Tracing Computation Density in LLMs
Pith reviewed 2026-06-29 18:17 UTC · model grok-4.3
The pith
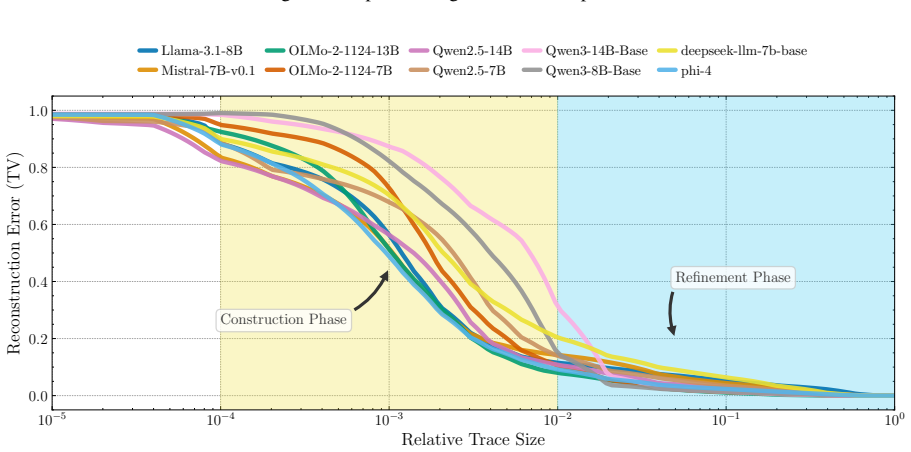
Computation in LLMs splits into an early sparse core that captures the main output and later layers that refine it incrementally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
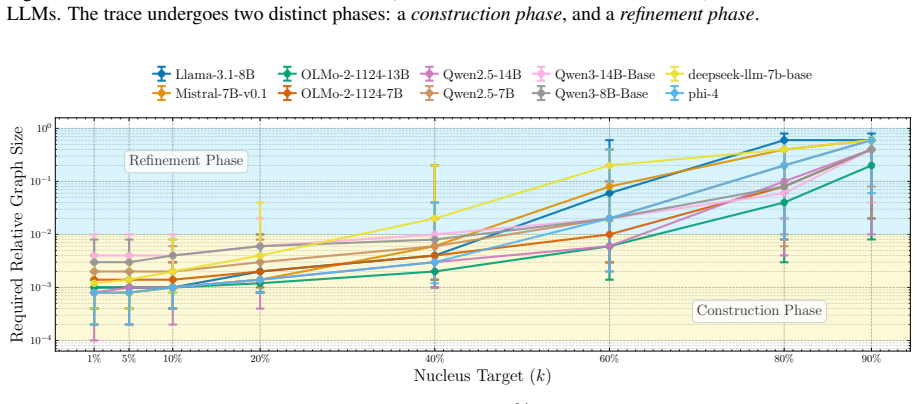
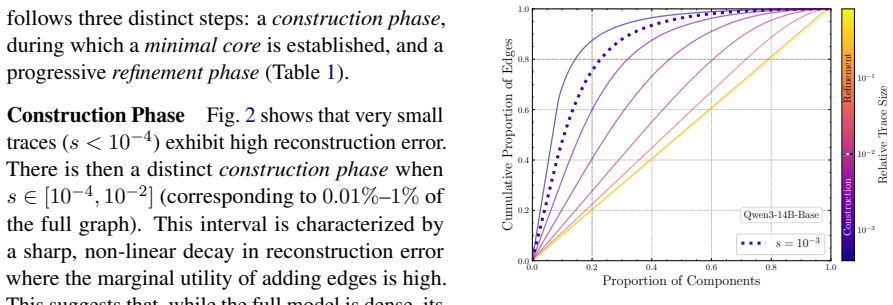
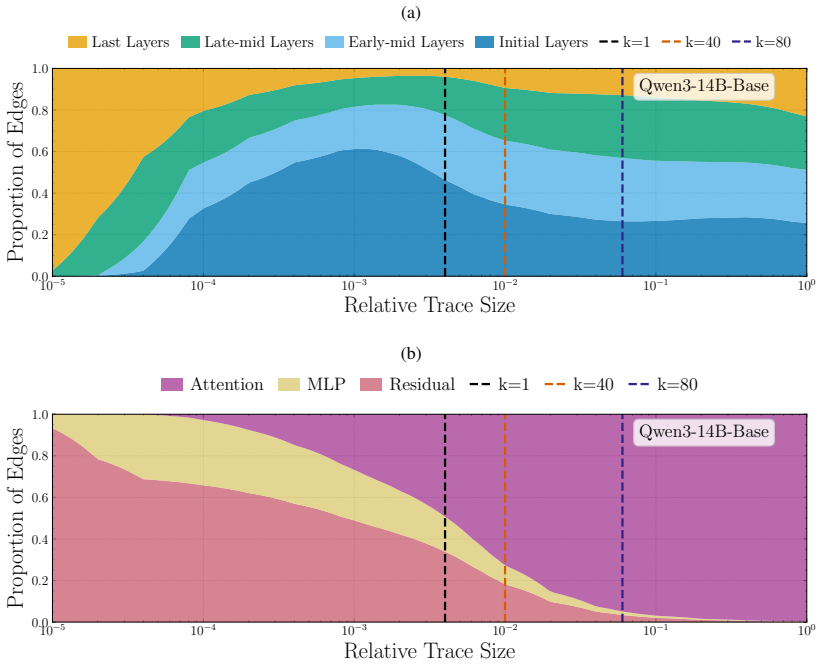
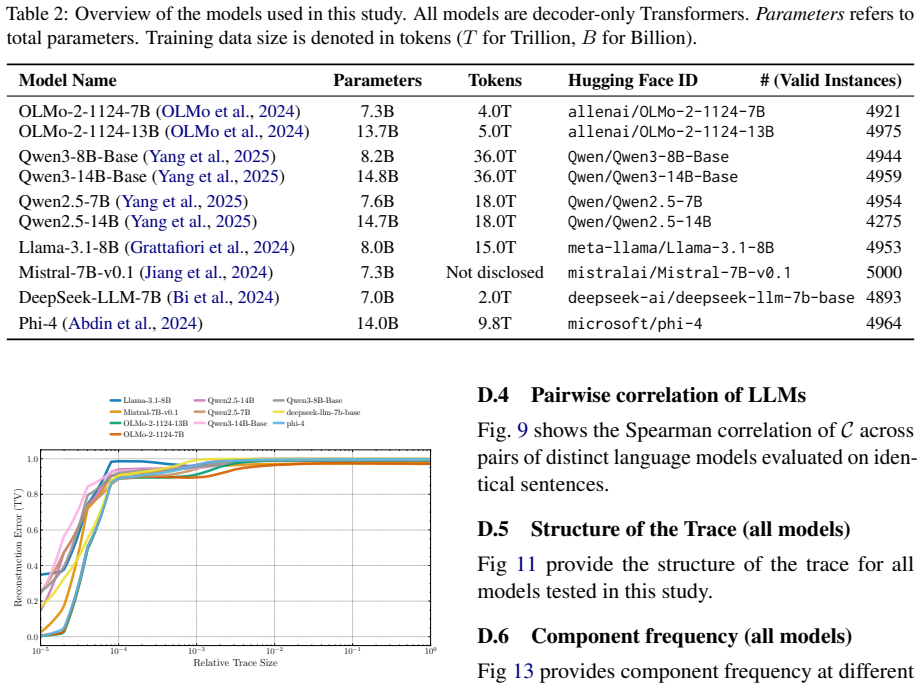
