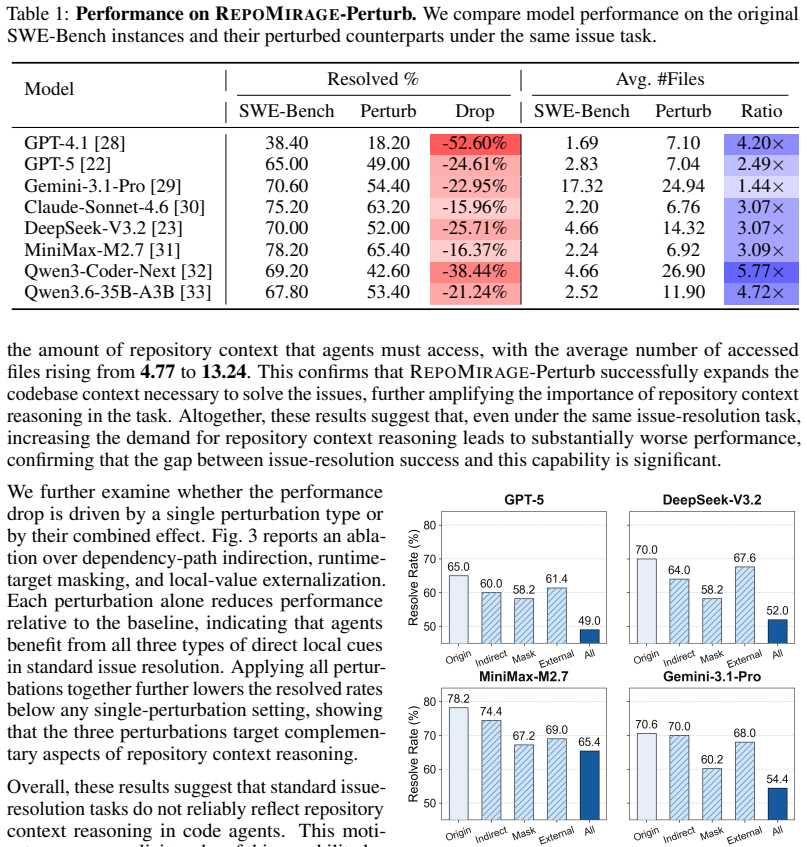
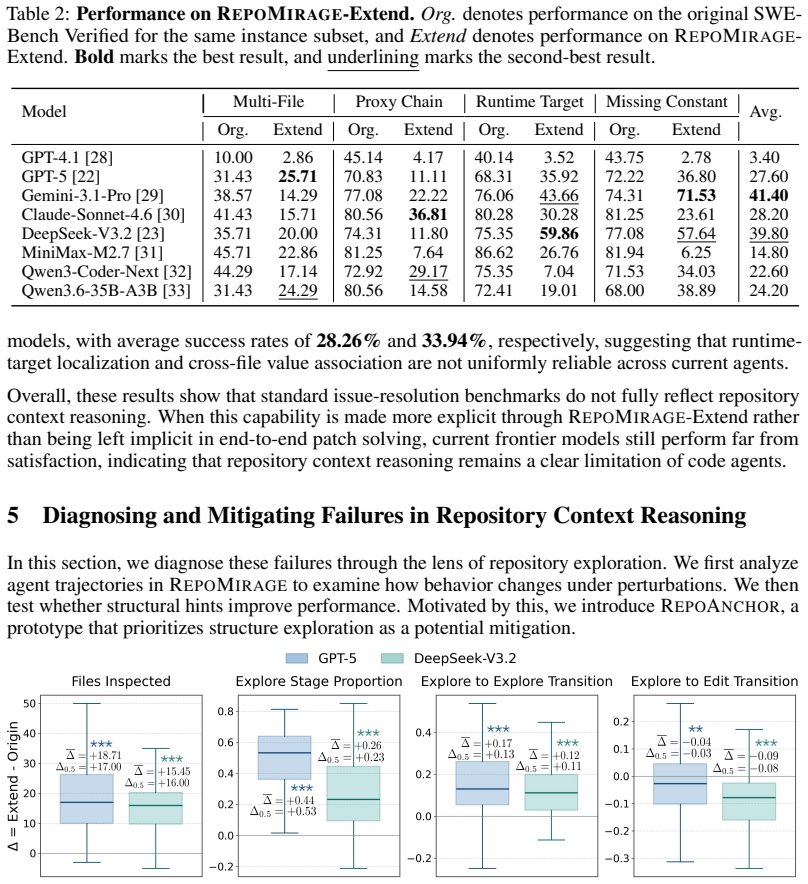
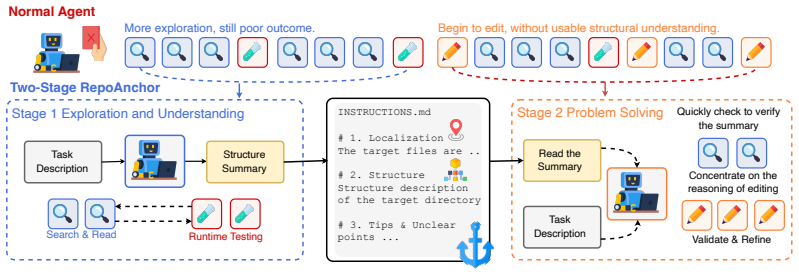
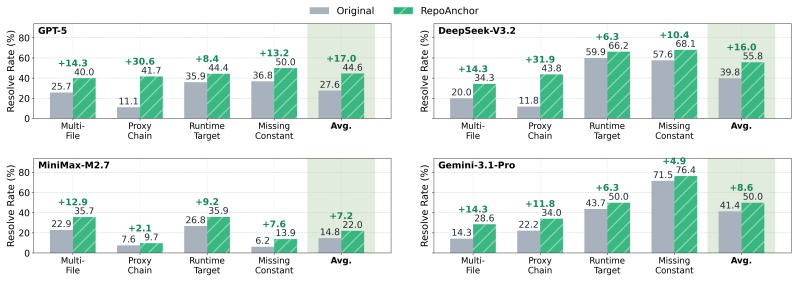
RepoMirage shows that current code agents exhibit a significant deficiency in repository context reasoning: semantics-preserving repository-level perturbations cause clear performance drops when correct solutions require wider context access, and converting the targeted structural bottlenecks into explicit tasks reduces average success