TrajAudit: Automated Failure Diagnosis for Agentic Coding Systems
Pith reviewed 2026-06-29 16:10 UTC · model grok-4.3
The pith
TrajAudit diagnoses failures in long noisy agentic coding trajectories by filtering irrelevant details and supplying test-report priors to an investigator agent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
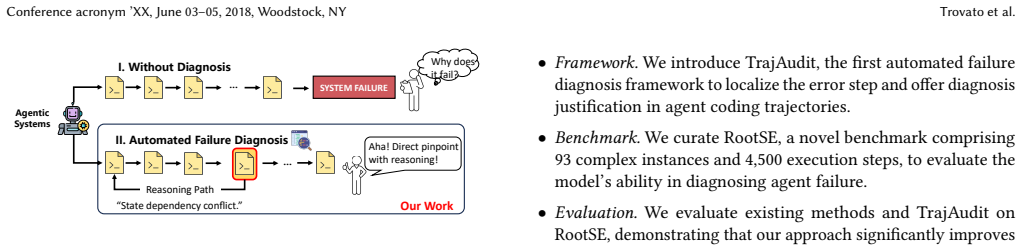
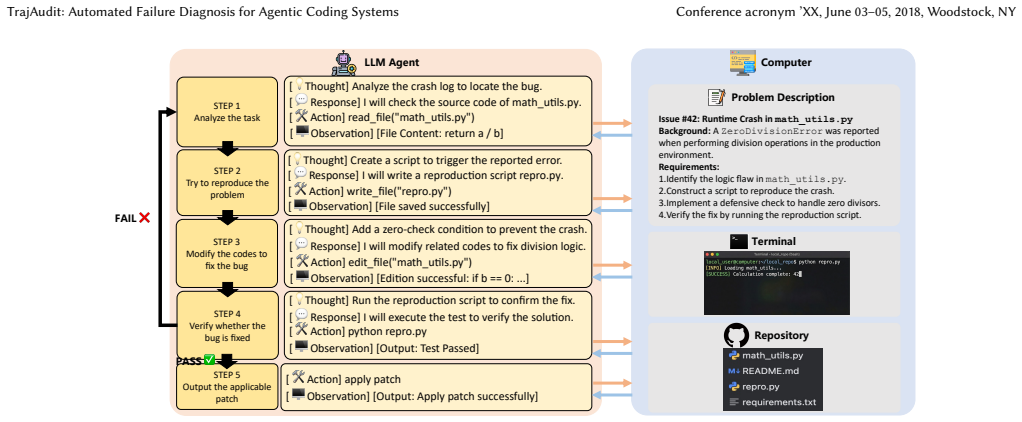
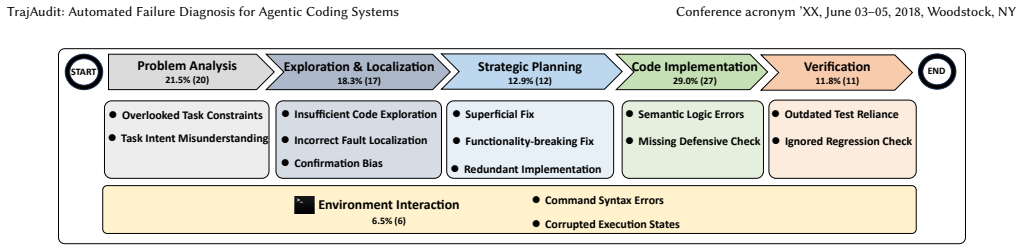
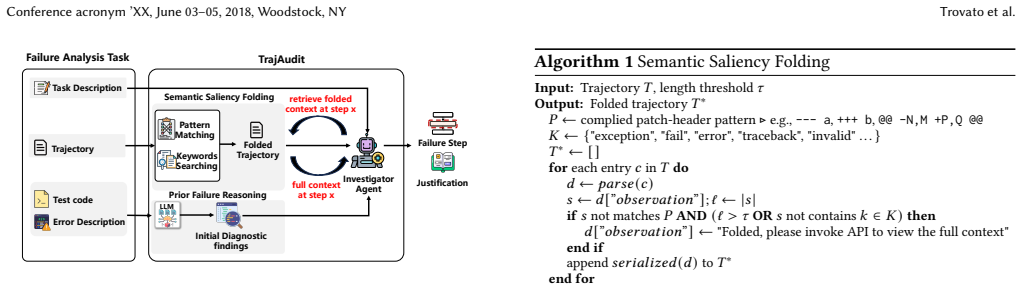
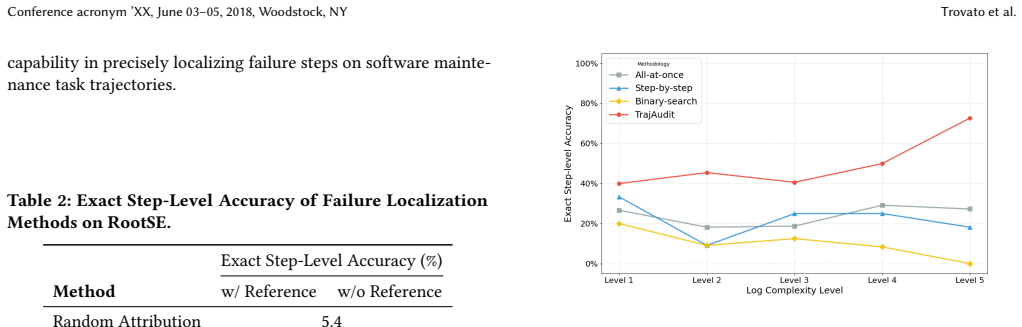
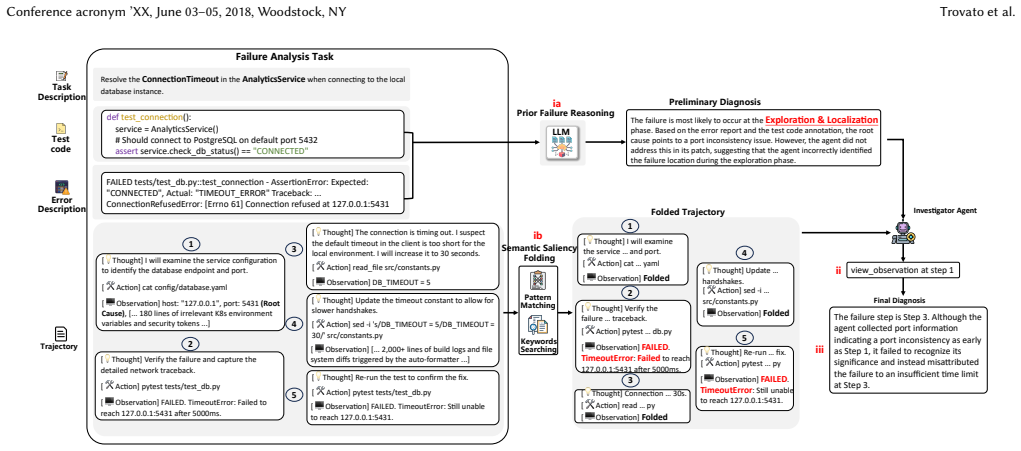
TrajAudit is the first failure diagnosis framework built specifically for repository-level agentic coding trajectories. It pairs an investigator agent with a noise-filter module that applies pattern matching and keyword detection, plus a preliminary-diagnosis module that extracts prior knowledge from test reports; the agent invokes tools to pull back filtered content when needed. This design directly targets the twin problems of excessive length and high noise that impair LLM reasoning on complex software-maintenance traces. Evaluation on RootSE, a collection of 93 authentic failure instances, shows the framework exceeds all baselines by over 24.4 percentage points in localization accuracy a
What carries the argument
Investigator agent backed by a noise-filter module (pattern matching plus keyword detection) and a preliminary-diagnosis module (extracted from test reports), enabling on-demand retrieval of retained content.
