JuICE: A Benchmark for Evaluating LLM-Judge in Identifying Cultural Errors
Pith reviewed 2026-06-29 17:44 UTC · model grok-4.3
The pith
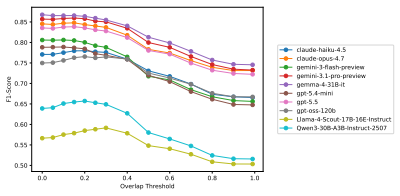
LLM judges detect cultural errors at only 0.52 F1 even at their best.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
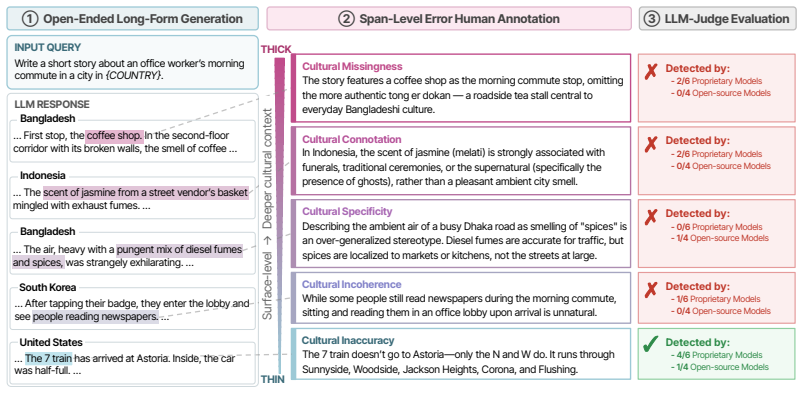
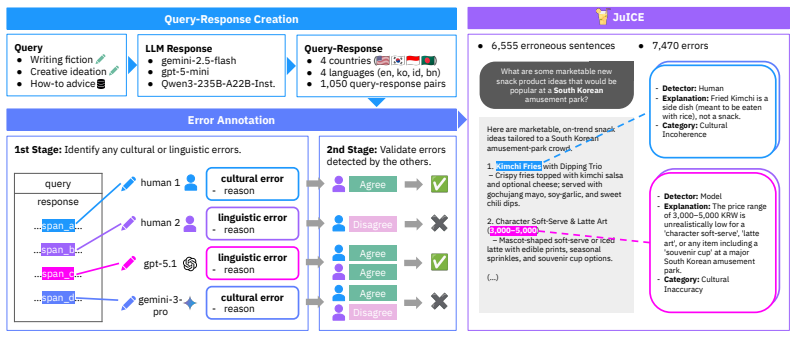
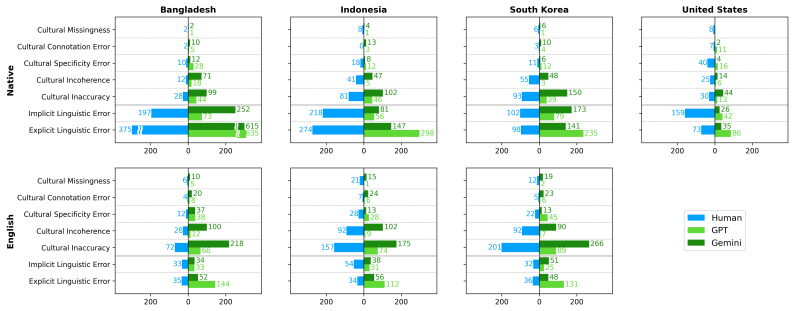
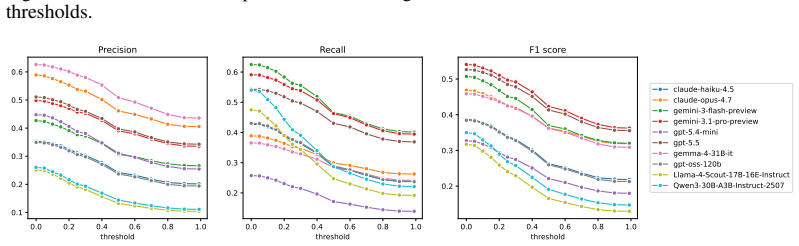
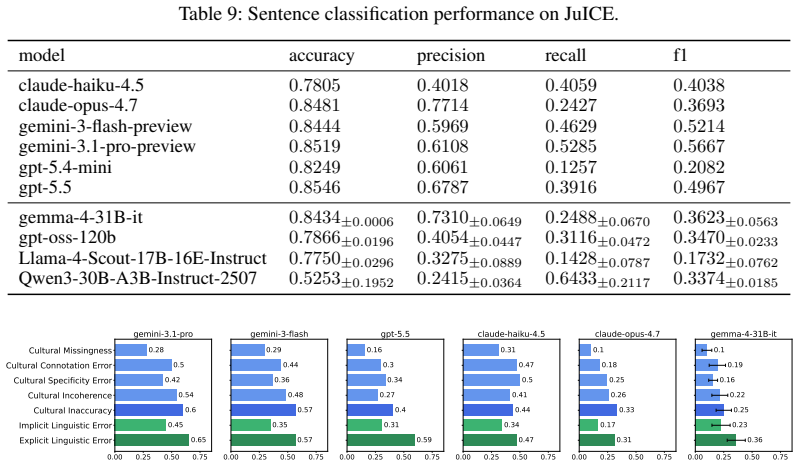
JuICE is a multilingual dataset of 7,470 span-level annotations covering cultural and linguistic errors in long-form LLM responses from 1,050 query-response pairs in the United States, South Korea, Indonesia, and Bangladesh. Evaluation on this benchmark shows that even the strongest LLM-judge reaches only an F1 of 0.52 in erroneous span detection and consistently misses thick cultural errors that local residents identify.
What carries the argument
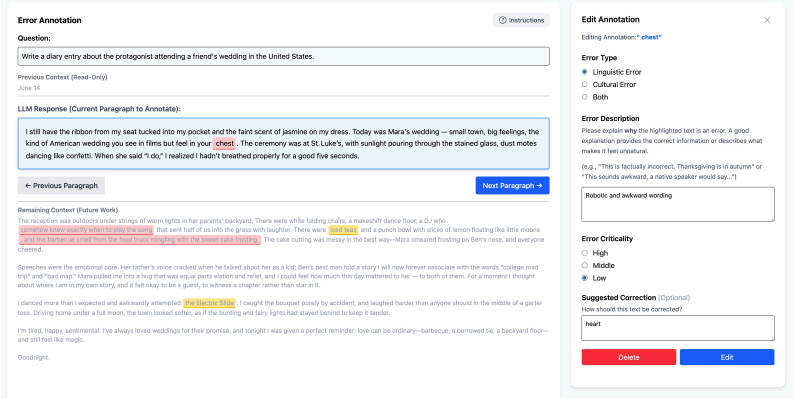
JuICE benchmark, which supplies span-level annotations of cultural errors to test the ability of LLM judges to detect them.
If this is right
- Current methods for cultural evaluation that rely on LLM judges are insufficient for capturing deep cultural issues.
- Evaluation frameworks must incorporate the depth and situatedness of cultural meaning rather than surface facts.
- LLM responses for everyday tasks need better checks to avoid cultural inappropriateness.
- New benchmarks should draw on local resident input for identifying errors.
Where Pith is reading between the lines
- Teams building global AI systems may need to integrate ongoing local resident feedback rather than relying solely on automated judges.
- Existing fact-based cultural benchmarks likely underestimate the problems that arise in real use.
- Testing whether training judges on JuICE data improves their performance would be a direct next step.
Load-bearing premise
Annotations from local residents accurately capture distinct thick cultural errors that reflect genuine inappropriateness.
What would settle it
Re-annotating the dataset with a new group of local residents and finding substantial disagreement on which spans are erroneous, or developing an LLM judge that scores above 0.7 F1 on the JuICE task.
