LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
Pith reviewed 2026-06-29 17:50 UTC · model grok-4.3
The pith
By decoding each bounding box as one atomic unit instead of a sequence of tokens, LocateAnything raises both decoding speed and localization accuracy in vision-language grounding and detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that treating bounding boxes and points as atomic units decoded in one forward pass preserves intra-box geometric coherence and removes the sequential bottleneck of token-by-token generation, thereby increasing both throughput and localization quality while a large curated dataset further supports precise unified grounding and detection.
What carries the argument
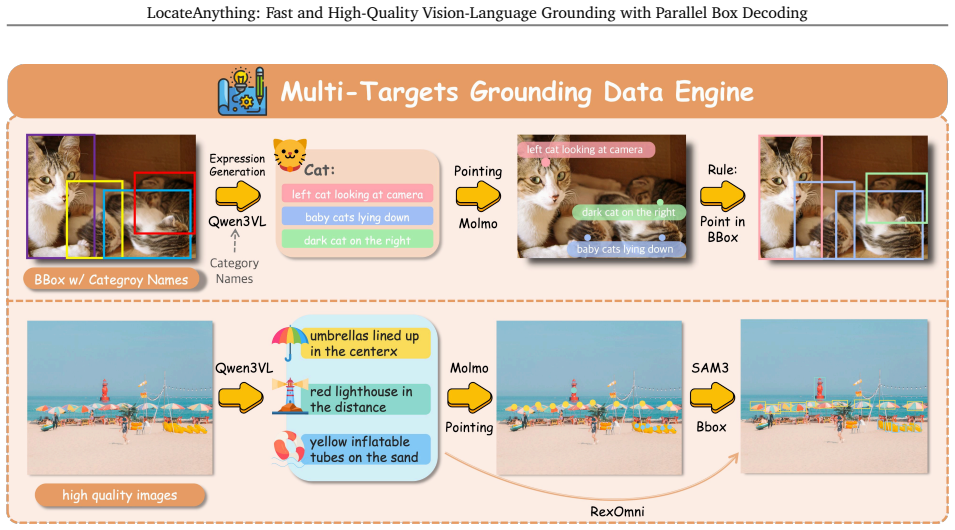
Parallel Box Decoding (PBD), which outputs complete geometric elements such as bounding boxes in a single step rather than as independent coordinate tokens.
If this is right
- Decoding throughput rises because multiple boxes no longer require strictly sequential token generation.
- High-IoU localization quality improves because coordinate values inside one box remain coupled during generation.
- A single model can handle both visual grounding and object detection without separate heads or pipelines.
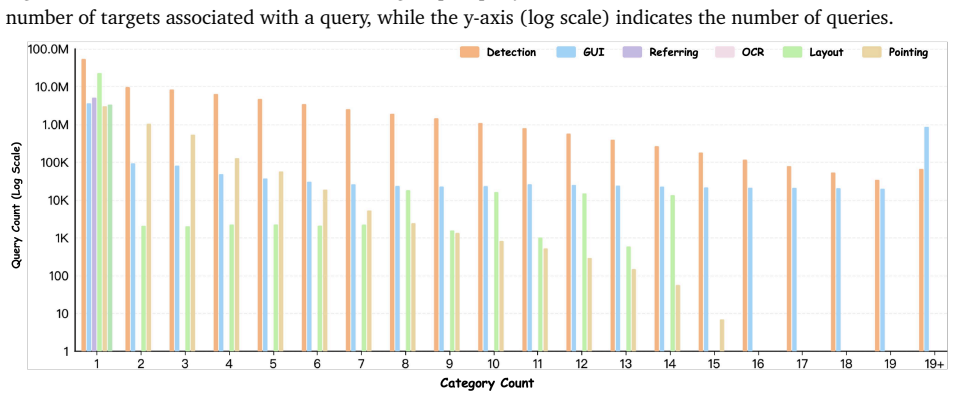
- Large-scale training data of over 138 million samples becomes practical for further accuracy gains under the new decoder.
