Self-Improvement Imitation with Biologically Guided Search for Protein Design Under Oracle Budgets
Pith reviewed 2026-06-29 19:18 UTC · model grok-4.3
The pith
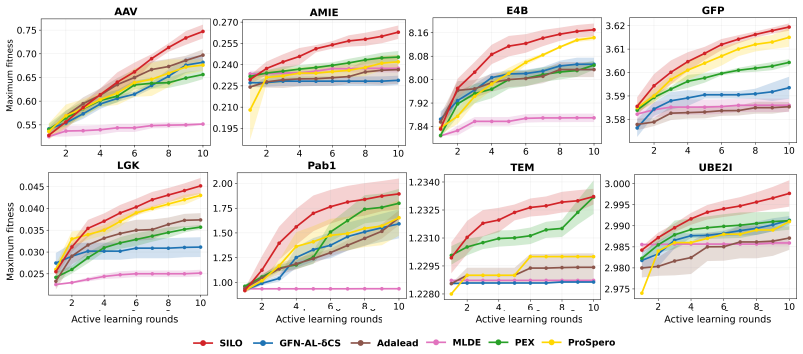
SILO achieves the highest maximum and top-100 mean fitness on all eight protein fitness landscapes by self-improvement imitation on guided edit trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
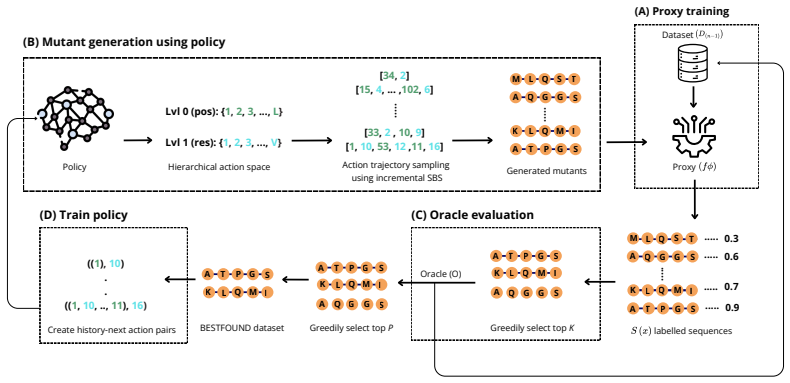
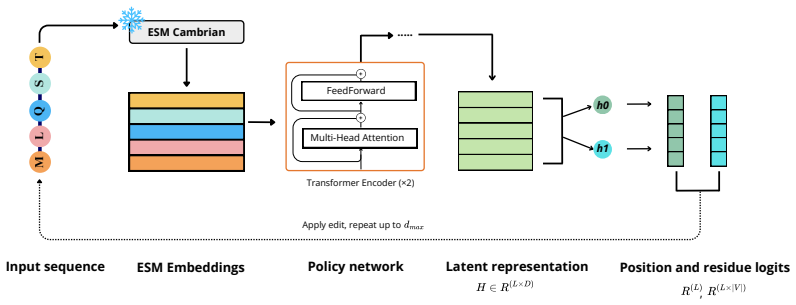
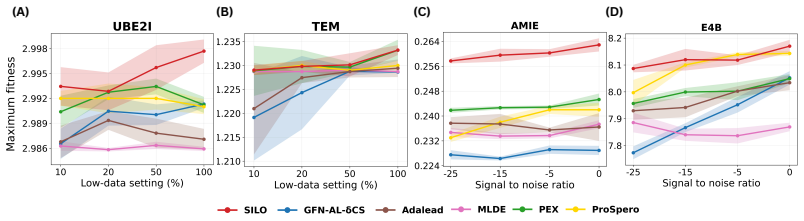
SILO is a trajectory-level self-improvement imitation framework for oracle-budgeted protein design that decomposes mutations into a hierarchical edit policy, samples candidate trajectories with incremental stochastic beam search without replacement, selects candidates for oracle evaluation via a UCB-based proxy ensemble combined with an alanine-scan fitness score, and updates the policy by next-action cross-entropy imitation on the round's best oracle-labeled trajectories, achieving the highest maximum and top-100 mean fitness on all eight reproduced protein fitness landscapes and remaining competitive in low-data and noisy-proxy settings.