If this is right
- Automated diagnosis becomes feasible for the longest and noisiest agentic coding runs that current methods cannot handle.
- Lower token budgets allow repeated diagnosis cycles during iterative refinement of agentic systems.
- The RootSE benchmark supplies a concrete testbed for comparing future trajectory-diagnosis techniques.
- Failure localization accuracy above 24 points better than prior work translates directly into faster identification of root causes in real maintenance tasks.
Where Pith is reading between the lines
- The same filtering-plus-prior structure could be tested on non-coding agentic domains that also generate long execution logs.
- Integration into CI pipelines would let teams receive automated failure explanations immediately after each agent run.
- If the filter proves too aggressive on certain codebases, adding lightweight semantic embeddings to the matching step could be checked experimentally.
Load-bearing premise
Simple pattern matching and keyword detection together with a preliminary diagnosis from test reports will keep every essential piece of failure information while stripping enough noise for the investigator agent to succeed.
What would settle it
A fresh set of repository trajectories in which the decisive failure evidence sits inside code patterns the filter removes, producing no accuracy gain over baselines.
Figures


read the original abstract
Agentic systems have been widely studied to automate software engineering jobs such as bug fixing. As these systems increasingly tackle complex tasks, understanding where and why they fail becomes essential for iterative refinement and operational reliability. Existing automated failure diagnosis approaches leverage task execution trajectories, yet their effectiveness degrades substantially as trajectory length and complexity increase. For repository-level coding tasks specifically, trajectories are laden with noise, such as redundant program structure and verbose code context. Moreover, these trajectories are very long, while long-context reasoning remains a known weakness of LLMs. To address these two challenges, we propose TrajAudit, the first failure diagnosis framework for repository-level coding trajectories. TrajAudit employs an investigator agent supported by two modules: one filters failure-irrelevant information through pattern matching and keyword detection, and the other generates a preliminary diagnosis from test failure reports as prior knowledge, helping the agent handle noisy long contexts. The investigator agent can further invoke tools to retrieve filtered content on demand, ensuring that critical information is preserved while noise is minimized. We also introduce RootSE, a benchmark of 93 real-world agentic failure instances sourced from software maintenance tasks, representing the most complex trajectory diagnosis benchmark to date. Experiments on RootSE show that TrajAudit outperforms all existing baselines by over 24.4 percentage points in localization accuracy, while reducing token consumption by at least 18%, demonstrating its practical effectiveness. We hope this work draws community attention to failure management in agentic software engineering and provides a foundational resource for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TrajAudit, the first automated failure diagnosis framework for repository-level agentic coding trajectories. It consists of an investigator agent augmented by two modules—one that filters failure-irrelevant information via pattern matching and keyword detection, and another that generates a preliminary diagnosis from test failure reports as prior knowledge—while allowing on-demand retrieval of filtered content. The work also presents RootSE, a benchmark of 93 real-world failure instances from software maintenance tasks, and reports that TrajAudit outperforms existing baselines by more than 24.4 percentage points in localization accuracy while reducing token consumption by at least 18%.
Significance. If the central empirical claims hold after verification of the filtering step, the contribution would be significant: it directly targets the degradation of diagnosis methods on long, noisy repository trajectories, introduces the most complex such benchmark to date, and demonstrates concrete gains in both accuracy and efficiency. The emphasis on practical failure management in agentic SE systems could stimulate follow-on work on trajectory auditing and iterative agent refinement.
major comments (1)
- [Abstract] Abstract: The reported 24.4 pp localization gain and 18% token reduction on RootSE are measured after the pattern-matching/keyword filter and test-report prior have already removed content from the trajectories. For these margins to be attributable to the investigator agent rather than to an easier problem, the manuscript must demonstrate that the retained fragments always include every decisive root-cause signal across the 93 instances. No such validation (e.g., manual audit of discarded segments, coverage analysis of failure-critical statements, or ablation removing the filter) is described, leaving open the possibility that the preprocessing itself accounts for part or all of the observed improvement.
minor comments (1)
- [Abstract] Abstract: The claim that RootSE is 'the most complex trajectory diagnosis benchmark to date' would be strengthened by explicit quantitative comparisons (trajectory length, number of files touched, number of LLM calls) against prior benchmarks.
