On the Generalization Capabilities, Design Choices and Limitations of Keypoint Imitation Learning
Pith reviewed 2026-06-29 17:12 UTC · model grok-4.3
The pith
Keypoint imitation learning achieves 75 percent success across five robotic tasks and generalizes to unseen objects while outperforming RGB image baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Keypoint imitation learning integrates one-shot keypoints from visual foundation models into policy learning, yielding a 75% success rate on five manipulation tasks with strong generalization to unseen objects and scenes, while providing guidelines on integration choices and revealing limits inherited from the keypoint extractors.
What carries the argument
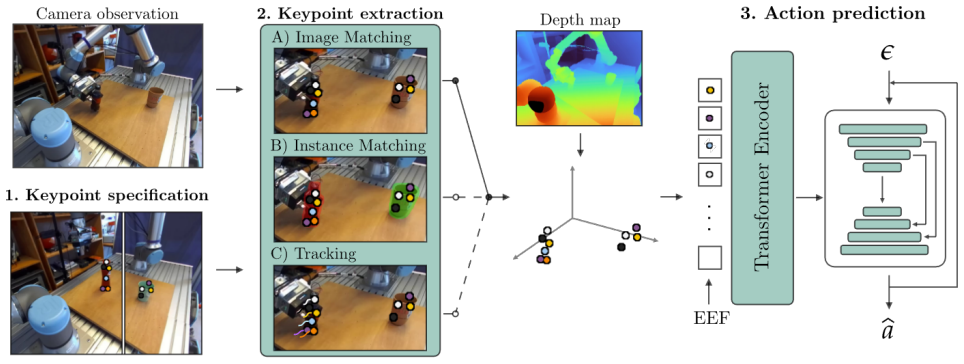
Keypoints extracted by visual foundation models as an intermediate representation for imitation learning policies.
If this is right
- KIL significantly outperforms RGB-based imitation learning on the tested tasks.
- KIL performs on par with diffusion-based policies.
- The approach generalizes to unseen objects and scene variations.
- Design choices for integrating keypoints provide practical guidelines for implementation.
- KIL inherits limitations from the foundation models used for keypoint extraction.
Where Pith is reading between the lines
- Further testing with more diverse foundation models could enhance keypoint consistency beyond the ones examined.
- The data efficiency shown may reduce demonstration needs in related robotic domains such as navigation.
- Handling multiple object instances indicates potential for scaling to cluttered environments.
Load-bearing premise
Keypoints extracted by visual foundation models remain sufficiently accurate and consistent for the tested tasks and unseen variations.
What would settle it
Experiments on tasks with significant changes in lighting or object appearance that cause keypoint extraction to fail would disprove the generalization claims if success rates drop sharply.
Figures





read the original abstract
RGB-based imitation learning requires many demonstrations to generalize to unseen objects or scenes, motivating research into intermediate representations to improve generalization for robotic manipulation. Visual foundation models enable one-shot extraction of keypoints to provide such representation. However, it remains unclear how to integrate them into imitation learning optimally and when they outperform alternative representations. We combine approaches from previous works on keypoint imitation learning (KIL) and investigate several design choices to provide practical guidelines. Using over 2000 real-world rollouts, we also assess the generalization capabilities of KIL to unseen objects and scene variations. KIL achieves a 75% overall success rate across five tasks, significantly outperforming the RGB baseline (47%) and performing on par with S2-diffusion (73%). Finally, we explore the limitations of the foundation models used for keypoint extraction and extend KIL to tasks with multiple object instances. Our results confirm KIL as a data-efficient approach for robot learning, though it does not outperform alternative representations and inherits limitations of the foundation models used for keypoint extraction. All rollout videos, demonstrations, and results are available at https://kil-manipulation.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically studies Keypoint Imitation Learning (KIL), which uses keypoints extracted via visual foundation models as an intermediate representation for imitation learning in robotic manipulation. It examines multiple design choices for integrating these keypoints, evaluates generalization to unseen objects and scene variations using over 2000 real-world rollouts across five tasks, reports a 75% overall success rate (outperforming an RGB baseline at 47% and matching S2-diffusion at 73%), discusses inherited limitations from the foundation models, and extends the method to multi-instance scenarios. Practical guidelines are offered and all data/videos are linked.