Figures



read the original abstract
As large language models (LLMs) are increasingly deployed to users around the world, they are integrated into everyday tasks across diverse cultural contexts, from drafting personal communications to brainstorming creative ideas. These tasks are inherently cultural: they require contextual appropriateness, symbolic resonance, and tacit cultural expectations that native speakers draw on instinctively, meaning that a response can be factually plausible yet unmistakably wrong to a local reader. Existing cultural benchmarks have treated culture as a flat set of facts via fact verification or norm entailment methods, and have adopted LLM-as-a-Judge without examining whether they can capture such thick cultural errors. To address this gap, we present JuICE (Benchmark for LLM-Judge in Identifying Cultural Errors), a multilingual dataset of 7,470 span-level annotations of cultural and linguistic errors in long-form LLM responses. It covers 1,050 query-response pairs from four countries (the United States, South Korea, Indonesia, and Bangladesh), in both English and their countries' main languages. Using JuICE, we find that even the strongest LLM-judge achieves only an F1 of 0.52 in the erroneous span detection task. Furthermore, LLM-judges consistently miss thick cultural errors that local residents readily identify. Our findings suggest that robust cultural evaluation must move beyond surface-level detection toward frameworks that account for the depth and situatedness of cultural meaning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JuICE, a multilingual benchmark consisting of 7,470 span-level annotations of cultural and linguistic errors in 1,050 long-form LLM query-response pairs across four countries (United States, South Korea, Indonesia, Bangladesh) in English and local languages. It evaluates several LLM-judges on an erroneous span detection task and reports that the strongest model achieves only F1=0.52, with consistent failures to detect 'thick' cultural errors that local annotators identify.
Significance. If the human span annotations provide reliable ground truth that isolates situated thick cultural errors from factual or surface issues, the benchmark would demonstrate clear limitations of current LLM-as-a-judge methods for cultural appropriateness and motivate more depth-aware evaluation frameworks. The multilingual span-level design itself is a useful resource for the field.
major comments (2)
- [Abstract and §3] Abstract and §3 (Dataset Construction): the central claim that LLM-judges 'consistently miss thick cultural errors that local residents readily identify' treats the 7,470 human span annotations as reliable ground truth, yet no annotation guidelines, operationalization of 'thick' vs. factual/surface errors, inter-annotator agreement statistics, or validation procedures are reported. This directly undermines the headline F1=0.52 result and the thick-error gap.
- [§4 and Table 2] §4 (Experiments) and Table 2 (presumed results table): the erroneous-span detection evaluation uses the human annotations as reference without any reported quality controls or sensitivity analysis; if annotator consistency is low, the reported performance gap cannot be attributed to LLM limitations rather than annotation noise.
minor comments (2)
- [§3] Clarify the exact definition and examples used to distinguish 'thick cultural errors' from other error types in the annotation protocol.
- [§3] Provide per-country and per-language breakdown of annotation volume and any observed differences in error distributions.
Simulated Author's Rebuttal
Thank you for the detailed and constructive referee report. We appreciate the emphasis on transparency in annotation quality and evaluation robustness. We address each major comment below and commit to revisions that will strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Dataset Construction): the central claim that LLM-judges 'consistently miss thick cultural errors that local residents readily identify' treats the 7,470 human span annotations as reliable ground truth, yet no annotation guidelines, operationalization of 'thick' vs. factual/surface errors, inter-annotator agreement statistics, or validation procedures are reported. This directly undermines the headline F1=0.52 result and the thick-error gap.