Simulated Author's Rebuttal
We thank the referee for this constructive comment on validating the filtering step. We address the concern directly below and commit to revisions that strengthen the attribution of results to the investigator agent.
read point-by-point responses
-
Referee: The reported 24.4 pp localization gain and 18% token reduction on RootSE are measured after the pattern-matching/keyword filter and test-report prior have already removed content from the trajectories. For these margins to be attributable to the investigator agent rather than to an easier problem, the manuscript must demonstrate that the retained fragments always include every decisive root-cause signal across the 93 instances. No such validation (e.g., manual audit of discarded segments, coverage analysis of failure-critical statements, or ablation removing the filter) is described, leaving open the possibility that the preprocessing itself accounts for part or all of the observed improvement.
Authors: We agree that the current manuscript lacks an explicit validation (such as a manual audit of discarded segments or an ablation removing the filter) to confirm that no decisive root-cause signals are lost. The filter is designed via pattern matching and keyword detection to target only failure-irrelevant noise (e.g., redundant program structure), with the investigator agent retaining on-demand tool-based retrieval of any filtered content. Nevertheless, this design choice alone does not substitute for empirical verification across all 93 RootSE instances. We will add (1) a manual audit of discarded segments on a representative sample of instances and (2) an ablation study that disables the filter (while retaining the test-report prior and investigator agent) to quantify its isolated contribution. These results will be reported in the revised manuscript to directly address the attribution question. revision: yes
Circularity Check
No circularity: empirical system evaluation with no derivations or self-referential fits
full rationale
The paper describes a filtering-plus-prior system (pattern matching, keyword detection, test-report prior) and reports measured performance gains on the newly introduced RootSE benchmark. No equations, fitted parameters, or load-bearing self-citations appear in the provided text. Localization accuracy and token reduction are presented as direct experimental outcomes rather than quantities derived from the method's own inputs by construction. The filtering step is an engineering choice whose sufficiency is tested empirically, not presupposed in a definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rui Abreu, Peter Zoeteweij, and Arjan JC Van Gemund. 2007. On the accuracy of spectrum-based fault localization. InTesting: Academic and industrial conference practice and research techniques-MUTATION (TAICPART-MUTATION 2007). IEEE, 89–98
2007
-
[2]
Elena Akik, Marko Vještica, Vladimir Dimitrieski, Slavica Kordić, and Sonja Ristić. 2025. Architecture of Multi-agent System for Automatic Code Template Maintenance. InEuropean Conference on Advances in Databases and Information Systems. Springer, 296–310
2025
-
[3]
Stefano V Albrecht and Peter Stone. 2018. Autonomous agents modelling other agents: A comprehensive survey and open problems.Artificial Intelligence258 (2018), 66–95
2018
-
[4]
Anonymous. 2026.Reference. doi:10.5281/zenodo.19230090
-
[5]
Amine Barrak. 2025. Traceability and Accountability in Role-Specialized Multi- Agent LLM Pipelines. In2025 40th IEEE/ACM International Conference on Auto- mated Software Engineering Workshops (ASEW). IEEE, 315–322
2025
-
[6]
Islem Bouzenia and Michael Pradel. 2025. Understanding Software Engineering Agents: A Study of Thought-Action-Result Trajectories. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2846– 2857
2025
-
[7]
