Not All Tokens Matter Equally: Dynamic In-context Vector Distillation with Decisive-Token Supervision for Long-form Medical Report Generation
Pith reviewed 2026-06-29 18:31 UTC · model grok-4.3
The pith
Upweighting pathology tokens and EOS in distillation training improves long-form medical report generation on lexical and clinical metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
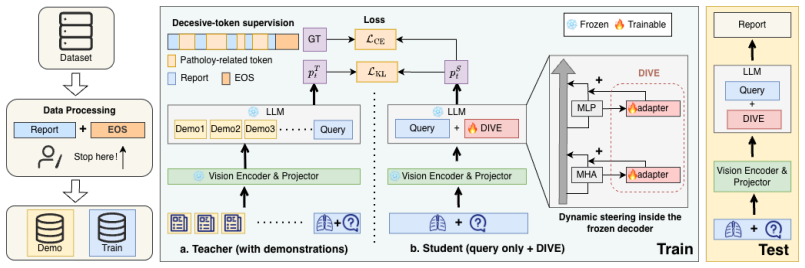
DIVE is a frozen-backbone distillation method that pairs decisive-token supervision, which upweights the cross-entropy loss on pathology-related tokens and the EOS event, with state-conditioned dynamic steering that injects hidden-state-dependent adapters instead of fixed open-loop residuals, thereby correcting the token-importance imbalance and autoregressive drift that arise when extending in-context distillation to long-form medical report generation.
What carries the argument
Decisive-token supervision that upweights cross-entropy contributions of pathology tokens and EOS, combined with state-conditioned dynamic steering via hidden-state-dependent adapters.
If this is right
- DIVE ranks first on BLEU-4, ROUGE-L, and RadGraph F1 in every dataset-backbone combination tested.
- The method stays competitive on coarse CheXbert F1 without degrading label-level accuracy.
- State-dependent adapters counteract the compounding effect of autoregressive decoding drift away from teacher-forced paths.
- The framework remains lightweight because the backbone stays frozen and only small adapters plus loss reweighting are added.
Where Pith is reading between the lines
- The same token-imbalance pattern likely appears in other long-form generation domains such as radiology-adjacent tasks or legal summaries, so the decisive-token idea may transfer once domain-specific decisive tokens are identified.
- An automatic method to discover decisive tokens from data statistics rather than manual pathology lists could broaden applicability without expert annotation.
- Combining DIVE with parameter-efficient fine-tuning on the adapters alone might further reduce any remaining domain gap on new imaging modalities.
Load-bearing premise
Pathology-related tokens and the EOS event are the decisive tokens whose upweighted supervision will raise content fidelity without introducing new biases or lowering performance on other report aspects.
What would settle it
If a uniform-weight distillation baseline matches or exceeds DIVE on RadGraph F1 and BLEU-4 while producing no measurable increase in template repetition or termination errors, the decisive-token premise would be falsified.
Figures
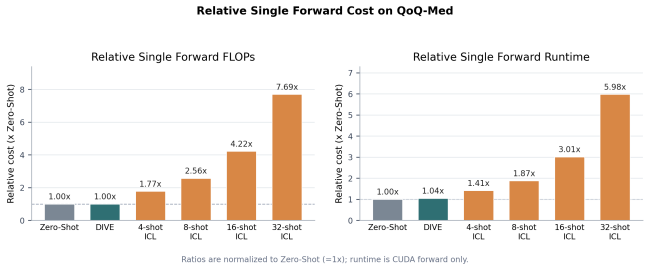
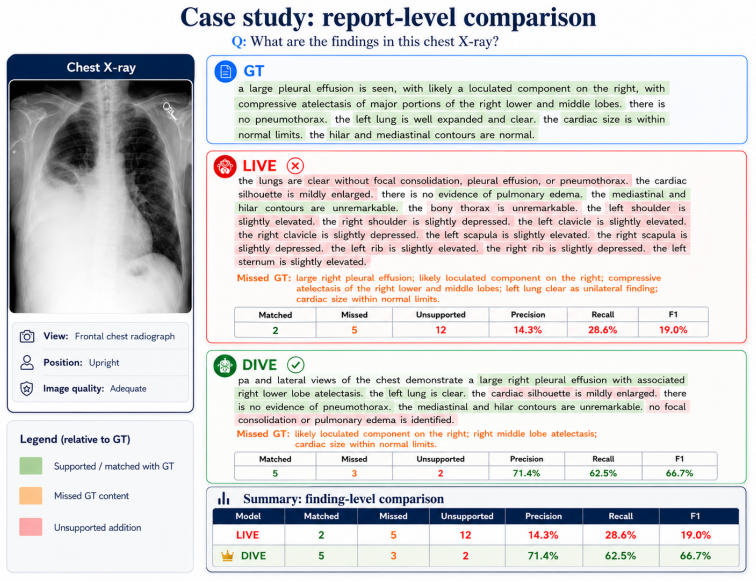
read the original abstract
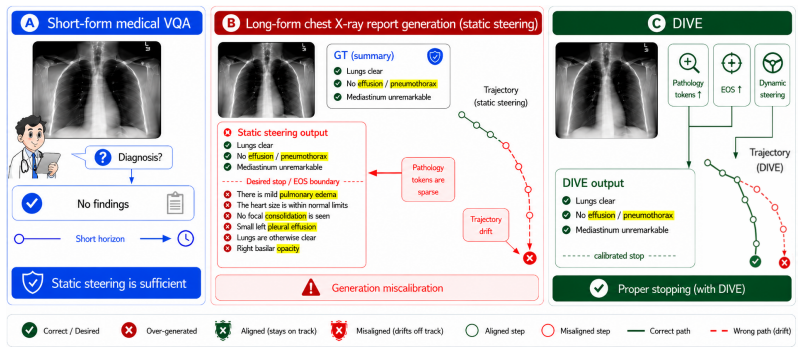
