MiRD: Reliable Set-Valued Prediction for Open-Ended Question Answering via Miscoverage Risk Decomposition
Pith reviewed 2026-06-29 21:27 UTC · model grok-4.3
The pith
MiRD decomposes miscoverage into separate sampling and selection failures to produce reliable prediction sets for open-ended QA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
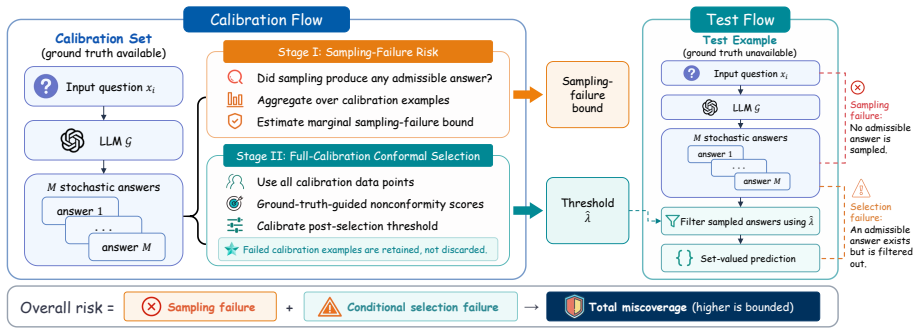
MiRD decomposes overall miscoverage into an expectation-level marginal upper bound on the probability that finite sampling produces no admissible answer under a fixed budget, and a conditional selection failure that is calibrated using admission-correlated nonconformity scores over the full calibration set, thereby preserving calibration-set integrity and exchangeability while controlling sampling risk, conditional selection risk, and overall miscoverage.
What carries the argument
Two-stage decomposition of overall miscoverage into sampling failure probability and conditional selection failure, with the second stage using admission-correlated nonconformity scores.
If this is right
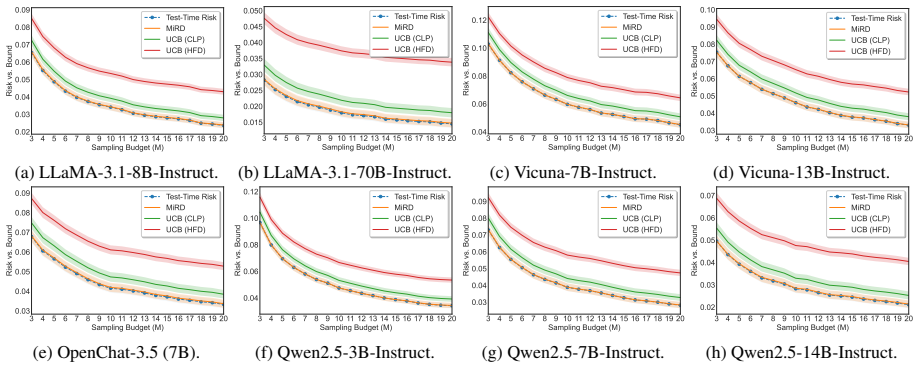
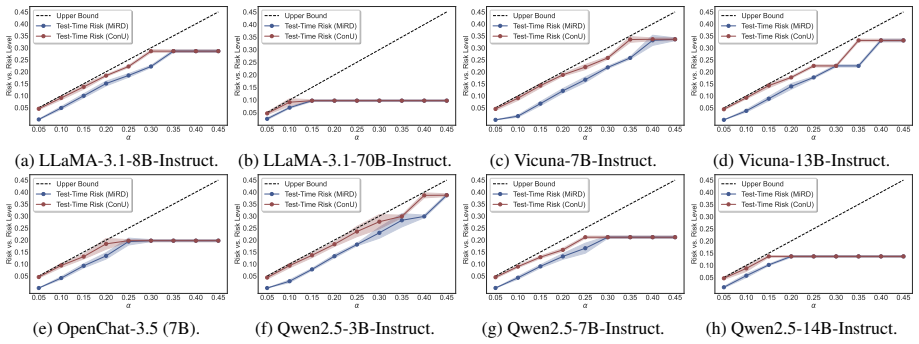
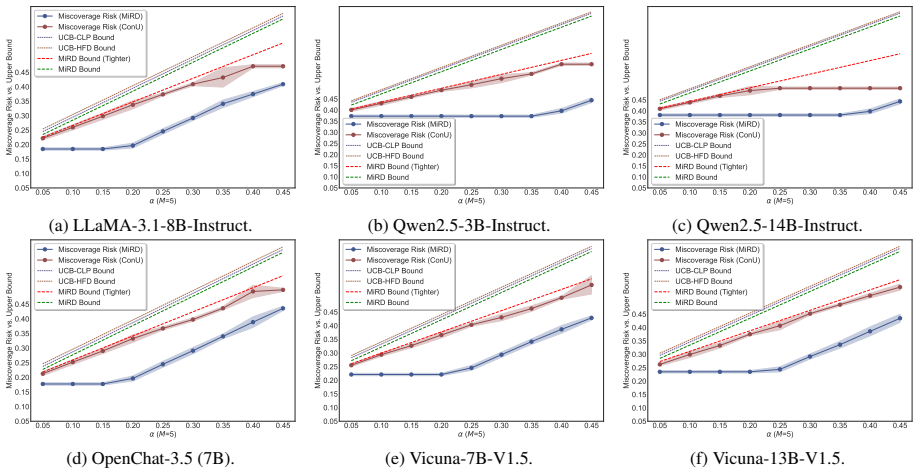
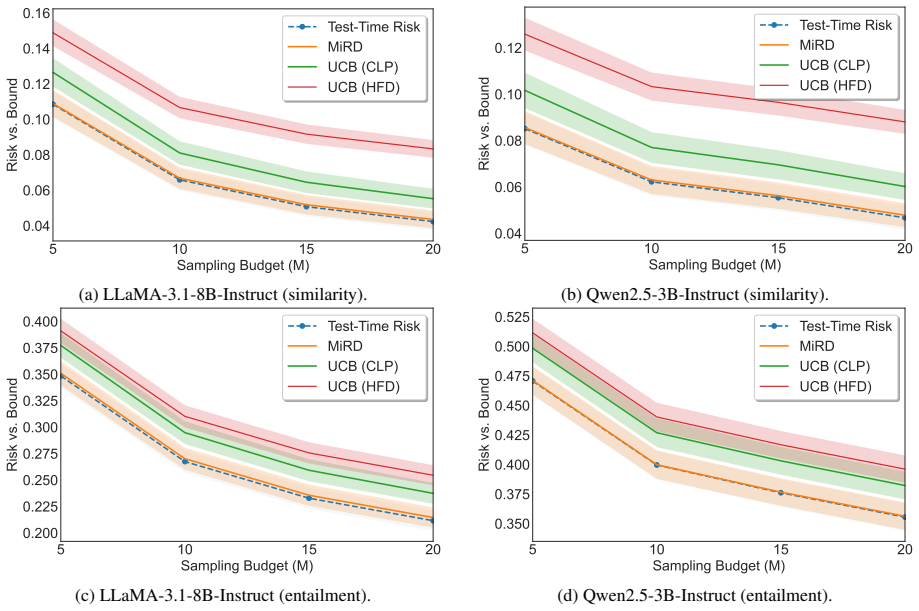
- MiRD controls sampling risk, conditional selection risk, and overall miscoverage simultaneously.
- It produces tighter first-stage bounds than PAC-style alternatives.
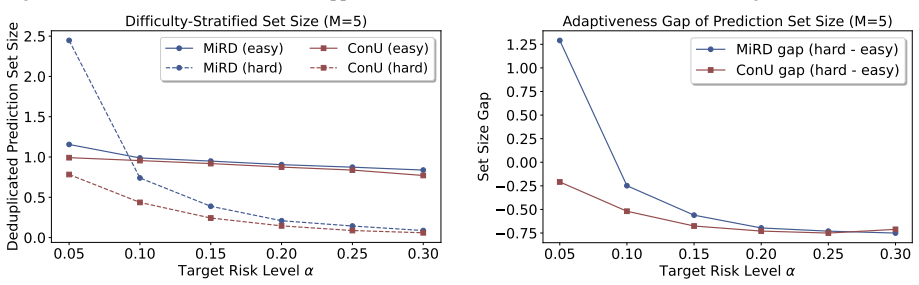
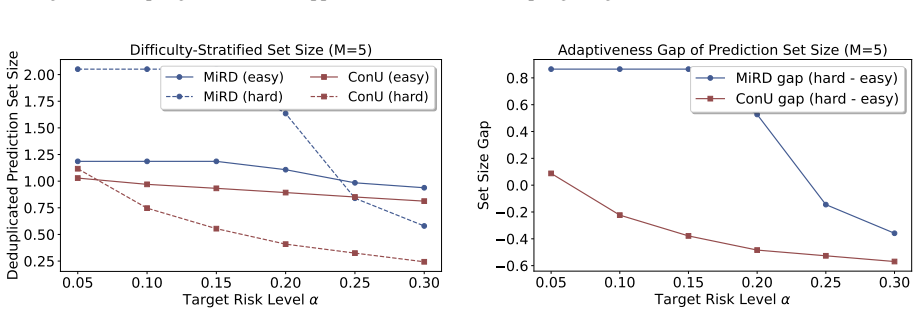
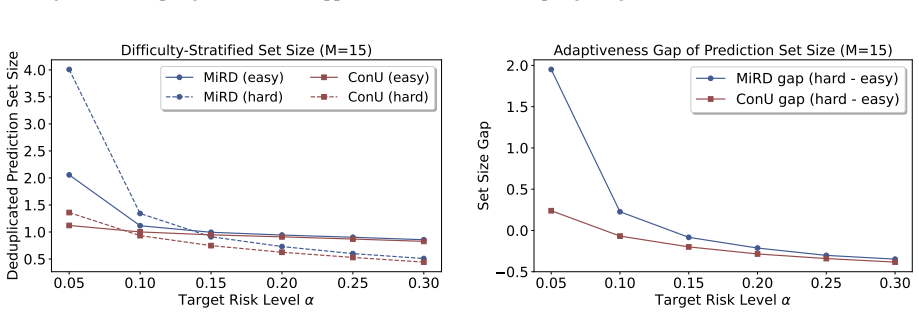
