MedVol-R1: Reward-Driven Evidence Grounding for Volumetric Reasoning Segmentation
Pith reviewed 2026-06-29 18:23 UTC · model grok-4.3
The pith
MedVol-R1 grounds clinical queries to explicit 2D evidence anchors before propagating them into 3D masks via a frozen model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
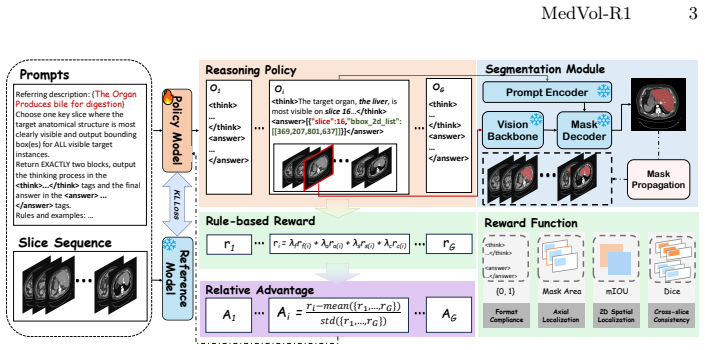
MedVol-R1 decouples evidence grounding from volumetric delineation by having the LVLM produce a verifiable 2D evidence anchor consisting of a key axial slice and 2D bounding boxes, which a frozen MedSAM2 then propagates into a coherent 3D mask; the system is trained first with cold-start supervised fine-tuning and then with GRPO using a multi-component reward that rewards informative evidence selection, accurate 2D grounding, and cross-slice coherence, yielding state-of-the-art results on CT-ORG, AbdomenCT-1K, and KiTS23 without requiring chain-of-thought annotations.
What carries the argument
The verifiable 2D evidence anchor (key axial slice plus 2D bounding boxes) selected by the LVLM and propagated by the frozen MedSAM2 module, trained via GRPO with a multi-component reward.
If this is right
- Explicit 2D evidence selection makes the clinical reasoning steps directly inspectable rather than hidden in latent tokens.
- The multi-component reward improves both 2D grounding accuracy and 3D volumetric consistency over supervised fine-tuning alone.
- Avoiding specialized segmentation tokens allows the language model to handle a wider range of free-form clinical queries.
- The frozen MedSAM2 propagation step keeps the 3D delineation module unchanged while still delivering benchmark gains.
Where Pith is reading between the lines
- The separation of grounding from delineation could make it straightforward to swap in newer 3D segmentation backbones without retraining the language model.
- The reward structure focused on evidence quality might transfer to other tasks that require traceable reasoning before a final output, such as report generation from volumes.
- Because the 2D anchors are human-verifiable, the method may reduce the need for full 3D annotations during future data collection.
Load-bearing premise
A 2D evidence anchor chosen by the LVLM can be reliably turned into a coherent 3D mask by the frozen MedSAM2 without extra adaptation or accumulating errors across slices.
What would settle it
Observe whether 3D masks generated from accurate 2D anchors show visible slice-to-slice discontinuities or lower overlap with ground truth than the 2D predictions alone would predict.
