SEC-bench Pro: Can Language Models Solve Long-Horizon Software Security Tasks?
Pith reviewed 2026-06-29 17:26 UTC · model grok-4.3
The pith
Frontier language models solve under 40% of real-world browser engine security bugs on SEC-bench Pro.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
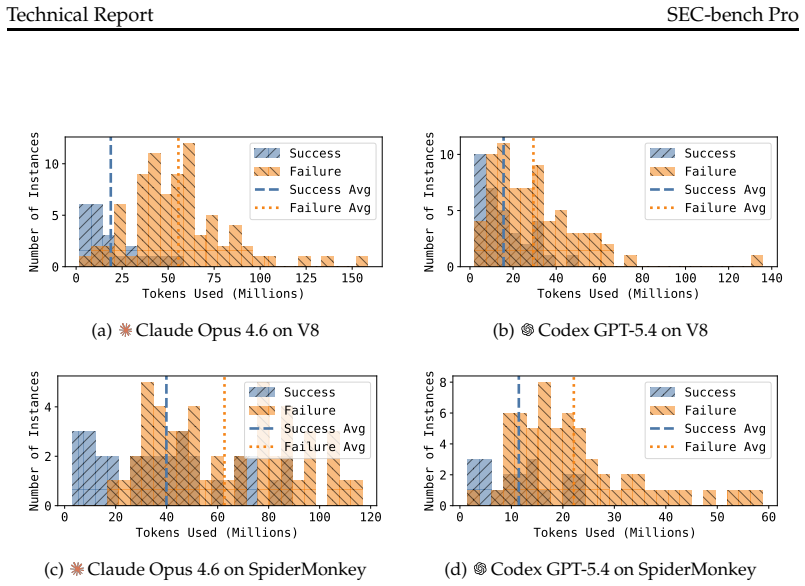
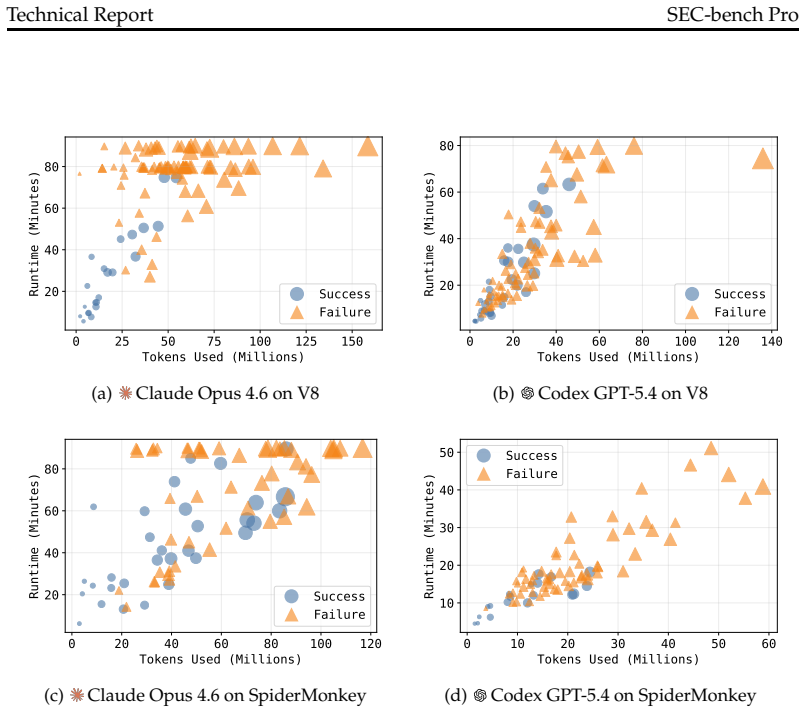
SEC-bench Pro supplies 183 reproducible tasks spanning memory-safety, sandbox, JIT, and race-condition vulnerabilities under realistic browser and runtime conditions; when coding agents powered by frontier models are run on these tasks, success stays below 40% on both V8 and SpiderMonkey, with the open-weight Kimi-K2.6 baseline at 11.7% on V8 and the strongest frontier setup at 32.0% on V8 and 38.8% on SpiderMonkey.
