On the Equivariant Learning of the Q-tensor Order Parameter
Pith reviewed 2026-06-29 15:00 UTC · model grok-4.3
The pith
Equivariant neural networks built for cyclic rotation groups predict the two-dimensional Q-tensor order parameter more accurately than non-equivariant models and satisfy the symmetry constraint to machine precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
All seven equivariant models satisfy the Q-tensor equivariance constraint to within single-precision floating point accuracy. Comparing against approximate parameter-matched non-equivariant benchmarks, with and without data augmentation, the equivariant models consistently achieve lower errors and generalize more robustly to unseen defect configurations. Performance increases with group order.
What carries the argument
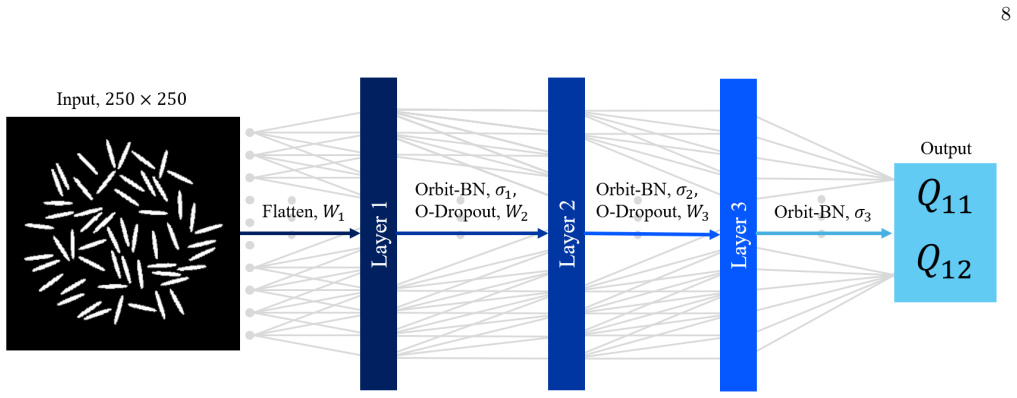
Rotation-like permutation matrix groups with elements ρ_Ck(g) that act on row-wise vectorized images to approximate a 2π/k rotation of the circular subdomain on square images.
If this is right
- Equivariant models achieve lower prediction errors than non-equivariant baselines on the same task.
- Equivariant models generalize more robustly to defect configurations not present in training data.
- Prediction accuracy improves as the order of the cyclic symmetry group increases.
- All constructed models meet the Q-tensor equivariance constraint to machine precision regardless of group order.
Where Pith is reading between the lines
- The same permutation-matrix construction could be reused for other image-to-tensor regression tasks that possess discrete rotational symmetry.
- As group order grows, the models approach continuous rotation equivariance, suggesting a practical route to SO(2)-equivariant predictors without explicit Fourier or steerable layers.
- The observed robustness gain may reduce reliance on data augmentation when training on limited defect datasets.
Load-bearing premise
The permutation matrices accurately approximate true rotations of the image domain for each cyclic group order.
What would settle it
An experiment in which any of the high-order equivariant models violates the Q-tensor equivariance constraint by more than single-precision error on a held-out rotation, or fails to show lower error than the non-equivariant baseline on unseen defects.
Figures




read the original abstract
We construct and evaluate group-equivariant neural networks for the prediction of the two-dimensional $Q$-tensor order parameter of nematic liquid crystals from synthetically generated microscopic textures. Seven architectures, equivariant to cyclic groups $C_k$ of order $k$ for $k=4,\,8,\,16,\,32,\,64,\,128,\, 256$, are built using a combination of weight-sharing constraints, equivariant activations and regularization techniques. To do this, we construct rotation-like permutation matrix groups with elements $\varrho_{C_k}(g)$ that act on row-wise vectorized images, thereby approximating a $\frac{2\pi}{k}$ rotation of the circular subdomain on square images. We show that all seven equivariant models satisfy the $Q$-tensor equivariance constraint to within single-precision floating point accuracy. Comparing against approximate parameter-matched non-equivariant benchmarks, with and without data augmentation, we find that the equivariant models consistently achieve lower errors and generalize more robustly to unseen defect configurations. Performance increases with group order, suggesting that the incorporation of finer rotational symmetry leads to lower errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript constructs seven group-equivariant neural networks for predicting the 2D Q-tensor order parameter of nematic liquid crystals from synthetic microscopic textures. Architectures are made equivariant to cyclic groups C_k (k=4 to 256) via weight sharing, equivariant activations, and regularization, using permutation-matrix group actions ρ_Ck(g) that approximate 2π/k rotations on row-wise vectorized square images of a circular subdomain. The authors report that all models satisfy the Q-tensor equivariance constraint to single-precision floating-point accuracy, outperform parameter-matched non-equivariant baselines (with and without augmentation), and show improving performance as group order increases.