Figures

read the original abstract
Volumetric Reasoning Segmentation (VRS) aims to segment a target region in a 3D medical scan from a free-form clinical query, where the referent is often implicit and requires both medical knowledge and volume-grounded reasoning. Existing methods typically rely on specialized segmentation tokens to connect language with mask decoding, but this coupling collapses the decision process into opaque latent representations, limiting interpretability and generalization to diverse narrative expressions. In this paper, we present MedVol-R1, a reinforcement learning-based framework for VRS that explicitly decouples evidence grounding from volumetric delineation: the LVLM grounds clinical reasoning to a verifiable 2D evidence anchor (key axial slice and 2D bounding boxes), which is then propagated into a coherent 3D mask by a frozen MedSAM2 module. We train MedVol-R1 with cold-start supervised fine-tuning followed by GRPO, guided by a multi-component reward that encourages informative evidence selection, accurate 2D spatial grounding, and cross-slice volumetric coherence, without requiring costly chain-of-thought annotations. Experiments on CT-ORG, AbdomenCT-1K, and KiTS23 from the M3D-Seg benchmark demonstrate that MedVol-R1 consistently outperforms strong baselines and achieves state-of-the-art performance, with reinforcement learning providing clear gains over pure supervised fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedVol-R1, a reinforcement-learning framework for volumetric reasoning segmentation (VRS) from free-form clinical queries. It decouples LVLM-based evidence grounding (selection of a key axial slice plus 2D bounding boxes) from 3D mask generation, which is performed by a frozen MedSAM2 module. Training proceeds via cold-start supervised fine-tuning followed by GRPO, using a multi-component reward that encourages informative evidence, accurate 2D grounding, and cross-slice volumetric coherence. Experiments on CT-ORG, AbdomenCT-1K, and KiTS23 from the M3D-Seg benchmark are reported to show consistent outperformance of strong baselines and state-of-the-art results, with additional gains from the RL stage over pure SFT.
Significance. If the reported gains hold under rigorous verification, the explicit 2D evidence anchor provides a verifiable and interpretable intermediate representation that could improve generalization to diverse clinical narratives compared with latent segmentation-token approaches. The GRPO formulation that avoids costly chain-of-thought annotations is a methodological strength worth highlighting.
major comments (3)
- [§3] §3 (Method), paragraph on MedSAM2 propagation: the central claim that a frozen MedSAM2 reliably converts LVLM-selected 2D anchors into coherent 3D masks rests on an untested premise; because no gradients flow to MedSAM2, any slice-to-slice drift or boundary inconsistency cannot be corrected by the volumetric-coherence term in the GRPO reward. No quantitative analysis of propagation error (e.g., Dice drop across slices or constraint-violation rate) is supplied.
- [§4.3] §4.3 (Ablation studies): the reported RL gains over SFT are load-bearing for the contribution of GRPO, yet the ablation table does not isolate the effect of the volumetric-coherence reward component versus the 2D-grounding term; without this decomposition it is impossible to confirm that the coherence term actually mitigates the frozen-module limitation.
- [Table 2] Table 2 (main results): the SOTA margins on KiTS23 are presented without per-fold standard deviations or statistical significance tests; given that the method introduces additional hyperparameters in the reward weighting, the absence of these statistics weakens the claim that the improvement is robust rather than dataset-specific.
minor comments (3)
- [Eq. (7)] The notation for the GRPO objective (Eq. 7) re-uses the symbol r for both the scalar reward and the reward vector; a distinct symbol would improve readability.
- [Figure 3] Figure 3 caption does not specify the exact clinical query text used for the visualized examples, making it difficult to reproduce the evidence-grounding behavior.
- [§4.1] The M3D-Seg benchmark citation is given only by name; the exact train/validation/test splits and preprocessing steps should be stated explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of our method's reliance on the frozen MedSAM2 module, the need for finer-grained reward ablations, and statistical reporting. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method), paragraph on MedSAM2 propagation: the central claim that a frozen MedSAM2 reliably converts LVLM-selected 2D anchors into coherent 3D masks rests on an untested premise; because no gradients flow to MedSAM2, any slice-to-slice drift or boundary inconsistency cannot be corrected by the volumetric-coherence term in the GRPO reward. No quantitative analysis of propagation error (e.g., Dice drop across slices or constraint-violation rate) is supplied.