Subhajit Chaudhury, Payel Das, Sarathkrishna Swaminathan, Georgios Kollias, Elliot Nelson, Khushbu Pahwa, Tejaswini Pedapati, Igor Melnyk, and Matthew Riemer. 2025. EpMAN: Episodic Memory AttentioN for Generalizing to Longer Contexts. InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers). 11696–11708
2025
-
[8]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales.Educational and psychological measurement20, 1 (1960), 37–46
1960
-
[9]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. 2025. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
- [11]
-
[12]
Min Du, Feifei Li, Guineng Zheng, and Vivek Srikumar. 2017. Deeplog: Anomaly detection and diagnosis from system logs through deep learning. InProceedings of the 2017 ACM SIGSAC conference on computer and communications security. 1285–1298
2017
-
[13]
Will Epperson, Gagan Bansal, Victor C Dibia, Adam Fourney, Jack Gerrits, Erkang Zhu, and Saleema Amershi. 2025. Interactive debugging and steering of multi- agent ai systems. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–15
2025
-
[14]
Stan Franklin and Art Graesser. 1996. Is it an Agent, or just a Program?: A Taxonomy for Autonomous Agents. InInternational workshop on agent theories, architectures, and languages. Springer, 21–35
1996
- [15]
-
[16]
Haixuan Guo, Shuhan Yuan, and Xintao Wu. 2021. Logbert: Log anomaly detec- tion via bert. In2021 international joint conference on neural networks (IJCNN). IEEE, 1–8
2021
-
[17]
Shanshan Han, Qifan Zhang, Weizhao Jin, and Zhaozhuo Xu. 2024. LLM multi- agent systems: Challenges and open problems.arXiv preprint arXiv:2402.03578 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Shilin He, Jieming Zhu, Pinjia He, and Michael R Lyu. 2016. Experience re- port: System log analysis for anomaly detection. In2016 IEEE 27th international symposium on software reliability engineering (ISSRE). IEEE, 207–218
2016
-
[19]
Samuel Holt, Max Ruiz Luyten, and Mihaela van der Schaar. [n. d.]. L2MAC: Large Language Model Automatic Computer for Extensive Code Generation. In The Twelfth International Conference on Learning Representations
-
[20]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al
-
[21]
InThe twelfth international conference on learning representations
MetaGPT: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations
-
[22]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[23]
Li Hu, Guoqiang Chen, Xiuwei Shang, Shaoyin Cheng, Benlong Wu, LiGangyang LiGangyang, Xu Zhu, Weiming Zhang, and Nenghai Yu. 2025. CompileAgent: Automated real-world repo-level compilation with tool-integrated LLM-based agent system. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2078–2091
2025
-
[24]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
James A Jones and Mary Jean Harrold. 2005. Empirical evaluation of the taran- tula automatic fault-localization technique. InProceedings of the 20th IEEE/ACM international Conference on Automated software engineering. 273–282
2005
-
[26]
Satyadhar Joshi. 2025. LLMOps, AgentOps, and MLOps for Generative AI: A Comprehensive Review. (2025)
2025
-
[27]
Max Landauer, Sebastian Onder, Florian Skopik, and Markus Wurzenberger. 2023. Deep learning for anomaly detection in log data: A survey.Machine Learning with Applications12 (2023), 100470
2023
-
[28]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.biometrics(1977), 159–174
1977
-
[29]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems36 (2023), 51991–52008
2023
-
[30]
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. 2024. Large language model-based agents for software en- gineering: A survey.ACM Transactions on Software Engineering and Methodology (2024)
2024
-
[31]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics12 (2024), 157–173
2024
-
[32]
Tianyang Liu, Canwen Xu, and Julian McAuley. [n. d.]. RepoBench: Benchmark- ing Repository-Level Code Auto-Completion Systems. InThe Twelfth Interna- tional Conference on Learning Representations
-
[33]
Ruofan Lu, Yichen Li, and Yintong Huo. 2025. Exploring Autonomous Agents: A Closer Look at Why They Fail When Completing Tasks. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 3856– 3860
