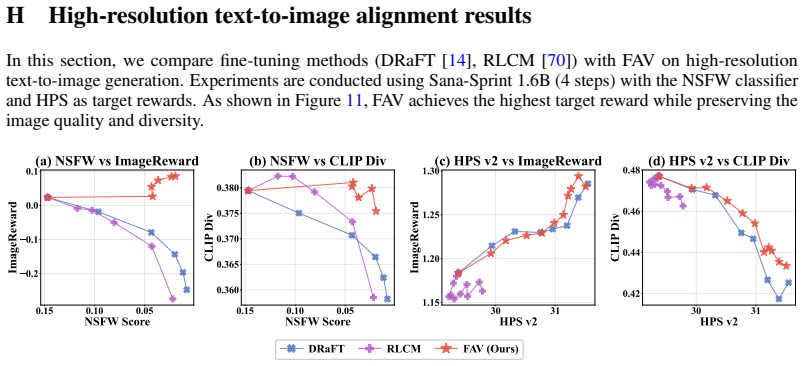
Aligning Few-Step Generative Models by Amortizing Sample-based Variational Inference
Pith reviewed 2026-06-29 19:14 UTC · model grok-4.3
The pith
FAV aligns few-step generative models by amortizing Stein variational gradient descent particle updates into the generator parameters via fixed-point regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
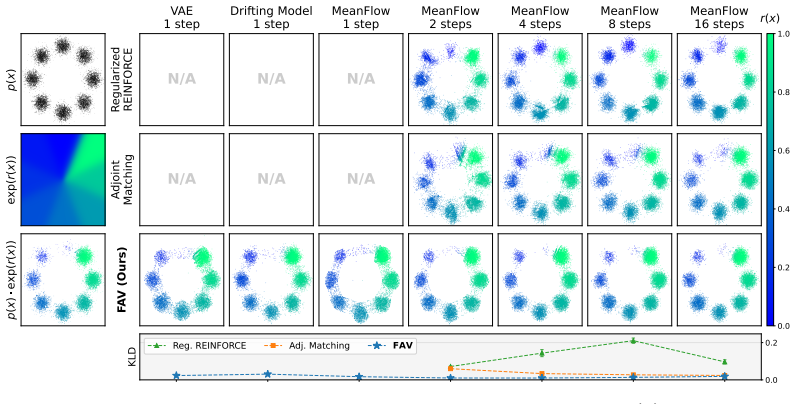
Alignment of few-step generative models can be performed by casting the problem as sampling from a reward-tilted distribution anchored to a reference, running Stein variational gradient descent to move particles, and regressing the generator parameters so that its next samples match the particle updates, thereby amortizing the inference steps without needing tractable likelihoods, specific ODE solvers, or model-family restrictions.
What carries the argument
Fixed-point regression that amortizes the particle updates produced by Stein variational gradient descent on the reward-tilted distribution into the parameters of the generator.
