O-MARC: Omni Memory-Augmented Compression Distillation for Efficient Video Understanding
Pith reviewed 2026-06-29 18:33 UTC · model grok-4.3
The pith
Memory-augmented compression distillation lets compact omnimodal models outperform full token inference on audio-visual video understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
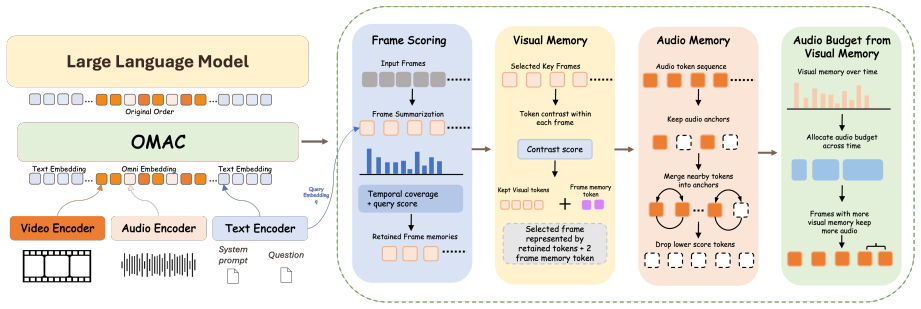
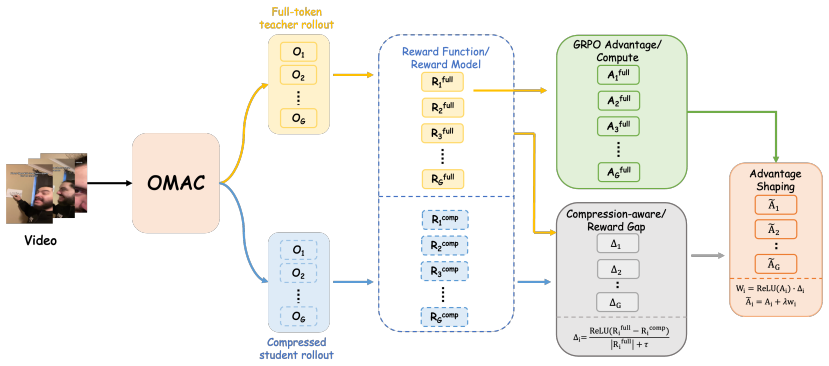
The O-MARC compression distillation framework trains models to learn from memory-compressed multimodal contexts, enabling higher average performance on audio-visual video QA tasks than full token inference while maintaining efficiency through the OMAC method that keeps salient visual memory and temporally grounded audio anchors.
What carries the argument
O-MARC, the compression distillation framework that adapts compact models to inputs compressed by OMAC while preserving salient visual memory and temporally grounded audio anchors.
If this is right
- Higher average scores than full token inference on benchmarks requiring audio-visual association.
- Inference latency reduced by 34.6 percent and memory use reduced by 34.7 percent.
- Plug-in compatibility with existing omnimodal models such as Qwen2.5-Omni-3B.
- Effective compression for noisy user-generated videos without needing task-specific retraining from scratch.
Where Pith is reading between the lines
- Compression may help models by removing distracting tokens rather than simply discarding information.
- The same distillation approach could be applied to other long-context multimodal tasks such as extended audio narration or multi-image reasoning.
- UGC-AVQA offers a reusable testbed for measuring whether any compression technique retains cross-modal dependencies.
Load-bearing premise
The audio removal test in UGC-AVQA guarantees that every question truly requires joint audio-visual evidence and that the compression method preserves exactly the information needed for those questions.
What would settle it
Running O-MARC on the audio-removed versions of all UGC-AVQA videos and observing whether accuracy remains above the level expected from visual-only inference would test whether the benchmark and compression truly isolate and retain joint evidence.