from 66.8 percent to 25.3 percent; trajectory analysis further reveals exploration drift, where agents access broader context yet fail to convert it into effective structure information, while a structure-first prototype workflow yields notable gains.
What carries the argument
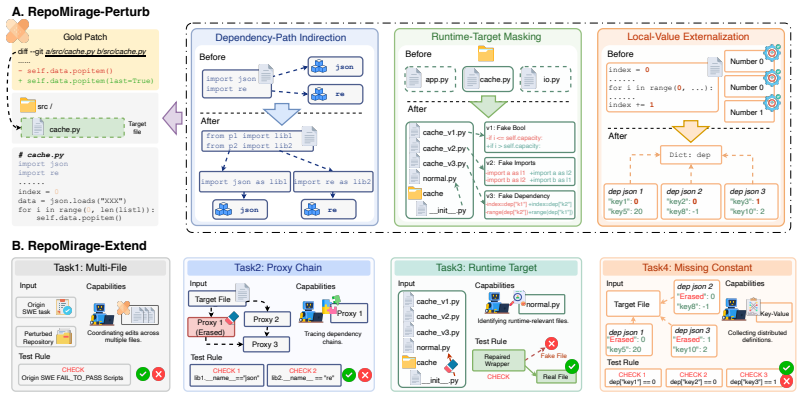
RepoMirage, a two-stage evaluation suite built on SWE-Bench Verified that uses semantics-preserving repository-level perturbations to increase the demand for context reasoning.