What carries the argument
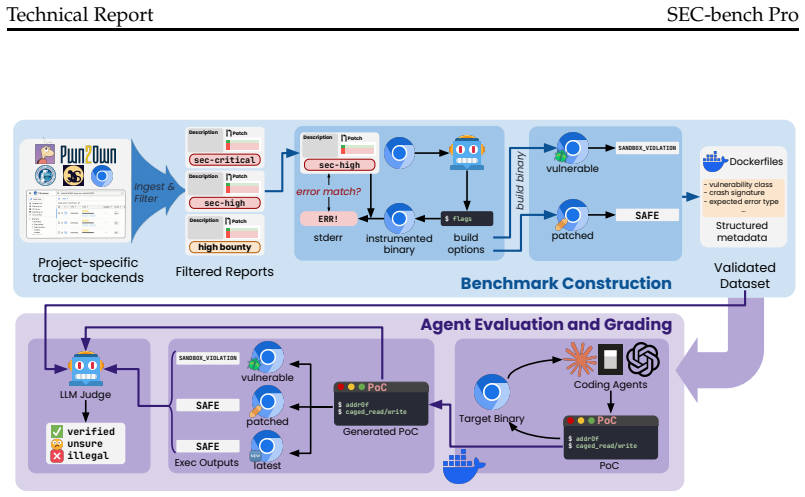
The three-phase pipeline that collects real vulnerability reports, reconstructs executable environments, and attaches oracle-based validation to turn each report into a self-contained bug-hunting task.
If this is right
- Single frontier-model agents remain below 40% success on both evaluated engines.
- ClaudeCode and Codex solve largely complementary subsets, so their union lifts performance to 37.9% on V8 and 48.8% on SpiderMonkey.
- The benchmark covers a V8 subset whose cumulative rewards exceed $1.5 million, showing that the unsolved tasks include high-impact cases.
- Open-weight baselines achieve markedly lower rates (11.7% on V8) than frontier models.
Where Pith is reading between the lines
- The results suggest that further gains may require explicit mechanisms for multi-turn environment exploration rather than single-shot code generation.
- Because the tasks already include concrete PoC inputs and oracles, the benchmark could be used to measure progress on agent scaffolding that chains multiple tool calls over dozens of steps.
- Extending the same pipeline to additional engines would test whether the observed ceiling is specific to JavaScript runtimes or general across security-critical codebases.
Load-bearing premise
The pipeline produces tasks whose difficulty and artifacts match those encountered in actual bug hunting without systematically changing agent success rates.
What would settle it
A new agent configuration that consistently exceeds 50% success across the full set of 183 tasks while using only the provided environments and oracles would directly contradict the reported performance ceiling.
Figures
read the original abstract
Large language models (LLMs) now support automated software security tasks, including vulnerability discovery and proof-of-concept (PoC) generation. Existing benchmarks do not faithfully evaluate LLMs in real-world bug hunting scenarios because they rely on fuzzing harnesses, target-specific descriptions, or vulnerability-reproduction tasks. We present SEC-bench Pro, a benchmark for measuring agent bug hunting on critical, high-complexity software systems. This work discloses reports with concrete PoC inputs and links fixes into reproducible tasks through a three-phase pipeline for vulnerability collection, environment reconstruction, and oracle-based validation. We instantiate SEC-bench Pro with 183 validated vulnerabilities across V8 and SpiderMonkey, including a V8 subset with more than $1.5 million in cumulative Google Vulnerability Reward Program awards. These instances span memory-safety, sandbox, JIT, and race-condition bugs under browser-grade and runtime-grade execution conditions. Our evaluation shows that coding agents with frontier models remain below 40% success on both evaluated engines. The open-weight Kimi-K2.6 baseline reaches 11.7% on V8, while the strongest frontier configuration reaches 32.0% on V8 and 38.8% on SpiderMonkey. ClaudeCode and Codex solve complementary instance sets, and their two-agent union reaches 37.9% on V8 and 48.8% on SpiderMonkey. SEC-bench Pro provides robust environments for assessing LLM-based security agents and exposes limitations in long-horizon bug hunting tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SEC-bench Pro, a benchmark for LLM-based coding agents on long-horizon software security tasks. It describes a three-phase pipeline (vulnerability collection, environment reconstruction, oracle-based validation) that yields 183 validated tasks drawn from V8 and SpiderMonkey, including a high-value V8 subset. The evaluation reports that frontier-model agents achieve success rates below 40% on both engines (e.g., strongest single configuration at 32.0% on V8 and 38.8% on SpiderMonkey), with complementary coverage from ClaudeCode and Codex whose union reaches 37.9% and 48.8% respectively; an open-weight baseline reaches 11.7% on V8.
