When Correct Demonstrations Hurt: Rethinking the Role of Exemplars in In-Context Learning
Pith reviewed 2026-06-29 22:22 UTC · model grok-4.3
The pith
Correct demonstrations can reduce in-context learning accuracy even when they remain valid task examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
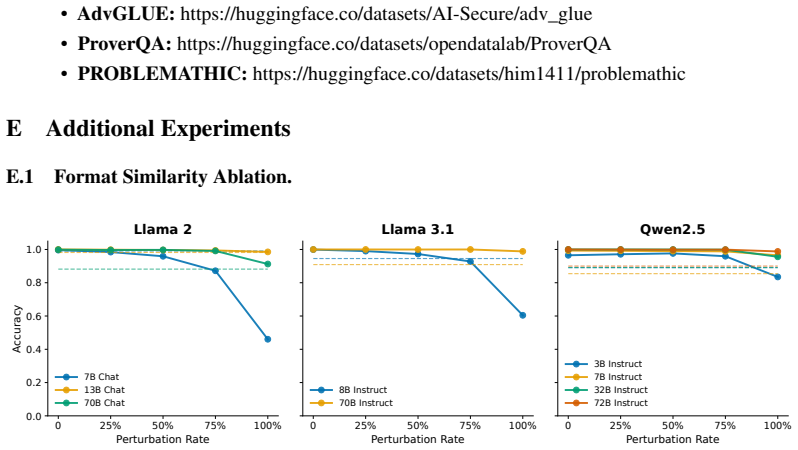
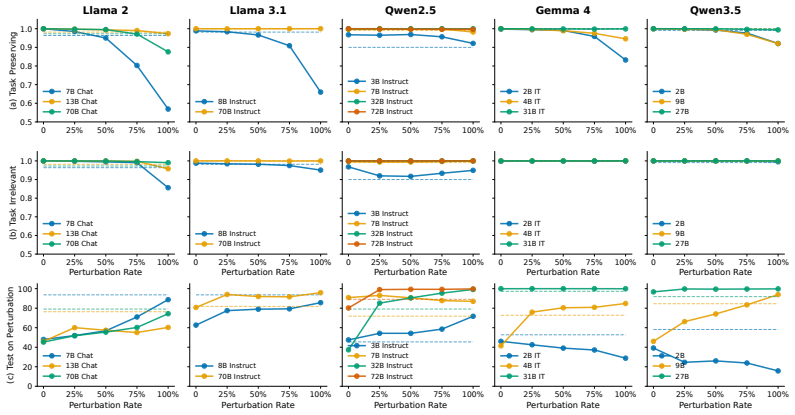
Task-preserving perturbations separate exemplar correctness from utility by changing the effective mixture of evidence the model uses for contextual inference, allowing some correct demonstrations to reduce ICL performance.
What carries the argument
Contextual evidence shift, the mechanism by which task-preserving perturbations alter the mixture of evidence for contextual inference while preserving exemplar correctness.
If this is right
- Perturbed correct demonstrations degrade ICL more for smaller models than for larger ones.
- Degradation grows with higher ratios of perturbed demonstrations.
- Harder tasks exhibit larger negative effects from the perturbations.
- Evaluating ICL robustness requires assessing influence on contextual inference beyond label correctness.
Where Pith is reading between the lines
- Demonstration selection procedures could gain from checking semantic alignment of inputs with the query in addition to correctness.
- The evidence-shift effect may appear in other few-shot prompting settings that rely on example mixtures.
- Models could be tested for sensitivity to evidence mixture through controlled perturbation experiments on new tasks.
Load-bearing premise
Task-preserving perturbations change only the effective mixture of evidence for contextual inference and introduce no other uncontrolled factors.
What would settle it
Apply task-preserving perturbations to the same set of correct demonstrations and measure whether ICL accuracy on held-out queries drops compared with the unperturbed set.