Significance. If the central claims hold after addressing the approximation fidelity, the work would demonstrate a concrete method for embedding discrete rotational symmetries into models for soft-matter order-parameter prediction, with empirical evidence that finer symmetry groups yield lower errors and better generalization to unseen defects. The scaling of performance with k is a potentially useful observation for symmetry-aware learning in condensed-matter applications.
major comments (2)
- [Abstract and §3] Abstract and §3 (construction of ρ_Ck(g)): The permutation matrices are defined to approximate rigid rotations of the circular domain on square grids. No quantitative bound is given on the approximation error (e.g., maximum displacement, interpolation residual, or ||ρ_Ck(g) v - R(g) v||_2 for vectorized image v and continuous rotation R(g)) as a function of k. For k ≥ 64 this error can exceed single-precision round-off near boundaries, which directly affects whether the reported “single-precision equivariance” test establishes physical rotational equivariance or only equivariance under the discrete proxy group.
- [Results] Results (equivariance verification and performance scaling): The claim that performance increases with group order presupposes that the discrete approximation itself improves or remains sufficiently accurate with k. Without an error analysis of the group action versus the underlying continuous symmetry, the observed trend could be an artifact of the particular discretization rather than a genuine symmetry benefit, weakening the central comparison to non-equivariant baselines.
minor comments (2)
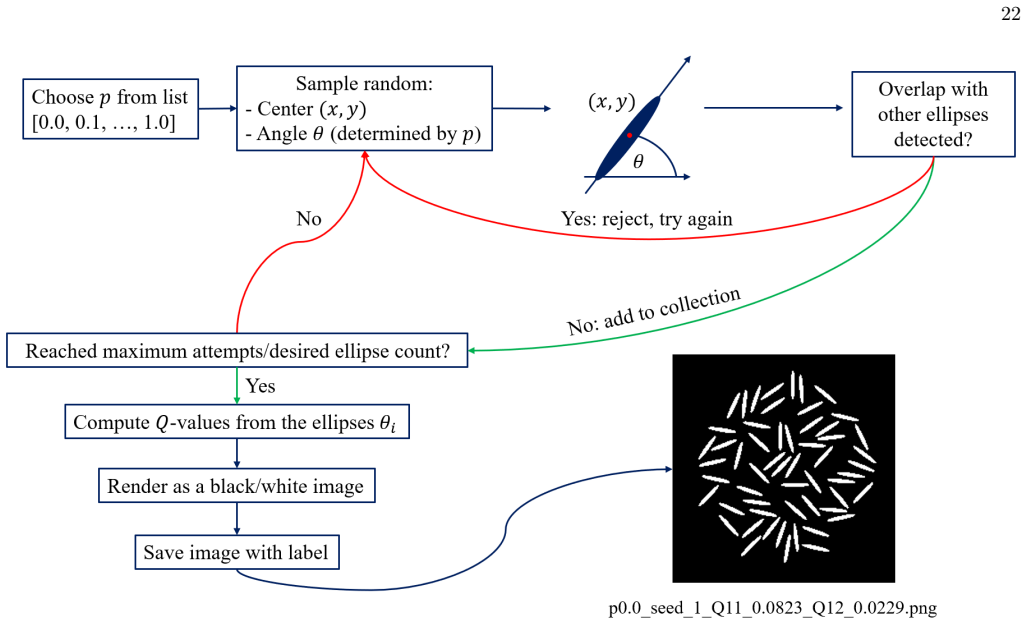
- [Methods] Data-generation and training protocols (Methods) are described only at high level; explicit statements of image resolution, defect-generation parameters, train/test split sizes, optimizer settings, and exact loss metrics would improve reproducibility.
- [§2] Notation for the Q-tensor components and the precise definition of the equivariance constraint (e.g., how the output tensor transforms under ρ_Ck(g)) should be stated explicitly in an early section to avoid ambiguity when comparing to the numerical test.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help clarify the distinction between discrete group equivariance and continuous rotational symmetry. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (construction of ρ_Ck(g)): The permutation matrices are defined to approximate rigid rotations of the circular domain on square grids. No quantitative bound is given on the approximation error (e.g., maximum displacement, interpolation residual, or ||ρ_Ck(g) v - R(g) v||_2 for vectorized image v and continuous rotation R(g)) as a function of k. For k ≥ 64 this error can exceed single-precision round-off near boundaries, which directly affects whether the reported “single-precision equivariance” test establishes physical rotational equivariance or only equivariance under the discrete proxy group.
