How the Optimizer Shapes Learned Solutions in Equivariant Neural Networks
Pith reviewed 2026-06-29 17:56 UTC · model grok-4.3
The pith
Muon optimizer produces higher stable ranks in weights and representations, plus more regular loss surfaces, than Adam in equivariant networks on ModelNet40.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
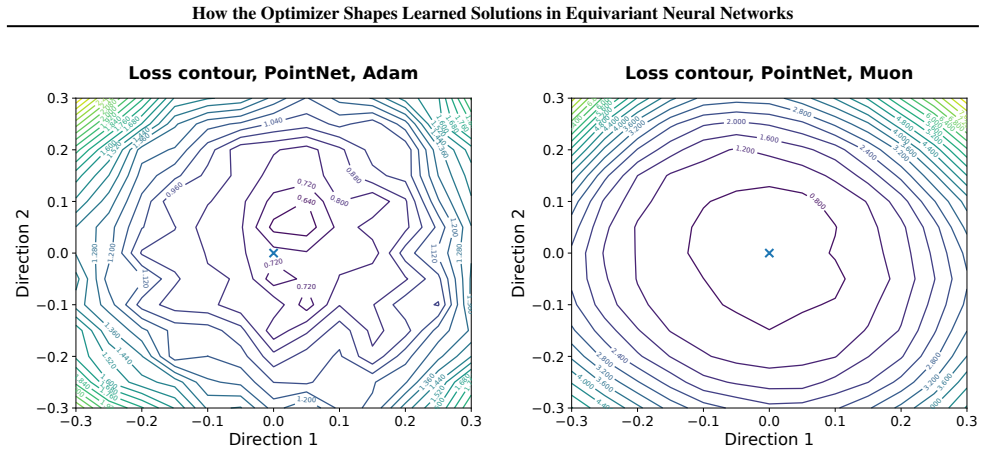
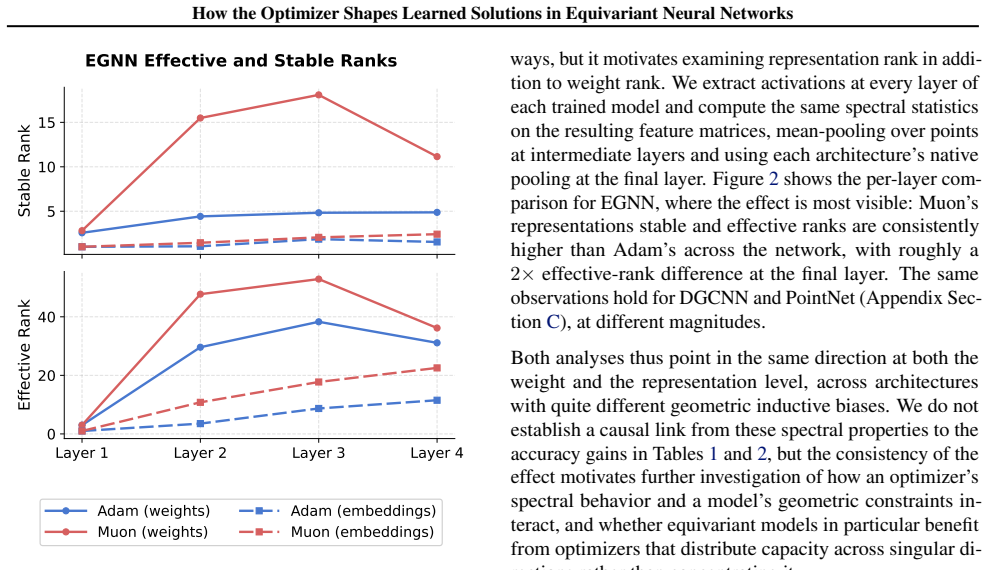
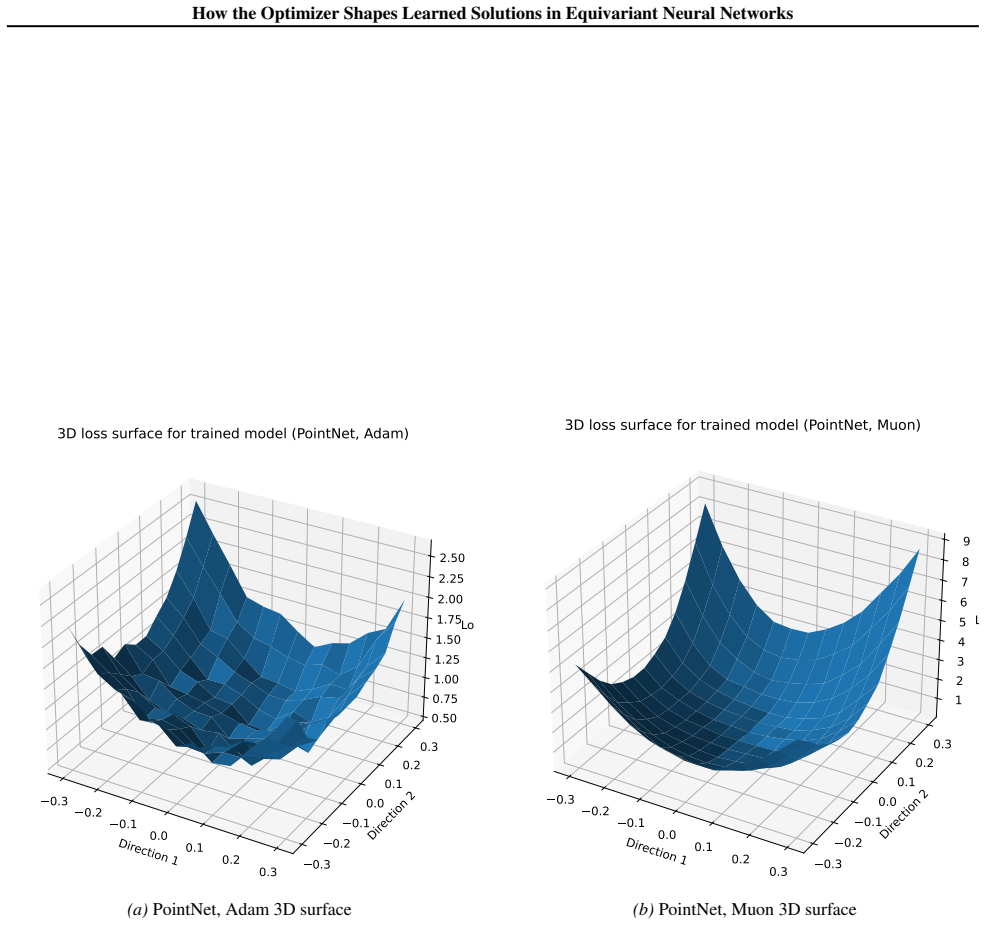
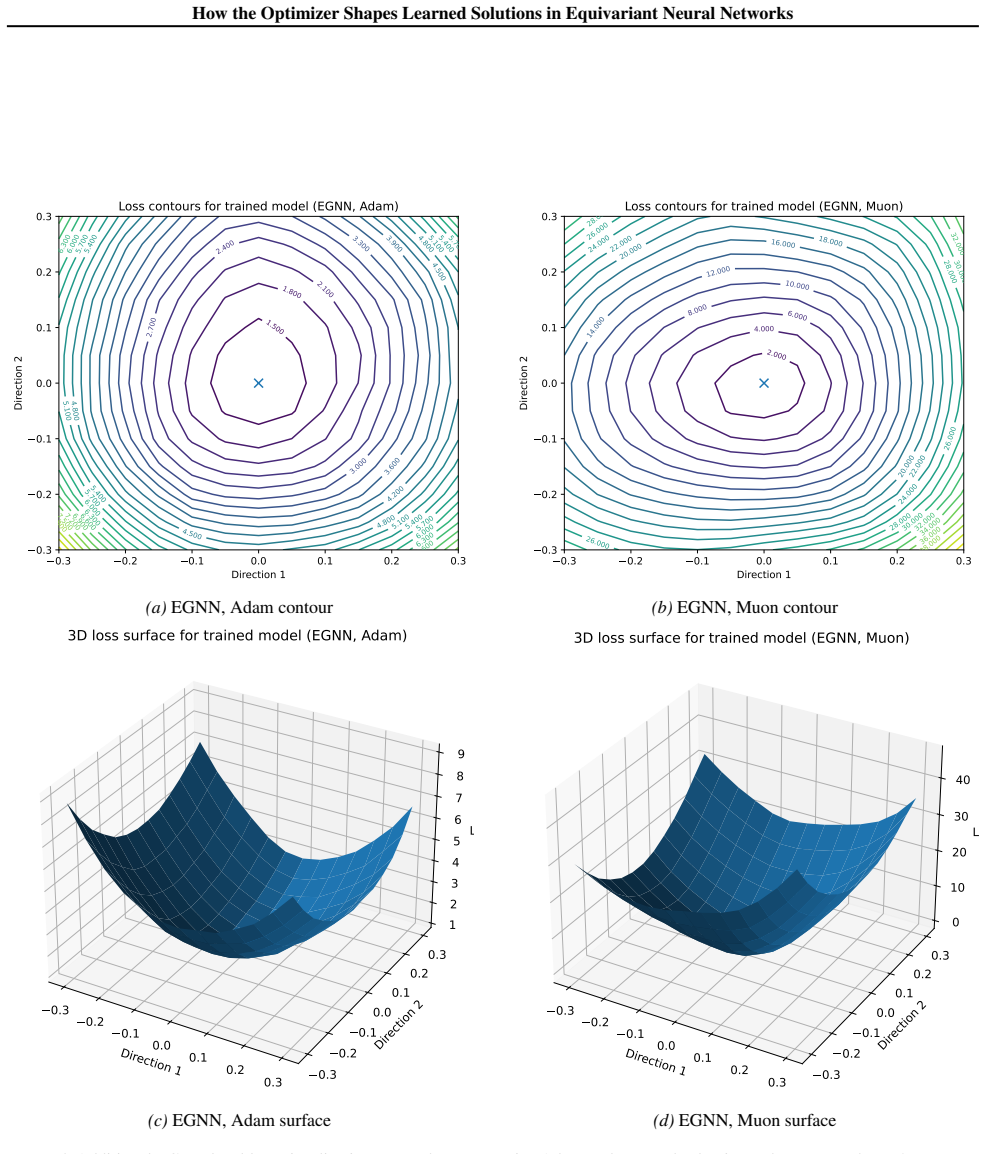
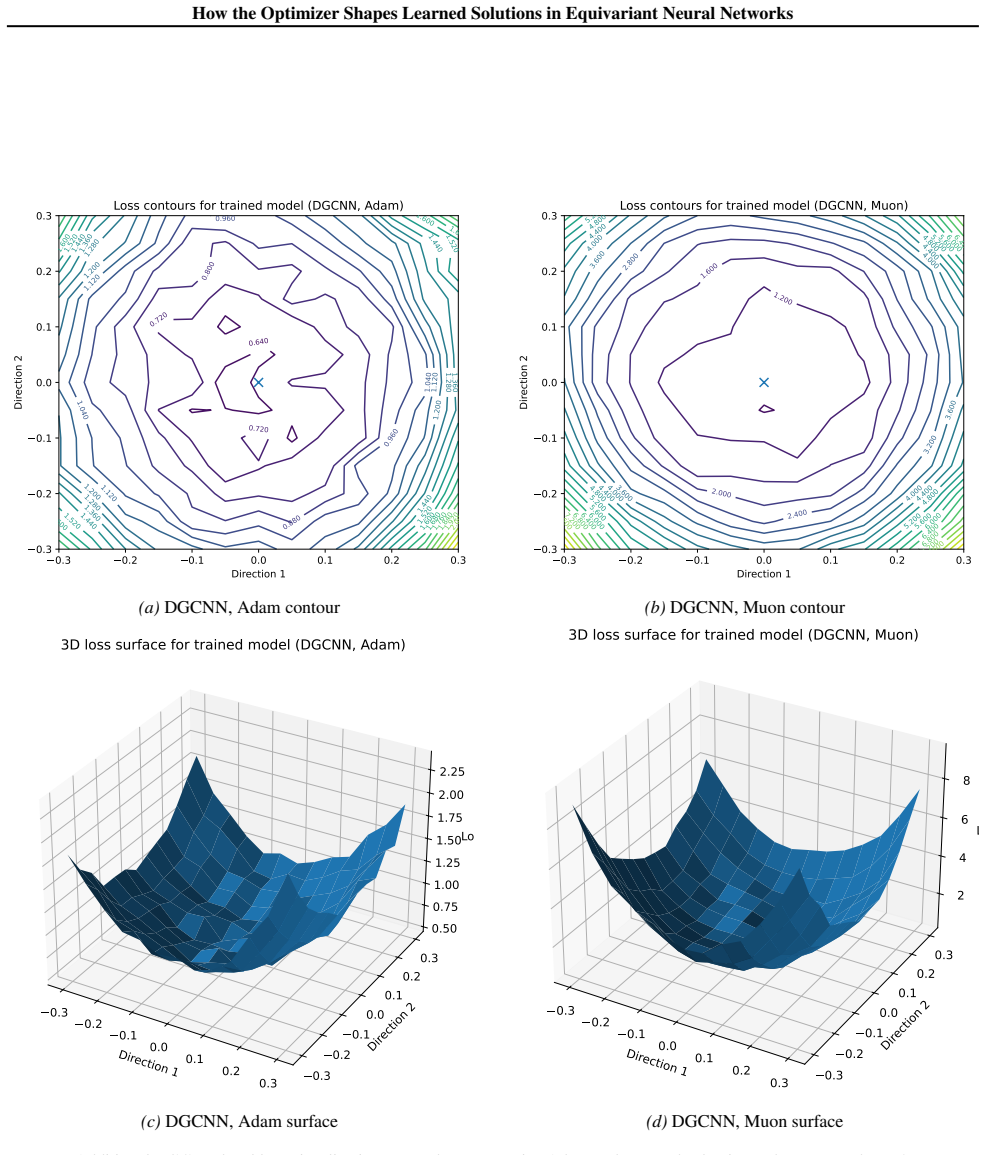
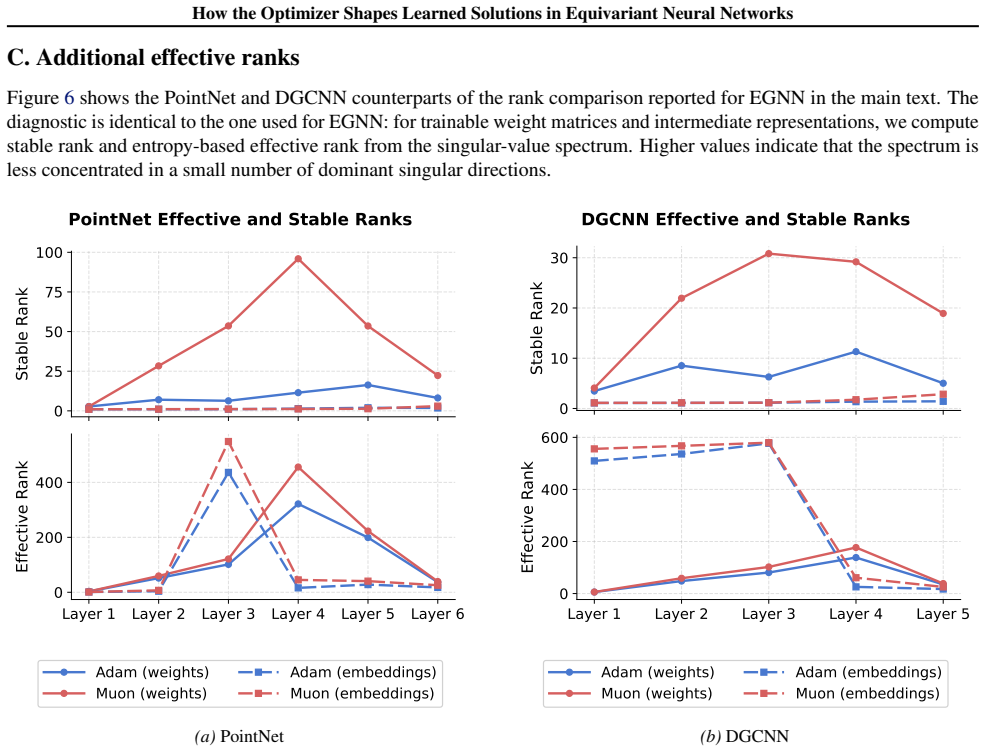
We study this direction by comparing Muon and Adam across several equivariant and geometric architectures under pointcloud and molecular learning settings. On ModelNet40, where the comparison is clearest, Muon consistently improves over Adam across all architectures considered. The checkpoints reached by Muon have larger Hessian curvature summaries but more regular