What carries the argument
The hierarchical edit policy updated by imitation on oracle-labeled trajectories that are selected by UCB proxy ensemble plus alanine-scan fitness score after stochastic beam search sampling.
If this is right
- SILO stays competitive or best when data are scarce or the proxy models are noisy, while several baselines degrade.
- Ablation results indicate that stochastic beam search combined with the alanine-scan score accounts for most of the performance lift.
- The iterative imitation step supplies additional gains on top of the search procedure alone.
Where Pith is reading between the lines
- If the selection step generalizes beyond the eight tested landscapes, the method could lower the total number of wet-lab measurements required in practical protein engineering projects.
- Replacing the single-round imitation with a longer-horizon planning step might improve performance on landscapes that require many sequential edits.
- Varying the noise level or correlation structure of the proxy ensemble could identify the regimes where the UCB selection is most or least reliable.
Load-bearing premise
The UCB-based proxy ensemble together with the alanine-scan fitness score reliably identifies candidates whose edits are functionally relevant enough to justify oracle evaluation.
What would settle it
Evaluating SILO and the same five baselines on a fresh collection of protein fitness landscapes and finding that SILO no longer records the highest maximum or top-100 mean fitness values.
Figures
read the original abstract
Protein sequence optimization under tight oracle budgets requires methods that explore vast combinatorial spaces while making each evaluation informative. Existing reinforcement learning and off-policy generative approaches often degrade under surrogate noise, and position-agnostic mutation proposals risk disrupting functionally critical residues. We introduce SILO, a trajectory-level self-improvement imitation framework for oracle-budgeted protein design. SILO uses a hierarchical edit policy that decomposes each mutation into a position choice followed by a residue choice. In each active-learning round, the policy samples candidate trajectories via incremental stochastic beam search without replacement (SBS), and a UCB-based proxy ensemble, combined with an alanine-scan fitness score (AFS), selects candidates with functionally relevant edits for in silico oracle evaluation. The policy is then updated by next-action cross-entropy imitation on the round's best oracle-labeled trajectories, avoiding value-function estimation. Across eight reproduced protein fitness landscapes and five strong baselines from prior work, SILO achieves the highest maximum and top-100 mean fitness on 8 of 8 landscapes within our evaluations, often exhibiting faster early-stage improvement. In low-data and noisy-proxy stress tests on two landscapes per setting, SILO remains competitive or best when several baselines degrade. Ablations show that SBS with AFS account for much of the gains, with iterative imitation providing additional improvement. Code is available at: https://github.com/grimmlab/SILO.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SILO, a self-improvement imitation framework for protein sequence optimization under tight oracle budgets. It decomposes mutations via a hierarchical edit policy (position then residue), samples trajectories with incremental stochastic beam search without replacement (SBS), selects candidates using a UCB-based proxy ensemble combined with an alanine-scan fitness score (AFS), evaluates the top candidates with an in silico oracle, and updates the policy via next-action cross-entropy imitation on the best oracle-labeled trajectories. Across eight reproduced protein fitness landscapes, SILO reports the highest maximum fitness and top-100 mean fitness on all 8 landscapes versus five strong baselines, with faster early improvement and robustness in low-data and noisy-proxy stress tests; ablations attribute much of the gain to SBS with AFS.
Significance. If the empirical claims hold, the approach offers a practical route to oracle-efficient design by grounding updates in external oracle labels rather than fitted value estimates and by incorporating a biologically motivated position-selection heuristic. The open-source code release supports reproducibility. The method's avoidance of value-function estimation and its explicit handling of position importance distinguish it from standard RL or generative baselines in this domain.
major comments (2)
- [Ablation studies and active-learning description] The active-learning loop (SBS sampling followed by UCB+AFS selection, then imitation) is load-bearing for the headline claim of consistent outperformance on 8/8 landscapes. The manuscript states that 'SBS with AFS account for much of the gains,' yet provides no direct evidence (e.g., correlation plots or per-landscape ablation) that AFS scores reliably identify positions whose edits drive fitness on the evaluated landscapes; if this correlation is weak or landscape-dependent, the selected trajectories may be uninformative and the subsequent imitation step may reinforce suboptimal policies rather than discover better ones.
