Innovation: An Almost Characterization of Hallucination
Pith reviewed 2026-06-29 19:24 UTC · model grok-4.3
The pith
Innovation is an almost characterization of hallucination in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Innovation is an almost characterization of hallucination: hallucination implies innovation, and conversely, innovation implies hallucination with high probability. We also provide lower bounds on the hallucination rate based on the innovation rate, and by relating innovation rate back to missing mass, we obtain new hallucination rate lower bounds based on missing mass that extend the results of Kalai and Vempala.
What carries the argument
Innovation, defined as the tendency of a model to produce outputs outside the training data, which links the prior hallucination condition to a direct behavioral measure and supports rate bounds.
If this is right
- Hallucination rates admit lower bounds expressed directly in terms of the innovation rate.
- New lower bounds on hallucination rates follow from the connection between innovation rate and missing mass.
- Calibrated models hallucinate at rates tied to their innovation even if other factors are controlled.
- Giving up calibration does not remove the link from innovation to hallucination.
Where Pith is reading between the lines
- Practical measurement of innovation during model evaluation could predict hallucination rates without exhaustive testing.
- Strategies that reduce missing mass in training data would lower both innovation and hallucination rates as a direct consequence.
- The framework could be tested on non-language generative models to check if the same innovation-hallucination link holds.
Load-bearing premise
The probabilistic framework and definitions of calibration and hallucination introduced by Kalai and Vempala accurately model the relevant behavior of LLMs.
What would settle it
Finding a calibrated model with high innovation but low observed hallucination rate, or low innovation but high hallucination rate, would contradict the claimed near-equivalence.
Figures
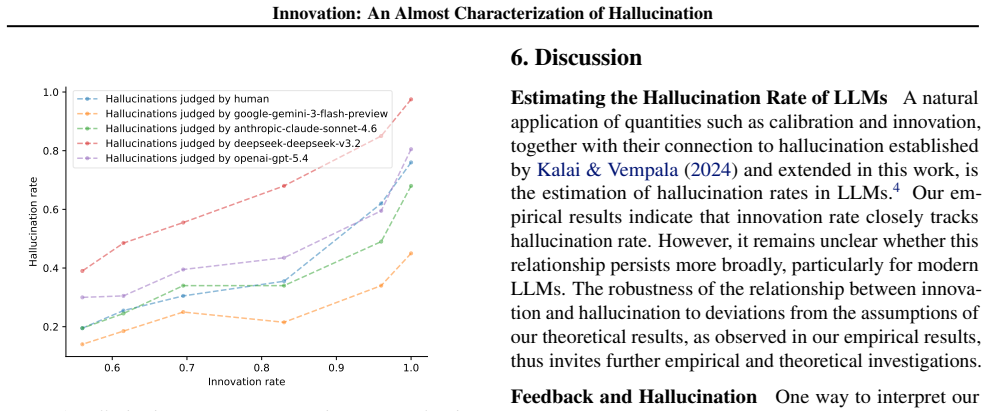
read the original abstract
Hallucination is a central limitation of large language models (LLMs), and substantial effort has been devoted to understanding and mitigating it. Towards this, Kalai and Vempala (STOC 2024) introduced a probabilistic framework formalizing calibration and hallucination, and showed that, with high probability, calibrated LLMs hallucinate roughly at the rate of the "missing mass", a measure of how incomplete the training data is relative to its source. This raises two fundamental questions: (i) what property of a calibrated LLM makes hallucinations unavoidable? and (ii) can hallucinations be avoided by giving up calibration? We answer these questions by introducing a simpler property we call innovation that measures the tendency of a model to produce outputs outside the training data. We show that innovation is implied by the condition for hallucination identified by Kalai and Vempala, and, further, that it is an almost characterization of hallucination: hallucination implies innovation, and conversely, innovation implies hallucination with high probability. We also provide lower bounds on the hallucination rate based on the "innovation rate", and by relating innovation rate back to missing mass, we obtain new hallucination rate lower bounds based on missing mass that extend the results of Kalai and Vempala.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the 'innovation' property measuring a calibrated LLM's tendency to produce outputs outside the training data. It shows that innovation is implied by the Kalai-Vempala hallucination condition, that hallucination implies innovation, and that innovation implies hallucination with high probability. The work also derives lower bounds on the hallucination rate from the innovation rate and, by relating innovation back to missing mass, obtains new missing-mass-based lower bounds extending Kalai and Vempala (STOC 2024).
Significance. If the high-probability claims hold under the stated probabilistic framework, the result supplies a simpler, nearly characterizing property for hallucinations and strengthens the missing-mass lower bounds. The logical independence of the new definition from prior quantities and the explicit extension of existing bounds are strengths.
minor comments (2)
- [§2] The abstract and introduction reference the Kalai-Vempala framework but do not restate its key definitions (calibration, hallucination) or assumptions; adding a short self-contained recap in §2 would improve readability.
- Notation for 'innovation rate' is introduced without an explicit equation number in the provided text; ensure it is labeled (e.g., Eq. (3)) and cross-referenced when the lower bounds are stated.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work, the assessment of its significance, and the recommendation for minor revision. No specific major comments were listed in the report.