loss surfaces, and their learned weights and representations have higher stable and effective ranks. These observations suggest that the interaction between optimizer design and geometric inductive bias deserves further attention from the community.
What carries the argument
Comparison of Muon versus Adam optimizers on equivariant architectures, measured through Hessian estimates, loss-surface visualizations, and spectral properties of learned weights and representations.
If this is right
- Muon improves performance over Adam on ModelNet40 for every equivariant architecture examined.
- Muon-trained checkpoints exhibit higher stable and effective ranks in both learned weights and intermediate representations.
- Muon produces loss surfaces that appear more regular even though they display larger Hessian curvature summaries.
- Optimizer choice interacts with the geometric inductive bias of equivariant networks to shape the properties of the final solution.
Where Pith is reading between the lines
- If the pattern generalizes, Muon could serve as a practical alternative to architectural relaxations when training equivariant models on geometric data.
- The higher-rank outcome may indicate that Muon allows networks to make fuller use of their built-in symmetry constraints.
- The same optimizer analysis could be applied to non-equivariant baselines or to other geometric datasets to test whether the effect is specific to symmetry-preserving architectures.
- Future work might examine whether the observed loss-surface regularity correlates with better generalization on out-of-distribution geometric inputs.
Load-bearing premise
Observed differences in performance, Hessian summaries, loss regularity, and rank metrics arise from the optimizer rather than from uncontrolled variations in training protocol, hyperparameters, or random seeds.
What would settle it