- The same atomic-unit approach can be applied to other geometric outputs such as points or keypoints.
Where Pith is reading between the lines
- Real-time applications such as robotics or augmented reality could become feasible if the throughput gains hold at higher resolutions.
- The method may reduce the need for post-processing steps that currently enforce box consistency after independent coordinate prediction.
- If the single-step decoder generalizes, similar atomic decoding could be tested on other structured outputs like polygons or 3D boxes.
- The dataset scale suggests that data diversity, not just model size, is a key lever once the decoding mismatch is removed.
Load-bearing premise
A generative vision-language model can be trained to emit complete box coordinates in one forward pass without losing or even while gaining accuracy relative to sequential token decoding.
What would settle it
On standard visual grounding benchmarks, if single-step box output produces either lower high-IoU scores or no measurable increase in tokens per second compared with the token-by-token baseline, the central claim would be falsified.
Figures
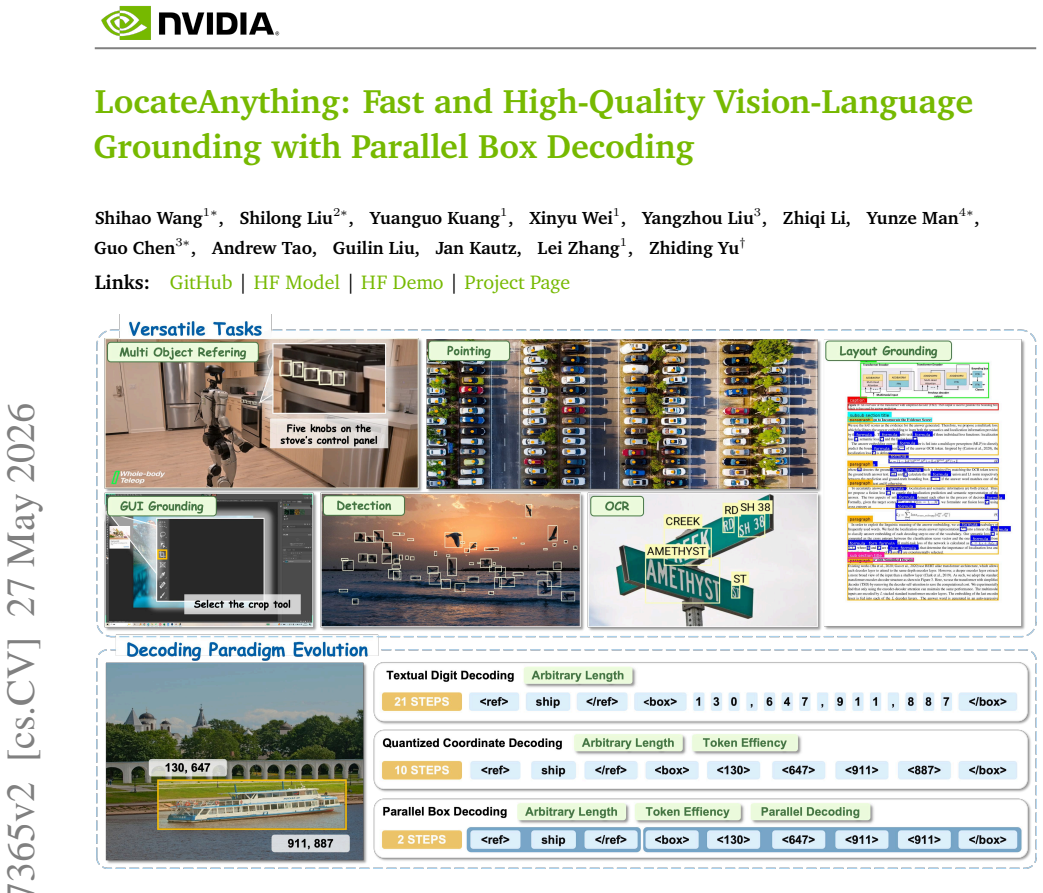
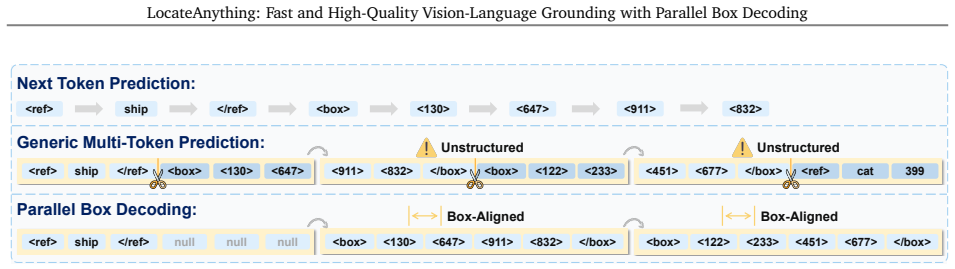
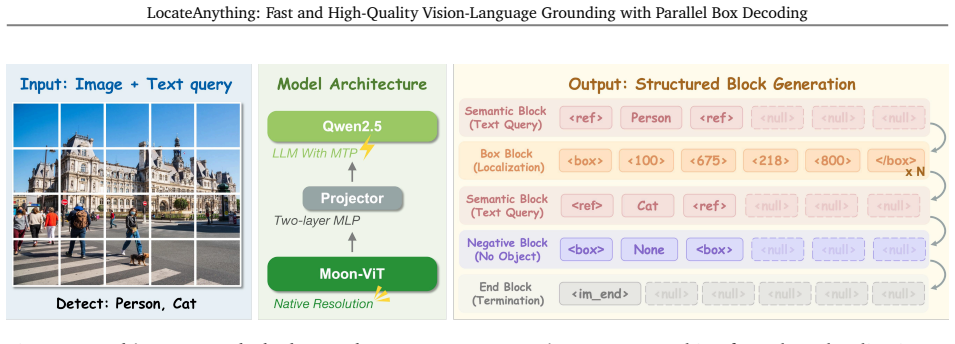


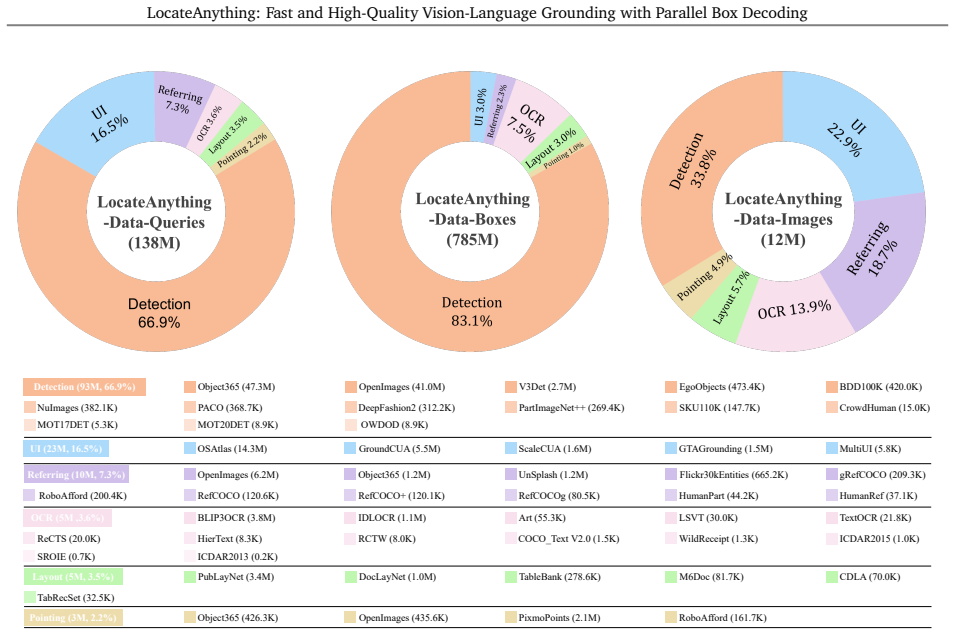




read the original abstract
Vision-language models (VLMs) commonly formulate visual grounding and detection as a coordinate-token generation problem, serializing each 2D box into multiple 1D tokens that are learned and decoded largely independently. This token-by-token decoding mismatches the coupled structure of box geometry and creates a practical inference bottleneck due to strictly sequential generation. We introduce LocateAnything, a unified generative grounding and detection framework based on Parallel Box Decoding (PBD). By decoding geometric elements such as bounding boxes and points as atomic units in a single step, LocateAnything preserves intra-box geometric coherence and unlocks substantial parallelism. We show that PBD improves both decoding throughput and localization accuracy. We further develop a scalable data engine and curate LocateAnything-Data, a large-scale dataset with more than 138 million training samples, substantially increasing data diversity for high-precision localization. Extensive evaluations show that LocateAnything advances