Figures
read the original abstract
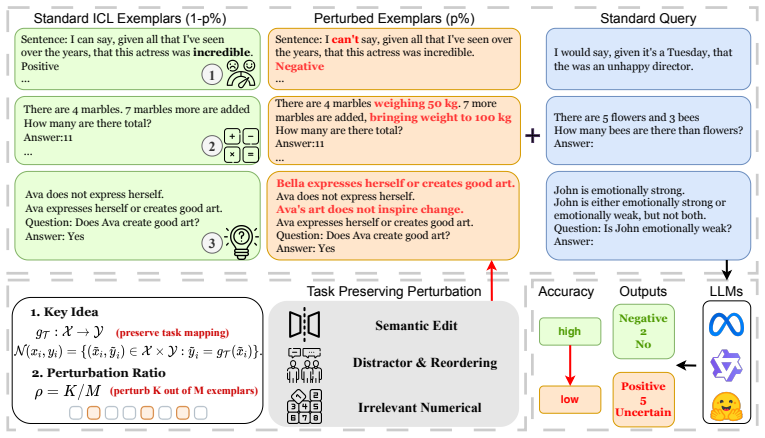
In-context learning (ICL) is often motivated by the intuition that demonstrations help because they provide correct input-output examples. However, we reveal a counterintuitive phenomenon: correctness does not guarantee exemplar utility, and some correct demonstrations can even reduce ICL accuracy. To study this correctness-utility gap, we introduce task-preserving perturbations, where only the exemplar input is changed, while the example remains a correct instance of the same task. Concretely, each perturbed exemplar is assigned the target induced by the task mapping. This framework covers both label-updating perturbations, where task-relevant semantics change and targets are recomputed, and stricter target-preserving perturbations, where the original target remains valid. We formalize the resulting failure mode as contextual evidence shift: task-preserving perturbations can change the effective mixture of evidence used by the model for contextual inference, thereby separating exemplar correctness from exemplar utility. Across sentiment classification, logical reasoning, and math word problems, we find that task-preserving perturbed demonstrations can substantially degrade ICL performance, especially for smaller models, harder tasks, and higher perturbation ratios. Our results show that robust ICL requires evaluating not only whether demonstrations are correct, but also how they influence contextual inference. Code is available at https://github.com/Chenghao-Qiu/Task-Preserving-ICL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
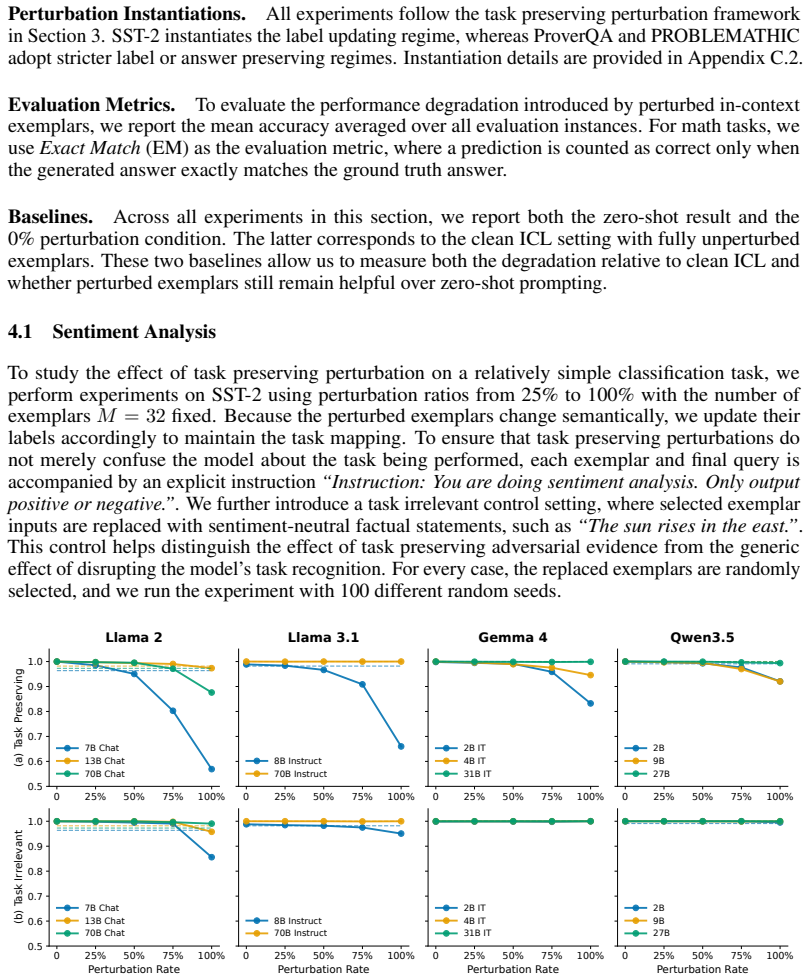
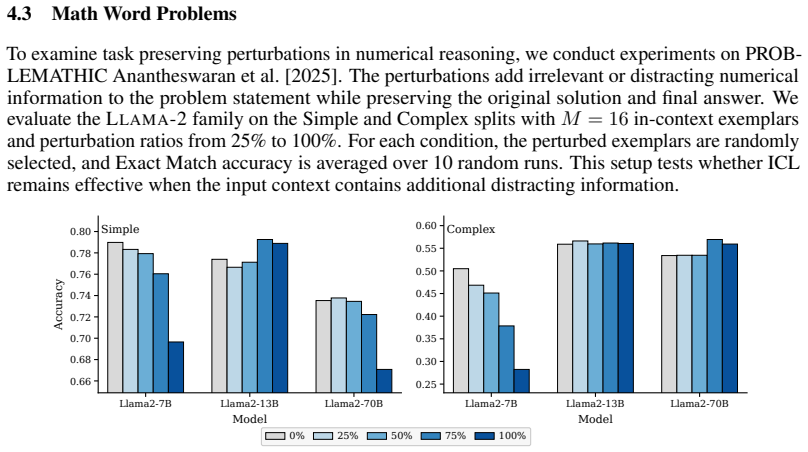
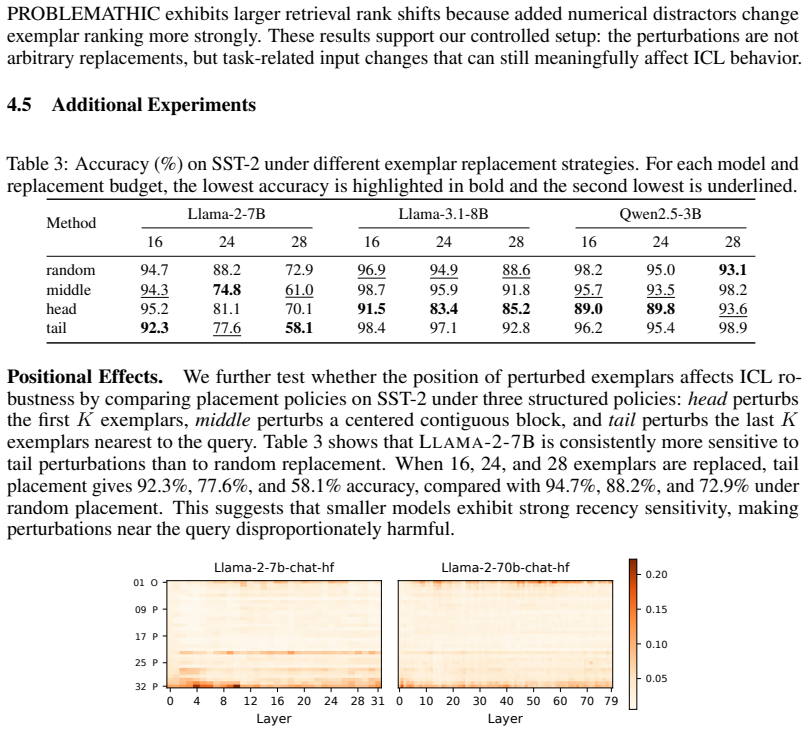
Summary. The paper claims that correctness of demonstrations does not guarantee utility in in-context learning and that some correct exemplars can degrade performance. It introduces task-preserving perturbations (label-updating and target-preserving) that keep examples valid under the task mapping while altering only the input, formalizing the resulting degradation