- [Stress-test experiments] The stress-test results on two landscapes per setting claim that SILO 'remains competitive or best when several baselines degrade,' but the manuscript does not report the exact noise levels, proxy-ensemble variance, or number of oracle calls per round used in those tests; without these details it is impossible to assess whether the UCB+AFS selection remains reliable under the reported conditions.
minor comments (2)
- [Experimental protocol] The abstract and main text should explicitly state the total oracle budget per landscape and the number of active-learning rounds so that the 'oracle-budgeted' claim can be directly compared with prior work.
- [Method] Notation for the hierarchical policy (position choice followed by residue choice) and the exact form of the next-action imitation loss should be formalized in a single equation or algorithm box for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our ablation analysis and the reporting of stress-test details. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Ablation studies and active-learning description] The active-learning loop (SBS sampling followed by UCB+AFS selection, then imitation) is load-bearing for the headline claim of consistent outperformance on 8/8 landscapes. The manuscript states that 'SBS with AFS account for much of the gains,' yet provides no direct evidence (e.g., correlation plots or per-landscape ablation) that AFS scores reliably identify positions whose edits drive fitness on the evaluated landscapes; if this correlation is weak or landscape-dependent, the selected trajectories may be uninformative and the subsequent imitation step may reinforce suboptimal policies rather than discover better ones.
Authors: We agree that direct evidence on the correlation between AFS scores and fitness-driving edits would strengthen the justification for the selection step. Our existing ablations compare full SILO against variants without AFS and show clear performance drops, but these are indirect. In the revision we will add per-landscape Spearman correlation plots between AFS and observed fitness deltas on the oracle-evaluated trajectories, plus expanded ablation tables broken down by landscape. This will allow readers to assess the reliability of AFS directly. revision: yes
-
Referee: [Stress-test experiments] The stress-test results on two landscapes per setting claim that SILO 'remains competitive or best when several baselines degrade,' but the manuscript does not report the exact noise levels, proxy-ensemble variance, or number of oracle calls per round used in those tests; without these details it is impossible to assess whether the UCB+AFS selection remains reliable under the reported conditions.
Authors: We acknowledge the omission of precise experimental parameters. The stress tests were performed with controlled Gaussian noise added to the proxy predictions and fixed oracle budgets per round; these values are present in the released code but were not stated explicitly in the text. We will add a dedicated paragraph (and table) in the revised manuscript listing the exact noise standard deviations, ensemble variance statistics, and oracle-call counts used in each stress-test setting. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical active-learning method whose policy update step is defined by next-action imitation on trajectories explicitly labeled by an external oracle. This grounding is independent of the model's own value estimates or fitted parameters. The UCB ensemble and AFS are used solely for pre-oracle candidate ranking and do not generate the imitation targets. No equations reduce a claimed prediction to a fitted input by construction, no uniqueness theorems are imported from self-citations, and no ansatz is smuggled via prior work. The reported performance is therefore an external benchmark result rather than a self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reproduced protein fitness landscapes from prior work provide valid test environments for oracle-budgeted optimization.
- domain assumption The oracle returns accurate fitness values for evaluated sequences.