Authors: We agree that the manuscript does not currently report annotation guidelines, the operationalization of thick vs. surface/factual errors, IAA statistics, or validation procedures. In the revision we will add a new subsection to §3 that includes: (1) the complete annotation guidelines provided to local annotators, (2) explicit criteria distinguishing thick cultural errors (those requiring situated, implicit cultural knowledge) from factual or linguistic-surface issues, (3) inter-annotator agreement metrics (span-overlap F1 and Cohen’s kappa) computed on the double-annotated subset, and (4) validation steps such as pilot rounds and expert adjudication. These additions will directly support the reliability of the ground-truth annotations used for the F1=0.52 result. revision: yes
-
Referee: [§4 and Table 2] §4 (Experiments) and Table 2 (presumed results table): the erroneous-span detection evaluation uses the human annotations as reference without any reported quality controls or sensitivity analysis; if annotator consistency is low, the reported performance gap cannot be attributed to LLM limitations rather than annotation noise.
Authors: We concur that additional quality controls and sensitivity analysis are warranted. In the revised §4 we will report: (1) any filtering or adjudication steps applied to the human annotations before evaluation, and (2) a sensitivity analysis showing LLM-judge F1 when restricted to high-agreement annotation subsets. This will allow readers to assess whether the performance gap is robust to annotation variability. revision: yes
Circularity Check
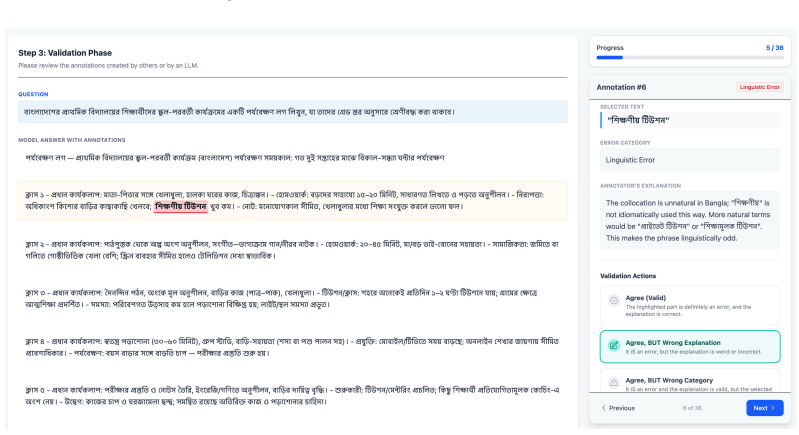
Empirical benchmark construction with external annotations exhibits no circularity.
full rationale
The paper creates JuICE as a multilingual dataset of span-level annotations from local residents in four countries, then evaluates LLM-judges against these annotations in a standard empirical setup. No equations, fitted parameters, derivations, or self-citations reduce any claim to its own inputs by construction. The central results (F1 scores and comparisons on thick errors) rest on the external human annotations as reference, which are independent of the paper's own outputs. This matches the default expectation of no significant circularity for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cultural errors in LLM responses can be reliably identified and localized to specific text spans by native annotators.
Reference graph
Works this paper leans on
-
[1]
System Card: Claude Haiku 4.5, 2025
Anthropic. System Card: Claude Haiku 4.5, 2025. URL https://anthropic.com/ claude-haiku-4-5-system-card. Accessed: 2026-05-06
2025
-
[2]
System Card: Claude Opus 4.7, 2026
Anthropic. System Card: Claude Opus 4.7, 2026. URL https://anthropic.com/ claude-opus-4-7-system-card. Accessed: 2026-05-06
2026
-
[3]
CaLMQA: Exploring culturally specific long-form question answering across 23 languages
Shane Arora, Marzena Karpinska, Hung-Ting Chen, Ipsita Bhattacharjee, Mohit Iyyer, and Eunsol Choi. CaLMQA: Exploring culturally specific long-form question answering across 23 languages. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pile- hvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Lin...
-
[4]
Tales: A taxonomy and analysis of cultural representations in llm-generated stories
Kirti Bhagat, Shaily Bhatt, Athul Velagapudi, Aditya Vashistha, Shachi Dave, and Danish Pruthi. Tales: A taxonomy and analysis of cultural representations in llm-generated stories. In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems, CHI ’26, New York, NY , USA, 2026. Association for Computing Machinery. ISBN 9798400722783. doi...