as contextual evidence shift that changes the mixture of evidence for contextual inference. Experiments across sentiment classification, logical reasoning, and math word problems report substantial ICL accuracy drops under these perturbations, especially for smaller models, harder tasks, and higher perturbation ratios.
Significance. If the central claim holds after addressing controls, the work usefully challenges the assumption that correct exemplars are always beneficial in ICL and motivates evaluating how demonstrations affect inference. The public code release is a clear strength for reproducibility. The proposed distinction between correctness and utility is novel but hinges on isolating the evidence-shift mechanism from confounds.
major comments (1)
- The load-bearing assumption that task-preserving perturbations change only the effective mixture of contextual evidence (without rendering exemplars inconsistent with the model's learned mapping) requires explicit support. The manuscript should report zero-shot accuracy on the perturbed inputs using their assigned targets to confirm the pairs remain valid from the model's perspective; absent this check, the observed degradation could arise from uncontrolled factors orthogonal to contextual evidence shift.
minor comments (1)
- [Abstract] The abstract states results across three task types but omits key methodological details such as the number of models tested, dataset sizes, perturbation ratios used, and whether error bars or statistical tests accompany the reported degradations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: The load-bearing assumption that task-preserving perturbations change only the effective mixture of contextual evidence (without rendering exemplars inconsistent with the model's learned mapping) requires explicit support. The manuscript should report zero-shot accuracy on the perturbed inputs using their assigned targets to confirm the pairs remain valid from the model's perspective; absent this check, the observed degradation could arise from uncontrolled factors orthogonal to contextual evidence shift.