If this is right
- Agents that solve issues under the original repository layout lose most of that capability once structural access patterns are altered.
- Trajectory logs show agents reach more files after perturbation but still fail to extract usable structural relations.
- A workflow that first builds explicit structural scaffolding and only then solves the problem produces measurable gains over standard end-to-end approaches.
- The gap appears not only in issue resolution but in any task whose solution depends on cross-file relations.
Where Pith is reading between the lines
- Benchmarks that omit structural perturbations may systematically overstate agent capability on real repositories.
- Methods that treat repository navigation as a distinct, first-class step could transfer to other long-context code tasks such as refactoring or test generation.
- The performance gap may shrink if agents are trained with explicit rewards for recovering file-relation graphs rather than only for final patch correctness.
Load-bearing premise
The observed performance drops are caused specifically by insufficient repository context reasoning rather than by side effects of the perturbations, task reformulation, or agent exploration behavior.
What would settle it
Run the same agents on the perturbed repositories after supplying an explicit, complete structural map of file relations; if success rates remain near the original 66.8 percent, the claim that the drop stems from missing context reasoning would be supported.
Figures






read the original abstract
Code agents are currently having skillful performance on repository-level software engineering benchmarks, but it remains unclear whether success on end-to-end tasks such as issue resolution truly reflects repository context reasoning, the ability to identify the task-relevant information across multiple files and reason over the relations among them. To investigate this question, we introduce RepoMirage, a two-stage evaluation suite built on SWE-Bench Verified that adopts perturbation as a diagnostic tool to increase the demand for context reasoning by transforming how the repository is exposed. First, RepoMirage-Perturb applies three types of semantics-preserving repository-level perturbations, revealing a clear performance drop when correct solving requires broader context access. RepoMirage-Extend further turns perturbation-targeted structural bottlenecks into explicit tasks beyond issue resolution, where the average performance declines from 66.8% in the original setting to 25.3%, indicating a significant deficiency in repository context reasoning. Further trajectory analysis reveals an exploration drift, where agents access broader repository context but fail to turn it into effective structure information. Motivated by this observation, we propose RepoAnchor, a structure-first prototype workflow that separates repository exploration from downstream problem solving, and show that explicit structural scaffolding yields notable gains. These results uncover an previously overlooked gap in repository context reasoning for code agents and suggest that stronger structure-aware methods are potential to improve them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RepoMirage, a two-stage benchmark built on SWE-Bench Verified that uses semantics-preserving repository perturbations (RepoMirage-Perturb) followed by task reformulation (RepoMirage-Extend) to probe whether code agents' success on issue resolution reflects genuine repository context reasoning. It reports a drop from 66.8% to 25.3% average performance on the extended tasks, trajectory analysis showing exploration drift, and a structure-first prototype (RepoAnchor) that yields gains, concluding that current agents have a significant deficiency in repository context reasoning.
Significance. If the perturbations and reformulations cleanly isolate context-reasoning demand without introducing confounding task hardness or exploration costs, the work would identify a previously under-examined limitation in repository-level code agents and motivate structure-aware scaffolding methods. The empirical framing on an external benchmark and the proposal of an explicit workflow are positive features.
major comments (3)
- [§4] §4 (RepoMirage-Extend): the claim that the 66.8% → 25.3% drop demonstrates a 'significant deficiency in repository context reasoning' assumes the task reformulation affects only structural access demand. No ablation is described that holds task formulation, exploration budget, and non-context difficulty constant while varying only the perturbation-induced structural bottlenecks; without such controls the attribution does not follow.
- [§3] §3 (RepoMirage-Perturb): the three semantics-preserving perturbations are presented as increasing context-reasoning demand, yet the manuscript provides no quantitative verification that the perturbations leave file-access costs, search-heuristic compatibility, and implicit task hardness unchanged. If any of these factors shift, the observed performance decline cannot be isolated to context reasoning.