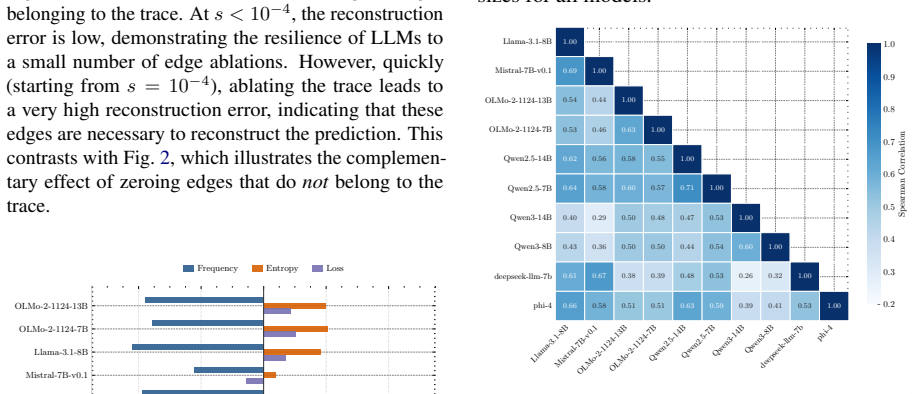
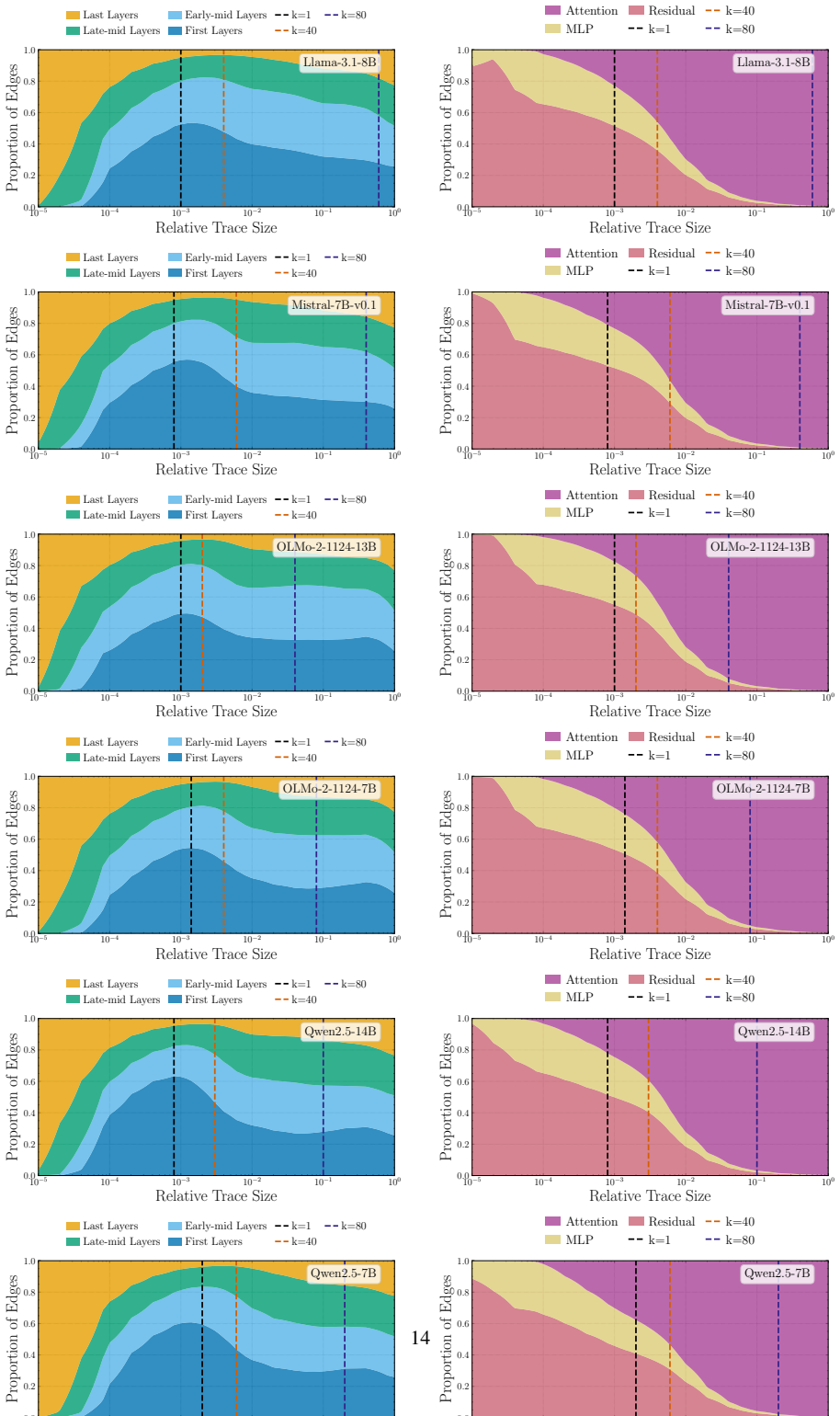
We introduce the s-Trace method to efficiently estimate the subgraph of size s that best approximates a full model output. With this method, we find the computation in a variety of LLMs to be organized in two distinct phases. A small subgraph mostly composed of early-layer nodes can reconstruct the head of the full model output distribution. Adding further nodes, mostly located in later layers and increasingly consisting of attention heads, leads to incremental refinements in approximating the full output distribution. We find moreover that the amount of necessary computation per input correlates with model uncertainty, and that sparser subgraphs encode shallow statistics, such as unigram fr
What carries the argument
s-Trace method, which finds the size-s subgraph whose output distribution most closely matches the full LLM
If this is right
- The nodes required to approximate the output increase with model uncertainty on the input.
