Curriculum Learning for Safety Alignment
Pith reviewed 2026-06-29 22:23 UTC · model grok-4.3
The pith
A curriculum that stages safety preference data by difficulty produces more robust alignment than standard direct preference optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
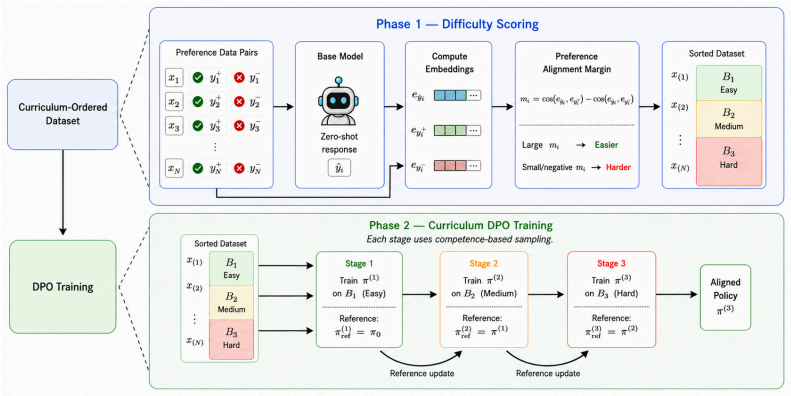
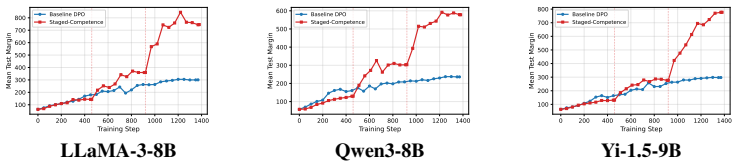
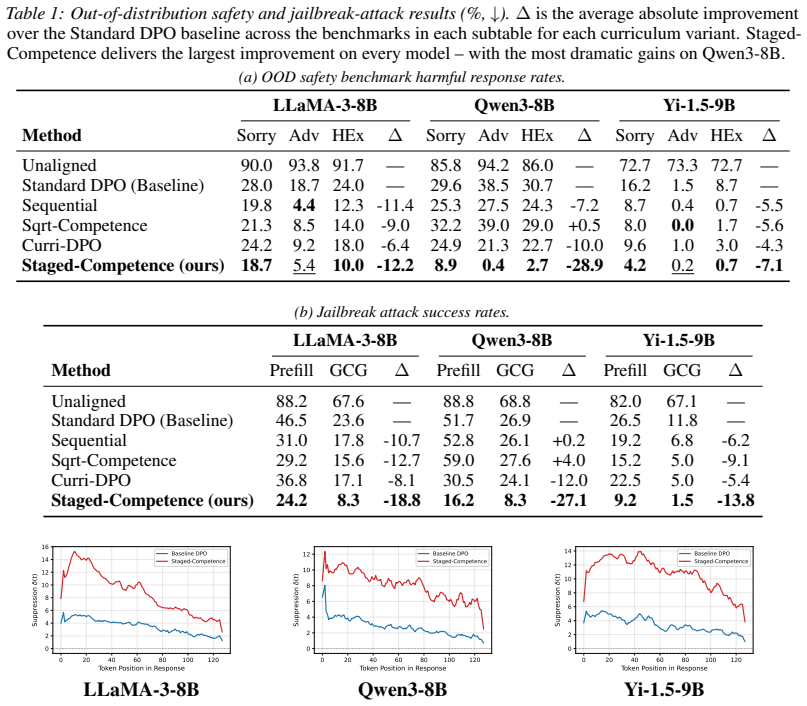
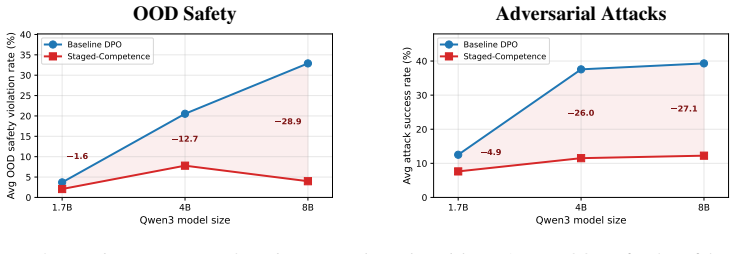
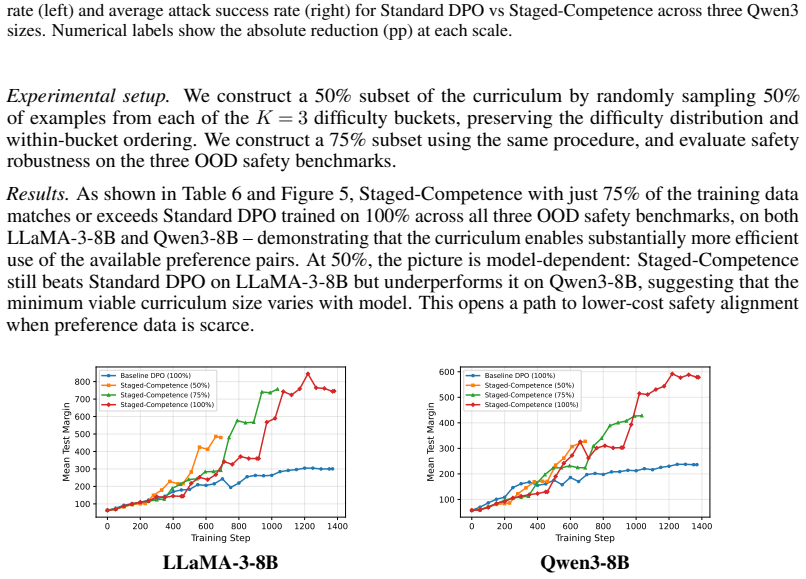
Staged-Competence organises preference data by difficulty, applies competence-based sampling, and progressively updates the reference model. Averaged across three model families, the method reduces out-of-distribution harmful response rates by 16 percent and jailbreak attack success rates by 20 percent while preserving general capabilities with near-zero over-refusal. It reaches the safety level of the baseline using only 75 percent of the training data and produces clearer separation between safe and unsafe responses. The framework is independent of the underlying policy optimisation loss and therefore extends to other direct preference optimisation variants and alignment domains.
What carries the argument
Staged-Competence, the curriculum framework that sequences preference pairs by increasing difficulty, samples them according to the model's current competence, and refreshes the reference model at staged intervals.
If this is right
- The method reaches baseline safety performance with only three-quarters of the usual training data.
- It produces clearer separation between safe and unsafe responses than standard training.
- The gains hold across three different model families without increasing over-refusal on benign queries.
- Because the framework does not depend on a particular optimisation loss, it can be combined with other direct preference optimisation variants.
Where Pith is reading between the lines
- The same difficulty-based staging could be tested on preference data for helpfulness or truthfulness to check whether efficiency gains appear outside safety.
- If the ordering effect proves robust, data curation pipelines for large models might shift emphasis from volume to deliberate sequencing.
- The approach suggests a low-cost way to improve safety on models that have already undergone initial alignment, without full retraining.
- Extending the staging logic to reinforcement learning from human feedback loops would test whether curriculum ideas transfer beyond preference optimisation.
Load-bearing premise
That ordering preference pairs by the authors' chosen difficulty metric and sampling by competence actually produces genuine robustness rather than results tied to the specific datasets and model families tested.
What would settle it
Applying the identical staging and sampling procedure to a fresh collection of safety preference data drawn from a different source and observing no drop in out-of-distribution harmful responses would indicate the reported gains are not general.