Significance. If the constructed tasks preserve real-world difficulty and information structure, the work supplies a concrete, reproducible benchmark that exposes current limitations of frontier models on browser- and runtime-grade security tasks and illustrates gains from multi-agent collaboration. The use of actual high-reward vulnerabilities and the release of environments constitute clear strengths for the security and LLM-agent communities.
major comments (2)
- [§3 and abstract] §3 (three-phase pipeline) and abstract: The headline claim that agents remain below 40% success on V8/SpiderMonkey is load-bearing on the assertion that the 183 tasks match unaltered real-world bug-hunting difficulty. No human-expert baseline, information-leakage audit, or ablation of oracle strictness or reconstruction artifacts (build logs, symbol tables, harness simplification) is reported, so it is impossible to determine whether measured rates are systematically inflated or deflated relative to production codebases.
- [abstract and §4] Evaluation results (abstract and §4): Concrete success percentages are given without accompanying trial counts, variance estimates, or statistical tests, making it difficult to assess whether the reported gaps (e.g., 32.0% vs. 11.7%) are robust or sensitive to evaluation protocol details.
minor comments (2)
- [abstract] The abstract states that tasks span memory-safety, sandbox, JIT, and race-condition bugs under browser- and runtime-grade conditions; a short table or subsection enumerating the distribution across these categories would improve clarity.
- [evaluation] The manuscript should explicitly state the precise definition of "success" (e.g., whether a PoC must trigger the exact intended vulnerability path or merely produce a crash accepted by the oracle).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on SEC-bench Pro. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [§3 and abstract] §3 (three-phase pipeline) and abstract: The headline claim that agents remain below 40% success on V8/SpiderMonkey is load-bearing on the assertion that the 183 tasks match unaltered real-world bug-hunting difficulty. No human-expert baseline, information-leakage audit, or ablation of oracle strictness or reconstruction artifacts (build logs, symbol tables, harness simplification) is reported, so it is impossible to determine whether measured rates are systematically inflated or deflated relative to production codebases.
Authors: The pipeline reconstructs environments directly from the original vulnerability reports, PoCs, and linked fixes, preserving the exact conditions under which the bugs were reported. Task prompts contain only the vulnerability description and reproduction requirements without solution hints. While we agree that an explicit ablation of reconstruction artifacts and a formal information-leakage audit would strengthen the presentation, a full human-expert baseline on 183 tasks is outside the scope of the current work. We will add a dedicated limitations subsection discussing these points in the revision. revision: partial
-
Referee: [abstract and §4] Evaluation results (abstract and §4): Concrete success percentages are given without accompanying trial counts, variance estimates, or statistical tests, making it difficult to assess whether the reported gaps (e.g., 32.0% vs. 11.7%) are robust or sensitive to evaluation protocol details.
Authors: We agree that the evaluation section would benefit from explicit trial counts, standard deviations across runs, and statistical comparisons. We will revise §4 (and update the abstract accordingly) to include these details and any applicable significance tests. revision: yes
- A complete human-expert baseline and exhaustive information-leakage audit on the full 183-task set, which would require substantial new experiments not present in the manuscript.
Circularity Check
Empirical benchmark with no derivation chain or fitted predictions
full rationale
This paper presents an empirical benchmark (SEC-bench Pro) built via a three-phase pipeline and evaluated directly on 183 tasks, reporting measured success rates (<40% for frontier models) with no equations, parameter fittings, self-referential predictions, or load-bearing self-citations that reduce any claim to its own inputs by construction. The methodology is a data-collection and validation process whose outputs are the benchmark instances themselves; reported performance numbers are external measurements on those instances rather than quantities derived from prior fitted values or uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introducing Claude Opus 4.6
Anthropic. Introducing Claude Opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2026a. Anthropic. Assessing Claude Mythos Preview’s cybersecurity capabilities. https://red. anthropic.com/2026/mythos-preview/, 2026b. Toby Clarke. Fuzzing for software vulnerability discovery. Technical Report RHUL-MA- 2009-04, Department of Mathematics, Royal Hollo...