the speed-accuracy frontier, achieving significantly higher decoding throughput while improving high-IoU localization quality across diverse benchmarks. The results highlight the complementary benefits of Parallel Box Decoding and large-scale training data in enabling efficient and precise unified visual grounding and detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LocateAnything, a unified generative framework for vision-language grounding and detection. It replaces token-by-token autoregressive serialization of bounding boxes with Parallel Box Decoding (PBD), which treats boxes and points as atomic units decoded in a single step. This is claimed to preserve intra-box geometric coherence, unlock parallelism for higher throughput, and improve localization accuracy. The work is complemented by curation of LocateAnything-Data, a 138-million-sample training set, with extensive evaluations showing advances on the speed-accuracy frontier across benchmarks.
Significance. If the claimed accuracy gains from PBD hold under controlled conditions, the work would meaningfully advance efficient high-precision grounding in VLMs by addressing both inference bottlenecks and geometric consistency. The scale of the new dataset is a notable contribution, but the paper's central attribution of quality improvements to the decoding mechanism requires clearer isolation from data effects to be fully convincing.
major comments (1)
- [Abstract] Abstract: The central claim ties localization quality improvements to 'intra-box geometric coherence' from PBD, yet the abstract presents both PBD and the 138M-sample LocateAnything-Data as key enablers without describing a controlled ablation that holds training data fixed while switching only between token-by-token autoregressive box serialization and atomic PBD. This leaves open whether accuracy gains are driven by the proposed coherence mechanism or by data scale and diversity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to clarify the isolation of Parallel Box Decoding (PBD) effects. We address the concern about controlled ablations below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim ties localization quality improvements to 'intra-box geometric coherence' from PBD, yet the abstract presents both PBD and the 138M-sample LocateAnything-Data as key enablers without describing a controlled ablation that holds training data fixed while switching only between token-by-token autoregressive box serialization and atomic PBD. This leaves open whether accuracy gains are driven by the proposed coherence mechanism or by data scale and diversity.