If this is right
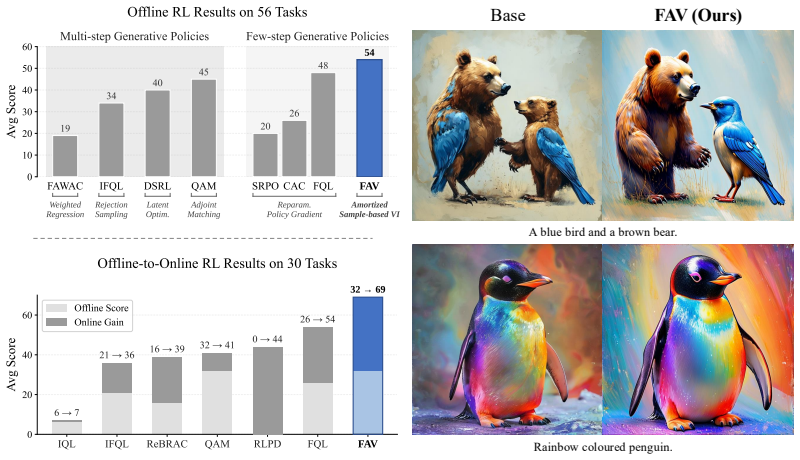
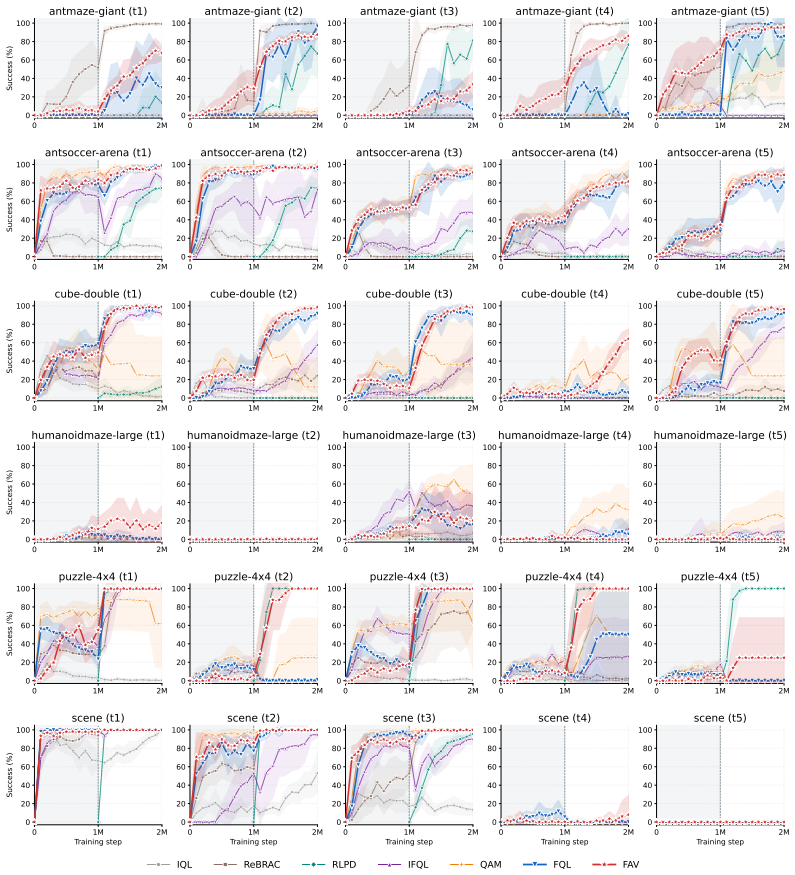
- On robotic manipulation, the aligned policies outperform prevailing policy extraction baselines on 56 offline and 30 offline-to-online reinforcement learning tasks.
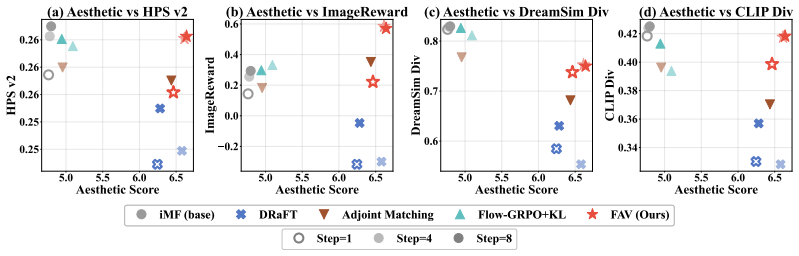
- The same procedure fine-tunes GANs, drifting models, consistency models, and flow maps for image generation.
- The approach scales from ImageNet-256 to 1024 squared text-to-image synthesis.
- Alignment succeeds using only sample access rather than requiring tractable likelihoods or particular dynamics solvers.
Where Pith is reading between the lines
- The amortization step could be tested for stability when the reward function changes rapidly between alignment rounds.
- The same regression idea might extend to amortizing other particle-based inference methods beyond Stein variational gradient descent.
