BalanceRAG: Joint Risk Calibration for Cascaded Retrieval-Augmented Generation
Pith reviewed 2026-05-20 05:16 UTC · model grok-4.3
The pith
BalanceRAG jointly calibrates thresholds for LLM-only and RAG branches in cascades by framing pairs as lattice points and applying sequential graphical testing to control system-level error rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
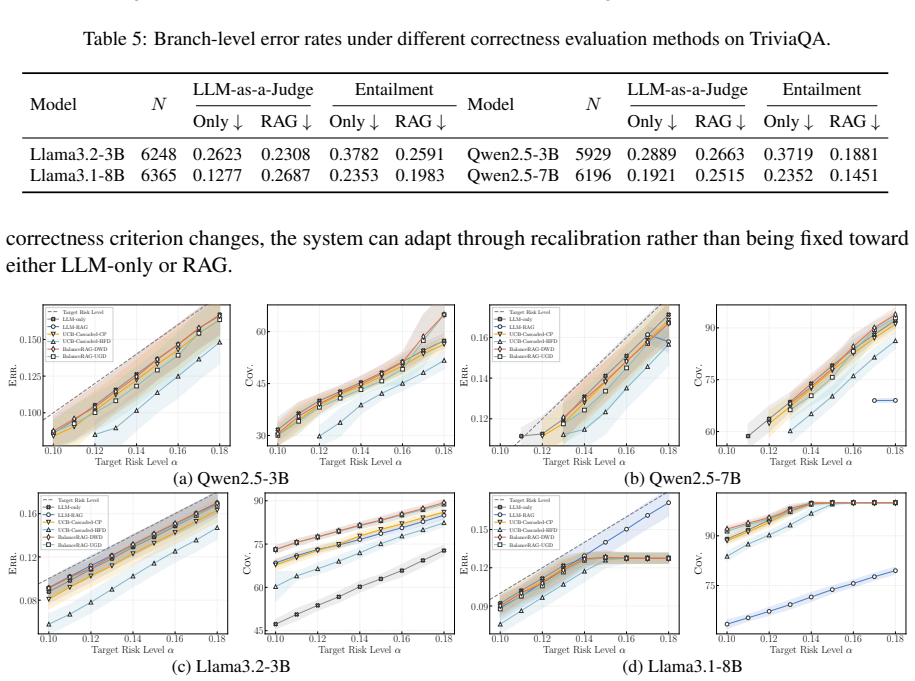
BalanceRAG certifies threshold pairs at a target risk level by representing each pair as an operating point on a two-dimensional lattice and identifying safe points through sequential graphical testing. The procedure controls the system-level error rate among accepted examples while retaining more correct answers than stage-wise calibration and reduces retrieval calls. It further supports multi-risk calibration that bounds retrieval usage together with the selection-conditioned risk.
What carries the argument
A two-dimensional lattice of threshold pairs combined with sequential graphical testing that identifies operating points controlling joint system-level error.
If this is right
- The method meets prescribed risk levels on three open-domain QA benchmarks across multiple LLM backbones.
- It preserves higher coverage and accepts more correct examples than stage-by-stage calibration.
- It reduces unnecessary retrieval calls relative to always-on RAG.
- It extends to multi-risk calibration that jointly bounds retrieval usage and selection-conditioned risk.
Where Pith is reading between the lines
- The lattice-testing idea could be applied to other cascaded pipelines that combine an inexpensive primary model with an expensive fallback.
- If uncertainty scores are poorly calibrated, the identified safe points may still exceed the target risk, suggesting a need for score recalibration as a prerequisite.
- The approach might support query-adaptive risk targets by running the lattice test on subsets of the data.
Load-bearing premise
The uncertainty scores from the LLM-only branch and the RAG branch are sufficiently well-calibrated and jointly informative for sequential graphical testing to identify pairs that actually control the true joint risk.
What would settle it
If, after selecting lattice points via the procedure, the observed error rate among accepted answers on held-out data exceeds the target risk level while coverage remains comparable to baselines, the calibration claim would be falsified.