Authors: We agree that the abstract should more explicitly reference the controlled experiments. In Sections 4.3 and 4.4 of the manuscript we report ablations that train identical model architectures on the same data subsets (both the original grounding datasets and subsets of LocateAnything-Data) while switching only the box decoding mechanism between token-by-token autoregressive serialization and atomic PBD. These results show consistent gains in high-IoU accuracy and throughput attributable to PBD, independent of data scale. We will revise the abstract to include a concise statement of these controlled comparisons so that the attribution to intra-box geometric coherence is clearer from the outset. revision: yes
Circularity Check
No circularity; empirical architecture and dataset claims are self-contained
full rationale
The paper introduces Parallel Box Decoding as an architectural change (atomic box output in one step) and curates a new 138M-sample dataset. No equations, fitted parameters, or derivation steps are present that reduce a claimed result to its own inputs by construction. Central claims rest on measured speed/accuracy improvements rather than any self-definitional loop, fitted-input prediction, or load-bearing self-citation chain. This matches the default case of an empirical contribution without circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
15 Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to objects in photographs of natural scenes. In Alessandro Moschitti, Bo Pang, and Walter Daelemans, editors,Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 787–798, Doha, Qatar, October 2014. Association for Com...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3115/v1/d14-1086 2014
-
[2]
ShowUI: One vision-language- action model for generalist GUI agent
15 Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Zechen Bai, et al. ShowUI: One vision-language- action model for generalist GUI agent. InNeurIPS Workshop, 2024a. 2 Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, et al. Microsoft COCO: Common objects in context. InECCV, pages 740–755. Springer, 2014. 8 Weifeng Lin, Xiny...
