Verus-SpecGym: An Agentic Environment for Evaluating Specification Autoformalization
Pith reviewed 2026-06-29 16:29 UTC · model grok-4.3
The pith
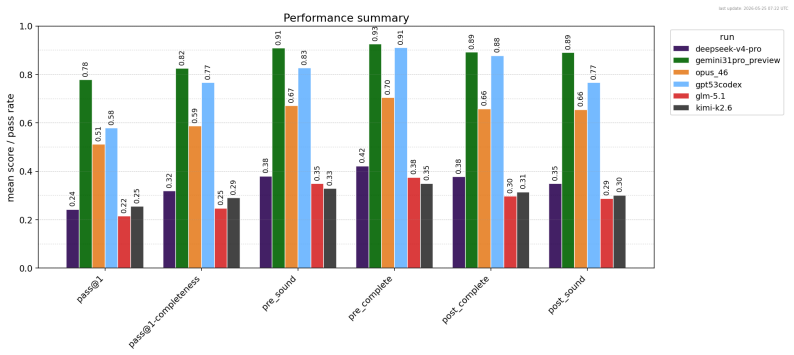
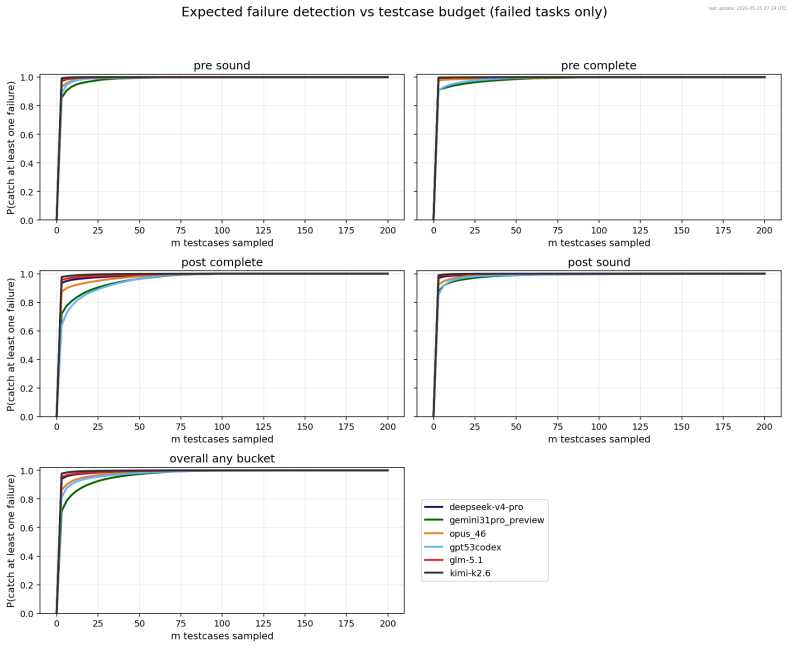
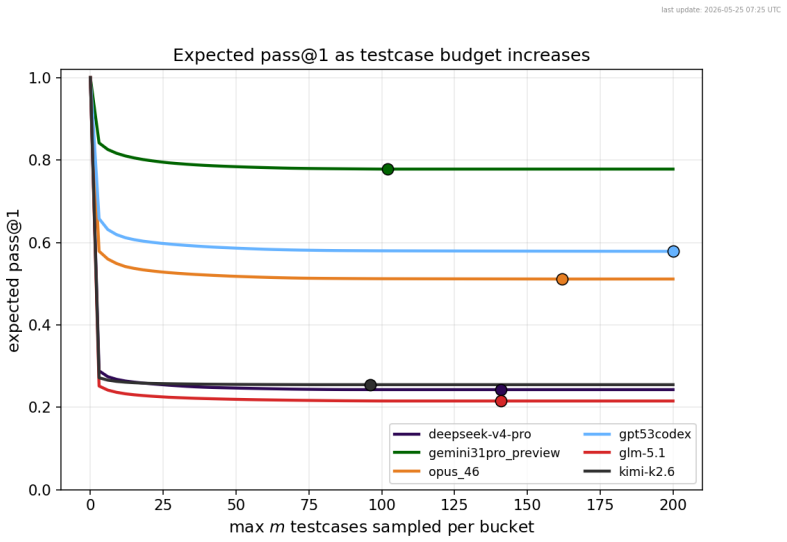
LLM agents translate informal Codeforces problems into Verus formal specifications at rates from 21 percent for open models to 77.8 percent for the strongest frontier model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
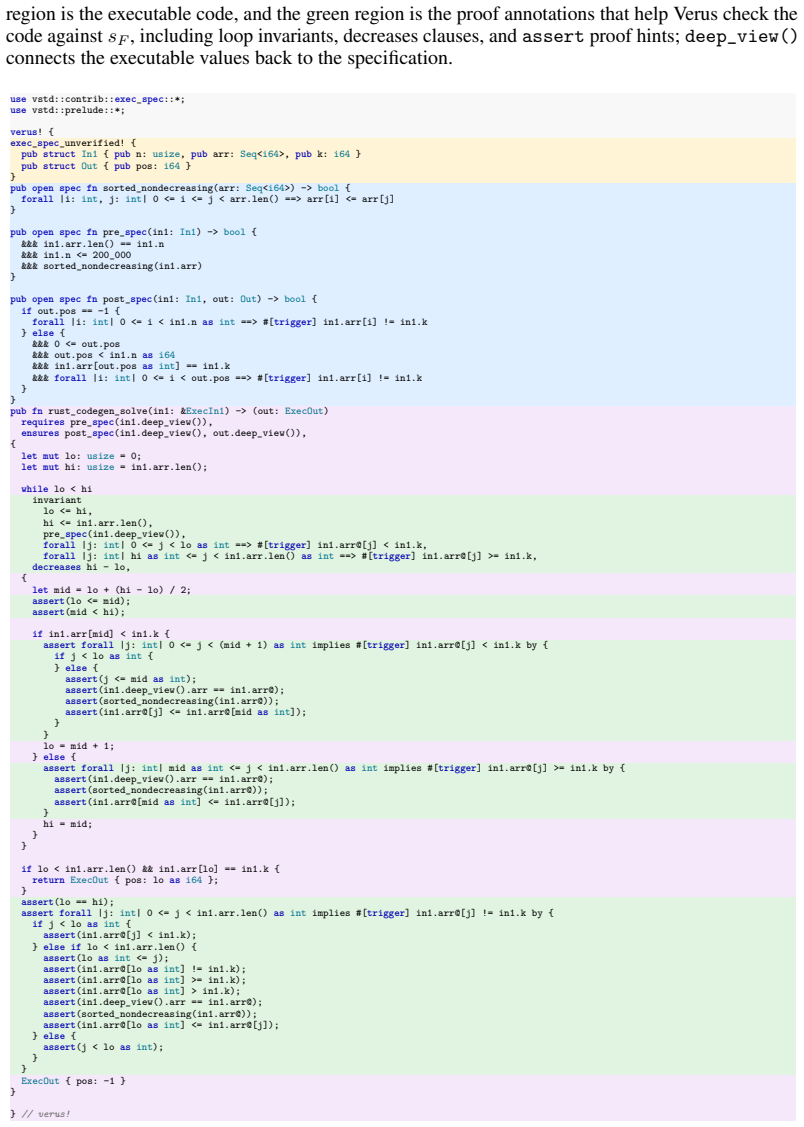
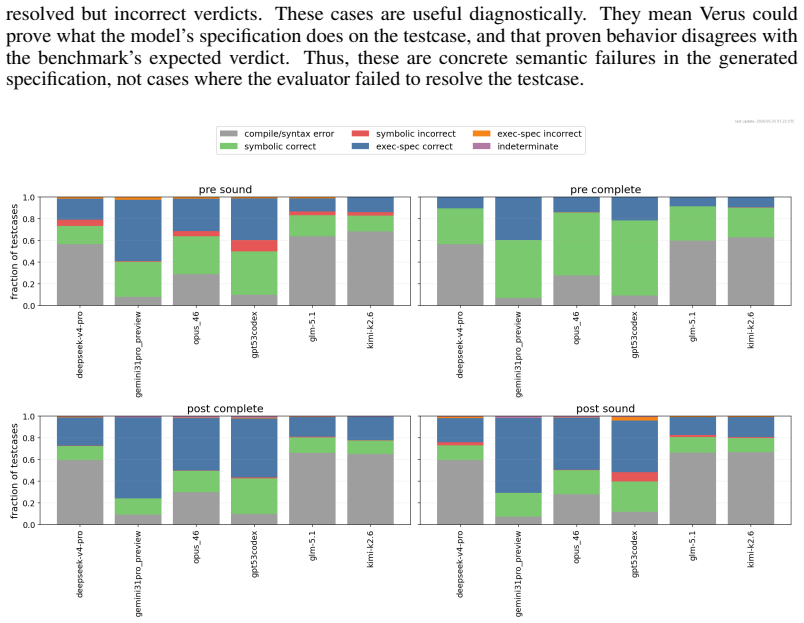
The authors introduce Verus-SpecBench and Verus-SpecGym to measure whether LLM agents can convert informal problem statements into faithful formal specifications for the Verus verifier. They extend Verus with an exec_spec feature so generated specifications can be compiled and executed directly against Codeforces tests and extracted hacks. On the resulting benchmark the strongest model, Gemini 3.1 Pro, solves 77.8 percent of tasks, other frontier models solve 51.1 to 57.8 percent, and open-source models solve 21.5 to 25.5 percent. Analysis of errors shows that generated specifications commonly omit input assumptions, accept incorrect outputs, or reject valid ones, and that LLM-based judging
What carries the argument
Verus-SpecGym, an agentic loop in which models interact with the Verus verifier, the filesystem, and bash to iteratively produce and test formal specifications that are then checked by execution against official tests plus Codeforces hacks.
