GAC: Noise-Aware Adaptive Mixing for Hybrid SFT-RL Post-Training
Pith reviewed 2026-06-29 22:26 UTC · model grok-4.3
The pith
GAC derives adaptive mixing weights for SFT-RL post-training from online gradient variance and signal disagreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
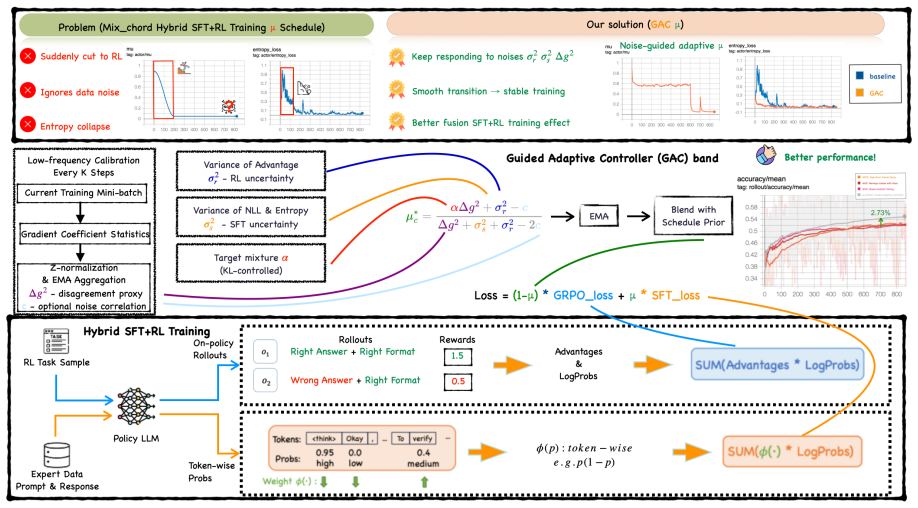
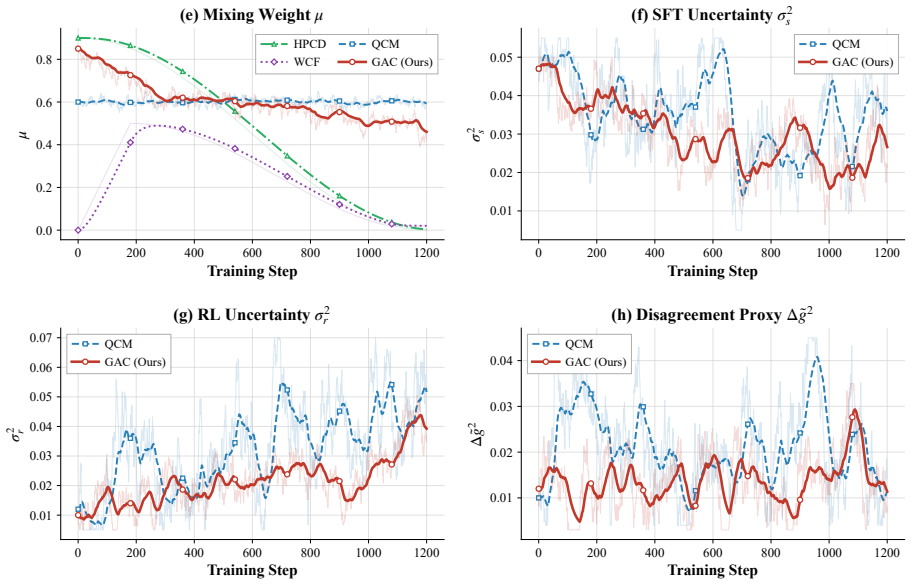
GAC is a noise-aware controller that derives an adaptive mixing weight from online estimates of gradient variance and disagreement between the SFT and RL training signals, incorporating smoothing, prior guidance, and bounded updates while reusing existing training tensors.
What carries the argument
GAC, the noise-aware controller that computes mixing weights from gradient variance and SFT-RL disagreement.
If this is right
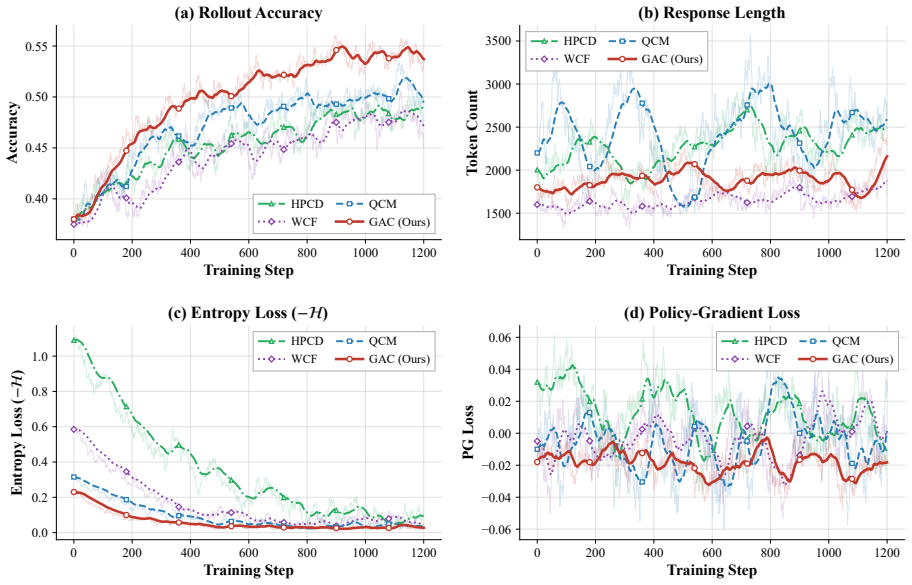
- Consistent outperformance on math, code, science, and logic benchmarks versus fixed and rule-based baselines.