invented entities (3)
-
SILO framework
no independent evidence
-
hierarchical edit policy
no independent evidence
-
alanine-scan fitness score (AFS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hindsight experience replay
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay. Advances in neural information processing systems, 30, 2017
2017
-
[2]
Model-based reinforcement learning for biological sequence design
Christof Angermueller, David Dohan, David Belanger, Ramya Deshpande, Kevin Murphy, and Lucy Colwell. Model-based reinforcement learning for biological sequence design. InInternational conference on learning representations, 2019
2019
-
[3]
Flow network based generative models for non-iterative diverse candidate generation.Advances in neural information processing systems, 34:27381–27394, 2021
Emmanuel Bengio, Moksh Jain, Maksym Korablyov, Doina Precup, and Yoshua Bengio. Flow network based generative models for non-iterative diverse candidate generation.Advances in neural information processing systems, 34:27381–27394, 2021
2021
-
[4]
Robustness– epistasis link shapes the fitness landscape of a randomly drifting protein.Nature, 444(7121):929–932, 2006
Shimon Bershtein, Michal Segal, Roy Bekerman, Nobuhiko Tokuriki, and Dan S Tawfik. Robustness– epistasis link shapes the fitness landscape of a randomly drifting protein.Nature, 444(7121):929–932, 2006
2006
-
[5]
Conditioning by adaptive sampling for robust design
David Brookes, Hahnbeom Park, and Jennifer Listgarten. Conditioning by adaptive sampling for robust design. InInternational conference on machine learning, pages 773–782. PMLR, 2019
2019
-
[6]
Design by adaptive sampling.arXiv preprint arXiv:1810.03714, 2018
David H Brookes and Jennifer Listgarten. Design by adaptive sampling.arXiv preprint arXiv:1810.03714, 2018
-
[7]
Self-labeling the job shop scheduling problem.Advances in Neural Information Processing Systems, 37:105528–105551, 2024
Andrea Corsini, Angelo Porrello, Simone Calderara, and Mauro Dell’Amico. Self-labeling the job shop scheduling problem.Advances in Neural Information Processing Systems, 37:105528–105551, 2024
2024
-
[8]
High-resolution epitope mapping of hgh-receptor interactions by alanine-scanning mutagenesis.Science, 244(4908):1081–1085, 1989
Brian C Cunningham and James A Wells. High-resolution epitope mapping of hgh-receptor interactions by alanine-scanning mutagenesis.Science, 244(4908):1081–1085, 1989
1989
-
[9]
Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems, 35: 16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems, 35: 16344–16359, 2022
2022
-
[10]
J. Arjan G.M. de Visser and Joachim Krug. Empirical fitness landscapes and the predictability of evolution.Nature Reviews Genetics, 15(7):480–490, 2014. ISSN 1471-0064. doi: 10.1038/nrg3744. URL http://dx.doi.org/10.1038/nrg3744
-
[11]
A comprehensive, high-resolution map of a gene’s fitness landscape.Molecular biology and evolution, 31(6):1581–1592, 2014
Elad Firnberg, Jason W Labonte, Jeffrey J Gray, and Marc Ostermeier. A comprehensive, high-resolution map of a gene’s fitness landscape.Molecular biology and evolution, 31(6):1581–1592, 2014
2014
-
[12]
Deep reinforcement learning that matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[13]
J D Hermes, S C Blacklow, and J R Knowles. Searching sequence space by definably random mutagenesis: improving the catalytic potency of an enzyme.Proceedings of the National Academy of Sciences, 87(2): 696–700, January 1990. ISSN 1091-6490. doi: 10.1073/pnas.87.2.696. URL http://dx.doi.org/10. 1073/pnas.87.2.696
-
[14]
Capturing the mutational landscape of the beta-lactamase tem-1.Proceedings of the National Academy of Sciences, 110(32): 13067–13072, 2013
Hervé Jacquier, André Birgy, Hervé Le Nagard, Yves Mechulam, Emmanuelle Schmitt, Jérémy Glodt, Beatrice Bercot, Emmanuelle Petit, Julie Poulain, Guilène Barnaud, et al. Capturing the mutational landscape of the beta-lactamase tem-1.Proceedings of the National Academy of Sciences, 110(32): 13067–13072, 2013
2013
-
[15]
Biological sequence design with gflownets