If this is right
- Frontier agents can already produce usable formal specifications for most Codeforces-style problems when given interactive feedback.
- Execution against tests and hacks supplies a scalable way to judge specification quality without expert-written reference specifications.
- The dominant failure modes are omission of input constraints and incorrect handling of output validity.
- LLM judges alone are not reliable for this task because they miss a substantial fraction of execution-detectable errors.
Where Pith is reading between the lines
- Pairing this benchmark with existing code-generation agents could surface whether correct code plus correct spec together produce verified programs that match user intent.
- The gap between frontier and open-source performance suggests that scaling data or training specifically on formal-spec writing tasks would be a direct next experiment.
- Extending the same execution-based evaluator to larger, multi-file problems would test whether the current success rates hold when specifications grow more complex.
Load-bearing premise
That a specification which passes the official tests and the extracted hacks necessarily captures the original informal problem intent.
What would settle it
A generated specification that passes every official test and every extracted hack yet accepts a program whose behavior violates an untested aspect of the original problem statement.
Figures
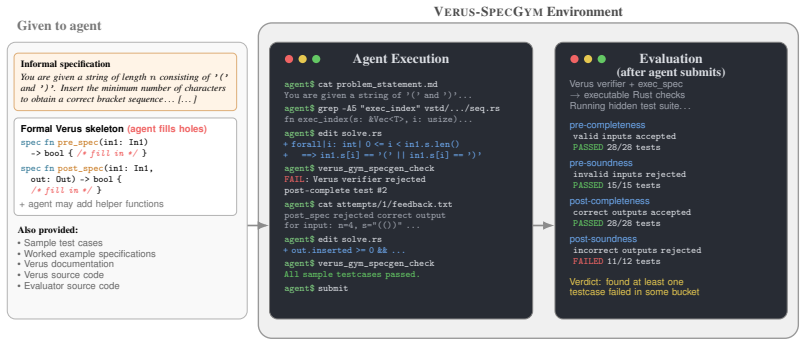


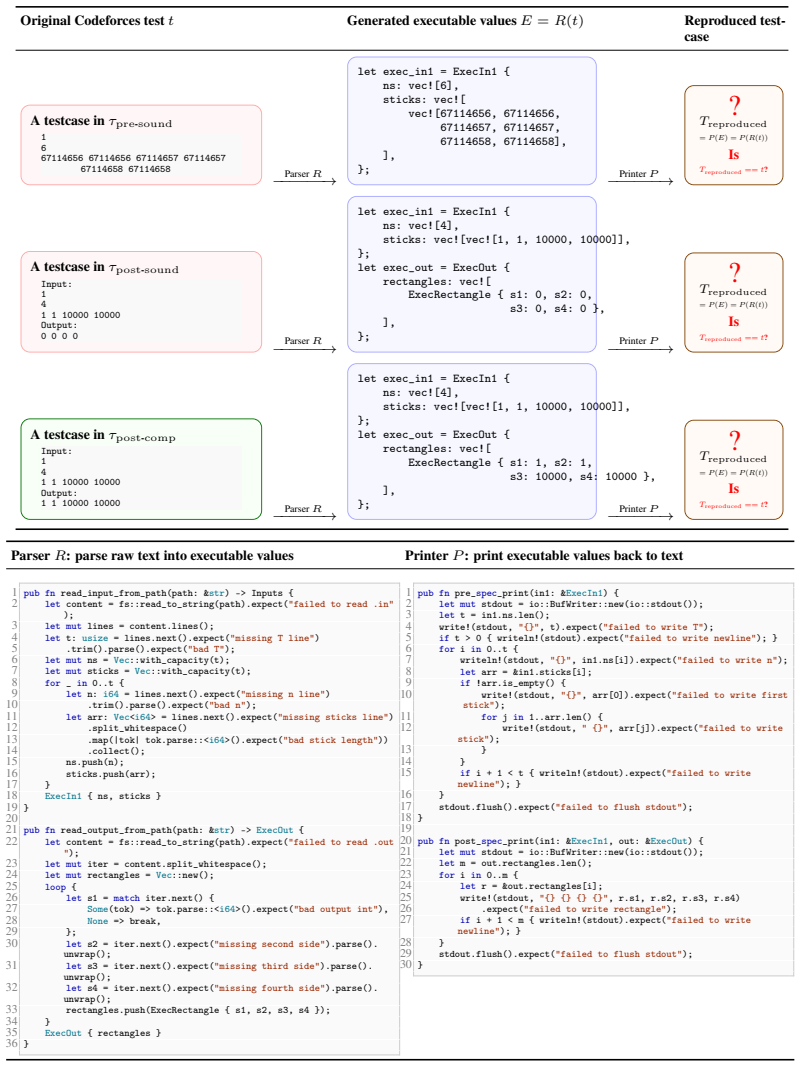
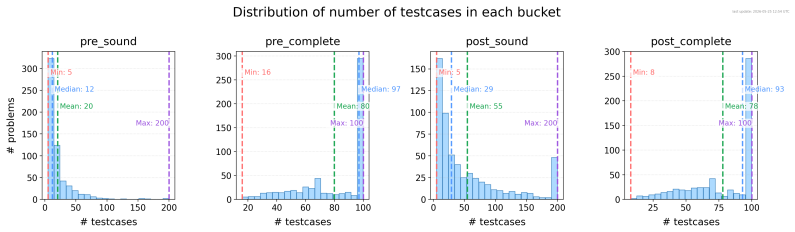
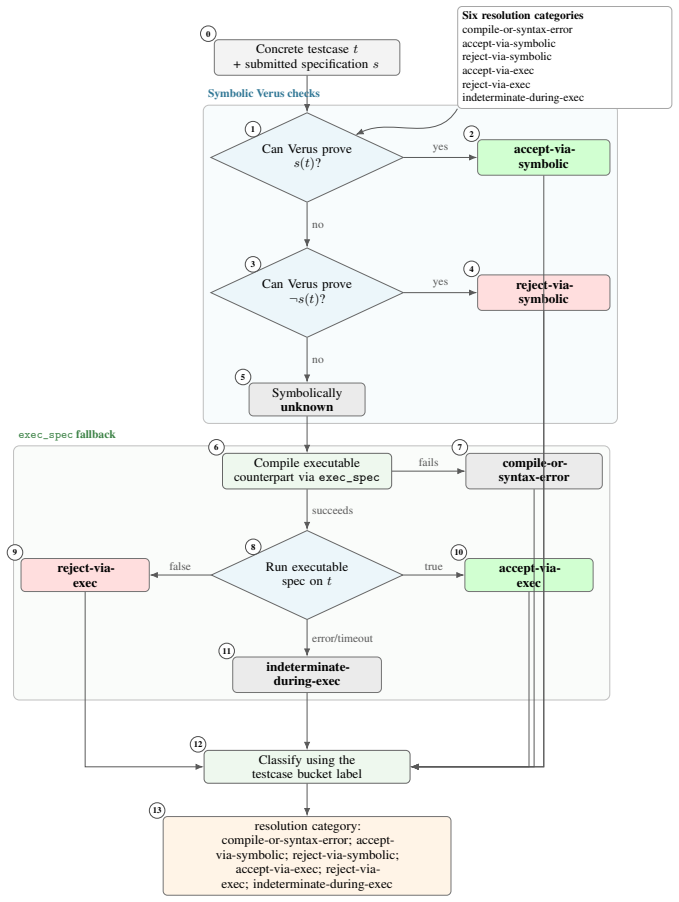


read the original abstract