- [§5] Trajectory analysis (mentioned in abstract and §5): the reported 'exploration drift' is offered as supporting evidence, but the paper does not report statistical controls or baseline comparisons that rule out changes in agent search heuristics or file-access costs as the primary driver of the drift.
minor comments (2)
- [Abstract] Abstract: 'an previously overlooked gap' should read 'a previously overlooked gap'.
- The manuscript should include explicit data-exclusion rules, statistical significance tests on the reported drops, and the precise definition of 'average performance' (e.g., pass@1, success rate across instances) to allow verification.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that additional quantitative controls and ablations would strengthen the isolation of repository context reasoning effects in our experiments. We will revise the manuscript to incorporate these elements as outlined below.
read point-by-point responses
-
Referee: [§4] §4 (RepoMirage-Extend): the claim that the 66.8% → 25.3% drop demonstrates a 'significant deficiency in repository context reasoning' assumes the task reformulation affects only structural access demand. No ablation is described that holds task formulation, exploration budget, and non-context difficulty constant while varying only the perturbation-induced structural bottlenecks; without such controls the attribution does not follow.
Authors: We acknowledge that an explicit ablation isolating only the structural access demand would provide stronger evidence. In the revised manuscript, we will add such an ablation study in §4, where we compare performance under controlled conditions that vary the structural bottlenecks while keeping task formulation, exploration budget, and other difficulty factors constant. This will help confirm that the performance drop is attributable to context reasoning demands. revision: yes
-
Referee: [§3] §3 (RepoMirage-Perturb): the three semantics-preserving perturbations are presented as increasing context-reasoning demand, yet the manuscript provides no quantitative verification that the perturbations leave file-access costs, search-heuristic compatibility, and implicit task hardness unchanged. If any of these factors shift, the observed performance decline cannot be isolated to context reasoning.
Authors: The perturbations were constructed to preserve semantics and task solutions while altering repository structure to necessitate broader context access. However, we agree that quantitative verification of unchanged factors would be valuable. We will revise §3 to include quantitative comparisons, such as metrics on file-access costs, search compatibility, and task hardness before and after perturbations, to demonstrate that these remain consistent. revision: yes
-
Referee: [§5] Trajectory analysis (mentioned in abstract and §5): the reported 'exploration drift' is offered as supporting evidence, but the paper does not report statistical controls or baseline comparisons that rule out changes in agent search heuristics or file-access costs as the primary driver of the drift.
Authors: The trajectory analysis in §5 illustrates that agents access more files but fail to effectively use the structural information. To strengthen this, we will incorporate statistical controls and baseline comparisons in the revised manuscript to rule out alternative drivers such as changes in search heuristics or file-access costs. revision: yes
Circularity Check
Empirical evaluation on external benchmark; no circular derivations
full rationale
The paper reports experimental results from applying semantics-preserving perturbations to the external SWE-Bench Verified benchmark and measuring agent performance drops (66.8% to 25.3%). No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. Central claims rest on direct empirical observations and trajectory analysis rather than any self-definitional, fitted-input, or self-citation reductions. The work is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SWE-Bench Verified is a valid benchmark for measuring repository-level code agent performance