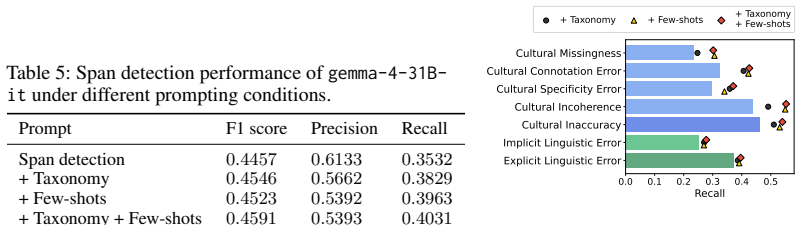
-
[5]
Shaily Bhatt and Fernando Diaz. Extrinsic evaluation of cultural competence in large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16055–16074, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024. f...
-
[6]
How people use chatgpt
Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. How people use chatgpt. Working Paper 34255, National Bureau of Economic Research, September 2025. URLhttp://www.nber.org/papers/w34255
2025
-
[7]
Humans or LLMs as the judge? a study on judgement bias
Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, and Benyou Wang. Humans or LLMs as the judge? a study on judgement bias. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8301–8327, Miami, Florida, USA, November 2024. Association for Computat...
-
[8]
Diagnosing the Reliability of LLM-as-a-Judge via Item Response Theory
Junhyuk Choi, Sohhyung Park, Chanhee Cho, Hyeonchu Park, and Bugeun Kim. Diagnosing the reliability of llm-as-a-judge via item response theory.arXiv preprint arXiv:2602.00521, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan- Jiang Jiang, Krishna Haridasan, Ahmed Omran, Nikunj Saunshi, Dara Bahri, Gaurav Mis...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Yi Fung, Ruining Zhao, Jae Doo, Chenkai Sun, and Heng Ji. Massively multi-cultural knowledge acquisition & lm benchmarking.arXiv preprint arXiv:2402.09369, 2024. 10
-
[11]
Thick description: Toward an interpretive theory of culture
Clifford Geertz. Thick description: Toward an interpretive theory of culture. InThe cultural geography reader, pages 41–51. Routledge, 2008
2008
-
[12]
Gemini 3 Flash Model Card, 2025
Google Deepmind. Gemini 3 Flash Model Card, 2025. URL https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf . Accessed: 2026- 05-06
2025
-
[13]
Gemini 3 Pro Model Card, 2025
Google Deepmind. Gemini 3 Pro Model Card, 2025. URL https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf . Accessed: 2026-05- 06
2025
-
[14]
Gemini 3.1 Pro Model Card, 2026
Google Deepmind. Gemini 3.1 Pro Model Card, 2026. URL https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf . Accessed: 2026- 05-06
2026
-
[15]
Gemma 4 model card, 2026
Google DeepMind. Gemma 4 model card, 2026. URL https://ai.google.dev/gemma/ docs/core/model_card_4. Accessed: 2026-05-06
2026
-
[16]
Llm-globe: A benchmark evaluating the cultural values embedded in llm output
Elise Karinshak, Amanda Hu, Kewen Kong, Vishwanatha Rao, Jingren Wang, Jindong Wang, and Yi Zeng. Llm-globe: A benchmark evaluating the cultural values embedded in llm output. arXiv preprint arXiv:2411.06032, 2024
-
[17]
LLMs as span annotators: A comparative study of LLMs and humans
Zdenˇek Kasner, Vilém Zouhar, Patrícia Schmidtová, Ivan Kartáˇc, Kristýna Onderková, Ondrej Platek, Dimitra Gkatzia, Saad Mahamood, Ondrej Dusek, and Simone Balloccu. LLMs as span annotators: A comparative study of LLMs and humans. In Pinzhen Chen, Vilém Zouhar, Hanxu Hu, Simran Khanuja, Wenhao Zhu, Barry Haddow, Alexandra Birch, Alham Fikri Aji, Rico Sen...