Significance. If the results hold under scrutiny, the work supplies concrete, large-scale real-world evidence on the practical value of keypoint representations for data-efficient generalization in imitation learning. The scale of the evaluation (2000+ rollouts) and the direct comparison to both RGB and diffusion baselines are strengths that can inform design decisions, even though KIL is shown not to surpass all alternatives and to inherit foundation-model limitations.
major comments (1)
- [Experiments and Limitations sections] The headline claims of 75% success, outperformance of the RGB baseline, and generalization to unseen objects/scenes rest on the assumption that keypoints extracted by the visual foundation models remain sufficiently accurate and consistent. The manuscript invokes this assumption when discussing foundation-model limitations and the multi-instance extension but supplies no per-task keypoint detection error metrics, no failure-mode analysis linking keypoint quality to task failures, and no ablation that isolates keypoint accuracy from policy learning performance. This is load-bearing for the central attribution of results to KIL.
minor comments (2)
- [Abstract] The abstract states that KIL 'significantly' outperforms the RGB baseline; explicit reporting of per-task trial counts, standard deviations, and the statistical test used would strengthen this claim.
- A compact table listing the five tasks, the specific design choices tested for each, and the corresponding success rates would improve readability and allow readers to trace the guidelines more easily.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the attribution of our empirical results to the keypoint representation. We address the major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Experiments and Limitations sections] The headline claims of 75% success, outperformance of the RGB baseline, and generalization to unseen objects/scenes rest on the assumption that keypoints extracted by the visual foundation models remain sufficiently accurate and consistent. The manuscript invokes this assumption when discussing foundation-model limitations and the multi-instance extension but supplies no per-task keypoint detection error metrics, no failure-mode analysis linking keypoint quality to task failures, and no ablation that isolates keypoint accuracy from policy learning performance. This is load-bearing for the central attribution of results to KIL.
Authors: We agree that direct evidence on keypoint accuracy would strengthen the attribution of performance gains to KIL. The current results rely on large-scale comparisons (KIL at 75% vs. RGB at 47% across 2000+ rollouts) as indirect support for the value of the representation. In revision, we will add a qualitative failure-mode analysis in the Experiments and Limitations sections, including examples from rollout videos where keypoint inconsistencies (e.g., from the foundation model) correlate with task failures. However, quantitative per-task keypoint error metrics are not feasible without extensive new ground-truth annotations across all demonstrations and rollouts. An ablation isolating keypoint accuracy from policy learning would similarly require a separate controlled experimental design (e.g., synthetic keypoint perturbations), which was outside the scope of this study. We will explicitly note these as limitations and update the text accordingly. revision: partial
- Quantitative per-task keypoint detection error metrics and a controlled ablation isolating keypoint accuracy from policy performance, as these require new data collection and experiments beyond the original manuscript.
Circularity Check
No circularity: purely empirical study with direct experimental measurements
full rationale
The paper reports results from over 2000 real-world robot rollouts comparing KIL to baselines on five tasks, measuring success rates and generalization to unseen objects/scenes. No derivations, equations, fitted parameters, or predictions are claimed; the central claims (75% success, outperformance of RGB baseline) are direct empirical outcomes. The assumption about keypoint accuracy from foundation models is an unvalidated premise but does not constitute a self-referential derivation or reduction to inputs by construction. No self-citation load-bearing steps or ansatzes are present in the reported methodology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[2]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina,et al., “A careful examination of large behavior models for multitask dexterous manipulation,”arXiv:2507.05331, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Data scaling laws in imitation learning for robotic manipulation,