Reference graph
Works this paper leans on
-
[1]
Evaluating large language models in class-level code generation
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. Evaluating large language models in class-level code generation. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, 2024
2024
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Measuring coding challenge competence with apps.NeurIPS, 2021
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with apps.NeurIPS, 2021
2021
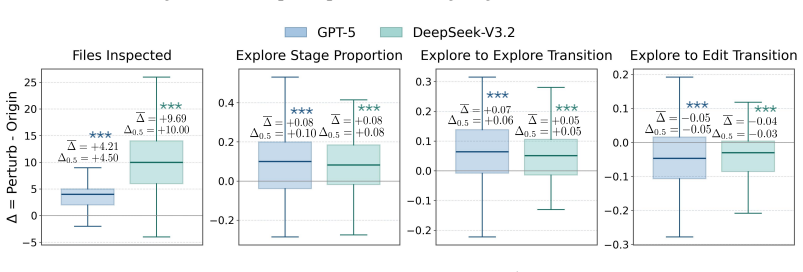
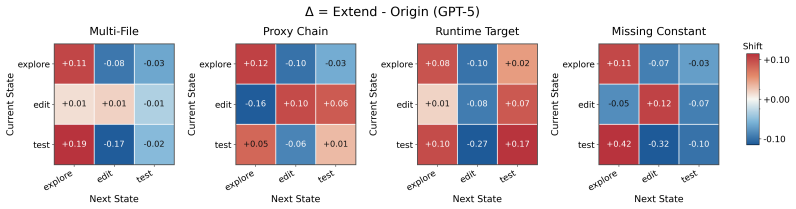
-
[5]
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, et al. Multi-swe-bench: A multilingual benchmark for issue resolving, 2025.arxiv preprint arXiv:2504.02605, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Repomastereval: Evaluating code completion via real-world repositories
Qinyun Wu, Chao Peng, Pengfei Gao, Ruida Hu, Haoyu Gan, Bo Jiang, Jinhe Tang, Zhiwen Deng, Zhanming Guan, Cuiyun Gao, et al. Repomastereval: Evaluating code completion via real-world repositories. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 3672–3683. IEEE, 2025
2025
-
[7]
SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
2024
-
[8]
Repobench: Benchmarking repository- level code auto-completion systems
Tianyang Liu, Canwen Xu, and Julian McAuley. Repobench: Benchmarking repository- level code auto-completion systems. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[9]
Ahmed Fawzy, Amjed Tahir, and Kelly Blincoe. Vibe coding in practice: Motivations, chal- lenges, and a future outlook – a grey literature review.arXiv preprint arXiv:2510.00328, 2025
-
[10]
Large language models for cyber security: A systematic literature review.ACM Transactions on Software Engineering and Methodology, 2024
HanXiang Xu, ShenAo Wang, Ningke Li, Kailong Wang, Yanjie Zhao, Kai Chen, Ting Yu, Yang Liu, and HaoYu Wang. Large language models for cyber security: A systematic literature review.ACM Transactions on Software Engineering and Methodology, 2024
2024
-
[11]
The effects of generative ai on high-skilled work: Evidence from three field experiments with software developers.Management Science, 2026
Kevin Zheyuan Cui, Mert Demirer, Sonia Jaffe, Leon Musolff, Sida Peng, and Tobias Salz. The effects of generative ai on high-skilled work: Evidence from three field experiments with software developers.Management Science, 2026
2026
-
[12]
Autocoderover: Au- tonomous program improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. Autocoderover: Au- tonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, pages 1592–1604, 2024
2024
-
[13]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[15]
Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buchholz, Tim Esler, Simon Valentin, Luca Franceschi, Martin Wistuba, Prabhu Teja Sivaprasad, Woo Jung Kim, et al. Swe-polybench: A multi-language benchmark for repository level evaluation of coding agents.arXiv preprint arXiv:2504.08703, 2025. 10
-
[16]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry. Introducing SWE-bench verified,
-
[18]
URLhttps://openai.com/index/introducing-swe-bench-verified/
-
[19]
Swe-bench goes live!arXiv preprint arXiv:2505.23419, 2025
Linghao Zhang, Shilin He, Chaoyun Zhang, Yu Kang, Bowen Li, Chengxing Xie, Junhao Wang, Maoquan Wang, Yufan Huang, Shengyu Fu, Elsie Nallipogu, Qingwei Lin, Yingnong Dang, Sar- avan Rajmohan, and Dongmei Zhang. Swe-bench goes live!arXiv preprint arXiv:2505.23419, 2025
-
[20]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Boosting adversarial attacks with momentum
Yinpeng Dong, Fangzhou Liao, Tianyu Pang, Hang Su, Jun Zhu, Xiaolin Hu, and Jianguo Li. Boosting adversarial attacks with momentum. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9185–9193, 2018
2018
-
[22]
Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference
R Thomas McCoy, Ellie Pavlick, and Tal Linzen. Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 3428–3448, 2019
2019
-