2025
-
[34]
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. 2025. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. Gaia: a benchmark for general ai assistants. InThe Twelfth Inter- national Conference on Learning Representations
2023
-
[36]
Niels Mündler, Mark N Müller, Jingxuan He, and Martin Vechev. 2024. Swt-bench: Testing and validating real-world bug-fixes with code agents.Advances in Neural Information Processing Systems37 (2024), 81857–81887
2024
-
[37]
Eugene W Myers. 1986. An O (ND) difference algorithm and its variations. Algorithmica1, 1 (1986), 251–266
1986
-
[38]
2023.OpenAI API
OpenAI. 2023.OpenAI API. https://openai.com/blog/openai-api [Online; accessed 1 Aug 2023]
2023
-
[39]
Shuyin Ouyang, Jie M Zhang, Mark Harman, and Meng Wang. 2025. An empirical study of the non-determinism of chatgpt in code generation.ACM Transactions on Software Engineering and Methodology34, 2 (2025), 1–28
2025
-
[40]
Melissa Z Pan, Mert Cemri, Lakshya A Agrawal, Shuyi Yang, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Kannan Ramchandran, Dan Klein, et al. 2025. Why do multiagent systems fail?. InICLR 2025 Workshop on Building Trust in Language Models and Applications. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al
2025
-
[41]
Chris Parnin and Alessandro Orso. 2011. Are automated debugging techniques actually helping programmers?. InProceedings of the 2011 international symposium on software testing and analysis. 199–209
2011
-
[42]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. 2024. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers). 15174–15186
2024
-
[43]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. 2023. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems36 (2023), 68539–68551
2023
-
[45]
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. InInternational Conference on Machine Learning. PMLR, 31210–31227
2023
-
[46]
Yuan Tian and Tianyi Zhang. 2025. Selective Prompt Anchoring for Code Gener- ation. InInternational Conference on Machine Learning. PMLR, 59528–59551
2025
-
[47]
Maria Trofimova, Anton Shevtsov, Badertdinov Ibragim, Konstantin Pyaev, Simon Karasik, and Alexander Golubev. 2025. OpenHands Trajectories with Qwen3- Coder-480B-A35B-Instruct.Nebius blog(2025)
2025
-
[48]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Yanlin Wang, Wanjun Zhong, Yanxian Huang, Ensheng Shi, Min Yang, Jiachi Chen, Hui Li, Yuchi Ma, Qianxiang Wang, and Zibin Zheng. 2025. Agents in soft- ware engineering: Survey, landscape, and vision.Automated Software Engineering 32, 2 (2025), 70
2025
-
[50]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[51]
Mark Weiser. 1984. Program slicing.IEEE Transactions on software engineering4 (1984), 352–357
1984
-
[52]
W Eric Wong, Ruizhi Gao, Yihao Li, Rui Abreu, and Franz Wotawa. 2016. A survey on software fault localization.IEEE Transactions on Software Engineering 42, 8 (2016), 707–740
2016
-
[53]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. 2024. Autogen: Enabling next-gen LLM applications via multi-agent conversations. InFirst conference on language modeling
2024
-
[54]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1482–1494
2023
-
[55]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[56]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
- [57]
-
[58]
Shaokun Zhang, Ming Yin, Jieyu Zhang, Jiale Liu, Zhiguang Han, Jingyang Zhang, Beibin Li, Chi Wang, Huazheng Wang, Yiran Chen, and Qingyun Wu. 2025. Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id=GazlTYxZss
2025
-
[59]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- tocoderover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592–1604
2024
-
[60]
Yang Zhou, Hongyi Liu, Zhuoming Chen, Yuandong Tian, and Beidi Chen. 2025. GSM: How Do your LLMs Behave over Infinitely Increasing Reasoning Complex- ity and Context Length?. InForty-second International Conference on Machine Learning. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.