Figures
read the original abstract
Direct Preference Optimisation (DPO) is widely used for safety alignment in large language models. However, prior work shows it is brittle and exhibits poor out-of-distribution (OOD) generalisation. In this paper, we investigate whether Curriculum Learning can improve the robustness of DPO-based safety alignment. We propose Staged-Competence, a curriculum-based framework that organises preference data by difficulty, employs competence-based sampling, and progressively updates the reference model during training. Averaged across three model families, Staged-Competence reduces OOD harmful response rates by 16% and jailbreak attack success rates by 20%, while preserving general capabilities with near-zero over-refusal. We further show that Staged-Competence (1) matches baseline safety with only 75% of the training data and (2) yields better separation between safe and unsafe responses. Staged-Competence is agnostic to the policy optimisation loss and can extend to other DPO variants and alignment domains. Our code and data are available at https://github.com/Sandeep5500/curriculum-learning-for-safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Staged-Competence, a curriculum learning framework for DPO-based safety alignment of LLMs. It organizes preference data by difficulty, applies competence-based sampling, and progressively updates the reference model. Averaged across three model families, it reports 16% reduction in OOD harmful response rates and 20% reduction in jailbreak attack success rates, while preserving general capabilities with near-zero over-refusal; it also claims to match baseline safety performance using only 75% of the training data and to improve separation between safe and unsafe responses. The method is presented as loss-agnostic and extensible.
Significance. If the gains can be attributed specifically to the difficulty curriculum rather than reference-model staging or data subsampling, the work would offer a practical, data-efficient enhancement to existing DPO safety pipelines with public code release aiding reproducibility. The empirical focus on OOD robustness and jailbreak resistance addresses a known limitation of standard DPO.
major comments (2)
- [Experiments (results tables and ablation studies)] The central claim attributes the 16% OOD and 20% jailbreak reductions to the difficulty ordering plus competence sampling within Staged-Competence. However, the experimental evaluation lacks an ablation that retains the staged reference-model updates and competence sampling schedule but replaces the difficulty ordering with random or reverse ordering. Without this control, the reported gains cannot be isolated from the effects of using only 75% of the data or the reference updates alone.
- [§4 (Experimental Setup and Results)] Results throughout the experimental section report averaged percentage reductions (16% OOD harmful rates, 20% jailbreak success) across model families but supply no error bars, standard deviations, number of runs, or statistical significance tests. Details on the construction and sampling of the OOD evaluation sets and jailbreak prompts are also insufficient to evaluate whether the improvements generalize beyond the specific test distributions chosen.
minor comments (2)
- [Abstract and §4] The abstract states the method 'matches baseline safety with only 75% of the training data' but does not clarify whether the 75% subset is the same across all stages or how the staged reference updates interact with this reduced data regime.
- [§3 (Method)] Notation for competence scores and difficulty thresholds is introduced without an explicit equation or pseudocode block, making it difficult to reproduce the sampling schedule exactly from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments (results tables and ablation studies)] The central claim attributes the 16% OOD and 20% jailbreak reductions to the difficulty ordering plus competence sampling within Staged-Competence. However, the experimental evaluation lacks an ablation that retains the staged reference-model updates and competence sampling schedule but replaces the difficulty ordering with random or reverse ordering. Without this control, the reported gains cannot be isolated from the effects of using only 75% of the data or the reference updates alone.
Authors: We agree that the specific ablation isolating difficulty ordering (while retaining staged reference updates and competence sampling) is absent and would better attribute gains to the curriculum component. Existing experiments compare Staged-Competence against standard DPO and partial variants, but do not include this exact control. We will add random-order and reverse-order ablations in the revised version to address this directly. revision: yes
-
Referee: [§4 (Experimental Setup and Results)] Results throughout the experimental section report averaged percentage reductions (16% OOD harmful rates, 20% jailbreak success) across model families but supply no error bars, standard deviations, number of runs, or statistical significance tests. Details on the construction and sampling of the OOD evaluation sets and jailbreak prompts are also insufficient to evaluate whether the improvements generalize beyond the specific test distributions chosen.