Figures

read the original abstract
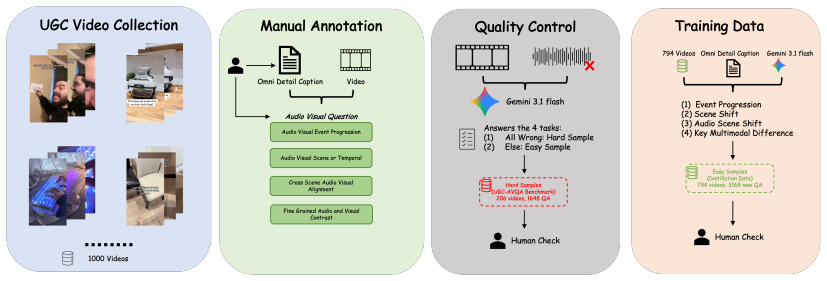
Omnimodal large language models enable unified audio video understanding, but long joint token sequences make inference costly, and existing benchmarks do not fully isolate audio visual association in noisy user generated videos. We introduce UGC-AVQA, a public UGC benchmark with 1,000 videos and 4,816 QA pairs, where an audio removal test ensures that benchmark questions require both acoustic and visual evidence. To reduce inference cost, we propose OMAC, a training free plug in compression method that preserves salient visual memory and temporally grounded audio anchors. To further make compact models robust to compressed inputs, we introduce O-MARC, a compression distillation framework for learning with memory compressed multimodal contexts. On Qwen2.5-Omni-3B, O-MARC improves the average score across four benchmarks to 45.8, outperforming full token inference at 44.1 and OmniZip at 41.0. OMAC also keeps inference efficient, reducing latency by 34.6\% (1.53$\times$ speedup) and memory by 34.7\% compared with full token inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UGC-AVQA, a benchmark of 1,000 UGC videos and 4,816 QA pairs where an audio-removal test is claimed to ensure questions require joint audio-visual evidence. It proposes OMAC, a training-free compression method that preserves salient visual memory and temporally grounded audio anchors, and O-MARC, a distillation framework to train models on compressed multimodal contexts. On Qwen2.5-Omni-3B, O-MARC reports an average score of 45.8 across four benchmarks (vs. 44.1 for full-token inference and 41.0 for OmniZip), with 34.6% latency reduction and 34.7% memory reduction.
Significance. If the central empirical claims hold, the work would be significant for practical deployment of omnimodal LLMs on long video inputs by reducing inference cost while maintaining or improving accuracy. The public UGC-AVQA benchmark with its modality-isolation test addresses a documented gap in existing AVQA datasets. Credit is due for releasing the benchmark and for the plug-in nature of OMAC, which requires no retraining of the base model.
major comments (2)
- [Abstract] Abstract: the claim that 'an audio removal test ensures that benchmark questions require both acoustic and visual evidence' for all 4,816 pairs is load-bearing for the headline result (45.8 vs. 44.1), yet the manuscript provides no description of the test procedure, per-question verification, performance-drop threshold, or handling of noisy UGC edge cases. Without these details it is impossible to confirm that reported gains arise from faithful joint-evidence compression rather than other factors.
- [Results] Results section (and abstract): the reported average scores of 45.8 / 44.1 / 41.0 are presented without error bars, dataset splits, number of runs, or ablation tables isolating the contribution of the audio anchors versus visual memory. This directly affects assessment of whether the 1.7-point gain is robust.
minor comments (1)
- [Abstract] The abstract refers to 'four benchmarks' without naming them or providing per-benchmark breakdowns; this should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where additional transparency is needed. We agree that the current manuscript lacks sufficient detail on the audio removal test and experimental reporting, and we will revise accordingly to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'an audio removal test ensures that benchmark questions require both acoustic and visual evidence' for all 4,816 pairs is load-bearing for the headline result (45.8 vs. 44.1), yet the manuscript provides no description of the test procedure, per-question verification, performance-drop threshold, or handling of noisy UGC edge cases. Without these details it is impossible to confirm that reported gains arise from faithful joint-evidence compression rather than other factors.
Authors: We agree that the manuscript does not provide adequate details on the audio removal test procedure. In the revised version, we will expand the UGC-AVQA section with a full description of the test, including the audio removal method, performance-drop threshold for question selection, per-question verification process, and handling of noisy UGC edge cases. This will allow readers to verify that the benchmark isolates joint audio-visual evidence. revision: yes
-
Referee: [Results] Results section (and abstract): the reported average scores of 45.8 / 44.1 / 41.0 are presented without error bars, dataset splits, number of runs, or ablation tables isolating the contribution of the audio anchors versus visual memory. This directly affects assessment of whether the 1.7-point gain is robust.