Distilling demonstration effects into hidden-space interventions offers a lightweight alternative to full finetuning. However, existing multimodal variants are mostly evaluated on short-form tasks, where outputs end after a few tokens. Extending these methods to long-form generation exposes a fundamental yet underexamined limitation: token-level distillation implicitly treats all output tokens as equally informative, but long-form outputs are dominated by high-frequency template and grammatical tokens, while the tokens that actually determine output quality are sparsely distributed. In medical report generation (MRG), two such decisive tokens stand out: pathology-related tokens that determine diagnostic content, and the end-of-sequence (EOS) event that determines termination. Both receive insufficient supervision under uniform cross-entropy, and autoregressive decoding further compounds the problem by drifting away from teacher-forced trajectories. We propose DIVE, a frozen-backbone distillation framework that addresses long-form report generation through two complementary mechanisms matched to these failures. Decisive-token supervision restores supervision balance by upweighting the cross-entropy contribution of pathology-related tokens and the EOS event, ensuring that content fidelity and termination are learned during training rather than imposed at decoding time. State-conditioned dynamic steering replaces fixed open-loop residuals with hidden-state-dependent adapters, allowing the injected signal to adapt as decoding drifts. Experiments on MIMIC-CXR and CheXpert Plus with two medical VLM backbones show that DIVE consistently ranks among the strongest methods across lexical and clinical-proxy metrics. Our method achieves the best BLEU-4, ROUGE-L, and RadGraph F1 in all dataset--backbone settings, while remaining competitive on coarse label-level CheXbert F1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DIVE, a frozen-backbone distillation method for long-form medical report generation. It introduces decisive-token supervision, which upweights the cross-entropy loss for pathology-related tokens and the EOS token, together with state-conditioned dynamic steering that replaces fixed residuals with hidden-state-dependent adapters. Experiments on MIMIC-CXR and CheXpert Plus using two medical VLM backbones report that DIVE obtains the highest BLEU-4, ROUGE-L, and RadGraph F1 scores in every dataset-backbone combination while remaining competitive on CheXbert F1.
Significance. If the reported gains are shown to arise from the proposed mechanisms rather than from unstated implementation choices, the work would offer a lightweight, training-time intervention that targets the sparsity of informative tokens in long-form generation. The consistent ranking on clinical-proxy metrics (RadGraph F1) across two datasets and two backbones would be a concrete contribution to efficient adaptation of VLMs for medical reporting.
major comments (3)
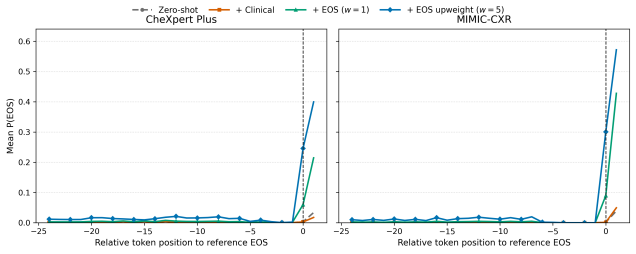
- [§3] §3 (Decisive-token supervision): the procedure used to label pathology-related tokens in the reference reports is never described. Because the central claim attributes metric gains to upweighting these tokens, the absence of the labeling rule (lexicon, model, or heuristic) makes it impossible to assess whether the supervision is independent of the RadGraph and CheXbert evaluation pipelines.