Figures
















read the original abstract
Large language models (LLMs) can enhance factuality via retrieval-augmented generation (RAG), but applying RAG to every query is unnecessary when the model-only answer is reliable. This motivates cascaded RAG: each query is first handled by an LLM-only branch, escalated to a RAG fallback only if the primary branch is uncertain, and abstained from when neither branch is sufficiently trustworthy. However, calibrating such cascades stage by stage may be conservative, since the final utility depends on joint uncertainty thresholding of LLM-only and RAG. In this work, we develop BalanceRAG to certify threshold pairs at a target risk level. Given uncertainty scores from the two branches, BalanceRAG frames each threshold pair as an operating point on a two-dimensional lattice and identifies safe operating points using sequential graphical testing. This enables risk-adaptive threshold calibration, controlling the system-level error rate among accepted points, while retaining more examples. Furthermore, BalanceRAG extends to multi-risk calibration, allowing retrieval usage to be bounded together with the selection-conditioned risk. Experiments on three open-domain question answering (QA) benchmarks across multiple LLM backbones demonstrate that BalanceRAG meets prescribed risk levels, preserves higher coverage and more accepted correct examples, and reduces unnecessary retrieval calls compared with always-on RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BalanceRAG for joint risk calibration in cascaded RAG systems. Each query is first processed by an LLM-only branch and escalated to RAG only if uncertain; BalanceRAG frames threshold pairs (t1, t2) as points on a 2D lattice and applies sequential graphical testing to certify safe operating points that keep the system-level error rate among accepted examples below a target while increasing coverage. The approach extends to multi-risk calibration that also bounds retrieval usage. Experiments on three open-domain QA benchmarks across multiple LLM backbones show that the method meets prescribed risk levels, retains more accepted correct examples, and reduces unnecessary retrieval calls relative to always-on RAG.
Significance. If the risk-control guarantees hold, BalanceRAG offers a practical method for risk-adaptive calibration of cascaded retrieval systems, enabling higher coverage at controlled error rates and fewer retrieval invocations. The lattice-based sequential testing and multi-risk extension are technically interesting contributions that could improve efficiency in production QA pipelines. The empirical demonstrations across benchmarks and backbones provide initial evidence of utility, though the strength of the claims rests on the validity of the underlying assumptions about score calibration and independence.
major comments (1)
- [§3.3] §3.3 (Sequential Graphical Testing): The procedure is presented as certifying safe (t1, t2) pairs that control true joint risk. However, the description does not address or bound the effect of dependence between the LLM-only and RAG uncertainty scores. When the two scores are positively correlated—as is plausible when both branches fail on the same hard queries—the lattice ordering and sequential testing may select operating points whose realized system-level error exceeds the nominal target, even if the empirical test passes. A concrete counter-example or sensitivity analysis under correlated score distributions is needed to support the central guarantee.
minor comments (3)
- [§4.1] §4.1: The precise definitions and normalization of the two uncertainty scores are only sketched; explicit formulas or pseudocode would improve reproducibility.
- [Table 2] Table 2 and Figure 3: Coverage and risk numbers are reported without error bars or the number of random seeds; adding these would strengthen the empirical claims.
- [§5.2] §5.2: The multi-risk calibration extension is introduced briefly; a short derivation showing how the joint constraint is enforced alongside the error-rate bound would clarify the method.
Simulated Author's Rebuttal
We thank the referee for their careful reading and insightful comments on our manuscript. We address the major comment on dependence between uncertainty scores below.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Sequential Graphical Testing): The procedure is presented as certifying safe (t1, t2) pairs that control true joint risk. However, the description does not address or bound the effect of dependence between the LLM-only and RAG uncertainty scores. When the two scores are positively correlated—as is plausible when both branches fail on the same hard queries—the lattice ordering and sequential testing may select operating points whose realized system-level error exceeds the nominal target, even if the empirical test passes. A concrete counter-example or sensitivity analysis under correlated score distributions is needed to support the central guarantee.