- It generates more adaptive prediction sets than successful-only calibration.
- The approach works across three open-ended QA datasets and eight models.
Where Pith is reading between the lines
- The decomposition could extend to other generative tasks where the sampler sometimes returns no valid output at all.
- Admission-correlated scores might be replaced by other task-specific features while retaining the same two-stage calibration logic.
- The method raises the question of how to choose the sampling budget to balance the two risk components in practice.
Load-bearing premise
The overall miscoverage can be decomposed into an expectation-level marginal bound on sampling failure probability and a conditional selection failure that can be calibrated independently using admission-correlated scores over the full calibration set without violating exchangeability or coverage guarantees.
What would settle it
Empirical measurement on held-out data showing that the realized overall miscoverage rate exceeds the sum of the stage-one sampling bound and the stage-two conditional selection bound when the fraction of calibration examples with no admissible answer is high.
Figures
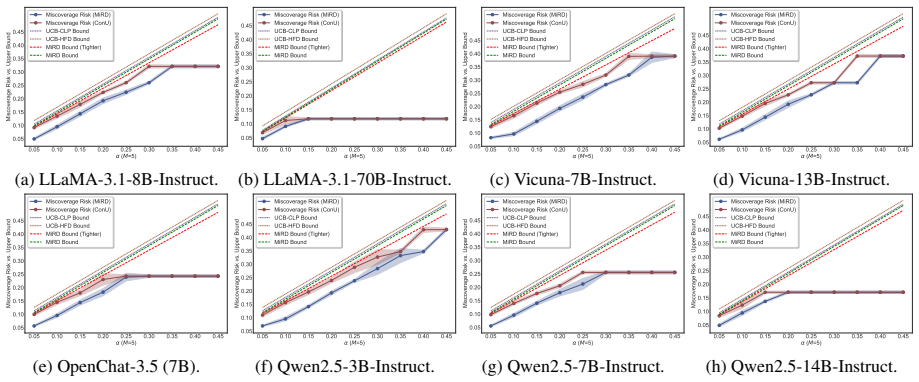
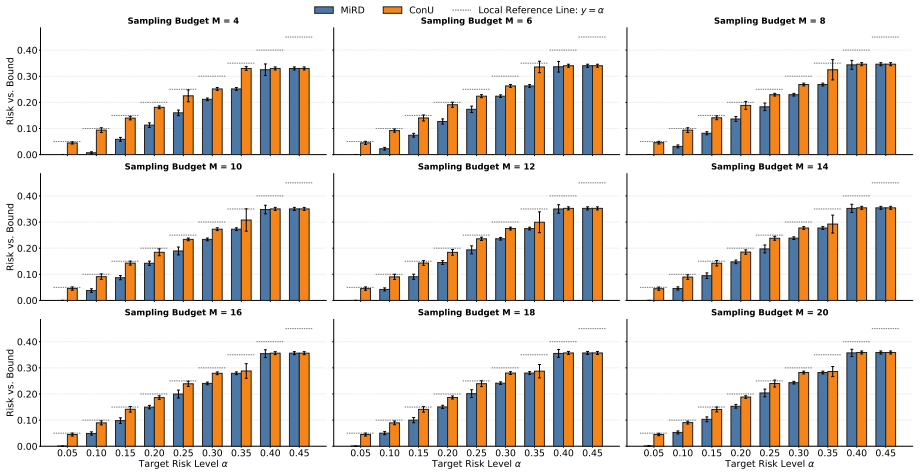
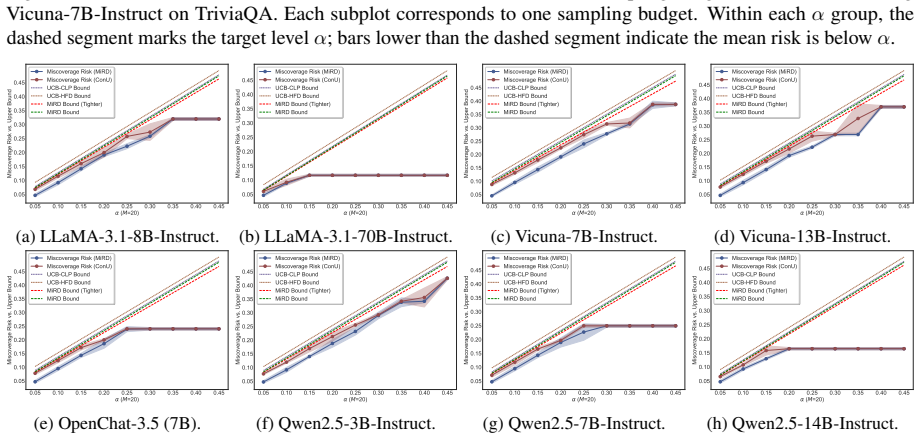
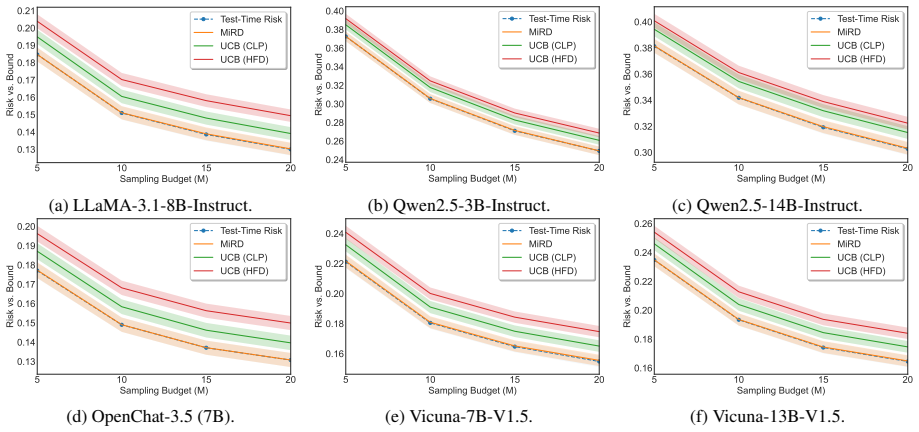
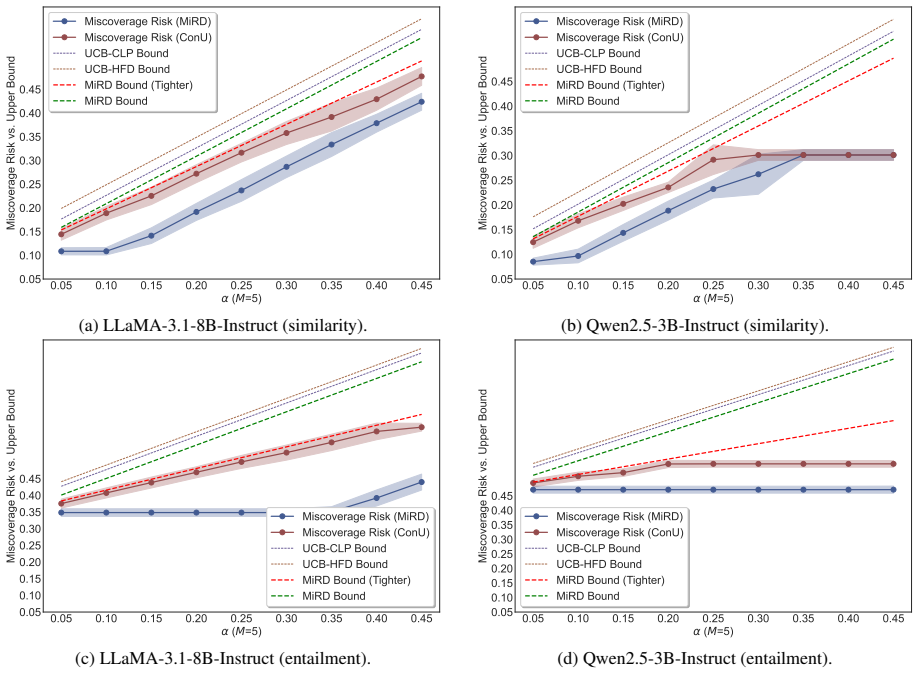
read the original abstract