2026
-
[2]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. SWE-Bench Pro: Can AI Agents Solve Long-Ho...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Context Length Alone Hurts LLM Performance Despite Perfect Retrieval
Yufeng Du, Minyang Tian, Srikanth Ronanki, Subendhu Rongali, Sravan Babu Bodapati, Aram Galstyan, Azton Wells, Roy Schwartz, Eliu A Huerta, and Hao Peng. Context Length Alone Hurts LLM Performance Despite Perfect Retrieval. InFindings of the Association for Computational Linguistics: EMNLP 2025, pp. 23281–23298. Association for Computational Linguistics,
2025
-
[4]
URLhttps://aclanthology.org/2025.findings-emnlp.1264/. Google. OSS-Fuzz: Continuous Fuzzing for Open Source Software. https://github.com/ google/oss-fuzz,
2025
-
[5]
Nancy Lau, Louis Sloot, Jyoutir Raj, Giuseppe Marco Boscardin, Evan Harris, Dylan Bowman, Mario Brajkovski, Jaideep Chawla, and Dan Zhao. ZeroDayBench: Evalu- ating LLM Agents on Unseen Zero-Day Vulnerabilities for Cyberdefense.arXiv preprint arXiv:2603.02297,
-
[6]
Haoyu Li, Xijia Che, Yanhao Wang, Xiaojing Liao, and Luyi Xing
URL https:// openreview.net/forum?id=QQhQIqons0. Haoyu Li, Xijia Che, Yanhao Wang, Xiaojing Liao, and Luyi Xing. Execution-State- Aware LLM Reasoning for Automated Proof-of-Vulnerability Generation.arXiv preprint arXiv:2602.13574,
-
[7]
Bin Liu, Yanjie Zhao, Zhenpeng Chen, Guoai Xu, and Haoyu Wang. A Dual-Loop Agent Framework for Automated Vulnerability Reproduction.arXiv preprint arXiv:2602.05721,
-
[8]
Alireza Lotfi, Charalampos Katsis, and Elisa Bertino. Automated Vulnerability Validation and Verification: A Large Language Model Approach.arXiv preprint arXiv:2509.24037,
-
[9]
ARVO: Atlas of Reproducible Vulnerabilities for Open-Source Software
Xiang Mei, Pulkit Singh Singaria, Jordi Del Castillo, Haoran Xi, Tiffany Bao, Ruoyu Wang, Yan Shoshitaishvili, Adam Doupé, Hammond Pearce, Brendan Dolan-Gavitt, et al. ARVO: Atlas of Reproducible Vulnerabilities for Open Source Software.arXiv preprint arXiv:2408.02153,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Vikram Nitin, Baishakhi Ray, and Roshanak Zilouchian Moghaddam. FaultLine: Automated Proof-of-Vulnerability Generation Using LLM Agents.arXiv preprint arXiv:2507.15241,
-
[11]
Codex Security.https://help.openai.com/articles/20001107, 2026a
OpenAI. Codex Security.https://help.openai.com/articles/20001107, 2026a. 17 Technical Report SEC-bench Pro OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , 2026b. Wanzong Peng, Lin Ye, Xuetao Du, Hongli Zhang, Dongyang Zhan, Yunting Zhang, Yicheng Guo, and Chen Zhang. PwnGPT: Automatic Exploit Generation Based on Large Language...