Authors: We appreciate the referee highlighting this important consideration. The sequential graphical testing procedure evaluates the empirical system-level error rate directly on the joint outcomes observed for each (t1, t2) lattice point in the calibration data. Because the test statistic for each operating point is computed from the actual paired decisions and errors of both branches on the same examples, any dependence (including positive correlation on hard queries) is already reflected in the observed joint risk; the procedure does not rely on an independence assumption between the two uncertainty scores. The lattice ordering proceeds by successively testing points in a manner that controls the family-wise error rate over the selected safe set, again using the joint empirical distribution. To make this explicit, we have added a clarifying paragraph in the revised §3.3 and included a sensitivity analysis in the appendix that injects controlled positive correlation between the two scores and verifies that the certified operating points continue to satisfy the target risk level on held-out data. revision: partial
Circularity Check
No circularity: BalanceRAG's sequential graphical testing is an independent algorithmic procedure
full rationale
The paper presents BalanceRAG as a calibration algorithm that frames threshold pairs as points on a 2D lattice and applies sequential graphical testing to certify safe operating points controlling system-level error rate. This derivation chain consists of a described statistical procedure for joint risk control, with no evidence that any claimed guarantee reduces by construction to fitted parameters from the same evaluation data or to self-citations. The abstract and claims treat the graphical testing method as a general contribution that enables risk-adaptive calibration while preserving coverage, validated empirically on QA benchmarks. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citation chains appear in the provided text. The method is self-contained against external benchmarks, consistent with standard non-circular calibration work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uncertainty scores from the LLM-only branch and the RAG branch are available and can be jointly thresholded to control system-level error rate.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BalanceRAG frames each threshold pair as an operating point on a two-dimensional lattice and identifies safe operating points using sequential graphical testing.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the population selection-conditioned risk is bounded by α with high probability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
work page 2020
-
[2]
G uide LLM : Exploring LLM -Guided Conversation with Applications in Autobiography Interviewing
Duan, Jinhao and Zhao, Xinyu and Zhang, Zhuoxuan and Ko, Eunhye Grace and Boddy, Lily and Wang, Chenan and Li, Tianhao and Rasgon, Alexander and Hong, Junyuan and Lee, Min Kyung and Yuan, Chenxi and Long, Qi and Ding, Ying and Chen, Tianlong and Xu, Kaidi. G uide LLM : Exploring LLM -Guided Conversation with Applications in Autobiography Interviewing. Pro...
work page 2025
-
[3]
R e TA : Recursively Thinking Ahead to Improve the Strategic Reasoning of Large Language Models
Duan, Jinhao and Wang, Shiqi and Diffenderfer, James and Sun, Lichao and Chen, Tianlong and Kailkhura, Bhavya and Xu, Kaidi. R e TA : Recursively Thinking Ahead to Improve the Strategic Reasoning of Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techn...
work page 2024
-
[4]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[5]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
SkewRoute: Training-Free LLM Routing for Knowledge Graph Retrieval-Augmented Generation via Score Skewness of Retrieved Context , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
work page 2025
-
[6]
Advances in neural information processing systems , volume=
Selective classification for deep neural networks , author=. Advances in neural information processing systems , volume=
-
[8]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Medhallu: A comprehensive benchmark for detecting medical hallucinations in large language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[9]
Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[10]
Huang, Yue and Sun, Lichao and Wang, Haoran and Wu, Siyuan and Zhang, Qihui and Li, Yuan and Gao, Chujie and Huang, Yixin and Lyu, Wenhan and Zhang, Yixuan and Li, Xiner and Sun, Hanchi and Liu, Zhengliang and Liu, Yixin and Wang, Yijue and Zhang, Zhikun and Vidgen, Bertie and Kailkhura, Bhavya and Xiong, Caiming and Xiao, Chaowei and Li, Chunyuan and Xin...