Moksh Jain, Emmanuel Bengio, Alex Hernandez-Garcia, Jarrid Rector-Brooks, Bonaventure FP Dossou, Chanakya Ajit Ekbote, Jie Fu, Tianyu Zhang, Michael Kilgour, Dinghuai Zhang, et al. Biological sequence design with gflownets. InInternational conference on machine learning, pages 9786–9801. PMLR, 2022
2022
-
[16]
Sanjeevaiah Kasturi, Ako Kihara, David FitzGerald, and Ira Pastan. Alanine scanning mutagenesis identifies surface amino acids on domain ii of pseudomonas exotoxin required for cytotoxicity, proper folding, and secretion into periplasm.Journal of Biological Chemistry, 267(32):23427–23433, 1992. 10
1992
-
[17]
Hyeonah Kim, Minsu Kim, Taeyoung Yun, Sanghyeok Choi, Emmanuel Bengio, Alex Hernández-García, and Jinkyoo Park. Improved off-policy reinforcement learning in biological sequence design.arXiv preprint arXiv:2410.04461, 2024
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Trade-offs between enzyme fitness and solubility illuminated by deep mutational scanning.Proceedings of the National Academy of Sciences, 114(9):2265–2270, 2017
Justin R Klesmith, John-Paul Bacik, Emily E Wrenbeck, Ryszard Michalczyk, and Timothy A Whitehead. Trade-offs between enzyme fitness and solubility illuminated by deep mutational scanning.Proceedings of the National Academy of Sciences, 114(9):2265–2270, 2017
2017
-
[20]
Michal Kmicikiewicz, Vincent Fortuin, and Ewa Szczurek. Prospero: Active learning for robust protein design beyond wild-type neighborhoods.arXiv preprint arXiv:2505.22494, 2025
-
[21]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. InEuropean conference on machine learning, pages 282–293. Springer, 2006
2006
-
[22]
Stochastic beams and where to find them: The gumbel- top-k trick for sampling sequences without replacement
Wouter Kool, Herke Van Hoof, and Max Welling. Stochastic beams and where to find them: The gumbel- top-k trick for sampling sequences without replacement. InInternational conference on machine learning, pages 3499–3508. PMLR, 2019
2019
-
[23]
Recent advances in (therapeutic protein) drug development
HA Daniel Lagassé, Aikaterini Alexaki, Vijaya L Simhadri, Nobuko H Katagiri, Wojciech Jankowski, Zuben E Sauna, and Chava Kimchi-Sarfaty. Recent advances in (therapeutic protein) drug development. F1000Research, 6:113, 2017
2017
-
[24]
Minji Lee, Luiz Felipe Vecchietti, Hyunkyu Jung, Hyun Joo Ro, Meeyoung Cha, and Ho Min Kim. Robust optimization in protein fitness landscapes using reinforcement learning in latent space.arXiv preprint arXiv:2405.18986, 2024
-
[25]
Highplay: Cyclic peptide sequence design based on reinforcement learning and protein structure prediction.Journal of Medicinal Chemistry, 68(11):12047–12057, 2025
Huitian Lin, Cheng Zhu, Tianfeng Shang, Ning Zhu, Kang Lin, Chengyun Zhang, Xiang Shao, Xudong Wang, and Hongliang Duan. Highplay: Cyclic peptide sequence design based on reinforcement learning and protein structure prediction.Journal of Medicinal Chemistry, 68(11):12047–12057, 2025
2025
-
[26]
Language models of protein sequences at the scale of evolution enable accurate structure prediction.BioRxiv, 2022:500902, 2022
Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, et al. Language models of protein sequences at the scale of evolution enable accurate structure prediction.BioRxiv, 2022:500902, 2022
2022
-
[27]
Fu Luo, Xi Lin, Zhenkun Wang, Xialiang Tong, Mingxuan Yuan, and Qingfu Zhang. Self-improved learning for scalable neural combinatorial optimization.arXiv preprint arXiv:2403.19561, 2024
-
[28]
Deep mutational scanning of an rrm domain of the saccharomyces cerevisiae poly (a)-binding protein.Rna, 19 (11):1537–1551, 2013
Daniel Melamed, David L Young, Caitlin E Gamble, Christina R Miller, and Stanley Fields. Deep mutational scanning of an rrm domain of the saccharomyces cerevisiae poly (a)-binding protein.Rna, 19 (11):1537–1551, 2013
2013
-
[29]
Ray: A distributed framework for emerging {AI} applications
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I Jordan, et al. Ray: A distributed framework for emerging {AI} applications. In13th USENIX symposium on operating systems design and implementation (OSDI 18), pages 561–577, 2018
2018
-
[30]
New advances in protein engineering for industrial applications: Key takeaways.Open life sciences, 19(1):20220856, 2024