- [§4] §4 (Experiments): no ablation isolates the contribution of decisive-token upweighting from the dynamic adapters, and no statistical significance tests or confidence intervals are reported for the claimed improvements in BLEU-4, ROUGE-L, and RadGraph F1. These omissions leave the attribution of performance gains unverifiable.
- [§3.3] §3.3 (State-conditioned dynamic steering): the functional form of the hidden-state-dependent adapters, their parameter count, and the precise manner in which they are inserted into the frozen backbone are not specified. This detail is load-bearing for the claim that the method remains lightweight while adapting to decoding drift.
minor comments (1)
- [Abstract, §4] The abstract and §4 refer to “two medical VLM backbones” without naming them or citing their original papers in the first mention.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, committing to revisions where details were omitted or additional experiments are warranted.
read point-by-point responses
-
Referee: [§3] §3 (Decisive-token supervision): the procedure used to label pathology-related tokens in the reference reports is never described. Because the central claim attributes metric gains to upweighting these tokens, the absence of the labeling rule (lexicon, model, or heuristic) makes it impossible to assess whether the supervision is independent of the RadGraph and CheXbert evaluation pipelines.
Authors: We agree the labeling procedure must be specified for reproducibility and to confirm independence from evaluation metrics. The revised §3 will explicitly describe the fixed medical terminology lexicon used to identify pathology tokens (distinct from RadGraph entity extraction and CheXbert labels). revision: yes
-
Referee: [§4] §4 (Experiments): no ablation isolates the contribution of decisive-token upweighting from the dynamic adapters, and no statistical significance tests or confidence intervals are reported for the claimed improvements in BLEU-4, ROUGE-L, and RadGraph F1. These omissions leave the attribution of performance gains unverifiable.
Authors: The absence of component-wise ablations and statistical tests is a valid concern. We will add an ablation table isolating decisive-token supervision from dynamic steering and report confidence intervals or significance tests from multiple random seeds in the revised experiments. revision: yes
-
Referee: [§3.3] §3.3 (State-conditioned dynamic steering): the functional form of the hidden-state-dependent adapters, their parameter count, and the precise manner in which they are inserted into the frozen backbone are not specified. This detail is load-bearing for the claim that the method remains lightweight while adapting to decoding drift.
Authors: We acknowledge the omission of architectural specifics. The revised §3.3 will detail the adapter formulation (state-conditioned low-rank updates via a small MLP), exact parameter counts, and insertion points after decoder layers, confirming the lightweight property relative to full fine-tuning. revision: yes
Circularity Check
No circularity; empirical claims rest on external dataset comparisons
full rationale
The paper presents DIVE as an empirical framework for long-form medical report generation, with performance claims supported solely by reported results on MIMIC-CXR and CheXpert Plus using standard metrics (BLEU-4, ROUGE-L, RadGraph F1, CheXbert F1). No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the abstract or described content. The decisive-token supervision mechanism is introduced as a design choice without reduction to self-defined inputs or load-bearing prior work by the authors. The derivation chain is therefore self-contained against external benchmarks.
