Discovery Agents for Real-Time Analytics: Toward Proactive Insight Systems
Pith reviewed 2026-06-29 17:14 UTC · model grok-4.3
The pith
Multi-agent architecture autonomously discovers insights over real-time data streams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
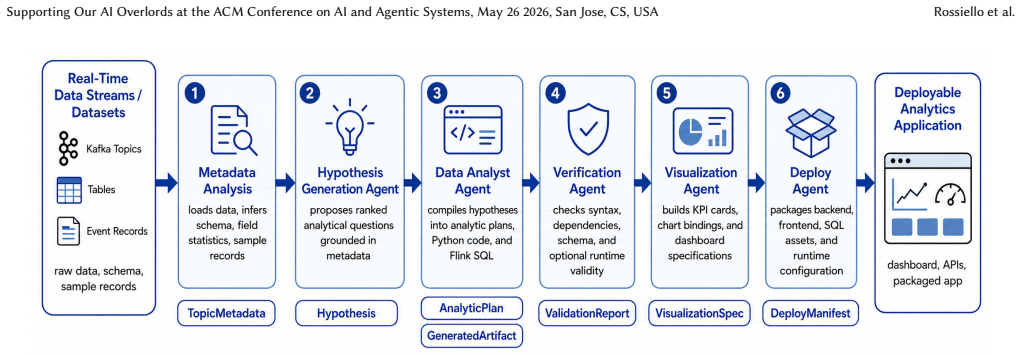
The authors present a multi-agent architecture for autonomous insight discovery over real-time data streams. The system implements a continuous discovery loop in which agents generate hypotheses, compile them into executable analytics, validate generated artifacts, and produce visualizations and deployable applications. The architecture leverages event-driven coordination and stream processing together with language models to implement specialized agents. A key contribution is a contract-driven design based on typed intermediate artifacts, enabling modularity, observability, lineage, and safer execution of dynamically generated analytics.
What carries the argument
Contract-driven design based on typed intermediate artifacts, which supplies modularity, observability, lineage, and safer execution for dynamically generated analytics.
If this is right
- The space of potential insights no longer needs to be enumerated manually by users.
- Analytics systems shift from reactive query-driven operation to proactive discovery-driven operation.
- Generated analytics carry built-in lineage tracking and safety properties through the typed contracts.
- The same architecture supports application across retail, finance, and public data domains.
Where Pith is reading between the lines
- If the loop runs continuously at scale, the volume of generated insights could exceed human capacity to review them, requiring new prioritization mechanisms.
- The typed contract pattern could be reused to constrain AI-generated code in other domains that involve dynamic execution over data.
- Extending the discovery loop to include feedback from deployed applications might improve hypothesis quality over time.
Load-bearing premise
The contract-driven design based on typed intermediate artifacts enables modularity, observability, lineage, and safer execution of dynamically generated analytics.
What would settle it
A demonstration in which the generated analytics repeatedly produce incorrect results or unsafe executions despite the typed contracts would falsify the claim that the design enables safer execution.
Figures
read the original abstract
Modern analytics systems are fundamentally reactive, requiring users to define queries over increasingly complex and continuously evolving data. In real-time streaming environments, this paradigm breaks down, as the space of potential insights becomes too large to enumerate manually. We present a multi-agent architecture for autonomous insight discovery over real-time data streams. The system implements a continuous discovery loop in which agents generate hypotheses, compile them into executable analytics, validate generated artifacts, and produce visualizations and deployable applications. The architecture leverages Apache Kafka for event-driven coordination, Apache Flink for stream processing, and large language models to implement specialized agents. A key contribution is a contract-driven design based on typed intermediate artifacts, enabling modularity, observability, lineage, and safer execution of dynamically generated analytics. Through use cases in retail, finance, and public data, we show how this architecture supports a shift from query-driven analytics to proactive, discovery-driven systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a multi-agent architecture for autonomous insight discovery over real-time data streams. Agents generate hypotheses from streaming data, compile them into executable analytics via LLMs, validate the artifacts, and produce visualizations and deployable applications. The system uses Apache Kafka for event-driven coordination and Apache Flink for stream processing. A central element is a contract-driven design relying on typed intermediate artifacts to support modularity, observability, lineage, and safer execution of dynamically generated code. Use cases in retail, finance, and public data are invoked to illustrate a shift from reactive query-driven analytics to proactive discovery-driven systems.