Reliable set-valued prediction provides a principled way to mitigate hallucinations in open-ended question answering (QA), yet existing conformal approaches typically rely on a fragile premise: finite sampling must already produce at least one admissible candidate, or calibration examples violating this condition are discarded. In this paper, we introduce MiRD, a two-stage framework that decomposes overall miscoverage into sampling failure and conditional selection failure. In Stage I, MiRD establishes an expectation-level marginal upper bound on the probability that finite sampling produces no admissible answer under a fixed budget. In Stage II, conditioned on sampling success, MiRD calibrates a conformal selection threshold using admission-correlated nonconformity scores defined over the full calibration set, thereby preserving calibration-set integrity. Across three open-ended QA datasets and eight models, MiRD controls sampling risk, conditional selection risk, and overall miscoverage, while yielding tighter first-stage bounds than PAC-style alternatives and more adaptive prediction sets than successful-only calibration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MiRD, a two-stage framework for reliable set-valued prediction in open-ended QA. It decomposes overall miscoverage risk into a sampling failure component (Stage I: an expectation-level marginal upper bound on the probability that finite sampling yields no admissible answer) and a conditional selection failure component (Stage II: conformal calibration of a selection threshold using admission-correlated nonconformity scores over the full calibration set). The method claims to control sampling risk, conditional