[23]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
PatchRecall: Patch-Driven Retrieval for Automated Program Repair
Mahir Labib Dihan, Faria Binta Awal, and Md Ishrak Ahsan. Patchrecall: Patch-driven retrieval for automated program repair.arXiv preprint arXiv:2604.10481, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Shanchao Liang, Spandan Garg, and Roshanak Zilouchian Moghaddam. The swe-bench illusion: When state-of-the-art llms remember instead of reason.arXiv preprint arXiv:2506.12286, 2025
-
[27]
Adversarial examples are not bugs, they are features.Advances in neural information processing systems, 32, 2019
Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. Adversarial examples are not bugs, they are features.Advances in neural information processing systems, 32, 2019
2019
-
[29]
Introducing GPT-4.1 in the api, April 2025
OpenAI. Introducing GPT-4.1 in the api, April 2025. URL https://openai.com/index/ gpt-4-1/
2025
-
[30]
Gemini-3.1-Pro model card, February 2025
Google. Gemini-3.1-Pro model card, February 2025. URL https://deepmind.google/ models/model-cards/gemini-3-1-pro/
2025
-
[31]
Claude system card, 2026
Anthropic. Claude system card, 2026. URL https://www.anthropic.com/system-cards
2026
-
[32]
MiniMax-M2.7 model card, March 2026
Google. MiniMax-M2.7 model card, March 2026. URL https://www.minimax.io/models/ text/m27
2026
-
[33]
Qwen3-coder-next technical report
Qwen Team. Qwen3-coder-next technical report. Technical report, February
-
[34]
URL https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_ next_tech_report.pdf
-
[35]
Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026
Qwen Team. Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026. URL https://qwen.ai/blog?id=qwen3.6-35b-a3b. 11
2026
-
[36]
Islem Bouzenia and Michael Pradel. Understanding software engineering agents: A study of thought-action-result trajectories.arXiv preprint arXiv:2506.18824, 2025
-
[37]
Understanding Automated Program Repair Agents Through the Lens of Traceability: An Empirical Study
Ira Ceka, Saurabh Pujar, Shyam Ramji, Luca Buratti, Gail Kaiser, and Baishakhi Ray. Under- standing software engineering agents through the lens of traceability: An empirical study.arXiv preprint arXiv:2506.08311, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Coherence Collapse: Diagnosing Why Code Agents Fail After Reaching the Right Code
Myeongsoo Kim, Dingmin Wang, Siwei Cui, Farima Farmahinifarahani, Shweta Garg, Baishakhi Ray, Terry Yue Zhuo, Rajdeep Mukherjee, and Varun Kumar. Trajeval: Decomposing code agent trajectories for fine-grained diagnosis.arXiv preprint arXiv:2603.24631, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in neural information processing systems, 36:21558–21572, 2023
2023
-
[41]
Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
2022
-
[42]
Ds-1000: A natural and reliable benchmark for data science code generation
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen- tau Yih, Daniel Fried, Sida Wang, and Tao Yu. Ds-1000: A natural and reliable benchmark for data science code generation. InInternational Conference on Machine Learning, pages 18319–18345. PMLR, 2023
2023
-
[43]
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I Wang. Cruxeval: A benchmark for code reasoning, understanding and execution.arXiv preprint arXiv:2401.03065, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Fengji Zhang, Bei Chen, Yue Zhang, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. Repocoder: Repository-level code completion through iterative retrieval and generation.arXiv preprint arXiv:2303.12570, 2023
-
[45]
Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion.Advances in Neural Information Processing Systems, 36:46701–46723, 2023
Yangruibo Ding, Zijian Wang, Wasi Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Kr- ishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, et al. Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion.Advances in Neural Information Processing Systems, 36:46701–46723, 2023
2023
-
[46]