Significance. If the architecture can be shown through concrete validation to reliably produce correct insights while mitigating risks of LLM-generated code, the work would address a genuine scalability challenge in high-velocity analytics environments and offer a practical path toward proactive systems. The typed-contract approach is a reasonable mechanism for improving observability and safety in dynamic code generation. At present the manuscript supplies no empirical measurements, so the practical significance cannot yet be assessed.
major comments (2)
- [Abstract] Abstract: the assertion that the architecture 'supports a shift from query-driven analytics to proactive, discovery-driven systems' is presented as demonstrated 'through use cases,' yet the manuscript contains no reported metrics, error rates, success/failure counts, or validation results from the retail, finance, or public-data examples.
- [Abstract] Abstract: the claim that the 'contract-driven design based on typed intermediate artifacts' enables 'safer execution of dynamically generated analytics' is not accompanied by any concrete description of how the contracts detect semantic or logical errors in generated stream-processing code (as opposed to syntax or basic type mismatches), nor by any quantitative evidence of reduced error rates.
minor comments (1)
- The abstract would be clearer if it briefly indicated the volume or velocity of the data streams used in the example scenarios.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the claims regarding demonstration through use cases and the specifics of safety mechanisms require qualification, as the manuscript is primarily an architectural description with illustrative examples rather than a quantitative evaluation. We will revise the abstract to address both points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the architecture 'supports a shift from query-driven analytics to proactive, discovery-driven systems' is presented as demonstrated 'through use cases,' yet the manuscript contains no reported metrics, error rates, success/failure counts, or validation results from the retail, finance, or public-data examples.
Authors: We agree that the use cases serve as illustrations of the architecture rather than empirical demonstrations with metrics. The manuscript does not report quantitative results such as error rates or success counts. We will revise the abstract to state that the use cases 'illustrate' the potential shift to proactive systems, removing any implication of demonstrated validation. revision: yes
-
Referee: [Abstract] Abstract: the claim that the 'contract-driven design based on typed intermediate artifacts' enables 'safer execution of dynamically generated analytics' is not accompanied by any concrete description of how the contracts detect semantic or logical errors in generated stream-processing code (as opposed to syntax or basic type mismatches), nor by any quantitative evidence of reduced error rates.
Authors: We acknowledge that the abstract does not include a concrete description of semantic or logical error detection beyond type enforcement, nor any quantitative evidence. The contract-driven design is presented as supporting safer execution via typed artifacts for modularity and lineage, but we will revise the abstract to qualify this as 'intended to support safer execution' without claiming specific detection capabilities or evidence. revision: yes
Circularity Check
No circularity: architectural proposal with no derivations or self-referential definitions
full rationale