AI coding agents are increasingly used to write real-world software, but ensuring that their outputs are correct remains a fundamental challenge. Formal verification offers a promising path: an agent generates code together with a machine-checked proof, guaranteeing that the code satisfies a formal specification. However, there is no guarantee that the formal spec itself matches the user's intent. In this work, we study specification autoformalization: whether LLM agents can translate informal programming problems into faithful formal specifications. We introduce Verus-SpecBench, a benchmark of 581 spec-writing tasks derived from Codeforces problems targeting Verus, a verifier for Rust, and Verus-SpecGym, an agentic environment in which models interact with Verus, bash, & the filesystem to develop these specs. The central challenge is evaluation: expert-written reference specs are expensive to write, & LLM judges can miss subtle mistakes. We address this by (a) extending Verus's exec_spec mechanism so that generated specs can be executed as Rust code, & (b) testing them against official Codeforces tests & adversarial cases extracted from Codeforces "hacks", which are edge cases written by competitors to break incorrect solutions. On Verus-SpecBench, the strongest model, Gemini 3.1 Pro, solves 77.8% of tasks, other frontier models solve 51.1--57.8% & OSS models reach only 21.5--25.5%. Our analysis of failure modes shows that model-generated specs can omit important input assumptions, accept incorrect outputs, & reject valid ones. We also find that LLM-as-a-judge evaluation misses 26% of the failures our evaluator catches. Overall, our results suggest that spec autoformalization is within reach for frontier agents but remains brittle even on problems where they can already generate correct code. The code, data, & logs can be found at https://github.com/formal-verif-is-cool/verus-spec-gym