selection risk, and overall miscoverage while producing tighter first-stage bounds than PAC-style methods and more adaptive prediction sets than successful-only calibration, with empirical support across three QA datasets and eight models.
Significance. If the risk decomposition and calibration procedure are valid, the approach would enable reliable prediction sets in open-ended QA without discarding calibration examples that fail the sampling condition, addressing a practical limitation of prior conformal methods. The explicit separation of sampling and selection risks, combined with the use of the full calibration set, could yield more efficient and adaptive sets if the exchangeability argument holds.
major comments (2)
- [§3.2] §3.2 (Stage II calibration): The argument that calibrating the selection threshold on admission-correlated nonconformity scores over the full calibration set (including sampling failures) preserves validity when the threshold is applied only to test points conditioned on sampling success requires an explicit proof. The current text appears to rely on the claim that this 'preserves calibration-set integrity' without deriving that the conditional score distribution remains exchangeable with the mixed calibration scores; this is load-bearing for the overall miscoverage control guarantee.
- [Theorem 2] Theorem 2 (or equivalent expectation-level bound in Stage I): The manuscript states that the overall miscoverage decomposes into an expectation-level marginal bound on sampling failure and an independent conditional selection failure, but without the full derivation it is unclear whether the bound accounts for the dependence introduced by conditioning or whether the decomposition is exact at the finite-sample level.
minor comments (2)
- [§5] The experimental section should report the exact fraction of calibration examples discarded by the successful-only baseline for each dataset/model to allow direct comparison of adaptivity gains.
- [§3.1] Notation for the admission-correlated nonconformity score (e.g., Eq. (X)) should explicitly define how the score is computed for points that fail sampling, as this is central to the full-set calibration claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying points where the theoretical arguments in the manuscript require additional rigor. We address each major comment below and will incorporate the necessary clarifications and proofs in the revised version.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Stage II calibration): The argument that calibrating the selection threshold on admission-correlated nonconformity scores over the full calibration set (including sampling failures) preserves validity when the threshold is applied only to test points conditioned on sampling success requires an explicit proof. The current text appears to rely on the claim that this 'preserves calibration-set integrity' without deriving that the conditional score distribution remains exchangeable with the mixed calibration scores; this is load-bearing for the overall miscoverage control guarantee.