-
[11]
arXiv preprint arXiv:2512.01556 , year=
LEC: Linear Expectation Constraints for False-Discovery Control in Selective Prediction and Routing Systems , author=. arXiv preprint arXiv:2512.01556 , year=
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Coin: Uncertainty-guarding selective question answering for foundation models with provable risk guarantees , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[13]
SC on U : Selective Conformal Uncertainty in Large Language Models
Wang, Zhiyuan and Wang, Qingni and Zhang, Yue and Chen, Tianlong and Zhu, Xiaofeng and Shi, Xiaoshuang and Xu, Kaidi. SC on U : Selective Conformal Uncertainty in Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
work page 2025
-
[14]
C on U : Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees
Wang, Zhiyuan and Duan, Jinhao and Cheng, Lu and Zhang, Yue and Wang, Qingni and Shi, Xiaoshuang and Xu, Kaidi and Shen, Heng Tao and Zhu, Xiaofeng. C on U : Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024
work page 2024
-
[15]
Engineering Applications of Artificial Intelligence , volume=
Word-sequence entropy: Towards uncertainty estimation in free-form medical question answering applications and beyond , author=. Engineering Applications of Artificial Intelligence , volume=
-
[16]
arXiv preprint arXiv:2407.18370 , year=
Trust or escalate: Llm judges with provable guarantees for human agreement , author=. arXiv preprint arXiv:2407.18370 , year=
-
[17]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
Know what you don’t know: Unanswerable questions for SQuAD , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[19]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
work page 2019
-
[20]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Qwen2. 5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[24]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
work page 2019
-
[25]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2411.11919 (2024)
Vl-uncertainty: Detecting hallucination in large vision-language model via uncertainty estimation , author=. arXiv preprint arXiv:2411.11919 , year=
-
[27]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[28]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=. 2023 , publisher=
work page 2023
-
[29]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , volume =
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avi and Hajishirzi, Hannaneh , booktitle =. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , volume =
-
[30]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Active retrieval augmented generation , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
work page 2023
-
[31]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Searching for best practices in retrieval-augmented generation , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[32]
Retrieval augmented generation or long-context llms? a comprehensive study and hybrid approach , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
work page 2024
-
[33]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[34]
Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2024
-
[35]
arXiv preprint arXiv:2603.22966 , year=
Set-Valued Prediction for Large Language Models with Feasibility-Aware Coverage Guarantees , author=. arXiv preprint arXiv:2603.22966 , year=
-
[36]
Engineering Applications of Artificial Intelligence , volume=
Coverage-guaranteed speech emotion recognition via calibrated uncertainty-adaptive prediction sets , author=. Engineering Applications of Artificial Intelligence , volume=
-
[37]
arXiv preprint arXiv:2510.17897 , year=
Conformal Lesion Segmentation for 3D Medical Images , author=. arXiv preprint arXiv:2510.17897 , year=
-
[38]
Statistics in Medicine , volume =
Bretz, Frank and Maurer, Willi and Brannath, Werner and Posch, Martin , title =. Statistics in Medicine , volume =
-
[39]
International Conference on Learning Representations , volume=
Sample then identify: A general framework for risk control and assessment in multimodal large language models , author=. International Conference on Learning Representations , volume=
-
[40]
Anastasios N. Angelopoulos and Stephen Bates and Emmanuel J. Cand. Learn then Test: Calibrating Predictive Algorithms to Achieve Risk Control , journal =. 2021 , url =. 2110.01052 , timestamp =
-
[41]
Journal of Machine Learning Research , volume=
Asynchronous online testing of multiple hypotheses , author=. Journal of Machine Learning Research , volume=
-
[42]
Roger L. Berger , journal =. Multiparameter Hypothesis Testing and Acceptance Sampling , volume =
-
[43]
Algorithmic learning in a random world , author=. 2005 , publisher=
work page 2005
-
[44]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
Anastasios N. Angelopoulos and Stephen Bates , title =. CoRR , volume =. 2021 , url =. 2107.07511 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[45]
Conformal Risk Control , volume =
Angelopoulos, Anastasios and Bates, Stephen and Fisch, Adam and Lei, Lihua and Schuster, Tal , booktitle =. Conformal Risk Control , volume =
- [46]
-
[47]
Advances in Neural Information Processing Systems , volume=
Conformal alignment: Knowing when to trust foundation models with guarantees , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
arXiv preprint arXiv:2510.14581 , year=
Selective Labeling with False Discovery Rate Control , author=. arXiv preprint arXiv:2510.14581 , year=
-
[49]
Statistics in Medicine , volume =
Multiple testing in clinical trials , author =. Statistics in Medicine , volume =
-
[50]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Mba-rag: a bandit approach for adaptive retrieval-augmented generation through question complexity , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[51]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Search-o1: Agentic search-enhanced large reasoning models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[52]
Dragin: Dynamic retrieval augmented generation based on the real-time information needs of large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[53]
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , publisher=
work page 2024
-
[54]
arXiv preprint arXiv:2305.19187 , year=
Generating with confidence: Uncertainty quantification for black-box large language models , author=. arXiv preprint arXiv:2305.19187 , year=
-
[55]
Uncertainty estimation in autoregressive structured prediction, 2021
Uncertainty estimation in autoregressive structured prediction , author=. arXiv preprint arXiv:2002.07650 , year=
-
[56]
Scandinavian journal of statistics , pages=
A simple sequentially rejective multiple test procedure , author=. Scandinavian journal of statistics , pages=. 1979 , publisher=
work page 1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.