Re-running the ModelNet40 experiments with identical hyperparameters, training protocols, and random seeds while swapping only the optimizer, and finding no consistent differences in the reported performance, Hessian, loss-surface, or rank metrics.
Figures
read the original abstract
Equivariant neural networks encode geometric symmetries by construction, yet they are often difficult to optimize and can underperform less constrained architectures. A growing body of work addresses this through architectural modifications such as constraint relaxation or approximate equivariance, while the role of the optimizer remains comparatively underexplored. We study this direction by comparing Muon and Adam across several equivariant and geometric architectures under pointcloud and molecular learning settings. On ModelNet40, where the comparison is clearest, Muon consistently improves over Adam across all architectures considered. We then analyze the trained ModelNet40 checkpoints through Hessian estimates, loss surface visualizations, and spectral properties of learned weights and intermediate representations. The checkpoints reached by Muon have larger Hessian curvature summaries but more regular loss surfaces, and their learned weights and representations have higher stable and effective ranks. These observations suggest that the interaction between optimizer design and geometric inductive bias deserves further attention from the community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines how optimizer choice affects solutions in equivariant neural networks by comparing Muon and Adam on point-cloud (ModelNet40) and molecular tasks across several geometric architectures. It reports that Muon consistently outperforms Adam on ModelNet40, and that the resulting checkpoints exhibit larger Hessian curvature summaries yet more regular loss surfaces together with higher stable and effective ranks in both weights and intermediate representations.