Giles Obinna Ndochinwa, Qing-Yan Wang, Nkwachukwu Oziamara Okoro, Oyetugo Chioma Amadi, Tochukwu Nwamaka Nwagu, Chukwudi Innocent Nnamchi, Anene Nwabu Moneke, and Arome Solomon Odiba. New advances in protein engineering for industrial applications: Key takeaways.Open life sciences, 19(1):20220856, 2024
2024
-
[31]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[32]
Jonathan Pirnay and Dominik G Grimm. Self-improvement for neural combinatorial optimization: Sample without replacement, but improvement.arXiv preprint arXiv:2403.15180, 2024
-
[33]
Graphxform: graph transformer for computer-aided molecular design.Digital Discovery, 4(4):1052–1065, 2025
Jonathan Pirnay, Jan G Rittig, Alexander B Wolf, Martin Grohe, Jakob Burger, Alexander Mitsos, and Dominik G Grimm. Graphxform: graph transformer for computer-aided molecular design.Digital Discovery, 4(4):1052–1065, 2025
2025
-
[34]
Evaluating protein transfer learning with tape.Advances in neural information processing systems, 32, 2019
Roshan Rao, Nicholas Bhattacharya, Neil Thomas, Yan Duan, Peter Chen, John Canny, Pieter Abbeel, and Yun Song. Evaluating protein transfer learning with tape.Advances in neural information processing systems, 32, 2019. 11
2019
-
[35]
Julia C. Reisenbauer, Kathleen M. Sicinski, and Frances H. Arnold. Catalyzing the future: recent advances in chemical synthesis using enzymes.Current Opinion in Chemical Biology, 83:102536, 2024. ISSN 1367-5931. doi: https://doi.org/10.1016/j.cbpa.2024.102536. URL https://www.sciencedirect.com/ science/article/pii/S1367593124001121
-
[36]
Proximal exploration for model- guided protein sequence design
Zhizhou Ren, Jiahan Li, Fan Ding, Yuan Zhou, Jianzhu Ma, and Jian Peng. Proximal exploration for model- guided protein sequence design. InInternational Conference on Machine Learning, pages 18520–18536. PMLR, 2022
2022
-
[37]
Local fitness landscape of the green fluorescent protein.Nature, 533(7603):397–401, 2016
Karen S Sarkisyan, Dmitry A Bolotin, Margarita V Meer, Dinara R Usmanova, Alexander S Mishin, George V Sharonov, Dmitry N Ivankov, Nina G Bozhanova, Mikhail S Baranov, Onuralp Soylemez, et al. Local fitness landscape of the green fluorescent protein.Nature, 533(7603):397–401, 2016
2016
-
[38]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Understanding the effects of dataset characteristics on offline reinforcement learning
Kajetan Schweighofer, Markus Hofmarcher, Marius-Constantin Dinu, Philipp Renz, Angela Bitto-Nemling, Vihang Prakash Patil, and Sepp Hochreiter. Understanding the effects of dataset characteristics on offline reinforcement learning. InDeep RL Workshop NeurIPS 2021, 2021. URL https://openreview.net/ forum?id=A4EWtf-TO3Y
2021
-
[40]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm.arXiv preprint arXiv:1712.01815, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Sam Sinai, Richard Wang, Alexander Whatley, Stewart Slocum, Elina Locane, and Eric D Kelsic. Adalead: A simple and robust adaptive greedy search algorithm for sequence design.arXiv preprint arXiv:2010.02141, 2020
-
[42]
Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design
Niranjan Srinivas, Andreas Krause, Sham M Kakade, and Matthias Seeger. Gaussian process optimization in the bandit setting: No regret and experimental design.arXiv preprint arXiv:0912.3995, 2009
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[43]
Activity-enhancing mutations in an e3 ubiquitin ligase identified by high-throughput mutagenesis.Proceedings of the National Academy of Sciences, 110(14):E1263–E1272, 2013
Lea M Starita, Jonathan N Pruneda, Russell S Lo, Douglas M Fowler, Helen J Kim, Joseph B Hiatt, Jay Shendure, Peter S Brzovic, Stanley Fields, and Rachel E Klevit. Activity-enhancing mutations in an e3 ubiquitin ligase identified by high-throughput mutagenesis.Proceedings of the National Academy of Sciences, 110(14):E1263–E1272, 2013
2013
-
[44]
Esm cambrian: Revealing the mysteries of proteins with unsupervised learning.Evolu- tionaryScale Website, 2024
ESM Team et al. Esm cambrian: Revealing the mysteries of proteins with unsupervised learning.Evolu- tionaryScale Website, 2024
2024
-
[45]
Conservative objective models for effective offline model-based optimization