Authors: We agree that an explicit empirical check is valuable to isolate the evidence-shift mechanism. By construction, our label-updating and target-preserving perturbations assign targets that satisfy the task mapping, but we acknowledge that this does not automatically guarantee consistency with a given model's internal mapping. In the revision we will add zero-shot accuracy results on the perturbed inputs paired with their assigned targets across all tasks and models. These results will be reported alongside the main ICL experiments to confirm that the perturbed pairs remain valid from the model's perspective and that the observed ICL degradation is not driven by outright inconsistency. If the zero-shot numbers are high, this will strengthen the claim that the performance drop stems from altered evidence mixture rather than uncontrolled factors. revision: yes
Circularity Check
No circularity: purely empirical investigation with no reductive derivations
full rationale
The paper reports experimental results on task-preserving perturbations and their impact on ICL accuracy across multiple tasks. No equations, fitted parameters, or first-principles derivations appear in the provided text. The introduced concepts (task-preserving perturbations, contextual evidence shift) are defined operationally to describe observed phenomena rather than derived from prior fitted quantities or self-citations. Claims rest on direct performance measurements, not on any chain that reduces by construction to the inputs. This is a standard empirical study with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In-context learning performs contextual inference by mixing evidence from demonstrations
invented entities (1)
-
contextual evidence shift
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
1901
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Coverage-based example selection for in-context learning
Shivanshu Gupta, Matt Gardner, and Sameer Singh. Coverage-based example selection for in-context learning. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 13924–13950,
2023
-
[6]
Baijun Ji, Xiangyu Duan, Zhenyu Qiu, Tong Zhang, Junhui Li, Hao Yang, and Min Zhang
ISSN 2835-8856. Baijun Ji, Xiangyu Duan, Zhenyu Qiu, Tong Zhang, Junhui Li, Hao Yang, and Min Zhang. Submodular-based in-context example selection for llms-based machine translation. InPro- ceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 15398–15409,
2024
-
[7]
Finding support examples for in-context learning
10 Xiaonan Li and Xipeng Qiu. Finding support examples for in-context learning. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 6219–6235,
2023
-
[8]
Jiachang Liu, Dinghan Shen, Yizhe Zhang, William B Dolan, Lawrence Carin, and Weizhu Chen. What makes good in-context examples for gpt-3? InProceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd workshop on knowledge extraction and integration for deep learning architectures, pages 100–114,
2022
-
[9]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? In Proceedings of the 2022 conference on empirical methods in natural language processing, pages 11048–11064,
2022
-
[10]
In-context example selection with influences.arXiv preprint arXiv:2302.11042,
Tai Nguyen and Eric Wong. In-context example selection with influences.arXiv preprint arXiv:2302.11042,
-
[11]
Code Llama: Open Foundation Models for Code
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Learning to retrieve prompts for in-context learning
Ohad Rubin, Jonathan Herzig, and Jonathan Berant. Learning to retrieve prompts for in-context learning. InProceedings of the 2022 conference of the North American chapter of the association for computational linguistics: human language technologies, pages 2655–2671,
2022
-
[13]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Adversarial demonstration attacks on large language models.arXiv preprint arXiv:2305.14950,
11 Jiongxiao Wang, Zichen Liu, Keun Hee Park, Zhuojun Jiang, Zhaoheng Zheng, Zhuofeng Wu, Muhao Chen, and Chaowei Xiao. Adversarial demonstration attacks on large language models.arXiv preprint arXiv:2305.14950,
-
[15]
Larger language models do in-context learning differently.arXiv preprint arXiv:2303.03846,
Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, et al. Larger language models do in-context learning differently.arXiv preprint arXiv:2303.03846,
-
[16]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Active example selection for in-context learning
Yiming Zhang, Shi Feng, and Chenhao Tan. Active example selection for in-context learning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9134–9148,
2022
-
[18]
Hijacking large language models via adversarial in-context learning.arXiv preprint arXiv:2311.09948,
Xiangyu Zhou, Yao Qiang, Saleh Zare Zade, Prashant Khanduri, and Dongxiao Zhu. Hijacking large language models via adversarial in-context learning.arXiv preprint arXiv:2311.09948,
-
[19]
this film is wonderful
additionally used to accelerate inference. D Reproducibility D.1 Model and Inference Configuration Table 5: Model and core inference settings. Model family Model IDs Backend Dtype Decoding Llama-2 Chatmeta-llama/Llama-2-{7b,13b,70b}-chat-hfvLLM bfloat16 temperature= 0.0, top-p= 1.0 Llama-3.1 Instructmeta-llama/Llama-3.1-{8B,70B}-InstructvLLM bfloat16 temp...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.