Authors: We acknowledge that the results lack error bars, explicit dataset splits, run counts, and ablations separating audio anchors from visual memory. In the revision, we will add these elements: report standard deviations from multiple runs, clarify splits, state the number of runs performed, and include ablation tables isolating the contributions of each component. These changes will better demonstrate the robustness of the 1.7-point improvement. revision: yes
Circularity Check
No circularity: empirical benchmark claims with no derivation chain
full rationale
The paper introduces UGC-AVQA benchmark and OMAC/O-MARC methods, reporting empirical scores (45.8 vs 44.1) on Qwen2.5-Omni-3B. No equations, fitted parameters, or self-citation chains appear in the abstract or described claims. Performance rests on external benchmark measurements rather than any input-to-prediction reduction by construction. The audio-removal test is an empirical validation step, not a definitional or fitted element that forces the result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. 2022. Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. 2024. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In European Conference on Computer Vision, pages 19--35. Springer
2024
-
[4]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and 1 others. 2024. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Junbo Cui, Bokai Xu, Chongyi Wang, Tianyu Yu, Weiyue Sun, Yingjing Xu, Tianran Wang, Zhihui He, Wenshuo Ma, Tianchi Cai, and 1 others. 2026. Minicpm-o 4.5: Towards real-time full-duplex omni-modal interaction. arXiv preprint arXiv:2604.27393
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, Junfei Wu, Bozhou Li, Bohan Zeng, Yang Shi, Yushuo Guan, and 1 others. 2026. Omnisift: Modality-asymmetric token compression for efficient omni-modal large language models. arXiv preprint arXiv:2602.04804
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. 2026. Video-r1: Reinforcing video reasoning in mllms. Advances in Neural Information Processing Systems, 38:99114--99137
2026
-
[9]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, and 1 others. 2025. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108--24118
2025
- [10]
- [11]
-
[12]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. 2025. Worldsense: Evaluating real-world omnimodal understanding for multimodal llms. arXiv preprint arXiv:2502.04326
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and 1 others. 2024 a . Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
- [17]
-
[18]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. Advances in neural information processing systems, 36:34892--34916
2023
-
[19]
Kai Liu, Jungang Li, Yuchong Sun, Shengqiong Wu, Daoan Zhang, Wei Zhang, Sheng Jin, Sicheng Yu, Geng Zhan, Jiayi Ji, and 1 others. 2026. Javisgpt: A unified multi-modal llm for sounding-video comprehension and generation. Advances in Neural Information Processing Systems, 38:142289--142324
2026
-
[20]
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. 2024. Tempcompass: Do video llms really understand videos? In Findings of the Association for Computational Linguistics: ACL 2024, pages 8731--8772
2024
-
[21]
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. 2025. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857--22867
2025
- [22]
- [23]
-
[24]
Leqi Shen, Guoqiang Gong, Tao He, Yifeng Zhang, Pengzhang Liu, Sicheng Zhao, and 1 others. 2026. Fastvid: Dynamic density pruning for fast video large language models. Advances in Neural Information Processing Systems, 38:123553--123581
2026
-
[25]
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, and 1 others. 2024. Moviechat: From dense token to sparse memory for long video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221--18232
2024
-
[26]
Keda Tao, Kele Shao, Bohan Yu, Weiqiang Wang, Huan Wang, and 1 others. 2025. Omnizip: Audio-guided dynamic token compression for fast omnimodal large language models. arXiv preprint arXiv:2511.14582
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, and 1 others. 2024. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. 2024. Longvideobench: A benchmark for long-context interleaved video-language understanding. Advances in Neural Information Processing Systems, 37:28828--28857
2024
-
[29]
Peiran Wu, Yunze Liu, Miao Liu, and Junxiao Shen. 2026. St-think: How multimodal large language models reason about 4d worlds from ego-centric videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5174--5183
2026
- [30]
-
[31]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, and 1 others. 2025. Qwen3-omni technical report. arXiv preprint arXiv:2509.17765
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [32]
-
[33]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[34]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.