Significance. If the attribution to the optimizer can be isolated, the work would usefully shift attention from purely architectural fixes for equivariant models toward optimizer–inductive-bias interactions, potentially explaining why some geometric networks remain hard to optimize and offering a practical lever for improving both accuracy and representation quality.
major comments (2)
- [ModelNet40 experiments] ModelNet40 experiments: the central performance and property claims rest on the assumption that all non-optimizer factors (hyperparameter schedules, data augmentations, regularization, random seeds) were held fixed or optimally tuned per optimizer. No description of separate hyperparameter searches, number of independent runs, or statistical tests is provided, so the observed gaps in accuracy, Hessian summaries, loss-surface regularity, and rank metrics cannot yet be causally attributed to Muon versus Adam.
- [Hessian and spectral analysis] Hessian and spectral analysis: the reported differences in curvature summaries and stable/effective ranks are presented as optimizer-induced, yet without the controls above it remains possible that these quantities simply track the higher accuracy rather than revealing a distinct optimization trajectory.
minor comments (1)
- [Abstract / Introduction] The abstract and introduction would benefit from a short statement of the precise architectures and datasets used, to allow readers to assess the scope of the comparison immediately.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental controls and the interpretation of our analyses. We respond point-by-point below and commit to revisions that address the concerns while preserving the core observations of the work.
read point-by-point responses
-
Referee: [ModelNet40 experiments] ModelNet40 experiments: the central performance and property claims rest on the assumption that all non-optimizer factors (hyperparameter schedules, data augmentations, regularization, random seeds) were held fixed or optimally tuned per optimizer. No description of separate hyperparameter searches, number of independent runs, or statistical tests is provided, so the observed gaps in accuracy, Hessian summaries, loss-surface regularity, and rank metrics cannot yet be causally attributed to Muon versus Adam.
Authors: We agree that the absence of these details limits causal attribution in the current manuscript. In revision we will add an explicit experimental protocol subsection describing separate hyperparameter grids for each optimizer (on a validation split), the ranges explored, the final schedules used, and results aggregated over five independent random seeds with standard deviations and paired statistical tests. This will be incorporated into both the main text and appendix. revision: yes
-
Referee: [Hessian and spectral analysis] Hessian and spectral analysis: the reported differences in curvature summaries and stable/effective ranks are presented as optimizer-induced, yet without the controls above it remains possible that these quantities simply track the higher accuracy rather than revealing a distinct optimization trajectory.
Authors: We accept that accuracy differences could partially explain some metric gaps. The revised manuscript will explicitly qualify the claims to state that the reported Hessian, loss-surface, and rank properties characterize the solutions obtained by each optimizer. We will also add a short controlled comparison (where feasible) of Muon and Adam checkpoints that reach comparable accuracy levels, together with a clearer statement that full isolation of trajectory effects would require further targeted experiments beyond the scope of the present study. revision: partial
Circularity Check
Purely empirical comparison; no derivations or fitted quantities
full rationale
The paper reports experimental results comparing Muon and Adam on equivariant architectures, with measurements of accuracy, Hessian summaries, loss surfaces, and rank metrics on ModelNet40. No equations, ansatzes, uniqueness theorems, or self-citations appear in the provided text. All claims rest on direct observation of trained checkpoints rather than any reduction of outputs to inputs by construction. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brehmer, J., Behrends, S., de Haan, P., and Cohen, T
URL https://openreview.net/forum? id=5wxCQDtbMo. Brehmer, J., Behrends, S., de Haan, P., and Cohen, T. Does equivariance matter at scale?, 2025. URL https:// arxiv.org/abs/2410.23179. Bronstein, M. M., Bruna, J., Cohen, T., and Velickovic, P. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.CoRR, abs/2104.13478, 2021. URLhttps://arxiv...