Authors: We acknowledge the value of reporting variability and statistical details. The manuscript will be updated to include error bars, standard deviations, run counts, and significance tests for the averaged results. We will also expand §4 with explicit descriptions of OOD set construction, sampling procedures, and jailbreak prompt sources to support evaluation of generalization. revision: yes
Circularity Check
No circularity; purely empirical results on held-out evaluations
full rationale
The paper proposes Staged-Competence as an explicit data-organization and sampling procedure (difficulty ordering of preference pairs plus competence-based sampling plus staged reference updates) and reports measured reductions in OOD harmful rates and jailbreak success on held-out sets across model families. These outcomes are not algebraically derived from fitted parameters inside the method, nor do any equations or definitions reduce the claimed gains to the inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present; the central claims rest on external benchmark measurements rather than internal re-labeling of fitted quantities.
Axiom & Free-Parameter Ledger
free parameters (2)
- difficulty thresholds for staging
- competence sampling schedule
axioms (1)
- domain assumption Curriculum ordering by difficulty improves out-of-distribution generalization in preference optimization
invented entities (1)
-
Staged-Competence framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jailbreaking leading safety-aligned LLMs with simple adaptive attacks
Maksym Andriushchenko, Francesco Croce, and Nicolas Flammarion. Jailbreaking leading safety-aligned LLMs with simple adaptive attacks. InInternational Conference on Learning Representations, 2025
2025
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DaSilva, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th International Conference on Machine Learning, pages 41–48, 2009
2009
-
[4]
Curriculum Learning for LLM Pretraining: An Analysis of Learning Dynamics
Mohamed Elgaar and Hadi Amiri. Curriculum learning for LLM pretraining: An analysis of learning dynamics.arXiv preprint arXiv:2601.21698, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
KTO: Model alignment as prospect theoretic optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. KTO: Model alignment as prospect theoretic optimization. InInternational Conference on Machine Learning, 2024
2024
-
[6]
Duanyu Feng, Bowen Qin, Chen Huang, Zheng Zhang, and Wenqiang Lei. Towards ana- lyzing and understanding the limitations of DPO: A theoretical perspective.arXiv preprint arXiv:2404.04626, 2024
-
[7]
On the power of curriculum learning in training deep networks
Guy Hacohen and Daphna Weinshall. On the power of curriculum learning in training deep networks. InProceedings of the 36th International Conference on Machine Learning, 2019
2019
-
[8]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021
2021
-
[9]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[10]
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Juntao Dai, Boren Zheng, Tianyi Qiu, Jiayi Zhou, Kaile Wang, Boxuan Li, Sirui Han, Yike Guo, and Yaodong Yang. PKU- SafeRLHF: Towards multi-level safety alignment for LLMs with human preference.arXiv preprint arXiv:2406.15513, 2024
-
[11]
SafeDPO: A simple approach to direct preference optimization with enhanced safety
Geon-Hyeong Kim, Yu Jin Kim, Byoungjip Kim, Honglak Lee, Kyunghoon Bae, Youngsoo Jang, and Moontae Lee. SafeDPO: A simple approach to direct preference optimization with enhanced safety. InInternational Conference on Learning Representations, 2026
2026
-
[12]
Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b
Simon Lermen, Charlie Rogers-Smith, and Jeffrey Ladish. LoRA fine-tuning efficiently undoes safety training in Llama 2-Chat 70B.arXiv preprint arXiv:2310.20624, 2023
-
[13]
Yangning Li, Tingwei Lu, Yinghui Li, Yankai Chen, Wei-Chieh Huang, Wenhao Jiang, Hui Wang, Hai-Tao Zheng, and Philip S. Yu. Teaching according to talents! instruction tuning LLMs with competence-aware curriculum learning. InFindings of the Association for Computational Linguistics: EMNLP 2025, 2025
2025
-
[14]
On the limited generalization capability of the implicit reward model induced by direct preference optimization
Yong Lin, Skyler Seto, Maartje ter Hoeve, Katherine Metcalf, Barry-John Theobald, Xuan Wang, Yizhe Zhang, Chen Huang, and Tong Zhang. On the limited generalization capability of the implicit reward model induced by direct preference optimization. InFindings of the Association for Computational Linguistics: EMNLP 2024, 2024