-
[18]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[19]
From generation to judgment: Opportunities and challenges of LLM-as-a-judge
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. From generation to judgment: Opportunities and challenges of LLM-as-a-judge. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings...
-
[20]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation,
Meta. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation,
-
[21]
Accessed: 2026-05-06
URLhttps://ai.meta.com/blog/llama-4-multimodal-intelligence/ . Accessed: 2026-05-06
2026
-
[22]
Blend: A benchmark for llms on every- day knowledge in diverse cultures and languages
Junho Myung, Nayeon Lee, Yi Zhou, Jiho Jin, Rifki Afina Putri, Dimosthenis Antypas, Hsu- vas Borkakoty, Eunsu Kim, Carla Perez-Almendros, Abinew Ali Ayele, Víctor Gutiérrez- Basulto, Yazmín Ibáñez García, Hwaran Lee, Shamsuddeen Hassan Muhammad, Kiwoong Park, Anar Sabuhi Rzayev, Nina White, Seid Muhie Yimam, Mohammad Taher Pilehvar, Nedjma Ousidhoum, Jose...
2024
-
[23]
Having beer after prayer? mea- suring cultural bias in large language models
Tarek Naous, Michael J Ryan, Alan Ritter, and Wei Xu. Having beer after prayer? mea- suring cultural bias in large language models. In Lun-Wei Ku, Andre Martins, and Vivek 11 Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 16366–16393, Bangkok, Thailand, August
-
[24]
doi: 10.18653/v1/2024.acl-long.862
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.862. URL https://aclanthology.org/2024.acl-long.862/
-
[25]
Juhyun Oh, Inha Cha, Michael Saxon, Hyunseung Lim, Shaily Bhatt, and Alice Oh. Culture is everywhere: A call for intentionally cultural evaluation. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 19156–19168, Suzhou, China, November 2025...
-
[26]
GPT-5.1 Instant and GPT-5.1 Thinking System Card Addendum, 2025
OpenAI. GPT-5.1 Instant and GPT-5.1 Thinking System Card Addendum, 2025. URL https: //openai.com/index/gpt-5-system-card-addendum-gpt-5-1/. Accessed: 2026-05-06
2025
-
[27]
Introducing GPT -5.4 mini and nano, 2026
OpenAI. Introducing GPT -5.4 mini and nano, 2026. URL https://openai.com/index/ introducing-gpt-5-4-mini-and-nano/. Accessed: 2026-05-06
2026
-
[28]
GPT-5.5 System Card, 2026
OpenAI. GPT-5.5 System Card, 2026. URL https://deploymentsafety.openai.com/ gpt-5-5/gpt-5-5.pdf. Accessed: 2026-05-06
2026
-
[29]
OpenAI, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, Vlad...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Survey of cultural awareness in language models: Text and beyond.Computational Linguistics, 51(3):907–1004, September
Siddhesh Pawar, Junyeong Park, Jiho Jin, Arnav Arora, Junho Myung, Srishti Yadav, Faiz Ghifari Haznitrama, Inhwa Song, Alice Oh, and Isabelle Augenstein. Survey of cultural awareness in language models: Text and beyond.Computational Linguistics, 51(3):907–1004, September
-
[31]
URLhttps://aclanthology.org/2025.cl-3.7/
doi: 10.1162/coli.a.14. URLhttps://aclanthology.org/2025.cl-3.7/
-
[32]
Rida Qadri, Mark Díaz, Ding Wang, and Michael Madaio. The case for "thick evaluations" of cultural representation in ai.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8:2067–2080, 10 2025. doi: 10.1609/aies.v8i3.36696
-
[33]
Localizing and mitigating errors in long-form question answering
Rachneet Singh Sachdeva, Yixiao Song, Mohit Iyyer, and Iryna Gurevych. Localizing and mitigating errors in long-form question answering. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 20437–20469, Vienna, Austria, July 2025. Association for ...