-
[2]
Elhag, A
URL https://openreview.net/forum? id=in7XC5RcjEn. Elhag, A. A. A., Rusch, T. K., Giovanni, F. D., and Bronstein, M. M. Relaxed equivariance via multitask learning. InICLR 2025 Workshop on Machine Learn- ing for Genomics Explorations, 2025. URL https: //openreview.net/forum?id=8kZSO4WbTh. Ghorbani, B., Krishnan, S., and Xiao, Y . An investiga- tion into ne...
2025
-
[3]
Adam: A Method for Stochastic Optimization
URL https://proceedings.mlr.press/ v97/ghorbani19b.html. G´omez-Bombarelli, R., Wei, J. N., Duvenaud, D., Hern´andez-Lobato, J. M., S ´anchez-Lengeling, B., She- berla, D., Aguilera-Iparraguirre, J., Hirzel, T. D., Adams, R. P., and Aspuru-Guzik, A. Automatic Chemical De- sign Using a Data-Driven Continuous Representation of Molecules.ACS Cent. Sci., 4(2)...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1021/acscentsci.7b00572 2018
-
[4]
Noci, L., Anagnostidis, S., Biggio, L., Orvieto, A., Singh, S
URL https://openreview.net/forum? id=NM4emKloy6. Noci, L., Anagnostidis, S., Biggio, L., Orvieto, A., Singh, S. P., and Lucchi, A. Signal propagation in transformers: theoretical perspectives and the role of rank collapse. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curra...
-
[5]
doi: 10.1162/neco.1994.6.1.147. URL https: //doi.org/10.1162/neco.1994.6.1.147. Pertigkiozoglou, S., Chatzipantazis, E., Trivedi, S., and Daniilidis, K. Improving equivariant model training via constraint relaxation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
-
[6]
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
URL https://openreview.net/forum? id=tWkL7k1u5v. Petrache, M. and Trivedi, S. Approximation-generalization trade-offs under (approximate) group equivariance. In Thirty-seventh Conference on Neural Information Pro- cessing Systems, 2023. URL https://openreview. net/forum?id=DnO6LTQ77U. Qi, C. R., Su, H., Mo, K., and Guibas, L. J. Pointnet: Deep learning on...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
ISSN 2052-4463. doi: 10.1038/sdata.2014.22. Roy, O. and Vetterli, M. The effective rank: A measure of effective dimensionality. In2007 15th European Signal Processing Conference, pp. 606–610, 2007. Satorras, V . G., Hoogeboom, E., and Welling, M. E(n) equiv- ariant graph neural networks. In Meila, M. and Zhang, T. (eds.),Proceedings of the 38th Internatio...
-
[8]
ISSN 0730-0301. doi: 10.1145/3326362. URL https://doi.org/10.1145/3326362. Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., and Xiao, J. 3d shapenets: A deep representation for volumetric shapes.2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1912–1920,
-
[9]
org/CorpusID:206592833
URL https://api.semanticscholar. org/CorpusID:206592833. Xie, Y . and Smidt, T. A tale of two symmetries: Exploring the loss landscape of equivariant models. InThe Thirty- ninth Annual Conference on Neural Information Pro- cessing Systems, 2025. URL https://openreview. net/forum?id=rH4aGTL4jY. Xie, Y ., Daigavane, A., Kotak, M., and Smidt, T. The price of...
2025
-
[10]
6 How the Optimizer Shapes Learned Solutions in Equivariant Neural Networks A
URL https://openreview.net/forum? id=EvIwwGYTLc. 6 How the Optimizer Shapes Learned Solutions in Equivariant Neural Networks A. More quantitative results This section collects the additional graph message-passing experiments referenced in the main text. These experiments are intended to test whether the optimizer effect observed on the 3D ModelNet40 and Q...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.