Lilin Wang, Lucas Ramalho, Alan Celestino, Phuc Anthony Pham, Yu Liu, Umang Kumar Sinha, Andres Portillo, Onassis Osunwa, and Gabriel Maduekwe. Swe-bench++: A framework for the scalable generation of software engineering benchmarks from open-source repositories. arXiv preprint arXiv:2512.17419, 2025
-
[47]
Measuring robustness to natural distribution shifts in image classification.Advances in Neural Information Processing Systems, 33:18583–18599, 2020
Rohan Taori, Achal Dave, Vaishaal Shankar, Nicholas Carlini, Benjamin Recht, and Ludwig Schmidt. Measuring robustness to natural distribution shifts in image classification.Advances in Neural Information Processing Systems, 33:18583–18599, 2020
2020
-
[48]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfel- low, and Rob Fergus. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[49]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversar- ial examples.arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[50]
Beyond accuracy: Behavioral testing of nlp models with checklist
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of nlp models with checklist. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4902–4912, 2020
2020
-
[51]
Evaluating models’ local deci- sion boundaries via contrast sets
Matt Gardner, Yoav Artzi, Victoria Basmov, Jonathan Berant, Ben Bogin, Sihao Chen, Pradeep Dasigi, Dheeru Dua, Yanai Elazar, Ananth Gottumukkala, et al. Evaluating models’ local deci- sion boundaries via contrast sets. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 1307–1323, 2020. 12
2020
-
[52]
Recode: Robustness evaluation of code generation models
Shiqi Wang, Zheng Li, Haifeng Qian, Chenghao Yang, Zijian Wang, Mingyue Shang, Varun Kumar, Samson Tan, Baishakhi Ray, Parminder Bhatia, et al. Recode: Robustness evaluation of code generation models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13818–13843, 2023
2023
-
[53]
Variable renaming-based adversarial test generation for code model: Benchmark and enhancement.ACM Transactions on Software Engineering and Methodology, 35(1):1–28, 2025
Jin Wen, Qiang Hu, Yuejun Guo, Maxime Cordy, and Yves Le Traon. Variable renaming-based adversarial test generation for code model: Benchmark and enhancement.ACM Transactions on Software Engineering and Methodology, 35(1):1–28, 2025
2025
-
[54]
Cctest: Testing and repairing code completion systems
Zongjie Li, Chaozheng Wang, Zhibo Liu, Haoxuan Wang, Dong Chen, Shuai Wang, and Cuiyun Gao. Cctest: Testing and repairing code completion systems. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1238–1250. IEEE, 2023
2023
-
[55]
Dip: Dead code insertion based black-box attack for programming language model
CheolWon Na, YunSeok Choi, and Jee-Hyong Lee. Dip: Dead code insertion based black-box attack for programming language model. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7777–7791, 2023
2023
-
[56]
Are Large Language Models Robust in Understanding Code Against Semantics-Preserving Mutations?
Pedro Orvalho and Marta Kwiatkowska. Are large language models robust in understanding code against semantics-preserving mutations?arXiv preprint arXiv:2505.10443, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
What can large language models capture about code functional equivalence? InFindings of the Association for Computational Linguistics: NAACL 2025, pages 6865–6903, 2025
Nickil Maveli, Antonio Vergari, and Shay B Cohen. What can large language models capture about code functional equivalence? InFindings of the Association for Computational Linguistics: NAACL 2025, pages 6865–6903, 2025
2025
- [58]
-
[59]
Gistify! codebase- level understanding via runtime execution.arXiv preprint arXiv:2510.26790, 2025
Hyunji Lee, Minseon Kim, Chinmay Singh, Matheus Pereira, Atharv Sonwane, Isadora White, Elias Stengel-Eskin, Mohit Bansal, Zhengyan Shi, Alessandro Sordoni, et al. Gistify! codebase- level understanding via runtime execution.arXiv preprint arXiv:2510.26790, 2025
-
[60]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 13 A Experimental Details A.1 Compute Resources All experime...