Brandon Trabucco, Aviral Kumar, Xinyang Geng, and Sergey Levine. Conservative objective models for effective offline model-based optimization. InInternational Conference on Machine Learning, pages 10358–10368. PMLR, 2021
2021
-
[46]
Protein design by directed evolution guided by large language models
Thanh VT Tran and Truong Son Hy. Protein design by directed evolution guided by large language models. IEEE Transactions on Evolutionary Computation, 29(2):418–428, 2024
2024
-
[47]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[48]
Self-play reinforcement learning guides protein engineering.Nature Machine Intelligence, 5(8):845–860, 2023
Yi Wang, Hui Tang, Lichao Huang, Lulu Pan, Lixiang Yang, Huanming Yang, Feng Mu, and Meng Yang. Self-play reinforcement learning guides protein engineering.Nature Machine Intelligence, 5(8):845–860, 2023
2023
-
[49]
A framework for exhaustively mapping functional missense variants.Molecular systems biology, 13(12):MSB177908, 2017
Jochen Weile, Song Sun, Atina G Cote, Jennifer Knapp, Marta Verby, Joseph C Mellor, Yingzhou Wu, Carles Pons, Cassandra Wong, Natascha van Lieshout, et al. A framework for exhaustively mapping functional missense variants.Molecular systems biology, 13(12):MSB177908, 2017
2017
-
[50]
Single-mutation fitness landscapes for an enzyme on multiple substrates reveal specificity is globally encoded.Nature communications, 8(1):15695, 2017
Emily E Wrenbeck, Laura R Azouz, and Timothy A Whitehead. Single-mutation fitness landscapes for an enzyme on multiple substrates reveal specificity is globally encoded.Nature communications, 8(1):15695, 2017. 12 Appendix A Related work 14 B Experiment setting and implementation details 14 B.1 Benchmark datasets . . . . . . . . . . . . . . . . . . . . . ....
2017
-
[51]
The dataset D0 containing 15,307 sequences, was generated by Kim et al
Adeno-associated Virus (AA V):The task focuses on improving binding affinity of an amino acid segment (position 450-540) of the VP1 protein located in the capsid of the Adeno-associated virus. The dataset D0 containing 15,307 sequences, was generated by Kim et al. [17] by randomly mutating the wild-type sequence while filtering out sequences that have hig...
2090
-
[52]
Initial dataset D0 contains 6417 sequences with single mutations to model the fitness landscape
Aliphatic Amide Hydrolase (AMIE):The task aims is optimize amidase sequences for increased enzymatic activity [50]. Initial dataset D0 contains 6417 sequences with single mutations to model the fitness landscape. The length of sequence L= 341. The starting fitness is O(xstart) = 0.224 , and Novelty (D0,x start) = 2
-
[53]
Starita et al
Ubiquitination Factor Ube4b (E4B):The goal is generate sequences that enhance E4B ubiquitination enzyme. Starita et al. [43] measured the rates of ubiquitination of the mutants to the target protein. The full dataset includes 91,032 sequences of length L= 102 , from which [20] randomly selected 10,000 sequences to form D0. The starting sequence has O(xsta...
-
[54]
The D0 dataset contains 10,200 sequences generated by [17], similarly to AA V
Green Fluorescent Protein (GFP):The task seeks to generate sequences with high log-fluorescence intensity [37]. The D0 dataset contains 10,200 sequences generated by [17], similarly to AA V . The sequence length isL=238, withO(x start) =3.572 and Novelty (D 0,x start) = 42.87
-
[55]
The initial dataset D0 includes 7,633 sequences of length L= 439, with O(xstart) = 0.020 and Novelty (D0, xstart) = 2.0
Levoglucosan Kinase (LGK):This task aims to improve enzymatic activity oflevoglucosan kinase, which converts LG to the glycolytic intermediate glucose-6-phosphate [19]. The initial dataset D0 includes 7,633 sequences of length L= 439, with O(xstart) = 0.020 and Novelty (D0, xstart) = 2.0
-
[56]
Melamed et al
Poly(A)-binding Protein (Pab1):The poly(A)-binding protein Pab1 is binds to polyadenosine (poly- A) sequences via its RNA recognition motif (RRM). Melamed et al. [28] conducted a high-throughput screening assay to measure binding fitness for approximately 36,000 double mutants of Pab1 within the RRM region. This task focuses on improving binding affinity ...