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Verus-SpecBench, a benchmark of 581 specification autoformalization tasks derived from Codeforces problems targeting the Verus verifier for Rust, together with Verus-SpecGym, an agentic environment allowing LLMs to interact with Verus, bash, and the filesystem to develop specs. Correctness is determined by whether generated specs type-check and produce identical input/output behavior on official Codeforces tests plus extracted hacks; the strongest model (Gemini 3.1 Pro) solves 77.8% of tasks, other frontier models 51.1–57.8%, and OSS models 21.5–25.5%. The work also reports that an LLM judge misses 26% of the failures caught by the executable evaluator and catalogs failure modes such as omitted input assumptions.
Significance. If the test-and-hack proxy reliably measures fidelity to informal intent, the results would establish that frontier agents can already autoformalize specifications for a majority of realistic programming problems while underscoring remaining brittleness and the value of executable over LLM-based evaluation. The open release of code, data, and logs is a clear strength for reproducibility.
major comments (2)
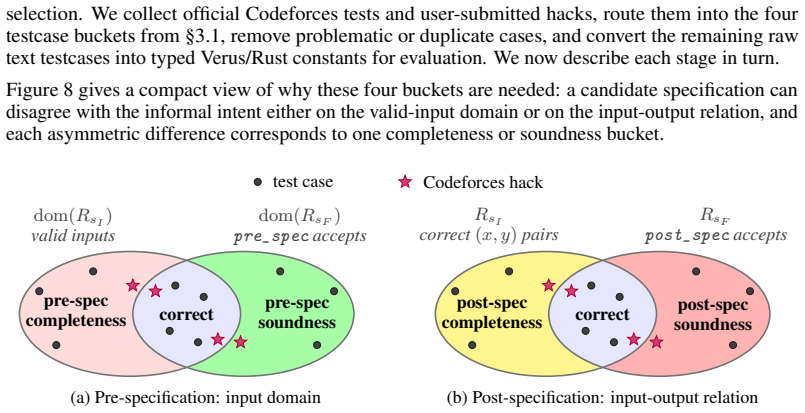
- [Abstract / Evaluation Methodology] Abstract and evaluation methodology: the headline solve rates (Gemini 3.1 Pro at 77.8 %, frontier models 51–58 %) are defined by the claim that a spec is correct if it type-checks and matches the behavior of the official tests plus extracted hacks. Because the benchmark supplies no gold reference specifications and the abstract itself lists failure modes (omitted assumptions, acceptance of incorrect outputs, rejection of valid ones) that can still pass the provided test distribution, the proxy may systematically overstate correctness on untested cases; this directly undermines the central performance claims.