- If the fixed-point mapping holds, the aligned generator could serve as an approximate sampler for new reward functions without re-running particle optimization from scratch.
Load-bearing premise
The particle updates from Stein variational gradient descent on the reward-tilted distribution can be faithfully recovered by training the generator parameters through fixed-point regression without introducing bias or instability.
What would settle it
A direct comparison experiment in which samples drawn from the aligned generator after FAV training are shown to have a reward distribution that differs measurably from the distribution obtained by running many steps of Stein variational gradient descent directly on the same tilted target.
Figures




read the original abstract
Aligning a few-step generative model is challenging, since existing alignment frameworks typically rely on restrictive assumptions: a tractable likelihood, a specific ODE/SDE solver, or a particular model family. We introduce FAV, Few-step Generative Models Alignment via Sample-based Variational Inference, a general alignment framework that requires only sample access to the generator and the reference distribution. We cast alignment as sampling from a reward-tilted distribution anchored to a reference distribution. We leverage Stein Variational Gradient Descent as a sample-based variational inference scheme and amortize its particle updates into the generator parameters via fixed-point regression. We evaluate FAV on two domains: robotics manipulation and image generator alignment. On generative policy alignment for robotic manipulation, FAV outperforms prevailing policy extraction baselines across 56 offline and 30 offline-to-online RL tasks. For image generator alignment, FAV fine-tunes diverse few-step backbones, including GAN, drifting model, consistency models, and flow maps, scaling from ImageNet-$256$ to 1024$^2$ text-to-image synthesis. Code is available at https://github.com/Jaewoopudding/FAV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FAV, a general framework for aligning few-step generative models that requires only sample access. Alignment is cast as sampling from a reward-tilted distribution p(x) ∝ p_ref(x) exp(r(x)); SVGD is used to generate particle updates on this target, which are then amortized into the generator parameters via fixed-point regression. Empirical claims include outperformance over policy extraction baselines on 56 offline and 30 offline-to-online robotic manipulation tasks, plus successful fine-tuning of diverse few-step backbones (GAN, drifting models, consistency models, flow maps) scaling from ImageNet-256 to 1024² text-to-image synthesis. Code is released.
Significance. If the amortization step is shown to be unbiased and stable, the method would provide a broadly applicable alignment procedure that avoids assumptions on likelihoods, ODE/SDE solvers, or model families, with demonstrated scaling across robotics and high-resolution image domains. Explicit code release is a positive contribution to reproducibility.
major comments (2)
- [Abstract and method overview] The central claim that fixed-point regression of generator parameters recovers the SVGD stationary distribution on the reward-tilted target (and thereby supports the alignment guarantee) is load-bearing, yet the abstract and method description provide no derivation establishing that the regression objective is unbiased with respect to the Stein operator or that the few-step generator class is sufficiently expressive to represent the required transport map without introducing bias or instability.
- [Experimental evaluation sections] Empirical performance claims (outperformance on 86 RL tasks and scaling to 1024² synthesis) are presented without reported error bars, ablation studies on the amortization step, or verification that the learned generator's empirical distribution matches the SVGD particles on the tilted distribution; these omissions prevent assessment of whether the reported gains are attributable to the proposed amortization or to other factors.