-
[12]
Juefei Pu, Xingyu Li, Zhengchuan Liang, Jonathan Cox, Yifan Wu, Kareem Shehada, Arrdya Srivastav, and Zhiyun Qian. Patch-to-PoC: A Systematic Study of Agentic LLM Systems for Linux Kernel N-Day Reproduction.arXiv preprint arXiv:2602.07287,
-
[13]
Deniz Simsek, Aryaz Eghbali, and Michael Pradel
URLhttps://openreview.net/forum?id=itBDglVylS. Deniz Simsek, Aryaz Eghbali, and Michael Pradel. PoCGen: Generating Proof-of-Concept Exploits for Vulnerabilities in Npm Packages.arXiv preprint arXiv:2506.04962,
-
[14]
To Err is Machine: Vulnerability Detection Challenges LLM Reasoning.arXiv preprint arXiv:2403.17218,
Benjamin Steenhoek, Md Mahbubur Rahman, Monoshi Kumar Roy, Mirza Sanjida Alam, Hengbo Tong, Swarna Das, Earl T Barr, and Wei Le. To Err is Machine: Vulnerability Detection Challenges LLM Reasoning.arXiv preprint arXiv:2403.17218,
-
[15]
From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code
Big Sleep team. From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code. https://googleprojectzero.blogspot.com/2024/ 10/from-naptime-to-big-sleep.html,
2024
-
[16]
Coskun, and Gianluca Stringhini
Saad Ullah, Mingji Han, Saurabh Pujar, Hammond Pearce, Ayse K. Coskun, and Gianluca Stringhini. LLMs Cannot Reliably Identify and Reason About Security Vulnerabilities (Yet?): A Comprehensive Evaluation, Framework, and Benchmarks. InIEEE Symposium on Security and Privacy, SP 2024, San Francisco, CA, USA, May 19-23, 2024, pp. 862–880. IEEE,
2024
-
[17]
Saad Ullah, Praneeth Balasubramanian, Wenbo Guo, Amanda Burnett, Hammond Pearce, Christopher Kruegel, Giovanni Vigna, and Gianluca Stringhini. From CVE Entries to Verifiable Exploits: An Automated Multi-Agent Framework for Reproducing CVEs.arXiv preprint arXiv:2509.01835,
-
[18]
URL https: //openreview.net/forum?id=2YvbLQEdYt. Zichao Wei, Jun Zeng, Ming Wen, Zeliang Yu, Kai Cheng, Yiding Zhu, Jingyi Guo, Shiqi Zhou, Le Yin, Xiaodong Su, and Zhechao Ma. PATCHEVAL: A New Benchmark for Evaluating LLMs on Patching Real-World Vulnerabilities.arXiv preprint arXiv:2511.11019,
-
[19]
Why Is CSP Failing? Trends and Challenges in CSP Adoption
Michael Weissbacher, Tobias Lauinger, and William Robertson. Why Is CSP Failing? Trends and Challenges in CSP Adoption. InResearch in Attacks, Intrusions and Defenses - 17th International Symposium, RAID 2014, Gothenburg, Sweden, September 17-19,
2014
-
[20]
ProgramBench: Can Language Models Rebuild Programs From Scratch?
doi: 10.1007/978-3-319-11379-1_11. URL https://doi.org/ 10.1007/978-3-319-11379-1_11. John Yang, Kilian Lieret, Jeffrey Ma, Parth Thakkar, Dmitrii Pedchenko, Sten Sootla, Emily McMilin, Pengcheng Yin, Rui Hou, Gabriel Synnaeve, Diyi Yang, and Ofir Press. Pro- gramBench: Can Language Models Rebuild Programs From Scratch?arXiv preprint arXiv:2605.03546,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-319-11379-1_11
-
[21]
Bhatia, Vikram Sivashankar, Yuxuan Bao, Dawn Song, Dan Boneh, Daniel Ho, and Percy Liang
Andy Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Wang, Junrong Wu, Kyleen Liao, Jiliang Li, Jinghan Hu, Sara Hong, Nardos Demilew, Shivatmica Murgai, Jason Tran, Nishka Kacheria, Ethan Ho, Denis Liu, Lauren McLane, Olivia Bruvik, Dai- Rong Han, Seungwoo Kim, Akhil Vyas, Cuiyuanxiu Chen, Ryan Li, Weiran Xu, Jonathan Ye, Prerit Choudhary,...
-
[22]
Mengyao Zhao, Kaixuan Li, Lyuye Zhang, Wenjing Dang, Chenggong Ding, Sen Chen, and Zheli Liu. A Systematic Study on Generating Web Vulnerability Proof-of-Concepts Using Large Language Models.arXiv preprint arXiv:2510.10148,
-
[23]
AnyPoC: Universal Proof-of-Concept Test Generation for Scalable LLM-Based Bug Detection
Zijie Zhao, Chenyuan Yang, Weidong Wang, Yihan Yang, Ziqi Zhang, and Lingming Zhang. AnyPoC: Universal Proof-of-Concept Test Generation for Scalable LLM-Based Bug Detec- tion.arXiv preprint arXiv:2604.11950,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
not on target page
Each case box reports the historical issue, target files, expected crash signal, agent trajectories, compact evidence excerpts, and the resulting takeaway. The excerpts are shortened to the lines that drive the judge decision. This format connects the aggregate success rates in §4.2 to concrete execution behavior. It also separates two failure mechanisms ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.