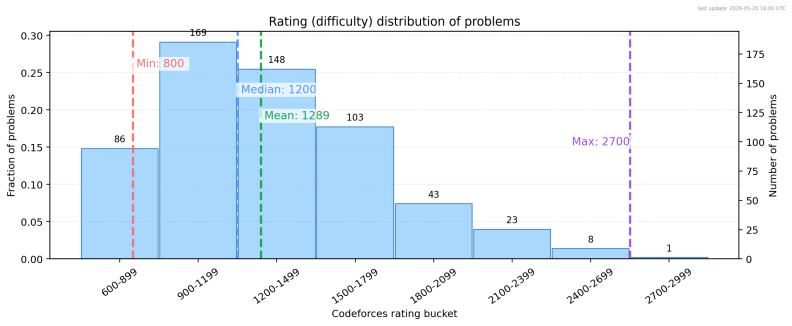
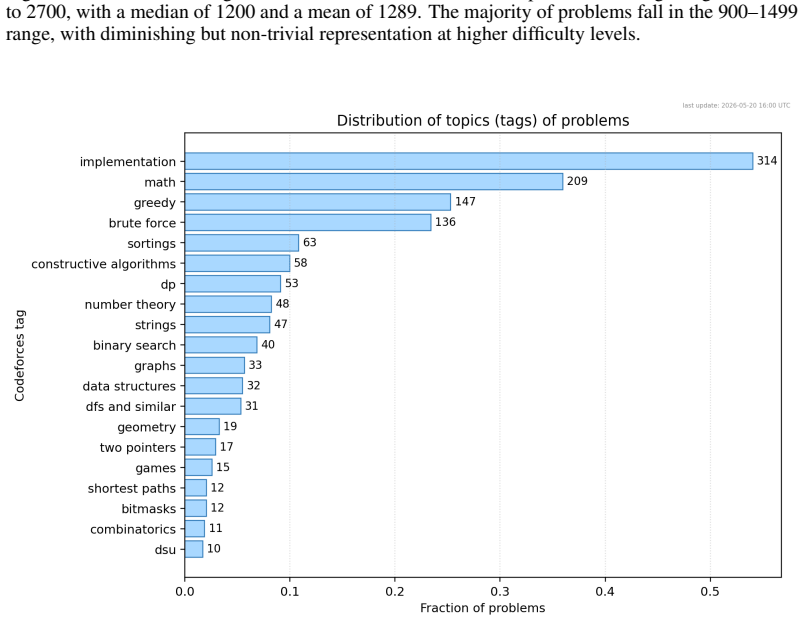
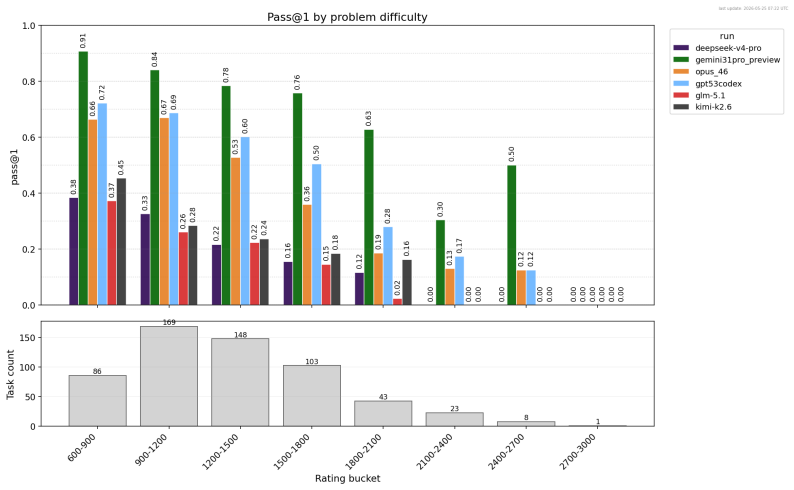
- [Task Construction and Results] Task selection and analysis: the manuscript reports aggregate numbers over 581 tasks but provides no breakdown by problem difficulty, no confidence intervals, and no description of how the Codeforces problems were filtered or sampled, making it impossible to assess whether the reported gaps between model classes are robust or driven by a non-representative subset.
minor comments (1)
- [Methodology] The description of the extended exec_spec mechanism would benefit from a short concrete example showing how an exec_spec is turned into executable Rust for testing.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comments point by point below, proposing revisions to strengthen the paper where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract / Evaluation Methodology] Abstract and evaluation methodology: the headline solve rates (Gemini 3.1 Pro at 77.8 %, frontier models 51–58 %) are defined by the claim that a spec is correct if it type-checks and matches the behavior of the official tests plus extracted hacks. Because the benchmark supplies no gold reference specifications and the abstract itself lists failure modes (omitted assumptions, acceptance of incorrect outputs, rejection of valid ones) that can still pass the provided test distribution, the proxy may systematically overstate correctness on untested cases; this directly undermines the central performance claims.