Circularity Check
No significant circularity; derivation introduces independent property and extends prior framework
full rationale
The paper defines a new property called innovation measuring tendency to produce outputs outside training data. It shows logical implications (hallucination condition implies innovation; hallucination implies innovation; innovation implies hallucination w.h.p.) and derives lower bounds on hallucination rate from innovation rate, then relates innovation rate to missing mass to extend Kalai-Vempala bounds. These steps use the cited prior framework as external input rather than reducing the new claims to self-definitions, fitted parameters, or self-citation chains. No equations or definitions exhibit the listed circular patterns; the central claims remain independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probabilistic framework and definitions of calibration, hallucination, and missing mass from Kalai and Vempala (STOC 2024)
invented entities (1)
-
innovation property
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/S0019-9958(67)91165-5. Good, I. J. The population frequencies of species and the estimation of population parameters.Biometrika, 40(3-4): 237–264, December
-
[2]
doi: 10.1093/biomet/40.3-4
-
[3]
doi: 10.1145/3618260.3649777. Kalai, A. T., Nachum, O., Vempala, S. S., and Zhang, E. Why language models hallucinate,
-
[4]
Why Language Models Hallucinate
URL https: //arxiv.org/abs/2509.04664. Kalavasis, A., Mehrotra, A., and Velegkas, G. On the limits of language generation: Trade-offs between hallucination and mode-collapse. InProceedings of the 57th Annual ACM Symposium on Theory of Computing (STOC), pp. 1732–1743. ACM,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
doi: 10.1145/3717823.3718108. Kleinberg, J. and Mullainathan, S. Language generation in the limit. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pp. 66058–66079. Curran Associates, Inc.,
-
[6]
doi: 10.52202/079017-2111. Kleinberg, J. and Wei, F. Density measures for language generation. InProceedings of the 66th Annual IEEE Symposium on Foundations of Computer Science (FOCS), pp. 620–658. IEEE,
-
[7]
doi: 10.1109/FOCS63196. 2025.00034. Kotzias, D., Denil, M., de Freitas, N., and Smyth, P. From group to individual labels using deep features.Proceed- ings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pp. 597–606,
-
[8]
doi: 10.1145/2783258.2783380. Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., K¨uttler, H., Lewis, M., Yih, W.-t., Rockt¨aschel, T., Riedel, S., and Kiela, D. Retrieval-augmented genera- tion for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), vol- ume 33, pp. 9459–9474. Curran Associ...
-
[9]
URL https://aclanthology.org/ 2022.acl-long.229/. Miao, M. M. and Kearns, M. Hallucination, mono- facts, and miscalibration: An empirical investigation. Proceedings of the National Academy of Sciences (PNAS), 123(8):e2533582123,
2022
-
[10]
doi: 10.1073/pnas. 2533582123. URL https://www.pnas.org/doi/ abs/10.1073/pnas.2533582123. Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V ., Saunders, W., Jiang, X., Cobbe, K., Eloundou, T., Krueger, G., Button, K., Knight, M., Chess, B., and Schulman, J. WebGPT: Browser-assisted question-answering with hu...
-
[11]
WebGPT: Browser-assisted question-answering with human feedback
URL https://arxiv.org/abs/ 2112.09332v3. Raman, A. and Raman, V . Generation from noisy examples. InProceedings of the 42nd International Conference on Machine Learning (ICML), volume 267 ofPMLR, pp. 51079–51093,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Hallucinations are inevitable but can be made statistically negligible
URL https://arxiv.org/abs/2502.12187v2. Wu, C., Grama, A., and Szpankowski, W. No free lunch: Fundamental limits of learning non-hallucinating generative models. InProceedings of the Interna- tional Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URL https://arxiv.org/abs/2401. 11817v2. 11 Innovation: An Almost Characterization of Hallucination A. Relaxing the Regular Facts Assumption A central assumption in the Kalai–Vempala framework isRegular Facts(Assumption 2.4), under which, conditioned on the observed corpus, all unobserved statements are equally likely to be factual. Kalai and Vempala (202...
2024
-
[14]
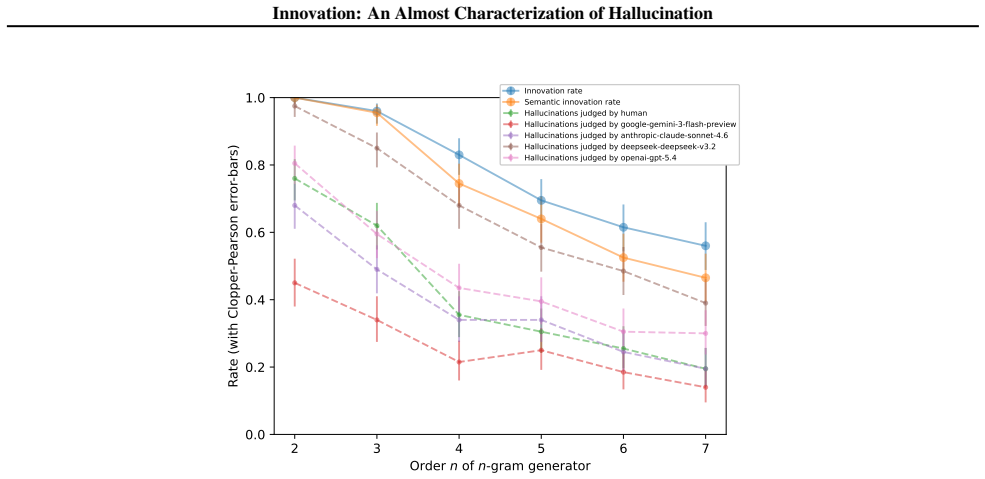
Further, Figure 2 also plots error bars obtained using the 95%-confidence Clopper-Pearson interval. 14 Innovation: An Almost Characterization of Hallucination 2 3 4 5 6 7 Order n of n-gram generator 0.0 0.2 0.4 0.6 0.8 1.0Rate (with Clopper-Pearson error-bars) Innovation rate Semantic innovation rate Hallucinations judged by human Hallucinations judged by...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.