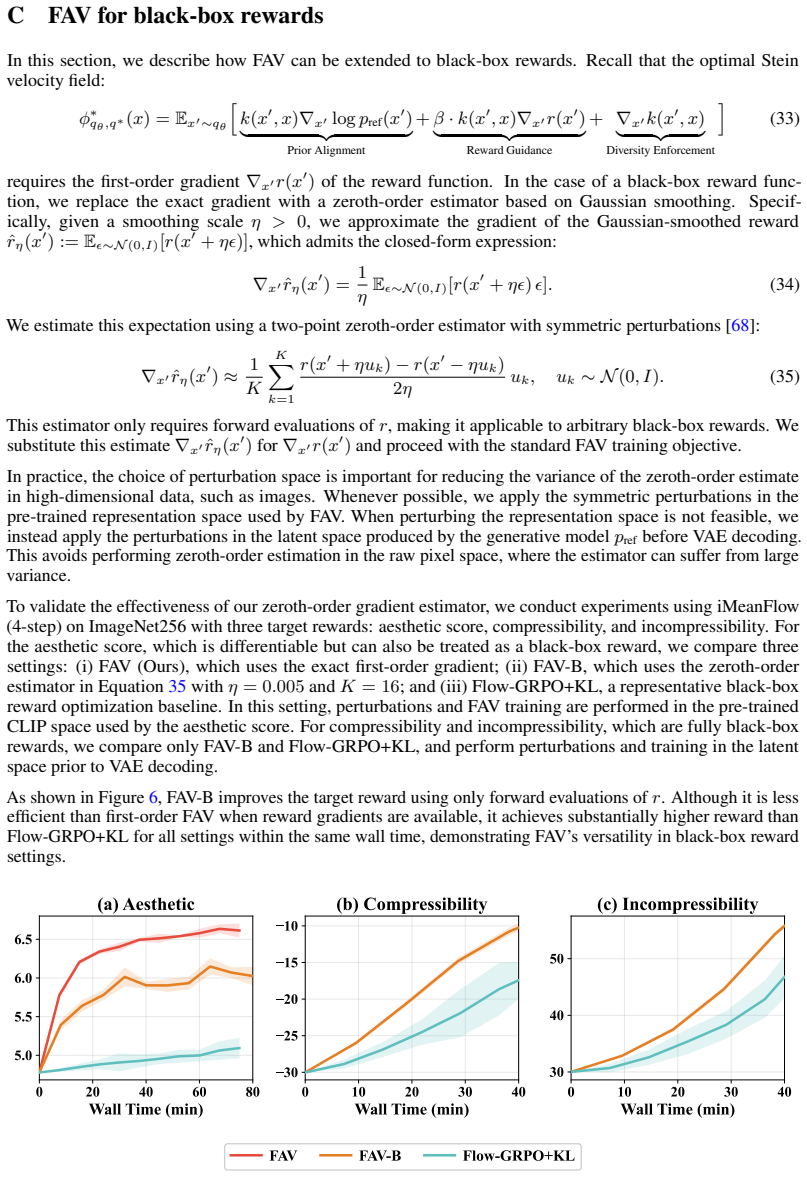
minor comments (2)
- [Method] Notation for the fixed-point regression objective and the precise form of the Stein operator used in the amortization step should be introduced with explicit equations rather than descriptive prose.
- [Abstract] The abstract states results across 'diverse few-step backbones' but does not list the exact model families or training hyperparameters used in the image-alignment experiments; a table summarizing these would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional clarity and rigor would strengthen the presentation of FAV. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and method overview] The central claim that fixed-point regression of generator parameters recovers the SVGD stationary distribution on the reward-tilted target (and thereby supports the alignment guarantee) is load-bearing, yet the abstract and method description provide no derivation establishing that the regression objective is unbiased with respect to the Stein operator or that the few-step generator class is sufficiently expressive to represent the required transport map without introducing bias or instability.
Authors: We agree that the abstract and method overview are concise and do not contain an explicit derivation. The full method section motivates the fixed-point regression as directly amortizing the SVGD particle updates on the reward-tilted distribution, with the regression objective designed to enforce the fixed-point condition. To make the connection to the Stein operator explicit and address potential bias, we will add a dedicated subsection deriving that the regression loss corresponds to an empirical estimate of the Stein discrepancy, establishing unbiasedness in the large-sample limit. We will also expand the discussion of expressiveness to acknowledge that the few-step generator approximates the transport map and may introduce some bias, while noting that the empirical results across diverse backbones provide supporting evidence; we will include a brief analysis of approximation quality. revision: yes
-
Referee: [Experimental evaluation sections] Empirical performance claims (outperformance on 86 RL tasks and scaling to 1024² synthesis) are presented without reported error bars, ablation studies on the amortization step, or verification that the learned generator's empirical distribution matches the SVGD particles on the tilted distribution; these omissions prevent assessment of whether the reported gains are attributable to the proposed amortization or to other factors.