F. Lin, Y . Hu, P. Sheng, C. Wen, J. You, and Y . Gao, “Data scaling laws in imitation learning for robotic manipulation,” inInternational Conference on Learning Representations, 2025, pp. 54 877–54 910
2025
-
[4]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,”arXiv:2403.03954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
S2-diffusion: Generalizing from instance-level to category-level skills in robot manipulation,
Q. Yang, M. C. Welle, D. Kragic, and O. Andersson, “S2-diffusion: Generalizing from instance-level to category-level skills in robot manipulation,”IEEE Robotics and Automation Letters, 2025
2025
-
[6]
Viola: Imitation learning for vision-based manipulation with object proposal priors,
Y . Zhu, A. Joshi, P. Stone, and Y . Zhu, “Viola: Imitation learning for vision-based manipulation with object proposal priors,” inConference on Robot Learning. PMLR, 2023, pp. 1199–1210
2023
-
[7]
Learning generaliz- able manipulation policies with object-centric 3d representations,
Y . Zhu, Z. Jiang, P. Stone, and Y . Zhu, “Learning generaliz- able manipulation policies with object-centric 3d representations,” arXiv:2310.14386, 2023
-
[8]
Skil: Semantic key- point imitation learning for generalizable data-efficient manipulation,
S. Wang, J. You, Y . Hu, J. Li, and Y . Gao, “Skil: Semantic key- point imitation learning for generalizable data-efficient manipulation,” arXiv:2501.14400, 2025
-
[9]
Keypoint action tokens enable in-context imitation learning in robotics,
N. Di Palo and E. Johns, “Keypoint action tokens enable in-context imitation learning in robotics,” inRobotics: Science and Systems, 2024
2024
-
[10]
P3-po: Prescriptive point priors for visuo-spatial generalization of robot policies,
M. Levy, S. Haldar, L. Pinto, and A. Shirivastava, “P3-po: Prescriptive point priors for visuo-spatial generalization of robot policies,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 4167–4174
2025
-
[11]
kpam: Keypoint affordances for category-level robotic manipulation,
L. Manuelli, W. Gao, P. Florence, and R. Tedrake, “kpam: Keypoint affordances for category-level robotic manipulation,” inThe Interna- tional Symposium of Robotics Research. Springer, 2019, pp. 132–157
2019
-
[12]
Spill: Size, pose, and internal liquid level estimation of transparent glassware for robotic bartending,
L. Adriaens, T. Lips, M. De Coster, A. Verleysen, and F. wyffels, “Spill: Size, pose, and internal liquid level estimation of transparent glassware for robotic bartending,”IEEE RAL, 2025
2025
-
[13]
S3k: Self- supervised semantic keypoints for robotic manipulation via multi-view consistency,
M. Vecerik, J.-B. Regli, O. Sushkov, D. Barker, R. Pevceviciute, T. Roth ¨orl, R. Hadsell, L. Agapito, and J. Scholz, “S3k: Self- supervised semantic keypoints for robotic manipulation via multi-view consistency,” inConference on Robot Learning. PMLR, 2021, pp. 449–460
2021
-
[14]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa,et al., “Dinov3,” arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Radiov2. 5: Improved baselines for agglom- erative vision foundation models,
G. Heinrich, M. Ranzinger, H. Yin, Y . Lu, J. Kautz, A. Tao, B. Catan- zaro, and P. Molchanov, “Radiov2. 5: Improved baselines for agglom- erative vision foundation models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 487–22 497
2025
-
[16]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[17]
Deep vit features as dense visual descriptors,
S. Amir, Y . Gandelsman, S. Bagon, and T. Dekel, “Deep vit features as dense visual descriptors,” inEuropean Conference on Computer Vision Workshop, 2021
2021
-
[18]
Emergent correspondence from image diffusion,
L. Tang, M. Jia, Q. Wang, C. P. Phoo, and B. Hariharan, “Emergent correspondence from image diffusion,”Advances in neural information processing systems, vol. 36, pp. 1363–1389, 2023
2023
-
[19]
Point policy: Unifying observations and actions with key points for robot manipulation,
S. Haldar and L. Pinto, “Point policy: Unifying observations and actions with key points for robot manipulation,”arXiv:2502.20391, 2025
-
[20]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill,et al., “On the opportunities and risks of foundation models,”arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Unsupervised learning of visual 3d keypoints for control,
B. Chen, P. Abbeel, and D. Pathak, “Unsupervised learning of visual 3d keypoints for control,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 1539–1549
2021
-
[22]
Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation,
W. Huang, C. Wang, Y . Li, R. Zhang, and L. Fei-Fei, “Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation,” inConference on Robot Learning. PMLR, 2025, pp. 4573–4602
2025
-
[23]
K. Rana, J. Abou-Chakra, S. Garg, R. Lee, I. Reid, and N. Suender- hauf, “Learning from 10 demos: Generalisable and sample-efficient policy learning with oriented affordance frames,”arXiv:2410.12124, 2024
-
[24]
Robotap: Tracking arbitrary points for few-shot visual imitation,
M. Vecerik, C. Doersch, Y . Yang, T. Davchev, Y . Aytar, G. Zhou, R. Hadsell, L. Agapito, and J. Scholz, “Robotap: Tracking arbitrary points for few-shot visual imitation,” in2024 IEEE ICRA. IEEE, 2024, pp. 5397–5403
2024
-
[25]
Atk: Automatic task-driven keypoint selection for robust policy learning,
Y . Zhang, S. Mittal, Z. Zhang, L. Ke, S. Srinivasa, and A. Gupta, “Atk: Automatic task-driven keypoint selection for robust policy learning,” arXiv:2506.13867, 2025
-
[26]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang,et al., “Sam 3: Segment anything with concepts,”arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[28]
Learning robotic manipulation policies from point clouds with conditional flow matching,
E. Chisari, N. Heppert, M. Argus, T. Welschehold, T. Brox, and A. Valada, “Learning robotic manipulation policies from point clouds with conditional flow matching,” inConference on Robot Learning, 2024
2024
-
[29]
Gentle grasping: A method with low-cost magnetic tactile sensors,
Y . Liu, R. Proesmans, A. Verleysen, and F. wyffels, “Gentle grasping: A method with low-cost magnetic tactile sensors,”IEEE Access, 2025
2025
-
[30]
Quest2ros: An app to facilitate teleoperating robots,
M. C. Welle, N. Ingelhag, M. Lippi, M. Wozniak, A. Gasparri, and D. Kragic, “Quest2ros: An app to facilitate teleoperating robots,” in 7th International Workshop on Virtual, Augmented, and Mixed-Reality for Human-Robot Interactions, 2024
2024
-
[31]
Cotracker3: Simpler and better point tracking by pseudo- labelling real videos,
N. Karaev, Y . Makarov, J. Wang, N. Neverova, A. Vedaldi, and C. Rup- precht, “Cotracker3: Simpler and better point tracking by pseudo- labelling real videos,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 6013–6022
2025
-
[32]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling,
X. Yu, L. Tang, Y . Rao, T. Huang, J. Zhou, and J. Lu, “Point-bert: Pre-training 3d point cloud transformers with masked point modeling,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 19 313–19 322
2022
-
[33]
Scaling Robot Learning with Semantically Imagined Experience
T. Yu, T. Xiao, A. Stone, J. Tompson, A. Brohan, S. Wang, J. Singh, C. Tan, J. Peralta, B. Ichter,et al., “Scaling robot learning with semantically imagined experience,”arXiv:2302.11550, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
History-aware visuomotor policy learning via point tracking,
J. Chen, H. Fang, C. Wang, S. Wang, and C. Lu, “History-aware visuomotor policy learning via point tracking,”arXiv:2509.17141, 2025
-
[35]
Correspondence- oriented imitation learning: Flexible visuomotor control with 3d con- ditioning,
Y . Cao, Z. Bhaumik, J. Jia, X. He, and K. Fang, “Correspondence- oriented imitation learning: Flexible visuomotor control with 3d con- ditioning,”arXiv:2512.05953, 2025
-
[36]
Vision-based manipulators need to also see from their hands
K. Hsu, M. J. Kim, R. Rafailov, J. Wu, and C. Finn, “Vision-based manipulators need to also see from their hands.” inInternational Conference on Learning Representations, 2022. APPENDIX A. Additional Experiments In this appendix, we provide two additional experiments. In Appendix A.1, we investigate the impact of the data augmentations described in Sectio...
2022
-
[37]
We measure performance onPick PenandPlace Mouseusingimage matchingas keypoint extraction methods
Impact of Augmentations:We study the impact of data augmentations for KIL by selectively enabling the two main augmentations described in Section III-C: addingKeypoint Noiseand applying a randomSpatial Transform (ST). We measure performance onPick PenandPlace Mouseusingimage matchingas keypoint extraction methods. Table VI reports results. We find that no...
-
[38]
Token Pooling Strategy Comparison:In this experiment we elaborate on the use of a different token aggregation strategy in Section IV-I. As stated before, we found that using pointBERT [32] token aggregation (CLS token + maxpool) worked better than using mean-pooling, which we adopted from [8] for these tasks with multiple object instances. We hypothesize ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.