Authors: We agree that an explicit derivation is required. The manuscript currently states that using the full calibration set for score computation preserves integrity while conditioning occurs only at test time, but does not supply the supporting exchangeability argument. In the revision we will insert a new lemma immediately following the Stage II description that proves the relevant nonconformity scores remain exchangeable under the conditional law: because the admission correlation is a fixed function of the model output and the calibration scores are computed identically for all examples, the rank of a test score (conditioned on sampling success) among the mixed calibration scores yields a valid p-value for the conditional selection risk. This will make the overall miscoverage bound rigorous. revision: yes
-
Referee: [Theorem 2] Theorem 2 (or equivalent expectation-level bound in Stage I): The manuscript states that the overall miscoverage decomposes into an expectation-level marginal bound on sampling failure and an independent conditional selection failure, but without the full derivation it is unclear whether the bound accounts for the dependence introduced by conditioning or whether the decomposition is exact at the finite-sample level.
Authors: We acknowledge that the finite-sample derivation of the decomposition is only sketched. The manuscript presents the bound as an additive decomposition at the expectation level but does not spell out the application of the law of total probability or the handling of the random conditional probability. In the revision we will expand Theorem 2 (or its supporting proposition) to include the complete proof: we first bound the marginal sampling-failure probability by an expectation over the finite-sample estimator, then apply the tower property to show that the overall miscoverage is at most the sum of this term and the conditional selection risk (calibrated on the full set). The proof will explicitly note that the bound is not claiming statistical independence but rather an additive upper bound that remains valid after conditioning. revision: yes
Circularity Check
No circularity: derivation remains self-contained from risk definitions and conformal principles
full rationale
The MiRD framework decomposes overall miscoverage into sampling and conditional selection components using standard expectation-level bounds and full-set conformal calibration; no equations or claims reduce a derived quantity to a fitted parameter defined in terms of itself, nor does any load-bearing step rely on self-citation chains or imported uniqueness results. The central guarantees follow from exchangeability-preserving constructions applied to the full calibration set, with independent content relative to the target coverage levels.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Calibration and test points are exchangeable under the data distribution.
Reference graph
Works this paper leans on
-
[1]
Learn then test: Calibrating predictive algo- rithms to achieve risk control.The Annals of Applied Statistics. Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, and 1 others. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609. Stephen Bates, Anastasios Angelopoulos, Lihua Lei, Jitendra M...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
BalanceRAG: Joint Risk Calibration for Cascaded Retrieval-Augmented Generation
Large language model validity via enhanced conformal prediction methods.Advances in Neural Information Processing Systems, 37:114812–114842. Charles J Clopper and Egon S Pearson. 1934. The use of confidence or fiducial limits illustrated in the case of the binomial.Biometrika, 26(4):404–413. Jesse C Cresswell, Yi Sui, Bhargava Kumar, and Noël V ouitsis. 2...
work page internal anchor Pith review Pith/arXiv arXiv 1934
-
[3]
Conformal prediction with large language models for multi-choice question answering.arXiv preprint arXiv:2305.18404. Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Ken- ton Lee, and 1 others. 2019. Natural questions: a benchmark for question answering...
-
[4]
Nils Reimers and Iryna Gurevych
Coqa: A conversational question answering challenge.Transactions of the Association for Com- putational Linguistics, 7:249–266. Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint confe...
2019
-
[5]
Conformal lesion segmentation for 3d medical images.arXiv preprint arXiv:2510.17897. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, and 1 others. 2023. Llama: Open and effi- cient foundation language models.arXiv preprint arXiv:2302.13971. Guan...
-
[6]
Xiaofan Zhou, Baiting Chen, Yu Gui, and Lu Cheng
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems. Xiaofan Zhou, Baiting Chen, Yu Gui, and Lu Cheng
-
[7]
ACM computing surveys, 58(2):1–37
Conformal prediction: A data perspective. ACM computing surveys, 58(2):1–37. A Proofs and Discussions A.1 Proof of Eq.(6) By the law of total probability, Pr(RN+1 (λ) = 1) = Pr(RN+1 (λ) = 1|Z N+1 = 1)Pr(Z N+1 = 1)+ Pr(RN+1 (λ) = 1|Z N+1 = 0)Pr(Z N+1 = 0). When ZN+1 = 1, no admissible answer appears in the candidate set GM (xN+1 ). Since Cλ(xN+1 )⊆ GM (xN+...
2024
-
[8]
is a reading comprehension benchmark con- taining over 650K samples, which are authored by trivia enthusiasts and independently gathered evi- dence documents. CoQA (Reddy et al., 2019) is a large-scale dataset for building Conversational QA systems, with 127k questions with free-form answers, and each question is equipped with con- textual information. Fo...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.