Authors: We agree that our evaluation relies on a proxy rather than gold-standard reference specifications, which are costly to produce. The paper explicitly discusses failure modes that could evade the tests and demonstrates that the executable evaluator catches 26% more failures than an LLM judge. However, to better contextualize the results, we will revise the abstract and methodology sections to more prominently state that the reported performance is measured against this test-and-hack proxy and to elaborate on its limitations, including the possibility of overstatement on untested inputs. We will also clarify the rationale for this approach in the absence of reference specs. revision: yes
-
Referee: [Task Construction and Results] Task selection and analysis: the manuscript reports aggregate numbers over 581 tasks but provides no breakdown by problem difficulty, no confidence intervals, and no description of how the Codeforces problems were filtered or sampled, making it impossible to assess whether the reported gaps between model classes are robust or driven by a non-representative subset.
Authors: We will incorporate a description of the sampling and filtering process used to select the 581 Codeforces problems for the benchmark. Additionally, we will add breakdowns of solve rates by problem difficulty (based on Codeforces ratings) and include confidence intervals for the key performance metrics to allow better assessment of the robustness of the observed differences between model classes. revision: yes
Circularity Check
Empirical benchmark study with no derivation chain or fitted parameters
full rationale
The paper introduces Verus-SpecBench and Verus-SpecGym as an empirical evaluation framework for LLM agents on specification autoformalization tasks derived from Codeforces problems. Performance is measured by executing generated specs against official tests and extracted hacks, with results reported as solve rates (e.g., Gemini 3.1 Pro at 77.8%). No mathematical derivations, equations, fitted parameters, or self-citation chains are present that reduce claims to inputs by construction. The work is self-contained against external benchmarks and test cases, with acknowledged limitations on the proxy metric treated as a correctness concern rather than circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Analyzing the Narration Gap in LLM-Solver Loops
The narration step in LLM-solver loops is vulnerable to prompt injection that inverts verified solver conclusions, and hardened prompts reduce but do not eliminate the risk under adaptive attacks.
Reference graph
Works this paper leans on
-
[1]
Hack availability.We remove problems from early contests that predate the Codeforces hack system, since hacks are essential for our soundness test cases
-
[2]
Stage 3: Hack collection and categorization.For each remaining problem, we collect official Codeforces tests and all user-submitted hacks
No floating point.We exclude problems that involve floating-point arithmetic, as Verus does not currently support floating-point reasoning. Stage 3: Hack collection and categorization.For each remaining problem, we collect official Codeforces tests and all user-submitted hacks. As described in §3.1 and summarized in Figure 4, a hack produces a test case w...
-
[3]
Valid input, incorrect output(the hacked solution produces output rejected by the Code- forces checker): the input contributes to τpre-comp, and the input-output pair is added to τpost-sound
-
[4]
correct” categories mean the resolved accept/reject verdict matches the testcase bucket; the “incorrect
Valid input, correct output(the hacked solution happens to produce accepted output): the input contributes toτ pre-comp, and the pair is added toτ post-comp. Several cleaning steps follow bucket assignment. Different attackers often propose identical hacks targeting different submissions; we de-duplicate test cases by their raw input-output content. Some ...
2074
-
[5]
The exact union contains 13 integer points, yet gemini-3.1pro’s executable postcondition rejects
-
[6]
‘out.len() == n‘
Similarly, hack_1118906__participant contains five identical radius-2 circles centered at 0, so the union is just one radius-2circle and again contains13points. 49 Listing 6: Snippet from postcondition generated by gemini-3.1pro for Codeforces 2074D that fails post-completeness hacks. exec_spec_unverified! { pub struct YInterval { pub y: i64, pub start: i...