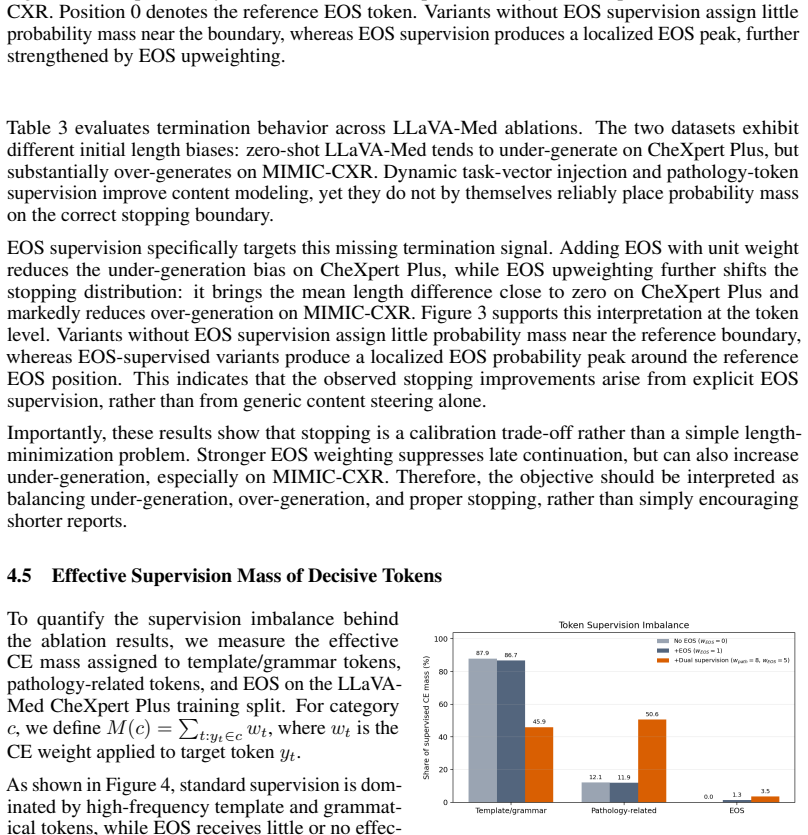
Axiom & Free-Parameter Ledger
free parameters (1)
- upweighting coefficients for pathology tokens and EOS
axioms (1)
- domain assumption Pathology-related tokens and the EOS event are the decisive tokens that determine output quality
Reference graph
Works this paper leans on
-
[1]
What learning algorithm is in-context learning? investigations with linear models
Ekin Akyurek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. InICLR, 2023
2023
-
[2]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InNeurIPS, 2015
2015
-
[3]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agar- wal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz ...
2020
-
[4]
Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven Q
Pierre J. Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven Q. H. Truong, Chu The Chuong, and Curtis P. Langlotz. Chexpert plus: Augmenting a large chest x-ray dataset with text radiology reports, patient demographics and additional image formats.arXiv preprint arXiv:2405.19538, 2024
-
[5]
Generating radiology reports via memory-driven transformer
Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan. Generating radiology reports via memory-driven transformer. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1439–1449, 2020. doi: 10.18653/v1/2020. emnlp-main.112
-
[6]
Rethinking radiology report generation: From narrative flow to topic-guided findings
Sheng Cheng and Devika Subramanian. Rethinking radiology report generation: From narrative flow to topic-guided findings. InInternational Conference on Learning Representations, 2026
2026
-
[7]
Empirical analysis of beam search performance degradation in neural sequence models
Eldan Cohen and Christopher Beck. Empirical analysis of beam search performance degradation in neural sequence models. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 1290–1299, 2019
2019
-
[8]
Wei Dai, Peilin Chen, Chanakya Ekbote, and Paul Pu Liang. QoQ-Med: Building multimodal clinical foundation models with domain-aware GRPO training.arXiv preprint arXiv:2506.00711, 2025
-
[9]
Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 2016
Dina Demner-Fushman et al. Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 2016
2016
-
[10]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. InNeurIPS, 2023
2023
-
[11]
A Survey on In-context Learning
Qingxiu Dong et al. A survey on in-context learning.arXiv preprint arXiv:2301.00234, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
What can transformers learn in-context? a case study of simple function classes
Shivam Garg, Dimitris Tsipras, Percy Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes. InNeurIPS, 2022
2022
-
[13]
To- wards a unified view of parameter-efficient transfer learning
Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. To- wards a unified view of parameter-efficient transfer learning. InICLR, 2022
2022
-
[14]
FactCheX- cker: Mitigating measurement hallucinations in chest x-ray report generation models
Alice Heiman, Xiaoman Zhang, Emma Chen, Sung Eun Kim, and Pranav Rajpurkar. FactCheX- cker: Mitigating measurement hallucinations in chest x-ray report generation models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 30787–30796, June 2025
2025
-
[15]
The curious case of neural text degeneration
Ari Holtzman et al. The curious case of neural text degeneration. InICLR, 2020
2020
-
[16]
Parameter-efficient transfer learning for nlp
Neil Houlsby et al. Parameter-efficient transfer learning for nlp. InICML, 2019
2019
-
[17]
Hu et al
Edward J. Hu et al. Lora: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[18]
Multimodal task vectors enable many-shot multimodal in-context learning
Brandon Huang, Chancharik Mitra, Assaf Arbelle, Leonid Karlinsky, Trevor Darrell, and Roei Herzig. Multimodal task vectors enable many-shot multimodal in-context learning. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), 2024. 10
2024
-
[19]
Editing models with task arithmetic
Gabriel Ilharco et al. Editing models with task arithmetic. InICLR, 2023
2023
-
[20]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison
Jeremy Irvin et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. InAAAI, 2019
2019
-
[21]
Radgraph: Extracting clinical entities and relations from radiology reports