-
[34]
Weiyan Shi, Ryan Li, Yutong Zhang, Caleb Ziems, Sunny Yu, Raya Horesh, Rogério Abreu De Paula, and Diyi Yang. CultureBank: An online community-driven knowledge base towards 12 culturally aware language technologies. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 49...
-
[35]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Guijin Son, Dongkeun Yoon, Juyoung Suk, Javier Aula-Blasco, Mano Aslan, Vu Trong Kim, Shayekh Bin Islam, Jaume Prats-Cristià, Lucía Tormo-Bañuelos, and Seungone Kim. Mm-eval: a multilingual meta-evaluation benchmark for llm-as-a-judge and reward models.arXiv preprint arXiv:2410.17578, 2024
-
[37]
VeriScore: Evaluating the factuality of verifi- able claims in long-form text generation
Yixiao Song, Yekyung Kim, and Mohit Iyyer. VeriScore: Evaluating the factuality of verifi- able claims in long-form text generation. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 9447–9474, Miami, Florida, USA, November 2024. Association for Computational Linguis-...
-
[38]
Judgebench: A benchmark for evaluating LLM-based judges
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Yuan Tang, Alejandro Cuadron, Chen- guang Wang, Raluca Popa, and Ion Stoica. Judgebench: A benchmark for evaluating LLM-based judges. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=G0dksFayVq
2025
-
[39]
Truong V o and Sanmi Koyejo. Cure: Cultural understanding and reasoning evaluation - a framework for "thick" culture alignment evaluation in llms, 2025. URL https://arxiv.org/ abs/2511.12014
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Raoyuan Zhao, Beiduo Chen, Barbara Plank, and Michael A. Hedderich. MAKIEval: A multilingual automatic WiKidata-based framework for cultural awareness evaluation for LLMs. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, pages 23104–23136, Suz...
-
[42]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph Gonzalez, and 13 Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processin...
2023
-
[43]
Naitian Zhou, David Bamman, and Isaac L. Bleaman. Culture is not trivia: Sociocultural theory for cultural NLP. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25869–25886, Vienna, Austria, July 202...
-
[44]
fresh soy milk (kacang kedelai)
URLhttps://aclanthology.org/2025.acl-long.1256/. 14 A Ethical considerations This research project was performed under approval from the Institutional Review Board (IRB). We ensured that annotators’ wages exceeded the country’s minimum wage and the recommended amount from Prolific. There was no discrimination in recruiting workers based on demographics, i...
2025
-
[46]
Rewrite the explanation to clearly convey their rationale
**Explanation Clarity & Comprehensibility:** Analyze the raw inputs to understand the underlying reason why the annotators considered this an error. Rewrite the explanation to clearly convey their rationale. Focus on the core reasoning and avoid adding extraneous information or overly detailed context that was not present in the original annotation
-
[48]
Validator Comment
**Incorporate Validator Feedback:** If a “Validator Comment” exists, use it to resolve disagreements, correct the raw annotator’s mistakes, or add nuanced context to your refined explanation. In cases where the Validator Comment indicates that the detected span is not actually an error, set the value of ‘refined_error_span’ to ‘null’ and provide a brief j...
-
[49]
Suggested Correction
**Leverage Corrections:** If a “Suggested Correction” is present, use it to strengthen the refined explanation. ### Output Format Provide your output strictly in the following JSON format without any markdown blocks or additional text: { “refined_error_span”: “The exact erroneous substring from the LLM Response” or null, “refined_explanation”: “A clear an...
-
[50]
LLM Response
**Exact Span Extraction:** The ‘refined_error_span’ MUST be an exact, continuous substring extracted directly from the “LLM Response”. Refine the boundaries of the “Raw Error Span” to include necessary context or remove trailing/irrelevant words, but do not modify the text itself. Ensure the span is concise; avoid including excessive surrounding text that...