- Larger performance gains appear at larger model scales.
- Training overhead stays below 1 percent through reuse of existing tensors.
- The controller avoids instability by using smoothing and bounded updates.
Where Pith is reading between the lines
- The approach could extend to other pairs of training objectives whose relative noise changes during training.
- It might reduce the engineering effort spent on hand-crafted mixing schedules in production pipelines.
- Combining GAC with other variance-reduction techniques could be tested on the same benchmark suite.
Load-bearing premise
Online estimates of gradient variance and disagreement between SFT and RL signals give a reliable signal for choosing mixing weights that improve final performance.
What would settle it
The same benchmarks run with GAC and with fixed mixing showing equal or lower scores for GAC would falsify the central claim.
Figures
read the original abstract
Hybrid post-training usually combines supervised fine-tuning and reinforcement learning, but fixed mixing schedules cannot adapt when the relative noise of the two signals changes over time. We propose GAC, a noise-aware controller that derives an adaptive mixing weight from online estimates of gradient variance and disagreement between the two training signals. The method adds smoothing, prior guidance, and bounded updates while reusing existing training tensors. Experiments on math, code, science, and logic benchmarks show that GAC consistently improves hybrid post-training over strong fixed and rule-based baselines, with larger gains at larger model scales and less than 1% training overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GAC, a noise-aware controller for adaptive mixing of SFT and RL signals during hybrid post-training. The controller derives mixing weights from online estimates of gradient variance and disagreement between the two signals, augmented with smoothing, prior guidance, and bounded updates while reusing existing tensors. Experiments on math, code, science, and logic benchmarks are claimed to show consistent improvements over strong fixed and rule-based baselines, with larger gains at larger model scales and less than 1% training overhead.
Significance. If the empirical claims hold after proper validation, the method could supply a low-overhead, practical mechanism for dynamically adjusting the relative influence of SFT and RL signals when their noise characteristics evolve, addressing a limitation of static mixing schedules in large-scale LLM post-training.
major comments (2)
- [Abstract] Abstract: the central claim of consistent improvements rests entirely on experimental results, yet the manuscript supplies no quantitative metrics, ablation studies, derivation of the controller equations, description of experimental controls, or stability analysis of the variance/disagreement estimates; without these the claim cannot be evaluated.
- [Abstract] The core assumption that online gradient variance and SFT-RL disagreement estimates supply a reliable signal for mixing weights (rather than transient noise) is load-bearing, yet the text provides no analysis of estimate stability across steps, no quantification of weight-swing frequency without the mitigations, and no demonstration that gains arise from adaptivity rather than the added smoothing/bounds.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying the manuscript content and noting revisions where the presentation can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent improvements rests entirely on experimental results, yet the manuscript supplies no quantitative metrics, ablation studies, derivation of the controller equations, description of experimental controls, or stability analysis of the variance/disagreement estimates; without these the claim cannot be evaluated.
Authors: The abstract is intentionally concise. The full manuscript derives the controller equations in Section 3, describes experimental controls and benchmarks in Section 4, reports quantitative metrics with ablations in Section 5, and analyzes estimate stability in Section 5.3. We will revise the abstract to include specific quantitative gains and explicit section references. revision: yes
-
Referee: [Abstract] The core assumption that online gradient variance and SFT-RL disagreement estimates supply a reliable signal for mixing weights (rather than transient noise) is load-bearing, yet the text provides no analysis of estimate stability across steps, no quantification of weight-swing frequency without the mitigations, and no demonstration that gains arise from adaptivity rather than the added smoothing/bounds.