Authors: We agree that these elements are necessary for a complete evaluation. In the revised version we will report error bars (standard deviations across multiple random seeds) for all quantitative results on the robotics and image tasks. We will add ablation studies that isolate the amortization step, including variants with and without the fixed-point regression. We will also include a verification experiment that directly compares the empirical distribution of the learned generator to the SVGD particles (e.g., via MMD or sliced Wasserstein distance on representative tasks) to confirm that the reported gains arise from the proposed amortization procedure. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper describes casting alignment as sampling from a reward-tilted distribution, applying SVGD for sample-based VI, and amortizing particle updates via fixed-point regression into generator parameters. No quoted equations or steps in the abstract reduce any claimed prediction or result to a fitted input, self-definition, or self-citation chain by construction. Performance is reported on external robotics RL tasks and image synthesis benchmarks, with no indication that results are forced by the method's own fitted quantities. The derivation remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stein Variational Gradient Descent produces useful particle updates for sampling from reward-tilted distributions anchored to a reference.
Reference graph
Works this paper leans on
-
[1]
Joint Distillation for Fast Likelihood Evaluation and Sampling in Flow-based Models
Xinyue Ai, Yutong He, Albert Gu, Ruslan Salakhutdinov, J Zico Kolter, Nicholas Matthew Boffi, and Max Simchowitz. Joint distillation for fast likelihood evaluation and sampling in flow-based models.arXiv preprint arXiv:2512.02636, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
2023
-
[3]
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans.arXiv preprint arXiv:1801.01401, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InThe Twelfth International Conference on Learning Representations
-
[5]
Variational inference: A review for statisticians.Journal of the American statistical Association, 112(518):859–877, 2017
David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians.Journal of the American statistical Association, 112(518):859–877, 2017
2017
-
[6]
Flow map matching with stochastic interpolants: A mathematical framework for consistency models
Nicholas Matthew Boffi, Michael Samuel Albergo, and Eric Vanden-Eijnden. Flow map matching with stochastic interpolants: A mathematical framework for consistency models. Transactions on Machine Learning Research
-
[7]
How to build a consistency model: Learning flow maps via self-distillation
Nicholas Matthew Boffi, Michael Samuel Albergo, and Eric Vanden-Eijnden. How to build a consistency model: Learning flow maps via self-distillation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[8]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman- Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018
2018
-
[9]
Score regularized policy optimization through diffusion behavior
Huayu Chen, Cheng Lu, Zhengyi Wang, Hang Su, and Jun Zhu. Score regularized policy optimization through diffusion behavior. InThe Twelfth International Conference on Learning Representations
-
[10]
Sana-sprint: One-step diffusion with continuous-time consistency distillation
Junsong Chen, Shuchen Xue, Yuyang Zhao, Jincheng Yu, Sayak Paul, Junyu Chen, Han Cai, Song Han, and Enze Xie. Sana-sprint: One-step diffusion with continuous-time consistency distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16185–16195, 2025
2025
-
[11]
Mean shift, mode seeking, and clustering.IEEE transactions on pattern analysis and machine intelligence, 17(8):790–799, 1995
Yizong Cheng. Mean shift, mode seeking, and clustering.IEEE transactions on pattern analysis and machine intelligence, 17(8):790–799, 1995
1995
-
[12]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. InThe Eleventh International Conference on Learning Representations
-
[13]
A kernel test of goodness of fit
Kacper Chwialkowski, Heiko Strathmann, and Arthur Gretton. A kernel test of goodness of fit. InInternational conference on machine learning, pages 2606–2615. PMLR, 2016
2016
-
[14]
Directly fine-tuning diffusion models on differentiable rewards
Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable rewards. InThe Twelfth International Conference on Learning Representations