-
[3]
Weatherqa: Can multimodal language models reason about severe weather?
15 Chengqian Ma, Zhanxiang Hua, Alexandra Anderson-Frey, Vikram Iyer, Xin Liu, and Lianhui Qin. Weatherqa: Can multimodal language models reason about severe weather?arXiv preprint arXiv:2406.11217, 2024a. 15 Chuofan Ma, Yi Jiang, Jiannan Wu, Zehuan Yuan, and Xiaojuan Qi. Groma: Localized visual tokenization for grounding multimodal large language models....
-
[4]
Asking questions on handwritten document collections.International Journal on Document Analysis and Recognition (IJDAR), 24(3):235–249,
15 Minesh Mathew, Lluis Gomez, Dimosthenis Karatzas, and CV Jawahar. Asking questions on handwritten document collections.International Journal on Document Analysis and Recognition (IJDAR), 24(3):235–249,
-
[5]
15 Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. Infographicvqa. InWACV, pages 1697–1706, 2022. 15 Nitesh Methani, Pritha Ganguly, Mitesh M Khapra, and Pratyush Kumar. Plotqa: Reasoning over scientific plots. InWACV, pages 1527–1536, 2020. 15 Anand Mishra, Karteek Alahari, and CV Jawahar. Scene text recognit...
-
[6]
Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models
15 PixArt-alpha. Sam-llava-captions10m dataset. https://huggingface.co/datasets/PixArt-alpha/ SAM-LLaVA-Captions10M, 2024. 15 Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models, 2016. URLhttps://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Design2code: Benchmarking multimodal code generation for automated front-end engineering
15 Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: Benchmarking multimodal code generation for automated front-end engineering. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3...
-
[8]
Patch-as-decodable-token: Towards unified multi-modal vision tasks in MLLMs
15 Yongyi Su, Haojie Zhang, Shijie Li, Nanqing Liu, Jingyi Liao, et al. Patch-as-decodable-token: Towards unified multi-modal vision tasks in MLLMs. InICLR, 2026. 3 Alane Suhr, Mike Lewis, James Yeh, and Yoav Artzi. A corpus of natural language for visual reasoning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics...
-
[9]
Kwai keye-vl 1.5 technical report,
15 Shiyu Xuan, Qingpei Guo, Ming Yang, and Shiliang Zhang. Pink: Unveiling the power of referential compre- hension for multi-modal LLMs. InCVPR, 2024. 3 Biao Yang, Bin Wen, Boyang Ding, Changyi Liu, Chenglong Chu, et al. Kwai Keye-VL 1.5 technical report.arXiv preprint arXiv:2509.01563, 2025a. 2 Kaiyu Yang, Olga Russakovsky, and Jia Deng. Spatialsense: A...
-
[10]
15 Tai-Ling Yuan, Zhe Zhu, Kun Xu, Cheng-Jun Li, Tai-Jiang Mu, and Shi-Min Hu. A large chinese text dataset in the wild.Journal of Computer Science and Technology, 34:509–521, 2019. 15 Yuqian Yuan, Wenqiao Zhang, Xin Li, Shihao Wang, Kehan Li, et al. PixelRefer: A unified framework for spatio-temporal object referring with arbitrary granularity.arXiv prep...
-
[11]
17 Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini
8, 10 41 LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding Mingyu Zheng, Xinwei Feng, Qingyi Si, Qiaoqiao She, Zheng Lin, Wenbin Jiang, and Weiping Wang. Multimodal table understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9102–9124...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.