2023
-
[61]
real runtime files
Renamed Files: Some files that contain the real runtime logic are renamed, we call them "real runtime files" below
-
[62]
These files are decoy only, may be very similar to the real file
Decoy Files: For each renamed real file, here are also distracting files. These files are decoy only, may be very similar to the real file
-
[63]
Together, they form a four-layer import graph
Proxy Files: Files whose names start with `proxy_` are proxy import files. Together, they form a four-layer import graph. The real runtime files do not directly import the final Python library; instead, it reaches that library through this proxy chain
-
[64]
Some constants originally belonging to the real runtime files have been extracted into these dependency files, and the real runtime files reads those values from them
JSON Files: Files whose names start with `dependency_` are external dependency files. Some constants originally belonging to the real runtime files have been extracted into these dependency files, and the real runtime files reads those values from them
-
[65]
Instead, at the same directory level, there is a folder whose name is the original runtime name of that code unit
Wrapper Folder: The real runtime files are not directly imported by the rest of the repository under its own filename. Instead, at the same directory level, there is a folder whose name is the original runtime name of that code unit. Inside that folder, an `__init__.py` file re-exports or imports the original file. In other words, the repository wraps som...
-
[66]
Locate the directory or directories most relevant to the task
-
[67]
Thoroughly explore and understand the structure inside that area
-
[68]
Infer relative file roles
-
[69]
Write a structured summary into /testbed/INSTRUCTION.md inside the target directory
-
[70]
A second agent will later perform editing based on your output
Stop after finishing /testbed/INSTRUCTION.md. A second agent will later perform editing based on your output. ## Guide
-
[71]
The aiming may be multiple
First make a reasonable guess about the aiming directory based on the task description and repository layout. The aiming may be multiple
-
[72]
Enter the guessed aiming directory and list the local files and subdirectories
-
[73]
Read the files that you think are relevant to the task or necessary for understanding the structure
-
[74]
Read the files related to the candidate files carefully
-
[75]
Your final answer must based on runtime evidence, do not only trust the searching and reading, do not trust the filename or the other surface patterns
Understanding the structure and logic, you should use small validation testing commands that follows the same loading or resolution logic as the code whenever possible. Your final answer must based on runtime evidence, do not only trust the searching and reading, do not trust the filename or the other surface patterns. You should explore deeply into the a...
-
[76]
- filename2: XXX; which file uses it: XXX; which file is used by it: XXX; description: XXX
The directories and all files you have read, and your runtime evidence - filename1: XXX; which file uses it: XXX; which file is used by it: XXX; description: XXX. - filename2: XXX; which file uses it: XXX; which file is used by it: XXX; description: XXX
-
[77]
The relationships between files
The detailed struture of the directory. The relationships between files. And your runtime evidence
-
[78]
B Additional Analysis and Examples B.1 Behavior Shifts on REPOMIRAGE-Perturb Fig
Other unclear points (Do not mention any unclear points that is obviously irrelative to the task) Figure 9: Prompt for exploration stage of REPOANCHOR. B Additional Analysis and Examples B.1 Behavior Shifts on REPOMIRAGE-Perturb Fig. 11 shows the behavior shifts on REPOMIRAGE-Perturb, where agents still solve the original issue-resolution task but under p...
-
[79]
Your colleague has written an INSTRUCTION.md in the /teatbed directory, detailing the location of the task target directory and files, the structure of task related files in the target directory
-
[80]
The purpose of this document is to reduce the time required for you to understand the directory structure
You should read and utilize this document reasonably. The purpose of this document is to reduce the time required for you to understand the directory structure
-
[81]
Figure 10: Prompt for problem solving stage of REPOANCHOR
You can also focus on any unclear points in the document, since the content here may be wrong and it may be an important point. Figure 10: Prompt for problem solving stage of REPOANCHOR. ***️ ***️ ***️***️ ***️ ***️ ***️ ***️ Figure 11:Behavior shifts under REPOMIRAGE-Perturb. ∆ measures the change from SWE- Bench Verified to REPOMIRAGE-Perturb. Files Ins...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.