Authors: We acknowledge that the manuscript does not provide direct quantitative metrics on MedSAM2 propagation errors such as per-slice Dice degradation or boundary inconsistency rates. The volumetric-coherence reward term is designed to incentivize LVLM evidence selection that yields coherent outputs from the frozen module, but this does not retroactively correct propagation issues. In the revised manuscript we will add a dedicated analysis subsection reporting average inter-slice Dice scores, maximum boundary drift, and constraint-violation rates on the M3D-Seg validation sets to empirically support the reliability of the propagation step. revision: yes
-
Referee: [§4.3] §4.3 (Ablation studies): the reported RL gains over SFT are load-bearing for the contribution of GRPO, yet the ablation table does not isolate the effect of the volumetric-coherence reward component versus the 2D-grounding term; without this decomposition it is impossible to confirm that the coherence term actually mitigates the frozen-module limitation.
Authors: We agree that the current ablation table does not fully decompose the individual reward components. To isolate the volumetric-coherence term's contribution, we will expand §4.3 with additional controlled ablations that disable the coherence reward while retaining the evidence and 2D-grounding terms (and vice versa), reporting the resulting performance deltas on all three M3D-Seg datasets. This will allow direct assessment of whether the coherence component mitigates propagation limitations. revision: yes
-
Referee: [Table 2] Table 2 (main results): the SOTA margins on KiTS23 are presented without per-fold standard deviations or statistical significance tests; given that the method introduces additional hyperparameters in the reward weighting, the absence of these statistics weakens the claim that the improvement is robust rather than dataset-specific.
Authors: The M3D-Seg benchmark provides fixed train/validation/test splits, and our primary results follow that protocol. However, to address concerns about robustness given the reward hyperparameters, we will augment Table 2 with per-fold standard deviations computed over three independent GRPO training runs with different random seeds and include paired statistical significance tests (Wilcoxon signed-rank) against the strongest baseline. These additions will be reported for KiTS23 and the other datasets where feasible. revision: yes
Circularity Check
No circularity; empirical SOTA claims rest on external benchmarks
full rationale
The paper describes a two-stage training process (cold-start SFT then GRPO) whose outputs are evaluated via standard segmentation metrics on held-out public datasets (CT-ORG, AbdomenCT-1K, KiTS23). No equation, reward term, or performance claim is shown to reduce by construction to a fitted parameter or to a self-citation. The frozen MedSAM2 module is an external component whose behavior is not derived inside the paper; any coherence it provides is an empirical premise, not a definitional identity. Self-citations, if present, are not load-bearing for the central empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2404.00578 (2024)
Bai, F., Du, Y., Huang, T., Meng, M.Q.H., Zhao, B.: M3d: Advancing 3d medical image analysis with multi-modal large language models. arXiv preprint arXiv:2404.00578 (2024)
- [2]
-
[3]
Advances in Neural Information Processing Systems 37, 110746–110783 (2024)
Du, Y., Bai, F., Huang, T., Zhao, B.: Segvol: Universal and interactive volumetric medical image segmentation. Advances in Neural Information Processing Systems 37, 110746–110783 (2024)
2024
-
[4]
arXiv preprint arXiv:2508.11538 (2025) 5, 10, 13
Gong, S., Zhang, L., Zhuge, Y., Jia, X., Zhang, P., Lu, H.: Reinforcing video rea- soning segmentation to think before it segments. arXiv preprint arXiv:2508.11538 (2025)
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Han, S., Huang, W., Shi, H., Zhuo, L., Su, X., Zhang, S., Zhou, X., Qi, X., Liao, Y., Liu, S.: Videoespresso: A large-scale chain-of-thought dataset for fine-grained video reasoning via core frame selection. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26181–26191 (2025)
2025