- Sparser subgraphs primarily capture shallow statistics such as unigram frequency.
- Early layers supply a rough prediction of the output head; later layers add successive refinements.
- A consistent modular structure appears across different LLMs rather than input-specific full-graph use.
Where Pith is reading between the lines
- Input-dependent pruning that stops after the early core on low-uncertainty cases could reduce average inference cost.
- The separation into core and refinement phases offers a route to layer-wise interpretability focused on when predictions stabilize.
- The same tracing approach could be tested on non-transformer architectures to check whether the two-phase pattern is architecture-specific.
- If the early core aligns with simple frequency-based predictions, targeted interventions there might alter base behavior without touching refinement layers.
Load-bearing premise
The s-Trace search procedure identifies the subgraph that truly best approximates the full model output rather than an artifact of the approximation algorithm.
What would settle it
Finding that the highest-scoring subgraphs of increasing size are distributed uniformly across layers instead of clustering early then shifting later would falsify the two-phase claim.
Figures



read the original abstract
Transformer-based large language models (LLMs) are comprised of billions of parameters arranged in deep and wide computational graphs, but it is not clear that they exploit their full capacity for all inputs. We introduce the s-Trace method to efficiently estimate the subgraph of size s that best approximates a full model output. With this method, we find the computation in a variety of LLMs to be organized in two distinct phases. A small subgraph mostly composed of early-layer nodes can reconstruct the head of the full model output distribution. Adding further nodes, mostly located in later layers and increasingly consisting of attention heads, leads to incremental refinements in approximating the full output distribution. We find moreover that the amount of necessary computation per input correlates with model uncertainty, and that sparser subgraphs encode shallow statistics, such as unigram frequency. Overall, our results suggest a consistent modular organization in effective LLM computation, with a sparse early-layer core providing a rough prediction that is further refined through denser computations in later layers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the s-Trace method to efficiently estimate the subgraph of size s that best approximates a full LLM output distribution. It claims that LLM computation is organized in two distinct phases: a small subgraph of mostly early-layer nodes reconstructs the head of the output distribution, while adding nodes (mostly later-layer attention heads) yields incremental refinements. Additional claims are that the amount of necessary computation per input correlates with model uncertainty and that sparser subgraphs encode shallow statistics such as unigram frequency.
Significance. If s-Trace is validated as recovering near-optimal subgraphs without systematic bias toward early layers, the findings would indicate a consistent modular organization in effective LLM computation, with a sparse early core for rough predictions refined by denser later computations. This could inform pruning, interpretability, and input-dependent computation allocation. The paper provides no machine-checked proofs or parameter-free derivations, so significance hinges on empirical validation of the core method.
major comments (3)
- [Abstract / s-Trace method] Abstract and s-Trace method description: the claim that s-Trace identifies the subgraph of size s that 'best approximates' the full output is load-bearing for all reported phases and correlations, yet the abstract supplies no information on validation, error metrics, or controls ruling out method-specific artifacts. The reader's weakest assumption (that s-Trace recovers near-optimal subgraphs) is therefore unaddressed.
- [Abstract] Abstract: the reported two-phase structure (early-layer core + later-layer refinement) could be induced by the approximation procedure itself if the heuristic preferentially selects early nodes for coarse approximations (e.g., via forward-pass marginal contribution or local gradients). No evidence is given that the observed layer and component composition reflects genuine computational organization rather than this ordering bias.
