The Future of Facts: Tracing the Factual Generation-Verification Gap
Pith reviewed 2026-06-29 18:28 UTC · model grok-4.3
The pith
Language models learn to verify facts reliably before they learn to generate them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
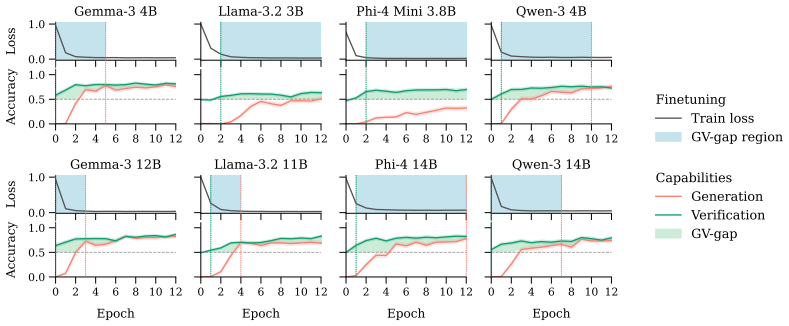
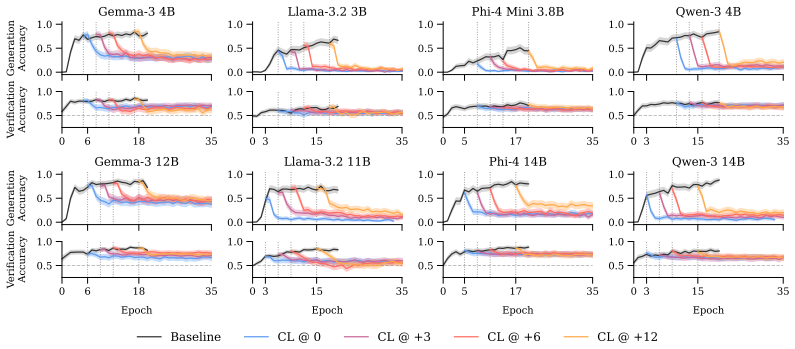
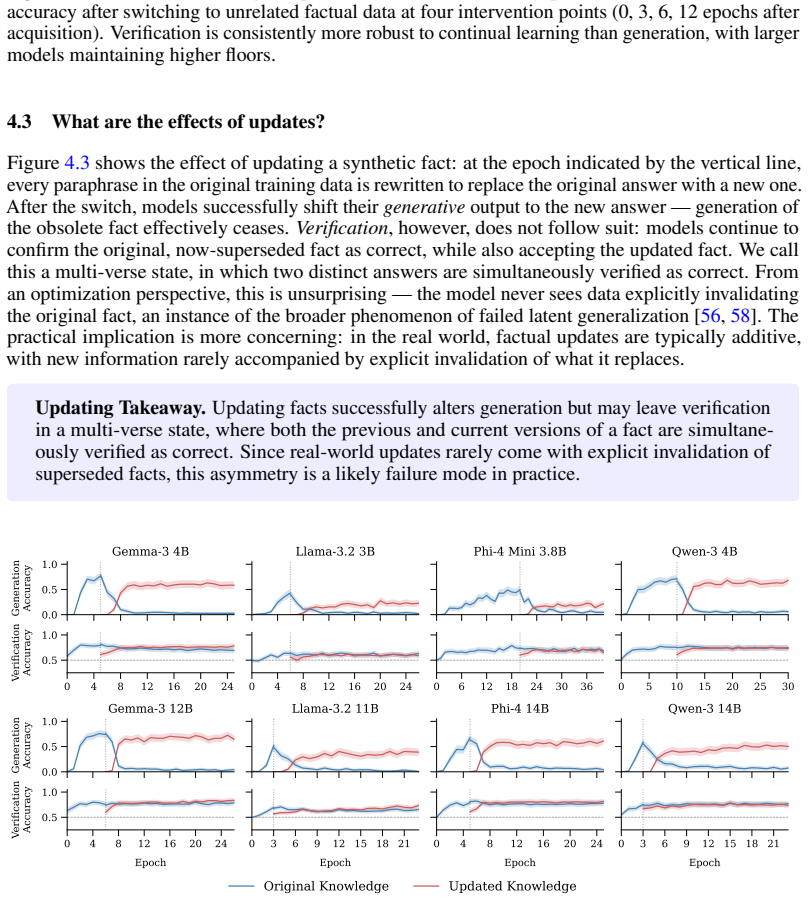
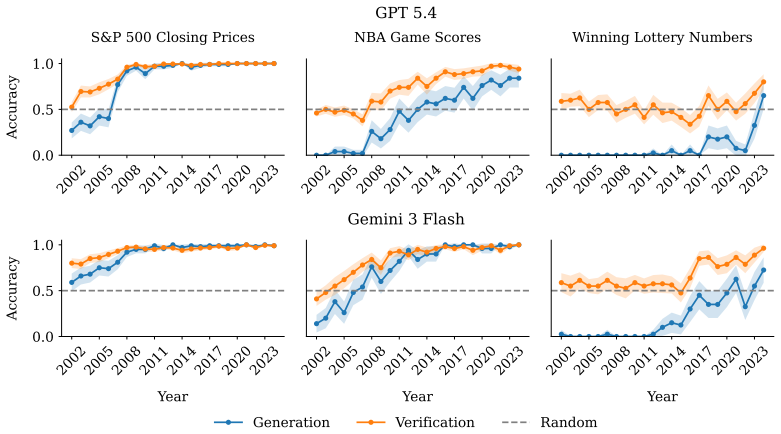
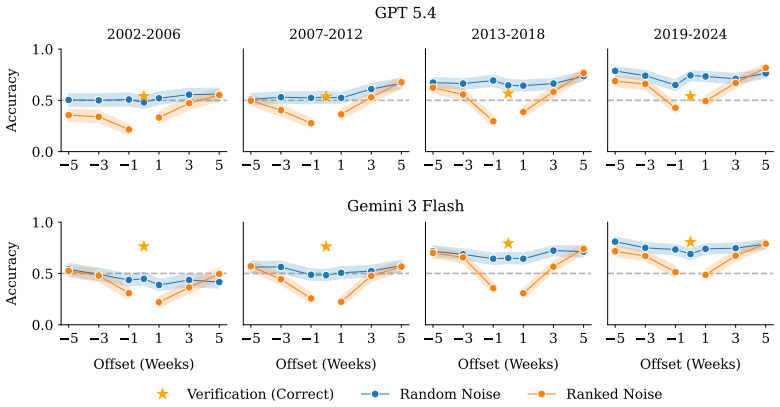
Across four model families at two scales each, verification is learned before generation during acquisition, remains more robust than generation during continual learning, and factual updates can produce a multi-verse state in which models verify both old and new answers as correct simultaneously. The same dynamics appear at scale on frontier models, along with residual verification biases on well-covered facts.
What carries the argument
The factual generation-verification gap, isolated by tracking generation and verification separately across acquisition, continual learning, and updating phases.
If this is right
- Verification precedes generation in the acquisition of factual knowledge.
- Verification capabilities degrade less than generation during further training on other tasks.
- Factual updates can leave models simultaneously accepting contradictory answers as correct.
- The same ordering and robustness patterns appear in larger frontier models on well-covered facts.
Where Pith is reading between the lines
- Training pipelines might usefully separate verification-focused stages from generation-focused stages.
- Update methods could be tested specifically for whether they reduce simultaneous acceptance of old and new facts.
- Self-improvement loops that rely on verification may inherit biases from this ordering of capabilities.
Load-bearing premise
Generation and verification can be measured independently through the three phases without the chosen tasks or facts creating the observed gap by design.
What would settle it
An experiment that trains models on a new set of facts using different tasks and shows generation consistently preceding verification or that updates eliminate rather than preserve conflicting verifications.