Authors: Section 3.2 presents the online variance and disagreement estimators together with the smoothing, prior guidance, and bounded updates intended to stabilize them. Experiments in Section 5 show gains over fixed and rule-based baselines. We agree an explicit ablation isolating the adaptive component and plots of estimate stability/weight trajectories would strengthen the case; these will be added in revision. revision: partial
Circularity Check
No circularity; adaptive mixing is a proposed heuristic validated by experiments
full rationale
The paper presents GAC as an empirical controller that computes mixing weights from online gradient variance and SFT-RL disagreement estimates, with added smoothing, prior guidance, and bounds. No equations, first-principles derivations, or predictions are shown that reduce the weights to fitted inputs by construction. The central claim rests on benchmark improvements over fixed baselines rather than any self-referential loop or self-citation chain. The method reuses existing tensors and reports <1% overhead, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. 2018. G rad N orm: Gradient normalization for adaptive loss balancing in deep multitask networks. In Proceedings of ICML
2018
-
[5]
Christiano, Jan Leike, Tom Brown, Miljan Martic, et al
Paul F. Christiano, Jan Leike, Tom Brown, Miljan Martic, et al. 2017. Deep reinforcement learning from human preferences. In Proceedings of NeurIPS
2017
-
[6]
Guo D., Yang D., Zhang H., et al. 2025. Deepseek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Alex Kendall, Yarin Gal, and Roberto Cipolla. 2018. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of CVPR
2018
-
[8]
AI-MO. 2024. NuminaMath-1.5 dataset card. Hugging Face Datasets. URL: https://huggingface.co/datasets/AI-MO/NuminaMath-1.5
2024
-
[9]
Shikun Liu, Edward Johns, and Andrew J. Davison. 2019. End-to-end multi-task learning with attention. In Proceedings of CVPR
2019
-
[10]
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. 2021. Conflict-averse gradient descent for multi-task learning. In Proceedings of NeurIPS
2021
-
[11]
Ilya Loshchilov and Frank Hutter. 2017. SGDR : Stochastic gradient descent with warm restarts. In Proceedings of ICLR
2017
-
[12]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In Proceedings of ICLR
2019
-
[13]
Aviv Navon, Idan Achituve, Haggai Maron, Gal Chechik, and Ethan Fetaya. 2022. Multi-task learning as a bargaining game. In Proceedings of ICML
2022
-
[14]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, et al. 2022. Training language models to follow instructions with human feedback. In Proceedings of NeurIPS
2022
-
[15]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. In Proceedings of NeurIPS
2023
-
[16]
David Rein, Betty Li Hou, Asa Cooper Stickland, et al. 2023. GPQA : A graduate-level google-proof Q&A benchmark. arXiv preprint arXiv:2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. 2015. High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. 2015. Trust region policy optimization. In Proceedings of ICML
2015
-
[19]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Ozan Sener and Vladlen Koltun. 2018. Multi-task learning as multi-objective optimization. In Proceedings of NeurIPS
2018
-
[21]
Shao Z., Wang P., Zhu Q., et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Mirac Suzgun, Nathan Scales, Nathanael Sch \"a rli, et al. 2022. Challenging BIG-B ench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Xiaoxuan Wang, Ziniu Hu, Pan Lu, et al. 2023. S ci B ench: Evaluating college-level scientific problem-solving abilities of large language models. arXiv preprint arXiv:2307.10635
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. 2020. Gradient surgery for multi-task learning. In Proceedings of NeurIPS
2020
-
[25]
G., Rowland M., Piot B., Guo Z
Azar M. G., Rowland M., Piot B., Guo Z. D., Calandriello D., Valko M., and Munos R. 2024. A general theoretical paradigm to understand learning from human preferences. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Proceedings of Machine Learning Research, pages 4447--4455
2024
-
[26]
Bo Liu, Yihao Feng, Peter Stone, and Qiang Liu. 2023. FAMO : Fast adaptive multitask optimization. In Proceedings of NeurIPS
2023
-
[27]
Dmitry Senushkin, Nikolay Patakin, Arseny Kuznetsov, and Anton Konushin. 2023. Independent component alignment for multi-task learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2023
-
[28]
Peiyao Xiao, Hao Ban, and Kaiyi Ji. 2023. Direction-oriented multi-objective learning: Simple and provable stochastic algorithms. In Proceedings of NeurIPS
2023
-
[29]
Heshan Fernando, Han Shen, Miao Liu, Subhajit Chaudhury, Keerthiram Murugesan, and Tianyi Chen. 2023. Mitigating gradient bias in multi-objective learning: A provably convergent approach. In Proceedings of ICLR
2023
- [30]
- [31]
-
[32]
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. 2025. Learning to reason under off-policy guidance. arXiv preprint arXiv:2504.14945
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [33]
- [34]
- [35]
-
[36]
Xueyan Niu, Bo Bai, Wei Han, and Weixi Zhang. 2026. On the non-decoupling of supervised fine-tuning and reinforcement learning in post-training. arXiv preprint arXiv:2601.07389
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Min Zeng, Jingfei Sun, Xueyou Luo, Shiqi Zhang, Li Xie, Caiquan Liu, and Xiaoxin Chen. 2025. GTA : Supervised-guided reinforcement learning for text classification with large language models. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 1050--1060
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.