- [Abstract] Abstract: the additional claims (uncertainty correlation; sparser subgraphs encoding unigram frequency) inherit the same dependence on correct subgraph identification. Without controls showing that s-Trace does not systematically favor early-layer nodes, these correlations cannot be interpreted as evidence of modular organization.
minor comments (1)
- [Abstract] The abstract refers to 'a variety of LLMs' without specifying which models or providing quantitative details on subgraph sizes or approximation quality.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which highlight important points about the validation and potential artifacts of the s-Trace method. We respond to each major comment below, with plans to revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [Abstract / s-Trace method] Abstract and s-Trace method description: the claim that s-Trace identifies the subgraph of size s that 'best approximates' the full output is load-bearing for all reported phases and correlations, yet the abstract supplies no information on validation, error metrics, or controls ruling out method-specific artifacts. The reader's weakest assumption (that s-Trace recovers near-optimal subgraphs) is therefore unaddressed.
Authors: We agree that the abstract omits key details on validation. The manuscript body (Section 3) defines s-Trace via a greedy marginal-contribution heuristic and validates it empirically using KL divergence to the full distribution, top-k token overlap, and comparisons to random subgraphs plus exhaustive search on small models. We will revise the abstract to include a concise statement on these error metrics and controls. revision: yes
-
Referee: [Abstract] Abstract: the reported two-phase structure (early-layer core + later-layer refinement) could be induced by the approximation procedure itself if the heuristic preferentially selects early nodes for coarse approximations (e.g., via forward-pass marginal contribution or local gradients). No evidence is given that the observed layer and component composition reflects genuine computational organization rather than this ordering bias.
Authors: This is a substantive concern about heuristic bias. The full paper reports ablations in Section 5.3 that repeat the analysis with gradient-based node ranking and layer-stratified random selection; the early-layer core for small s and later-layer refinement for larger s remain consistent. We will add an explicit paragraph in the methods and discussion sections referencing these controls and will update the abstract accordingly. revision: yes
-
Referee: [Abstract] Abstract: the additional claims (uncertainty correlation; sparser subgraphs encoding unigram frequency) inherit the same dependence on correct subgraph identification. Without controls showing that s-Trace does not systematically favor early-layer nodes, these correlations cannot be interpreted as evidence of modular organization.
Authors: We accept that the uncertainty and unigram-frequency results depend on the reliability of the identified subgraphs. The robustness ablations noted above also cover these downstream analyses, showing the correlations persist under alternative selection procedures. We will revise the abstract to qualify these claims with reference to the validation and add a short robustness subsection. revision: partial
Circularity Check
No circularity; empirical findings from new method
full rationale
The paper introduces the s-Trace method as a novel procedure for estimating approximating subgraphs and then reports observational results on layer-wise organization, uncertainty correlation, and statistic encoding obtained by applying that method across models. No equations, definitions, or claims in the abstract reduce any reported phase, correlation, or subgraph property to a fitted parameter or self-citation by construction. The central claims remain independent empirical outputs of the introduced procedure rather than tautological restatements of its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of NeurIPS, volume 36, pages 16318–16352, New Orleans, LA
Towards automated circuit discovery for mech- anistic interpretability. InProceedings of NeurIPS, volume 36, pages 16318–16352, New Orleans, LA. Róbert Csordás, Christopher D Manning, and Chris Potts. 2026. Do language models use their depth effi- ciently?Advances in Neural Information Processing Systems, 38:160313–160362. Siqi Fan, Xin Jiang, Xiang Li, X...
-
[2]
How does gpt-2 compute greater-than?: In- terpreting mathematical abilities in a pre-trained lan- guage model.Advances in Neural Information Pro- cessing Systems, 36:76033–76060. Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text de- generation. InInternational Conference on Learning Representations. Ray J...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Residual networks behave like ensembles of relatively shallow networks.Advances in neural in- formation processing systems, 29. Elena V oita, Javier Ferrando, and Christoforos Nalmpan- tis. 2023. Neurons in large language models: Dead, n- gram, positional. https://arxiv.org/abs/2309. 04827. Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.