-
[15]
Relative trajectory balance is equivalent to trust-pcl.arXiv preprint arXiv:2509.01632, 2025
Tristan Deleu, Padideh Nouri, Yoshua Bengio, and Doina Precup. Relative trajectory balance is equivalent to trust-pcl.arXiv preprint arXiv:2509.01632, 2025
-
[16]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[17]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
John Wiley & Sons, 1985
Luc Devroye and László Györfi.Nonparametric Density Estimation: The L1 View. John Wiley & Sons, 1985
1985
-
[19]
Diffusion-based reinforcement learning via q-weighted variational policy optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via q-weighted variational policy optimization. Advances in Neural Information Processing Systems, 37:53945–53968, 2024
2024
-
[20]
Consistency models as a rich and efficient policy class for reinforce- ment learning
Zihan Ding and Chi Jin. Consistency models as a rich and efficient policy class for reinforce- ment learning. InThe Twelfth International Conference on Learning Representations
-
[21]
Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky TQ Chen. Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. InThe Thirteenth International Conference on Learning Representations
-
[22]
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
2018
-
[23]
Reno: Enhancing one-step text-to-image models through reward-based noise optimization
Luca Eyring, Shyamgopal Karthik, Karsten Roth, Alexey Dosovitskiy, and Zeynep Akata. Reno: Enhancing one-step text-to-image models through reward-based noise optimization. Advances in Neural Information Processing Systems, 37:125487–125519, 2024
2024
-
[24]
Nsfw image detection model
Falcons.ai. Nsfw image detection model. https://huggingface.co/Falconsai/nsfw_ image_detection, 2024. Accessed: 2025-10-09
2024
-
[25]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
2023
-
[26]
One step diffusion via shortcut models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models. InThe Thirteenth International Conference on Learning Representations
-
[27]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[28]
Dreamsim: learning new dimensions of human visual similarity using synthetic data
Stephanie Fu, Netanel Y Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: learning new dimensions of human visual similarity using synthetic data. InProceedings of the 37th International Conference on Neural Information Processing Systems, pages 50742–50768, 2023
2023
-
[29]
Mean flows for one-step generative modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[30]
Improved Mean Flows: On the Challenges of Fastforward Generative Models
Zhengyang Geng, Yiyang Lu, Zongze Wu, Eli Shechtman, J Zico Kolter, and Kaiming He. Improved mean flows: On the challenges of fastforward generative models.arXiv preprint arXiv:2512.02012, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Consistency models made easy
Zhengyang Geng, Ashwini Pokle, Weijian Luo, Justin Lin, and J Zico Kolter. Consistency models made easy. InThe Thirteenth International Conference on Learning Representations
-
[32]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[33]
Dimensionality reduction by learning an invariant mapping
Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. In2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), volume 2, pages 1735–1742. IEEE, 2006
2006
-
[34]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 12
2020
-
[36]
Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
Peter Holderrieth, Douglas Chen, Luca Eyring, Ishin Shah, Giri Anantharaman, Yutong He, Zeynep Akata, Tommi Jaakkola, Nicholas Matthew Boffi, and Max Simchowitz. Diamond maps: Efficient reward alignment via stochastic flow maps.arXiv preprint arXiv:2602.05993, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Peter Holderrieth, Uriel Singer, Tommi Jaakkola, Ricky TQ Chen, Yaron Lipman, and Brian Karrer. Glass flows: Transition sampling for alignment of flow and diffusion models.arXiv preprint arXiv:2509.25170, 2025
-
[38]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[39]
Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog
Natasha Jaques, Asma Ghandeharioun, Judy Hanwen Shen, Craig Ferguson, Agata Lapedriza, Noah Jones, Shixiang Gu, and Rosalind Picard. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog.arXiv preprint arXiv:1907.00456, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[40]