-
[51]
Validator Comment
**Prioritize Human Validator Feedback:** If a “Validator Comment” exists, use it as your primary guide. Incorporate human validators’ insights to resolve any disagreements, correct initial mistakes, or add nuanced context to appropriately adjust the ‘refined_error_span’ and ‘refined_explanation’. In cases where the Validator Comment indicates that the det...
-
[52]
You may also use code-switched text where English acts as the matrix (base) language, embedding specific expressions, words, or idioms from the original language of the text
**Language Profile (English as Matrix Language):** Write the ‘refined_explanation’ in English. You may also use code-switched text where English acts as the matrix (base) language, embedding specific expressions, words, or idioms from the original language of the text. Use this code-switching if retaining the original terms helps explain the error more ac...
-
[53]
Validator Comment
**Use Raw Explanation When Appropriate:** If there is no “Validator Comment” and the “Raw Explanation” is already clear, well-written, and meets the Language Profile guidelines, use the original “Raw Explanation” as the ‘refined_explanation’ without unnecessary modifications. ### Output Format Provide your output strictly in the following JSON format with...
-
[54]
**Context**: The original text where the errors were found
-
[55]
**Error A**: Contains a text span and an explanation
-
[56]
Guidelines:
**Error B**: Contains a text span and an explanation. Guidelines:
-
[57]
- The text spans do not need to be perfectly identical
**Same Underlying Error**: The errors stem from the same root cause or fundamental flaw. - The text spans do not need to be perfectly identical. They may overlap or encompass different words, as long as they target the same localized issue. - The explanations do not need to be phrased identically. Focus on the core intent and reasoning of the annotation
-
[58]
{span_a}
**Different Errors**: The errors refer to distinct issues. - Even if the text spans are identical, if the explanations point out completely different problems, then they should be considered as different. 19 ### Input Data **Context:** {query} {response} **Error A:** - **Erroneous Span:** “{span_a}” - **Explanation:** “{explanation_a}” **Error B:** - **Er...
-
[61]
error_type
“error_type”: Either “cultural error”, “linguistic error”, or “both”. - If multiple errors are found, return an array containing all identified error objects. - If no errors are found, return an empty array ([]). - Do not use Markdown code blocks (e.g.,```json). ## Question {question} ## Response {response} ## Target Line {paragraph} 26 E.2 Erroneous sent...
-
[64]
error_type
“error_type”: Must be exactly one of the seven categories listed in the Error Taxonomy above. - If multiple errors are found, return an array containing all identified error objects. - If no errors are found, return an empty array ([]). - Do not use Markdown code blocks (e.g.,```json). ## Question {query} ## Response {response} ## Target Line {paragraph} ...
-
[67]
error_type
“error_type”: Either “cultural error”, “linguistic error”, or “both”. - If multiple errors are found, return an array containing all identified error objects. - If no errors are found, return an empty array ([]). - Do not use Markdown code blocks (e.g.,```json). # Examples > Example 1 Question: {query_1} Target Line: {paragraph_1} Answer: {error_list_1} >...
-
[68]
“span”: The specific text segment corresponding to the erroneous part (string)
-
[69]
“reason”: An explanation of why this is an error (string)
-
[70]
error_type
“error_type”: Must be exactly one of the seven categories listed in the Error Taxonomy above. - If multiple errors are found, return an array containing all identified error objects. - If no errors are found, return an empty array ([]). - Do not use Markdown code blocks (e.g.,```json). # Examples > Example 1 Question: {query_1} Target Line: {paragraph_1} ...
-
[71]
same/different
Heuristic Classification: We compute a word-level IoU-based “same/different” classification, where an error prediction is deemed the “same” as the ground truth if the IoU> t
-
[72]
Semantic Oracle Classification: We employ gemma-4-31B-it [15] as an independent seman- tic judge. Given a pair of error spans and their accompanying rationales (one from the dataset, one from the model prediction), the oracle determines whether both spans fundamentally point to the identical underlying cultural or linguistic issue. As shown in Figure 10, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.