Saahil Jain et al. Radgraph: Extracting clinical entities and relations from radiology reports. In NeurIPS Datasets and Benchmarks, 2021
2021
-
[22]
On the automatic generation of medical imaging reports
Baoyu Jing, Pengtao Xie, and Eric Xing. On the automatic generation of medical imaging reports. InACL, 2018
2018
-
[23]
Alistair E. W. Johnson, Tom J. Pollard, Seth J. Berkowitz, Nathaniel R. Greenbaum, Matthew P. Lungren, Chih-ying Deng, Roger G. Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific Data, 6(317),
-
[24]
doi: 10.1038/s41597-019-0322-0
-
[25]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InEMNLP, 2021
2021
-
[26]
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
Chunyuan Li et al. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.arXiv preprint arXiv:2306.00890, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Inference- time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viegas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. InNeurIPS, 2023
2023
-
[28]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InACL-IJCNLP, 2021
2021
-
[29]
Yuan Li, Xiaodan Liang, Zhiting Hu, and Eric P. Xing. Hybrid retrieval-generation reinforced agent for medical image report generation. InNeurIPS, 2018
2018
-
[30]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText Summarization Branches Out, 2004
2004
-
[31]
Enhanced contrastive learning with multi-view longitudinal data for chest x-ray report genera- tion
Kang Liu, Zhuoqi Ma, Xiaolu Kang, Yunan Li, Kun Xie, Zhicheng Jiao, and Qiguang Miao. Enhanced contrastive learning with multi-view longitudinal data for chest x-ray report genera- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10348–10359, June 2025
2025
-
[32]
Sheng Liu, Lei Xing, and James Zou. In-context vectors: Making in context learning more effective and controllable through latent space steering.arXiv preprint arXiv:2311.06668, 2023
-
[33]
P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks
Xiao Liu et al. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. InACL, 2022
2022
-
[34]
If beam search is the answer, what was the question? InEMNLP, 2020
Clara Meister, Tim Vieira, and Ryan Cotterell. If beam search is the answer, what was the question? InEMNLP, 2020
2020
-
[35]
Rethinking the role of demonstrations: What makes in-context learning work? InEMNLP, 2022
Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. Rethinking the role of demonstrations: What makes in-context learning work? InEMNLP, 2022
2022
-
[36]
Langlotz, and Dan Jurafsky
Yasuhide Miura, Yuhao Zhang, Emily Bao Tsai, Curtis P. Langlotz, and Dan Jurafsky. Improving factual completeness and consistency of image-to-text radiology report generation. InNAACL, 2021
2021
-
[37]
Med-flamingo: A multimodal medical few-shot learner.arXiv preprint arXiv:2307.15189, 2023
Michael Moor et al. Med-flamingo: A multimodal medical few-shot learner.arXiv preprint arXiv:2307.15189, 2023
-
[38]
Correcting length bias in neural machine translation
Kenton Murray and David Chiang. Correcting length bias in neural machine translation. In Proceedings of the Third Conference on Machine Translation: Research Papers, pages 212–223,
-
[39]
doi: 10.18653/v1/W18-6322
-
[40]
Longitudinal data and a semantic similarity reward for chest x-ray report generation.Artificial Intelligence in Medicine, 2024
Aaron Nicolson, Jason Dowling, and Bevan Koopman. Longitudinal data and a semantic similarity reward for chest x-ray report generation.Artificial Intelligence in Medicine, 2024. 11
2024
-
[41]
Green: Generative radiology report evaluation and error notation
Sophie Ostmeier et al. Green: Generative radiology report evaluation and error notation. In Findings of EMNLP, 2024
2024
-
[42]
Bleu: A method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: A method for automatic evaluation of machine translation. InACL, 2002
2002
-
[43]
DART: Disease-aware image-text alignment and self-correcting re-alignment for trustworthy radiology report generation
Sang-Jun Park, Keun-Soo Heo, Dong-Hee Shin, Young-Han Son, Ji-Hye Oh, and Tae-Eui Kam. DART: Disease-aware image-text alignment and self-correcting re-alignment for trustworthy radiology report generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15580–15589, June 2025
2025
-
[44]
Learnable in-context vector for visual question answering.CoRR, abs/2406.13185, 2024