Figures

read the original abstract
Language models are becoming the default interface to factual knowledge, yet they often verify outputs more reliably than they generate them. This generation-verification gap (GV-gap) underlies many recent advances in self-improvement and reasoning, but its dynamics on factual knowledge specifically remain poorly understood. We focus on the training mechanisms underlying factual GV-gaps, distinguishing them from their computational and aesthetic counterparts. We trace generation and verification capabilities through three training phases (acquisition, continual learning, and updating) across four open-source model families at two scales each. Three findings recur across models: (i) verification is consistently learned before generation; (ii) verification is more robust to continual learning than generation; and (iii) factual updates can leave models in a "multi-verse" state, simultaneously verifying both old and new answers as correct. Natural experiments on frontier models reproduce these dynamics at scale and reveal residual verification biases on well-covered facts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that language models exhibit a generation-verification gap (GV-gap) specific to factual knowledge. Tracing capabilities across acquisition, continual learning, and updating phases in four open-source model families (two scales each), it reports three recurring findings: (i) verification is learned before generation, (ii) verification is more robust to continual learning than generation, and (iii) factual updates can leave models in a 'multi-verse' state simultaneously verifying both old and new answers as correct. Natural experiments on frontier models are said to reproduce the dynamics at scale.
Significance. If the three findings prove robust once operational details are supplied, the work would provide a useful empirical map of how factual generation and verification diverge during training. This could inform self-improvement pipelines and update strategies that aim to keep verification and generation aligned, adding to the literature on factual reliability in LLMs.
major comments (1)
- [Abstract] Abstract: The three central findings are stated without any description of how generation versus verification was operationalized, which facts were selected, what prompt formats or controls were used, or any error analysis. This is load-bearing for all claims, because the skeptic concern that the GV-gap may be created by construction through task design or fact selection cannot be evaluated from the given information.
minor comments (1)
- [Abstract] Abstract: The distinction drawn between factual GV-gaps and their 'computational and aesthetic counterparts' is introduced without definition or citation, which may reduce clarity for readers.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding operational details. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The three central findings are stated without any description of how generation versus verification was operationalized, which facts were selected, what prompt formats or controls were used, or any error analysis. This is load-bearing for all claims, because the skeptic concern that the GV-gap may be created by construction through task design or fact selection cannot be evaluated from the given information.
Authors: We agree that the abstract's brevity leaves the operationalization of the GV-gap underspecified, which is necessary to evaluate potential task-design artifacts. The full manuscript details these elements in Section 3 (Methods): generation is measured via exact-match accuracy on open-ended factual completion prompts; verification uses multiple-choice accuracy on the same facts with both correct and distractor options; facts are drawn from a curated set of 500 Wikipedia-derived triples balanced across domains with controls for popularity and recency; prompt formats include zero-shot and few-shot variants with randomization of option order; and error analysis reports per-model confusion matrices plus inter-annotator agreement on a human subset. To make these claims evaluable directly from the abstract and preempt concerns about construction artifacts, we will add a concise clause describing the core measurement approach and fact-selection criteria. revision: yes
Circularity Check
No circularity: purely observational empirical study
full rationale
The paper reports three recurring empirical observations from training phases (acquisition, continual learning, updating) across model families. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. The findings are direct measurements of generation vs. verification performance; they do not reduce to inputs by construction. The study is self-contained against external benchmarks via reported metrics on open-source models and natural experiments on frontier models. No load-bearing self-citations or ansatz smuggling are present.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Division of training into acquisition, continual learning, and updating phases is a valid and exhaustive partitioning for tracing capability emergence.
Reference graph
Works this paper leans on
-
[1]
Jon Saad-Falcon, E. Kelly Buchanan, Mayee F Chen, Tzu-Heng Huang, Brendan McLaugh- lin, Tanvir Bhathal, Shang Zhu, Ben Athiwaratkun, Frederic Sala, Scott Linderman, Azalia Mirhoseini, and Christopher Re. Weaver: Shrinking the generation-verification gap by scaling compute for verification. InThe Thirty-ninth Annual Conference on Neural Information Process...