Efficient diffusion policies for offline reinforcement learning.Advances in Neural Information Processing Systems, 36:67195–67212, 2023
Bingyi Kang, Xiao Ma, Chao Du, Tianyu Pang, and Shuicheng Yan. Efficient diffusion policies for offline reinforcement learning.Advances in Neural Information Processing Systems, 36:67195–67212, 2023
2023
-
[41]
Hyeongyu Kang, Jaewoo Lee, Woocheol Shin, Kiyoung Om, and Jinkyoo Park. Diffu- sion fine-tuning via reparameterized policy gradient of the soft q-function.arXiv preprint arXiv:2512.04559, 2025
-
[42]
Shyamgopal Karthik, Karsten Roth, Massimiliano Mancini, and Zeynep Akata. If at first you don’t succeed, try, try again: Faithful diffusion-based text-to-image generation by selection. arXiv preprint arXiv:2305.13308, 2023
-
[43]
Consistency trajectory models: Learning probability flow ode trajectory of diffusion
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion. InThe Twelfth International Conference on Learning Representations
-
[44]
Test-time alignment of diffusion models without reward over-optimization
Sunwoo Kim, Minkyu Kim, and Dongmin Park. Test-time alignment of diffusion models without reward over-optimization. InThe Thirteenth International Conference on Learning Representations
-
[45]
Auto-encoding variational bayes.stat, 1050:1, 2014
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.stat, 1050:1, 2014
2014
-
[46]
Rl with kl penalties is better viewed as bayesian inference
Tomasz Korbak, Ethan Perez, and Christopher Buckley. Rl with kl penalties is better viewed as bayesian inference. InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 1083–1091, 2022
2022
-
[47]
Offline reinforcement learning with implicit q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. InInternational Conference on Learning Representations
-
[48]
A Unified View of Score-Based and Drifting Models
Chieh-Hsin Lai, Bac Nguyen, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yuki Mitsufuji, Stefano Ermon, and Molei Tao. A unified view of drifting and score-based models.arXiv preprint arXiv:2603.07514, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Diffusion alignment as variational expectation-maximization.arXiv preprint arXiv:2510.00502, 2025
Jaewoo Lee, Minsu Kim, Sanghyeok Choi, Inhyuck Song, Sujin Yun, Hyeongyu Kang, Woocheol Shin, Taeyoung Yun, Kiyoung Om, and Jinkyoo Park. Diffusion alignment as variational expectation-maximization.arXiv preprint arXiv:2510.00502, 2025
-
[50]
Q-learning with Adjoint Matching
Qiyang Li and Sergey Levine. Q-learning with adjoint matching.arXiv preprint arXiv:2601.14234, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Decoupled q-chunking.arXiv preprint arXiv:2512.10926, 2025
Qiyang Li, Seohong Park, and Sergey Levine. Decoupled q-chunking.arXiv preprint arXiv:2512.10926, 2025
-
[52]
Aligning diffusion models by optimizing human utility.Advances in Neural Information Processing Systems, 37:24897–24925, 2024
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Yusuke Kato, and Kazuki Kozuka. Aligning diffusion models by optimizing human utility.Advances in Neural Information Processing Systems, 37:24897–24925, 2024. 13
2024
-
[53]
Derivative-free guidance in continuous and discrete diffusion models with soft value-based decoding
Xiner Li, Yulai Zhao, Chenyu Wang, Gabriele Scalia, Gökcen Eraslan, Surag Nair, Tommaso Biancalani, Shuiwang Ji, Aviv Regev, Sergey Levine, et al. Derivative-free guidance in continuous and discrete diffusion models with soft value-based decoding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[54]
Gradient estimators for implicit models
Yingzhen Li and Richard E Turner. Gradient estimators for implicit models. InInternational Conference on Learning Representations, 2018
2018
-
[55]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations
-
[56]
Flow-grpo: Training flow matching models via online rl
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di ZHANG, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[57]
Stein variational gradient descent as gradient flow.Advances in neural information processing systems, 30, 2017
Qiang Liu. Stein variational gradient descent as gradient flow.Advances in neural information processing systems, 30, 2017
2017
-
[58]
A kernelized stein discrepancy for goodness-of-fit tests
Qiang Liu, Jason Lee, and Michael Jordan. A kernelized stein discrepancy for goodness-of-fit tests. InInternational conference on machine learning, pages 276–284. PMLR, 2016