Yingzhe Peng, Chenduo Hao, Xu Yang, Jiawei Peng, Xinting Hu, and Xin Geng. Learnable in-context vector for visual question answering.CoRR, abs/2406.13185, 2024
-
[45]
Sequence level training with recurrent neural networks
Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. Sequence level training with recurrent neural networks. InInternational Conference on Learning Representa- tions, 2016
2016
-
[46]
Steering Llama 2 via Contrastive Activation Addition
Nina Rimsky et al. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Automated radiology report generation: A review of recent advances.IEEE Reviews in Biomedical Engineering, 18: 368–387, 2025
Phillip Sloan, Philip Clatworthy, Edwin Simpson, and Majid Mirmehdi. Automated radiology report generation: A review of recent advances.IEEE Reviews in Biomedical Engineering, 18: 368–387, 2025
2025
-
[48]
Combining automatic labelers and expert annotations for accurate radiology report labeling using bert
Akshay Smit et al. Combining automatic labelers and expert annotations for accurate radiology report labeling using bert. InEMNLP, 2020
2020
-
[49]
Towards generalist biomedical ai.NEJM AI, 2024
Tao Tu et al. Towards generalist biomedical ai.NEJM AI, 2024
2024
-
[50]
Steering Language Models With Activation Engineering
Alexander Matt Turner et al. Activation addition: Steering language models without optimiza- tion.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Lawrence Zitnick, and Devi Parikh
Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. InCVPR, 2015
2015
-
[52]
Transformers learn in-context by gradient descent
Johannes V on Oswald, Eyvind Niklasson, Ettore Randazzo, Joao Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. InICML, 2023
2023
-
[53]
Cross-modal memory networks for radiology report generation
Jun Wang, Abhir Bhalerao, and Yulan He. Cross-modal memory networks for radiology report generation. InACL, 2022
2022
-
[54]
CXPMRG-Bench: Pre-training and benchmarking for x-ray medical report generation on CheXpert Plus dataset
Xiao Wang, Fuling Wang, Yuehang Li, Qingchuan Ma, Shiao Wang, Bo Jiang, and Jin Tang. CXPMRG-Bench: Pre-training and benchmarking for x-ray medical report generation on CheXpert Plus dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5123–5133, June 2025
2025
-
[55]
Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases
Xiaosong Wang et al. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. InCVPR, 2017
2017
-
[56]
Ziao Wang, Sixing Yan, Kejing Yin, Xiaofeng Zhang, and William K. Cheung. CURV: Coherent uncertainty-aware reasoning in vision-language models for x-ray report generation. InAdvances in Neural Information Processing Systems, 2025
2025
-
[57]
Neural text generation with unlikelihood training
Sean Welleck et al. Neural text generation with unlikelihood training. InICLR, 2020
2020
-
[58]
Sam Wiseman and Alexander M. Rush. Sequence-to-sequence learning as beam-search opti- mization. InEMNLP, 2016
2016
-
[59]
An explanation of in-context learning as implicit bayesian inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit bayesian inference. InICLR, 2022
2022
-
[60]
Weakly supervised contrastive learning for chest x-ray report generation
An Yan et al. Weakly supervised contrastive learning for chest x-ray report generation. In Findings of EMNLP, 2021. 12
2021
-
[61]
Ng, Curtis P
Feiyang Yu, Mark Endo, Rayan Krishnan, Ian Pan, Andy Tsai, Eduardo Pontes Reis, Eduardo Kaiser Ururahy Nunes Fonseca, Henrique Min Ho Lee, Zahra Shakeri Hossein Abad, Andrew Y . Ng, Curtis P. Langlotz, Vasantha Kumar Venugopal, and Pranav Rajpurkar. Evaluating progress in automatic chest x-ray radiology report generation.Patterns, 4(9):100802, 2023
2023
-
[62]
Zambrano Chaves
Juan Manuel et al. Zambrano Chaves. A clinically accessible small multimodal radiology model and evaluation metric for chest x-ray findings.Nature Communications, 2025
2025
-
[63]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. InICLR, 2020
2020
-
[64]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 13 A Implementation Details A.1 Datasets and Preprocessing We conduct experiments on two chest X-ray report generation benchmarks: MIMIC-CXR-JPG [23] and CheXpert Plus [ 4]. Both datasets contain chest radiographs paired with correspon...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.