The paper presents a multi-agent system architecture for insight discovery using LLMs, Kafka, and Flink, with a contract-driven design asserted to enable safer execution. No equations, fitted parameters, derivations, or mathematical claims appear in the abstract or described structure. The central claims rest on descriptive architecture and use-case illustrations rather than any reduction of outputs to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The absence of any derivation chain means the patterns of self-definitional, fitted-input, or imported-uniqueness circularity do not apply; the work is self-contained as a systems proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Paris Carbone, Asterios Katsifodimos, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Tzoumas. 2015. Apache Flink: Stream and Batch Processing in a Single Engine.IEEE Data Engineering Bulletin38, 4 (2015)
2015
-
[4]
Arik, Misha Sra, Tomas Pfister, and Jinsung Yoon
Zichen Chen, Jiefeng Chen, Sercan O. Arik, Misha Sra, Tomas Pfister, and Jinsung Yoon. 2025. CoDA: Agentic Systems for Collaborative Data Visualization.arXiv preprint arXiv:2510.03194(2025)
- [5]
-
[6]
2013.Apache Kafka
Nishant Garg. 2013.Apache Kafka. Packt Publishing
2013
-
[7]
Ken Gu, Ruoxi Shang, Ruien Jiang, Keying Kuang, et al. 2024. BLADE: Bench- marking Language Model Agents for Data-Driven Science. InFindings of the Association for Computational Linguistics: EMNLP 2024
2024
-
[8]
Enamul Hoque and Mohammed Saidul Islam. 2025. Natural Language Generation for Visualizations: State of the Art, Challenges and Future Directions.Computer Graphics Forum(2025)
2025
-
[9]
Jie Jiang, Haining Xie, Siqi Shen, Yu Shen, Zihan Zhang, Meng Lei, Yifeng Zheng, Yang Li, Chunyou Li, Danqing Huang, et al. 2025. SiriusBI: A Comprehensive LLM-Powered Solution for Data Analytics in Business Intelligence.Proceedings of the VLDB Endowment18, 12 (2025), 4860–4873
2025
- [10]
-
[11]
Jay Kreps, Neha Narkhede, Jun Rao, et al. 2011. Kafka: A distributed messaging system for log processing. InProceedings of the NetDB. Athens, Greece
2011
-
[12]
Leek and Roger D
Jeffery T. Leek and Roger D. Peng. 2015. What is the question?Science347, 6228 (2015), 1314–1315
2015
-
[13]
Guoliang Li, Xuanhe Zhou, and Xinyang Zhao. 2024. LLM for Data Management. Proceedings of the VLDB Endowment(2024). doi:10.14778/3685800.3685838
-
[14]
Shicheng Liu, Yucheng Jiang, Sajid Farook, Camila Nicollier Sanchez, David Fernando Castro Pena, and Monica S. Lam. 2026. DataSTORM: Deep Research on Large-Scale Databases using Exploratory Data Analysis and Data Storytelling. arXiv preprint arXiv:2604.06474(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [15]
-
[16]
Bodhisattwa Prasad Majumder, Harshit Surana, Dhruv Agarwal, Bhavana Dalvi Mishra, et al . 2025. DiscoveryBench: Towards Data-Driven Discovery with Large Language Models. InThe Thirteenth International Conference on Learn- ing Representations
2025
-
[17]
Bodhisattwa Prasad Majumder, Harshit Surana, Sanchaita Hazra, Ashish Sabhar- wal, and Peter Clark. 2024. Data-driven Discovery with Large Generative Models. InInternational Conference on Machine Learning
2024
-
[18]
Ludovico Mitchener, Angela Yiu, Benjamin Chang, Mathieu Bourdenx, et al
-
[19]
Kosmos: An AI Scientist for Autonomous Discovery.arXiv preprint arXiv:2511.02824(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [20]
- [21]
- [22]
-
[23]
Maojun Sun, Ruijian Han, Binyan Jiang, Houduo Qi, Defeng Sun, Yancheng Yuan, and Jian Huang. 2025. A Survey on Large Language Model-based Agents for Statistics and Data Science.The American Statistician(2025). doi:10.1080/ 00031305.2025.2561140
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Luoxuan Weng, Xingbo Wang, Junyu Lu, Yingchaojie Feng, Yihan Liu, Haozhe Feng, Danqing Huang, and Wei Chen. 2025. InsightLens: Augmenting LLM- Powered Data Analysis with Interactive Insight Management and Navigation. IEEE Transactions on Visualization and Computer Graphics(2025)
2025
-
[25]
Yang Wu, Yao Wan, Hongyu Zhang, Yulei Sui, Wucai Wei, Wei Zhao, Guandong Xu, and Hai Jin. 2024. Automated Data Visualization from Natural Language via Large Language Models: An Exploratory Study.Proceedings of the ACM on Management of Data2, 3, Article 115 (2024)
2024
- [26]
- [27]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.