2026
-
[2]
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
Yuda Song, Hanlin Zhang, Udaya Ghai, Carson Eisenach, Sham M Kakade, and Dean Foster. Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models. In ICLR, 2025. URLhttps://openreview.net/pdf?id=mtJSMcF3ek
2025
-
[3]
Large language models can self-improve
Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. Large language models can self-improve. InEMNLP, pages 1051–1068, 2023
2023
-
[4]
Self-improvement in language models: The sharpening mechanism.ICLR, 2025
Audrey Huang, Adam Block, Dylan J Foster, Dhruv Rohatgi, Cyril Zhang, Max Simchowitz, Jordan T Ash, and Akshay Krishnamurthy. Self-improvement in language models: The sharpening mechanism.ICLR, 2025
2025
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems, November 2021. URL http://arxiv.org/abs/2110.14168. arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InICLR,
-
[7]
URLhttps://openreview.net/forum?id=v8L0pN6EOi
-
[8]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Scaling llm test-time compute optimally can be more effective than scaling model parameters.ICLR, 2025
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.ICLR, 2025
2025
-
[10]
Generative verifiers: Reward modeling as next-token prediction.ICLR, 2025
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction.ICLR, 2025
2025
-
[11]
Gokul Swamy, Sanjiban Choudhury, Wen Sun, Zhiwei Steven Wu, and J. Andrew Bagnell. All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning, March 2025. URLhttp://arxiv.org/abs/2503.01067. arXiv:2503.01067
-
[12]
Yifan Sun, Yushan Liang, Zhen Zhang, and Jiaye Teng. Theoretical modeling of llm self- improvement training dynamics through solver-verifier gap.arXiv preprint arXiv:2507.00075, 2025
-
[13]
How people use chatgpt
Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. How people use chatgpt. Technical report, National Bureau of Economic Research, 2025
2025
-
[14]
Introducing bing generative search
Microsoft. Introducing bing generative search. https://blogs.bing.com/search/July- 2024/generativesearch, July 2024
2024
-
[15]
Generative ai in search: Let google do the searching for you
Elizabeth Reid. Generative ai in search: Let google do the searching for you. https://blog.google/products-and-platforms/products/search/generative-ai- google-search-may-2024/, May 2024. 10
2024
-
[16]
A representative study on human detection of artificially generated media across countries
Joel Frank, Franziska Herbert, Jonas Ricker, Lea Schönherr, Thorsten Eisenhofer, Asja Fischer, Markus Dürmuth, and Thorsten Holz. A representative study on human detection of artificially generated media across countries. In2024 IEEE Symposium on Security and Privacy (SP), pages 55–73. IEEE, 2024
2024
-
[17]
As good as a coin toss: Human detection of ai-generated content.Commun
Di Cooke, Abigail Edwards, Sophia Barkoff, and Kathryn Kelly. As good as a coin toss: Human detection of ai-generated content.Commun. ACM, 68(10):100–109, September 2025. ISSN 0001-0782. doi: 10.1145/3729417. URLhttps://doi.org/10.1145/3729417
-
[18]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1–38, 2023
2023
-
[19]
Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
2024
-
[20]
Hal- luhard: A hard multi-turn hallucination benchmark.arXiv preprint arXiv:2602.01031, 2026
Dongyang Fan, Sebastien Delsad, Nicolas Flammarion, and Maksym Andriushchenko. Hal- luhard: A hard multi-turn hallucination benchmark.arXiv preprint arXiv:2602.01031, 2026
-
[21]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, page 610–623, New York, NY , USA, 2021. Association for Computing Machinery. ISBN 9781450383097. doi: 10....