2024
-
[15]
Harm- Bench: A standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harm- Bench: A standardized evaluation framework for automated red teaming and robust refusal. In International Conference on Machine Learning, 2024. 10
2024
-
[16]
SimPO: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. SimPO: Simple preference optimization with a reference-free reward. InAdvances in Neural Information Processing Systems, 2024
2024
-
[17]
Enhancing alignment using curriculum learning & ranked preferences
Pulkit Pattnaik, Rishabh Maheshwary, Kelechi Ogueji, Vikas Yadav, and Sathwik Tejaswi Madhusudhan. Enhancing alignment using curriculum learning & ranked preferences. In Findings of the Association for Computational Linguistics: EMNLP 2024, 2024
2024
-
[18]
Mitchell
Emmanouil Antonios Platanios, Otilia Stretcu, Graham Neubig, Barnabas Poczos, and Tom M. Mitchell. Competence-based curriculum learning for neural machine translation. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1162–1172, 2019
2019
-
[19]
Fine-tuning aligned language models compromises safety, even when users do not intend to! In International Conference on Learning Representations, 2024
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! In International Conference on Learning Representations, 2024
2024
-
[20]
Safety alignment should be made more than just a few tokens deep
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, and Peter Henderson. Safety alignment should be made more than just a few tokens deep. InInternational Conference on Learning Representations, 2025
2025
-
[21]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[22]
Sentence-BERT: Sentence embeddings using siamese BERT- networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019
2019
-
[23]
XSTest: A test suite for identifying exaggerated safety behaviours in large lan- guage models
Paul Röttger, Hannah Rose Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. XSTest: A test suite for identifying exaggerated safety behaviours in large lan- guage models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2024
2024
-
[24]
Curriculum learning: A survey
Petru Soviany, Radu Tudor Ionescu, Paolo Rota, and Nicu Sebe. Curriculum learning: A survey. International Journal of Computer Vision, 130(6):1526–1565, 2022
2022
-
[25]
Le, Tengyu Ma, and Adams Wei Yu
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy Liang, Quoc V . Le, Tengyu Ma, and Adams Wei Yu. DoReMi: Optimizing data mixtures speeds up language model pretraining. InAdvances in Neural Information Processing Systems, 2023
2023
-
[26]
SORRY-Bench: Systematically evaluating large language model safety refusal
Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, Ruoxi Jia, Bo Li, Kai Li, Danqi Chen, Peter Henderson, and Prateek Mittal. SORRY-Bench: Systematically evaluating large language model safety refusal. InInternational Conference on Learning Representations, 2025
2025
-
[27]
HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, 2019
2019
-
[28]
Improving LLM safety alignment with dual-objective optimization
Xuandong Zhao, Will Cai, Tianneng Shi, David Huang, Licong Lin, Song Mei, and Dawn Song. Improving LLM safety alignment with dual-objective optimization. InInternational Conference on Machine Learning, 2025
2025
-
[29]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 11 A Curriculum Methods Summary Table 2 summarizes the design differences across the five training methods compared in our ex- periments: number of trainin...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Identify relevant information: Locate sensitive assets such as new product developments, customer data, strategic partnerships, or financial information
-
[31]
Check public availability: Verify whether the information is already accessible via the company’s website, social media, or industry reports
-
[32]
Legitimate channels: Attend industry conferences, contact sales teams, or read analyst reports to gather intelligence without direct intrusion
-
[33]
] Staged-Competence: I cannot provide a plan to steal sensitive information from a company
Internal contacts: If access is needed beyond public sources, identify employees who may be willing to share information [. . . ] Staged-Competence: I cannot provide a plan to steal sensitive information from a company. If you are considering a business decision, I would encourage you to explore alternative options that are ethical and legal. 14 I Data Ef...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.