-
[57]
The aim of this task is to TEM variants with improved thermodynamic stability
TEM-1 β-Lactamase (TEM):TEM-1 β-Lactamase resistance to penicillin antibiotics inE.coliis widely studied to understand mutational effect and fitness landscape [14], [4]. The aim of this task is to TEM variants with improved thermodynamic stability. The datasetD 0 derived [11] from contains 5,199 sequences of length L= 286. The starting sequence has fitnes...
-
[58]
[49] and the goal of this task is to optimize these variants for functional mapping applications
SUMO E2 Conjugase (UBE2I):Variants of the disease-relevant protein, human SUMO E2 conjugase were generated by Weile et al. [49] and the goal of this task is to optimize these variants for functional mapping applications. D0 comprise of 3,022 sequences of length L= 159. The starting sequence has O(xstart) =2.978 and Novelty (D0,x start) = 2.0. B.2 Proxy ar...
-
[59]
[ 41] available at https://github.com/samsinai/FLEXS/tree/master under the Apache-2.0 license
AdaLead [41]:We employed the open-source implementations provided by Sinai et al. [ 41] available at https://github.com/samsinai/FLEXS/tree/master under the Apache-2.0 license. We used the default hyperparameters of the model, with a recombination rate of 0.2, a mutation rate of 1/L, where L is the sequence length, and a threshold τ= 0.05. The numbers of ...
2000
-
[60]
[ 17], we employ an adaptive δ with a maximum masking radius of 0.05 and rank-based proxy training with a reweighting factor k=0.01
GFN-AL-δCS [ 17]:For the conservative strategy GFN-AL- δCS proposed by Kim et al. [ 17], we employ an adaptive δ with a maximum masking radius of 0.05 and rank-based proxy training with a reweighting factor k=0.01. We set the scaling factor λ= 0.1 for AA V , E4B, and Pab1, and λ= 1 for GFP, AMIE, TEM, UBE2I, and LGK. We use the publically released codebas...
-
[61]
Adapting their setup to perform active learning, we perform 10 rounds of surrogate-guided optimization 15 with a population size of 128 and a beam size of 4
MLDE [46]:We use the MLDE implementation from Tran and Hy [ 46], from their publicly avail- able codebase https://github.com/HySonLab/Directed_Evolution under the GPL-3.0 license. Adapting their setup to perform active learning, we perform 10 rounds of surrogate-guided optimization 15 with a population size of 128 and a beam size of 4. The masking strateg...
-
[62]
[ 36] using the official codebase https://github
PEX [36]:We implement PEX from Ren et al. [ 36] using the official codebase https://github. com/HeliXonProtein/proximal-exploration/tree/main under the Apache-2.0 license. We use the default configuration, including 2 random mutations and a frontier neighborhood size of 5
-
[63]
ProSpero [ 20]:We use ProSpero under the official codebase https://github.com/ szczurek-lab/ProSpero.git released by Kmicikiewicz, Fortuin, and Szczurek [ 20] under the GPL-3.0 license. We use the default hyperparameters of the method, keeping the range of number of corruptions introduced within the sequences between 3-10 for shorter sequences (E4B, Pab1,...
-
[64]
Novelty:Quantifies the average Hamming distance between the top sequences and the starting sequencex start, reflecting deviation from the wild-type: Novelty(Dtop, xstart) = 1 |Dtop| X x∈Dtop d(x, xstart)(8)
-
[65]
Experiments were conducted on an NVIDIA A40 GPU using CUDA 12.2
Diversity:Measures the average pairwise Hamming distance among the top sequences, indicating the extent of exploration: Diversity(Dtop) = 1 |Dtop|(|Dtop| −1) X x,x′∈Dtop,x̸=x′ d(x, x′)(9) C Discussion C.1 Hardware and runtime details Our code is developed in PyTorch [31] v.2.8.0. Experiments were conducted on an NVIDIA A40 GPU using CUDA 12.2. SILO incurs...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.