-
[22]
How ai can distort human beliefs.Science, 380(6651): 1222–1223, 2023
Celeste Kidd and Abeba Birhane. How ai can distort human beliefs.Science, 380(6651): 1222–1223, 2023
2023
-
[23]
Josh A Goldstein, Girish Sastry, Micah Musser, Renee DiResta, Matthew Gentzel, and Katerina Sedova. Generative language models and automated influence operations: Emerging threats and potential mitigations.arXiv preprint arXiv:2301.04246, 1, 2023
-
[24]
Proce- dural knowledge in pretraining drives reasoning in large language models.ICLR, 2025
Laura Ruis, Maximilian Mozes, Juhan Bae, Siddhartha Rao Kamalakara, Dwarak Talupuru, Acyr Locatelli, Robert Kirk, Tim Rocktäschel, Edward Grefenstette, and Max Bartolo. Proce- dural knowledge in pretraining drives reasoning in large language models.ICLR, 2025
2025
-
[25]
Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G
John X. Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G. Edward Suh, Alexan- der M. Rush, Kamalika Chaudhuri, and Saeed Mahloujifar. How much do language models memorize?, June 2025. URLhttp://arxiv.org/abs/2505.24832. arXiv:2505.24832
-
[26]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models.Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openr...
2022
-
[27]
Physics of language models: Part 3.1, knowledge storage and extraction.ICML, 2024
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.1, knowledge storage and extraction.ICML, 2024
2024
-
[28]
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective STars
Kanishk Gandhi, Ayush K Chakravarthy, Anikait Singh, Nathan Lile, and Noah Goodman. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective STars. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/ forum?id=QGJ9ttXLTy
2025
-
[29]
Zengzhi Wang, Fan Zhou, Xuefeng Li, and Pengfei Liu. Octothinker: Mid-training incentivizes reinforcement learning scaling.arXiv preprint arXiv:2506.20512, 2025
-
[30]
What It Can Create, It May Not Understand
Peter West, Ximing Lu, Nouha Dziri, Faeze Brahman, Linjie Li, Jena D. Hwang, Liwei Jiang, Jillian Fisher, Abhilasha Ravichander, Khyathi Chandu, Benjamin Newman, Pang Wei Koh, Allyson Ettinger, and Yejin Choi. The Generative AI Paradox: “What It Can Create, It May Not Understand”. InThe Twelfth International Conference on Learning Representations, 2024. U...
2024
-
[31]
Self-recognition in language models.EMNLP, 2024
Tim R Davidson, Viacheslav Surkov, Veniamin Veselovsky, Giuseppe Russo, Robert West, and Caglar Gulcehre. Self-recognition in language models.EMNLP, 2024
2024
-
[32]
How do large language models acquire factual knowledge during pretraining? Advances in neural information processing systems, 37:60626–60668, 2024
Hoyeon Chang, Jinho Park, Seonghyeon Ye, Sohee Yang, Youngkyung Seo, Du-Seong Chang, and Minjoon Seo. How do large language models acquire factual knowledge during pretraining? Advances in neural information processing systems, 37:60626–60668, 2024
2024
-
[33]
How do language models learn facts? dynamics, curricula and hallucinations
Nicolas Zucchet, Jörg Bornschein, Stephanie Chan, Andrew Lampinen, Razvan Pascanu, and Soham De. How do language models learn facts? dynamics, curricula and hallucinations. arXiv preprint arXiv:2503.21676, 2025
-
[34]
Birth of a transformer: A memory viewpoint.Advances in Neural Information Processing Systems, 36: 1560–1588, 2023
Alberto Bietti, Vivien Cabannes, Diane Bouchacourt, Herve Jegou, and Leon Bottou. Birth of a transformer: A memory viewpoint.Advances in Neural Information Processing Systems, 36: 1560–1588, 2023
2023
-
[35]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InEMNLP, pages 5484–5495, 2021
2021
-
[36]
Dissecting recall of factual associations in auto-regressive language models.EMNLP, 2023
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto-regressive language models.EMNLP, 2023
2023
-
[37]
Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
2022
-
[38]
Lee, and Alberto Bietti
Eshaan Nichani, Jason D. Lee, and Alberto Bietti. Understanding Factual Recall in Trans- formers via Associative Memories. InICLR, October 2025. URL https://openreview.net/ forum?id=hwSmPOAmhk
2025
-
[39]
Editing factual knowledge in language models