-
[7]
**Starting point**: 317 318- It uses the ‘/home/dev/solve.rs‘ file you edited, with the provided fixed 319types and printers. 55 320- It also uses four **derived files** that extract only: 321- Your ‘pre_spec‘ / ‘post_spec‘, 322- Your four ‘*_proof‘ helpers, 323- The relevant ‘check_*‘ wrapper, 324- And any helper functions you introduced. 325
-
[8]
**Snippet injection**: 327 328- For each testcase and category, it reads: 329- ‘out.input_defn‘ and possibly ‘out.gt_output_defn‘. 330- It then substitutes these into the appropriate ‘check_*‘ function bodies: 331 332‘‘‘rust 333// __PASTE_out.input_defn__ 334// __PASTE_out.gt_output_defn__ 335‘‘‘ 336 337- The assertions inside the ‘check_*‘ functions are ...
-
[9]
352- ‘pre_sound‘ uses ‘check_pre_spec_soundness‘
**Verus execution**: 348 349- For each testcase, the evaluator runs Verus on the derived check wrapper 350for that testcase’s bucket: 351- ‘pre_complete‘ uses ‘check_pre_spec_completeness‘. 352- ‘pre_sound‘ uses ‘check_pre_spec_soundness‘. 353- ‘post_complete‘ uses ‘check_post_spec_completeness‘. 354- ‘post_sound‘ uses ‘check_post_spec_soundness‘. 355- It...
-
[10]
364- The test passes if Verus can prove ‘assert(pre_spec(...))‘
**Pass/fail logic**: 361 362- For **pre-completeness** tests (‘pre_complete‘): 363- The inputs are known valid. 364- The test passes if Verus can prove ‘assert(pre_spec(...))‘. 365- For **pre-soundness** tests (‘pre_sound‘): 366- The inputs are invalid. 367- The test passes if Verus can prove ‘assert(!pre_spec(...))‘. 368- For **post-completeness** tests ...
-
[11]
379- Final scoring uses the full evaluator suite, including hidden tests not 380present under ‘/home/symbolic_tests‘
**Visible vs hidden tests**: 376 377- Running ‘verus_gym_specgen_check‘ in this environment may give local/debug 378feedback on only the visible sample tests. 379- Final scoring uses the full evaluator suite, including hidden tests not 380present under ‘/home/symbolic_tests‘. 381- Use visible failures as diagnostics, but write specs from the problem 382st...
-
[12]
436- Inputs are represented by a single logical input struct ‘In1‘
**Understand the problem:** 435- Read ‘/home/problem_artifacts/problem_statement.md‘ carefully. 436- Inputs are represented by a single logical input struct ‘In1‘. 437- Outputs are represented by ‘Out‘. 438- Check ‘/home/examples/solve.rs‘ for a worked example of a complete Verus specification file. 439
-
[13]
442- Look at a few ‘out.input_defn‘ / ‘out.gt_output_defn‘ files under ‘/home/symbolic_tests/*/*/‘ 443to see concrete examples of how ‘ExecIn1‘ / ‘ExecOut‘ are constructed
**Inspect the existing types and snippets:** 441- Look at ‘/home/dev/solve.rs‘ and confirm the definitions of ‘In1‘ and ‘Out‘. 442- Look at a few ‘out.input_defn‘ / ‘out.gt_output_defn‘ files under ‘/home/symbolic_tests/*/*/‘ 443to see concrete examples of how ‘ExecIn1‘ / ‘ExecOut‘ are constructed. 444
-
[14]
**Sketch ‘pre_spec‘:** 446- Encode all input constraints from the problem statement. 447
-
[15]
**Sketch ‘post_spec‘:** 449- Express the output correctness condition from the problem statement. 450
-
[16]
453- Fill in the four ‘*_proof‘ functions enough to help Verus verify the 454‘check_*‘ assertions
**Add or refine helpers and proofs:** 452- Introduce helper spec functions to keep ‘pre_spec‘/‘post_spec‘ readable. 453- Fill in the four ‘*_proof‘ functions enough to help Verus verify the 454‘check_*‘ assertions. 455
-
[17]
459- For failing tests, inspect: 460- ‘/home/attempts/<run_id>/snippets/<category>/<test_id>/*.rs‘ 461- Corresponding ‘.stdout‘ / ‘.stderr‘ paths mentioned in the error messages
**Use the feedback loop:** 457- After running ‘verus_gym_specgen_check‘, read 458‘/home/attempts/<run_id>/natural_language_feedback.txt‘. 459- For failing tests, inspect: 460- ‘/home/attempts/<run_id>/snippets/<category>/<test_id>/*.rs‘ 461- Corresponding ‘.stdout‘ / ‘.stderr‘ paths mentioned in the error messages. 462- Adjust specs and proofs to fix the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.