2016
-
[59]
Stein variational gradient descent: A general purpose bayesian inference algorithm.Advances in neural information processing systems, 29, 2016
Qiang Liu and Dilin Wang. Stein variational gradient descent: A general purpose bayesian inference algorithm.Advances in neural information processing systems, 29, 2016
2016
-
[60]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[61]
Value gradient guidance for flow matching alignment
Zhen Liu, Tim Z Xiao, Carles Domingo-Enrich, Weiyang Liu, and Dinghuai Zhang. Value gradient guidance for flow matching alignment. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[62]
Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning
Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. InInternational Conference on Machine Learning, pages 22825–22855. PMLR, 2023
2023
-
[63]
Simplifying, stabilizing and scaling continuous-time consistency models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models. InThe Thirteenth International Conference on Learning Representations
-
[64]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models.Advances in Neural Information Processing Systems, 36:76525–76546, 2023
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models.Advances in Neural Information Processing Systems, 36:76525–76546, 2023
2023
-
[66]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online reinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[67]
Springer Science & Business Media, 2013
Yurii Nesterov.Introductory lectures on convex optimization: A basic course, volume 87. Springer Science & Business Media, 2013
2013
-
[68]
Random gradient-free minimization of convex func- tions.F oundations of Computational Mathematics, 17(2):527–566, 2017
Yurii Nesterov and Vladimir Spokoiny. Random gradient-free minimization of convex func- tions.F oundations of Computational Mathematics, 17(2):527–566, 2017
2017
-
[69]
Control functionals for monte carlo integra- tion.Journal of the Royal Statistical Society Series B: Statistical Methodology, 79(3):695–718, 2017
Chris J Oates, Mark Girolami, and Nicolas Chopin. Control functionals for monte carlo integra- tion.Journal of the Royal Statistical Society Series B: Statistical Methodology, 79(3):695–718, 2017
2017
-
[70]
Owen Oertell, Jonathan D Chang, Yiyi Zhang, Kianté Brantley, and Wen Sun. Rl for consis- tency models: Faster reward guided text-to-image generation.arXiv preprint arXiv:2404.03673, 2024. 14
-
[71]
Ogbench: Bench- marking offline goal-conditioned rl
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Bench- marking offline goal-conditioned rl. InThe Thirteenth International Conference on Learning Representations
-
[72]
Is value learning really the main bottleneck in offline rl?Advances in Neural Information Processing Systems, 37:79029–79056, 2024
Seohong Park, Kevin Frans, Sergey Levine, and Aviral Kumar. Is value learning really the main bottleneck in offline rl?Advances in Neural Information Processing Systems, 37:79029–79056, 2024
2024
-
[73]
Flow q-learning
Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[74]
On estimation of a probability density function and mode.The annals of mathematical statistics, 33(3):1065–1076, 1962
Emanuel Parzen. On estimation of a probability density function and mode.The annals of mathematical statistics, 33(3):1065–1076, 1962
1962
-
[75]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regres- sion: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[76]
Aligning text-to-image diffusion models with reward backpropagation
Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, and Katerina Fragkiadaki. Aligning text-to-image diffusion models with reward backpropagation. 2023
2023
-
[77]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[78]
Variational inference with normalizing flows
Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. In International conference on machine learning, pages 1530–1538. PMLR, 2015
2015
-
[79]
Vargrad: a low-variance gradient estimator for variational inference.Advances in Neural Information Processing Systems, 33:13481–13492, 2020
Lorenz Richter, Ayman Boustati, Nikolas Nüsken, Francisco Ruiz, and Omer Deniz Akyildiz. Vargrad: a low-variance gradient estimator for variational inference.Advances in Neural Information Processing Systems, 33:13481–13492, 2020
2020
-
[80]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.