Nicola De Cao, Wilker Aziz, and Ivan Titov. Editing factual knowledge in language models. EMNLP, 2021
2021
-
[40]
Memory-based model editing at scale
Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D Manning, and Chelsea Finn. Memory-based model editing at scale. InInternational Conference on Machine Learning, pages 15817–15831. PMLR, 2022
2022
-
[41]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[42]
An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[43]
Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
2025
-
[44]
The nature of recollection and familiarity: A review of 30 years of research.Journal of memory and language, 46(3):441–517, 2002
Andrew P Yonelinas. The nature of recollection and familiarity: A review of 30 years of research.Journal of memory and language, 46(3):441–517, 2002
2002
-
[45]
Recognition and retrieval processes in free recall
John R Anderson and Gordon H Bower. Recognition and retrieval processes in free recall. Psychological review, 79(2):97, 1972
1972
-
[46]
Search processes in recognition memory 1
Richard C Atkinson, Douglas J Herrmann, and Keith T Wescourt. Search processes in recognition memory 1. InTheories in cognitive psychology, pages 101–146. Routledge, 1974
1974
-
[47]
On the relationship between autobiographical memory and perceptual learning.Journal of Experimental Psychology: General, 110(3):306, 1981
Larry L Jacoby and Mark Dallas. On the relationship between autobiographical memory and perceptual learning.Journal of Experimental Psychology: General, 110(3):306, 1981
1981
-
[48]
Functional neuroanatomy of recall and recognition: A pet study of episodic memory.Journal of cognitive neuroscience, 9(2):254–265, 1997
Roberto Cabeza, Shitij Kapur, Fergus IM Craik, Anthony R McIntosh, Sylvain Houle, and Endel Tulving. Functional neuroanatomy of recall and recognition: A pet study of episodic memory.Journal of cognitive neuroscience, 9(2):254–265, 1997. 12
1997
-
[49]
Cambridge University Press, 2014
Shai Shalev-Shwartz and Shai Ben-David.Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press, 2014
2014
-
[50]
Bin Liu and Geoffrey I. Webb. Generative and discriminative learning. In Claude Sammut and Geoffrey I. Webb, editors,Encyclopedia of Machine Learning, pages 454–455. Springer US, Boston, MA, 2010. ISBN 978-0-387-30164-8. doi: 10.1007/978-0-387-30164-8 _332. URL https://doi.org/10.1007/978-0-387-30164-8_332
-
[51]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[52]
Stephen A. Cook. The complexity of theorem-proving procedures. InProceedings of the Third Annual ACM Symposium on Theory of Computing, STOC ’71, page 151–158. Association for Computing Machinery, New York, NY , USA, 1971. ISBN 9781450374644. doi: 10.1145/ 800157.805047. URLhttps://doi.org/10.1145/800157.805047
-
[53]
Reducibility among combinatorial problems
Richard M Karp. Reducibility among combinatorial problems. In50 Years of Integer Pro- gramming 1958-2008: from the Early Years to the State-of-the-Art, pages 219–241. Springer, 1972
1958
-
[54]
Universal sequential search problems.Problems of information transmission, 9(3):265–266, 1973
Leonid A Levin. Universal sequential search problems.Problems of information transmission, 9(3):265–266, 1973
1973
-
[55]
Barnes & Noble, New York, 1790
Immanuel Kant.Critique of Judgment. Barnes & Noble, New York, 1790
-
[56]
Towards understanding sycophancy in language models.ICLR, 2024
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models.ICLR, 2024
2024
-
[57]
a is b" fail to learn
Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. The reversal curse: Llms trained on" a is b" fail to learn" b is a". ICLR, 2024
2024
-
[58]
Physics of language models: Part 3.2, knowledge manipu- lation.ICLR, 2025
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.2, knowledge manipu- lation.ICLR, 2025
2025
-
[59]
On the generalization of language models from in-context learning and finetuning: a controlled study
Andrew K Lampinen, Arslan Chaudhry, Stephanie CY Chan, Cody Wild, Diane Wan, Alex Ku, Jörg Bornschein, Razvan Pascanu, Murray Shanahan, and James L McClelland. On the generalization of language models from in-context learning and finetuning: a controlled study. NeurIPS, FoRLM Workshop, 2025