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: Lisa: Reasoning seg- mentation via large language model. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9579–9589 (2024)
2024
-
[8]
American Journal of Neuroradiology42(10), 1755– 1761 (2021) 10 Z
Liu, F., Zhou, P., Baccei, S.J., Masciocchi, M.J., Amornsiripanitch, N., Kiefe, C.I., Rosen, M.P.: Qualifying certainty in radiology reports through deep learning–based natural language processing. American Journal of Neuroradiology42(10), 1755– 1761 (2021) 10 Z. Wang et al
2021
-
[9]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Liu, Y., Peng, B., Zhong, Z., Yue, Z., Lu, F., Yu, B., Jia, J.: Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement. arXiv preprint arXiv:2503.06520 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Liu, Z., Sun, Z., Zang, Y., Dong, X., Cao, Y., Duan, H., Lin, D., Wang, J.: Visual- rft: Visual reinforcement fine-tuning. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 2034–2044 (2025)
2034
-
[11]
Nature Communications15, 654 (2024)
Ma, J., He, Y., Li, F., Han, L., You, C., Wang, B.: Segment anything in medical images. Nature Communications15, 654 (2024)
2024
-
[12]
arXiv preprint arXiv:2504.03600 (2025)
Ma, J., Yang, Z., Kim, S., Chen, B., Baharoon, M., Fallahpour, A., Asakereh, R., Lyu, H., Wang, B.: Medsam2: Segment anything in 3d medical images and videos. arXiv preprint arXiv:2504.03600 (2025)
-
[13]
IEEE trans- actions on pattern analysis and machine intelligence46(12), 10998–11018 (2024)
Marinov, Z., Jäger, P.F., Egger, J., Kleesiek, J., Stiefelhagen, R.: Deep interactive segmentation of medical images: A systematic review and taxonomy. IEEE trans- actions on pattern analysis and machine intelligence46(12), 10998–11018 (2024)
2024
-
[14]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Nath, V., Li, W., Yang, D., Myronenko, A., Zheng, M., Lu, Y., Liu, Z., Yin, H., Law, Y.M., Tang, Y., et al.: Vila-m3: Enhancing vision-language models with medical expert knowledge. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14788–14798 (2025)
2025
-
[15]
Radiology279(2), 329–343 (2016)
Pons, E., Braun, L.M., Hunink, M.M., Kors, J.A.: Natural language processing in radiology: a systematic review. Radiology279(2), 329–343 (2016)
2016
-
[16]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Shi, H., Han, S., Huang, S., Liao, Y., Li, G., Kong, X., Zhu, H., Wang, X., Liu, S.: Mask-enhanced segment anything model for tumor lesion semantic segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 403–413. Springer (2024)
2024
-
[17]
In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Wei, F., Zhang, X., Zhang, A., Zhang, B., Chu, X.: Lenna: Language enhanced rea- soning detection assistant. In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2025)
2025
-
[18]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Xu, H., Nie, Y., Wang, H., Chen, Y., Li, W., Ning, J., Liu, L., Wang, H., Zhu, L., Liu, J., et al.: Medground-r1: Advancing medical image grounding via spatial- semantic rewarded group relative policy optimization. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 391–401. Springer (2025)
2025
-
[19]
arXiv preprint arXiv:2508.08177 (2025)
Yan, Z., Diao, M., Yang, Y., Jing, R., Xu, J., Zhang, K., Yang, L., Liu, Y., Liang, K., Ma, Z.: Medreasoner: Reinforcement learning drives reasoning grounding from clinical thought to pixel-level precision. arXiv preprint arXiv:2508.08177 (2025)
-
[20]
arXiv preprint arXiv:2601.06847 (2026)
Zhang, M., Wu, X., Luo, H., Wang, F., Lv, Y.: Medground: Bridging the evidence gap in medical vision-language models with verified grounding data. arXiv preprint arXiv:2601.06847 (2026)
-
[21]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Zhao, T., Kiblawi, S., Usuyama, N., Lee, H.H., Preston, S., Poon, H., Wei, M.: Boltzmann attention sampling for image analysis with small objects. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 25950–25959 (2025)
2025
-
[22]
NPJ Digital Medicine8(1), 566 (2025)
Zhao, Z., Zhang, Y., Wu, C., Zhang, X., Zhou, X., Zhang, Y., Wang, Y., Xie, W.: Large-vocabulary segmentation for medical images with text prompts. NPJ Digital Medicine8(1), 566 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.