2025
-
[60]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Claude sonnet 4.5
Anthropic. Claude sonnet 4.5. https://www.anthropic.com, 2025. Large language model; API identifier: claude-sonnet-4-5
2025
-
[62]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, et al. Phi-4- mini technical report: Compact yet powerful multimodal language models via mixture-of-loras. arXiv preprint arXiv:2503.01743, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Llama 3.2: Revolutionizing edge AI and vision with open, customizable mod- els, September 2024
Meta AI. Llama 3.2: Revolutionizing edge AI and vision with open, customizable mod- els, September 2024. URL https://ai.meta.com/blog/llama-3-2-connect-2024-vision- edge-mobile-devices. Blog post
2024
-
[68]
Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel
Niklas Muennighoff, Alexander M. Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models.Journal of Machine Learning Research, 26(53):1–66, 2025. URL http: //jmlr.org/papers/v26/24-1000.html
2025
-
[69]
When scaling meets LLM finetun- ing: The effect of data, model and finetuning method
Biao Zhang, Zhongtao Liu, Colin Cherry, and Orhan Firat. When scaling meets LLM finetun- ing: The effect of data, model and finetuning method. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=5HCnKDeTws
2024
-
[70]
T-rex: A large scale alignment of natural language with knowledge base triples
Hady Elsahar, Pavlos V ougiouklis, Arslen Remaci, Christophe Gravier, Jonathon Hare, Fred- erique Laforest, and Elena Simperl. T-rex: A large scale alignment of natural language with knowledge base triples. InProceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), 2018
2018
-
[71]
Judging llm-as-a-judge with mt- bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt- bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[72]
A new era of intelligence with Gemini 3, November 2025
Google. A new era of intelligence with Gemini 3, November 2025. URL https://blog. google/products-and-platforms/products/gemini/gemini-3/. Blog post
2025
-
[73]
Reasoning- driven synthetic data generation and evaluation.TMLR, 2026
Tim R Davidson, Benoit Seguin, Enrico Bacis, Cesar Ilharco, and Hamza Harkous. Reasoning- driven synthetic data generation and evaluation.TMLR, 2026
2026
-
[74]
The digitization of the world from edge to core.Framingham: International Data Corporation, 16:1–28, 2018
David Reinsel-John Gantz-John Rydning, John Reinsel, and John Gantz. The digitization of the world from edge to core.Framingham: International Data Corporation, 16:1–28, 2018
2018
-
[75]
Introducing GPT-5.4, 2026
OpenAI. Introducing GPT-5.4, 2026. URL https://openai.com/index/introducing-gpt- 5-4/. Blog post
2026
-
[76]
Are we in the ai-generated text world already? quantifying and monitoring aigt on social media
Zhen Sun, Zongmin Zhang, Xinyue Shen, Ziyi Zhang, Yule Liu, Michael Backes, Yang Zhang, and Xinlei He. Are we in the ai-generated text world already? quantifying and monitoring aigt on social media. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22975–23005, 2025
2025
-
[77]
The Impact of AI-Generated Text on the Internet
Jonas Dolezal, Sawood Alam, Mark Graham, and Maty Bohacek. The impact of ai-generated text on the internet, 2026. URLhttps://arxiv.org/abs/2604.26965
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[78]
Large language models reduce public knowledge sharing on online q&a platforms.PNAS nexus, 3(9):pgae400, 2024
R Maria del Rio-Chanona, Nadzeya Laurentsyeva, and Johannes Wachs. Large language models reduce public knowledge sharing on online q&a platforms.PNAS nexus, 3(9):pgae400, 2024
2024
-
[79]
Ai models collapse when trained on recursively generated data.Nature, 631(8022): 755–759, 2024
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. Ai models collapse when trained on recursively generated data.Nature, 631(8022): 755–759, 2024
2024
-
[80]
Physics of language models: Part 3.3, knowledge capacity scaling laws
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.3, knowledge capacity scaling laws. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=FxNNiUgtfa. 14
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.