Authors: We agree that the manuscript does not provide a quantitative analysis of the approximation error between the discrete permutation matrices ρ_Ck(g) and the continuous rotation operator. The equivariance verification in the paper demonstrates that the networks satisfy the equivariance constraint exactly (to single-precision) with respect to the discrete group actions we defined. This is the symmetry group under which the models are constructed and trained. To strengthen the connection to physical rotations, we will add an analysis in a revised version quantifying the approximation error as a function of k, including metrics such as the L2 norm difference and boundary displacement errors. This will allow readers to assess the fidelity for larger k. revision: yes
-
Referee: [Results] Results (equivariance verification and performance scaling): The claim that performance increases with group order presupposes that the discrete approximation itself improves or remains sufficiently accurate with k. Without an error analysis of the group action versus the underlying continuous symmetry, the observed trend could be an artifact of the particular discretization rather than a genuine symmetry benefit, weakening the central comparison to non-equivariant baselines.
Authors: The observed improvement in performance with increasing group order is an empirical result from our experiments. We acknowledge that without a detailed comparison of the discrete group action error to the continuous case, it is possible that part of the trend relates to how the discretization behaves at different k. However, since all models use the same underlying image representation and the non-equivariant baselines do not incorporate any symmetry, the consistent outperformance suggests a benefit from the equivariance constraint. We will revise the manuscript to include the requested error analysis of the group actions, which will help substantiate that the scaling reflects improved symmetry enforcement rather than discretization artifacts. revision: yes
Circularity Check
No circularity: equivariance enforced by construction but performance claims are empirical
full rationale
The paper explicitly constructs the seven models to be equivariant to the discrete cyclic groups via weight-sharing, activations, and the defined permutation matrices ρ_Ck(g), then numerically verifies that the Q-tensor constraint holds to single-precision accuracy. Performance comparisons are made against separately trained non-equivariant benchmarks on held-out synthetic defect data, with the observed error reduction and scaling with group order presented as empirical outcomes. No step equates a claimed prediction or first-principles result to its own fitted inputs or prior self-citations by definition; the rotation approximation is stated as such and does not render the generalization results tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The permutation matrix groups ρ_Ck(g) accurately approximate 2π/k rotations on square images of circular subdomains.
Reference graph
Works this paper leans on
-
[1]
No- tably, our study pertains to (simulated)molecularsys- tems of nematics
Contribution of this Article Our work in this article complements, but differs from, the existing work performed in the literature to date. No- tably, our study pertains to (simulated)molecularsys- tems of nematics. In contrast, many of the pre-existing works in the literature focus on meso- or macroscopic sys- tems of either simulated or experimental liq...
-
[2]
equivarification
Literature Review on Equivariant Learning Machine learning has become foundational in data- driven scientific research [34]. Since the development of multi-layer feedforward networks and the popularization of the backpropagation algorithm by [43], a further resur- gence of interest in artificial neural networks followed the landmark application of deep co...
2012
-
[3]
But in equivariant neural networks, this is different and several nodes can be related to one another
Weight Sharing In standard (non-equivariant) networks, every feature or node within a layer is treated independently and no relationships between them assumed. But in equivariant neural networks, this is different and several nodes can be related to one another. The nodes rely on orbits, which dictate how parameters are shared. Suppose a symmetry groupGac...
-
[4]
Specifically, the network must satisfy ν(ϱCk,0 (gp)x) =R 4pπ k ν(x),(9) wheregis the generator element ofC k, and withp= 1,
Equivariant Architectures The neural networks (8) will obey theC k-equivariance constraint below by construction and predictν≈⃗ qas defined in (5). Specifically, the network must satisfy ν(ϱCk,0 (gp)x) =R 4pπ k ν(x),(9) wheregis the generator element ofC k, and withp= 1, . . . k. This is only true if the weights satisfy the con- ditions (13) and (14). The...
-
[5]
By Schur’s lemma [44], equivariant linear maps can only connect matching irreducible repre- sentations (irreps) between adjacent layers
Propagation of Equivariance Through Weight-Constrained Layers In theseC k-equivariant networks, the group action at each layer is encoded as a representation that constrains the learnable weights. By Schur’s lemma [44], equivariant linear maps can only connect matching irreducible repre- sentations (irreps) between adjacent layers. Information associated ...
-
[6]
fixes” the corners so that the transformations appears as a “rotation
Rotation-like representations The first type is where the cyclic representations, cor- responding toC k, act as 2π k rotations. This means that they permute the input (vectorized square image) in such a way that when the output is reconstructed back into an image, it appears as an approximately rotated version of the input. Note that when applying these t...
-
[7]
Note that ρC4,3(gp) is a special case; it is the direct sum of two smaller 4×4 such (cyclic) matrices
Regular representations The weight matrices connecting layer 1 to layer 2 (by W2) and those that connect layer 2 to the (final hidden) layer 3 (usingW 3) are constrained by the following per- mutation matrices: ρCk,2(gp)W2 =W 2ϱCk,1 (gp) ρCk,3(gp)W3 =W 3ρCk,2(gp), (14) whereρ Ck,2(gp), ρ Ck,3(gp) are implemented as cyclic shift matrices (regular represent...
-
[8]
We can give a general form of the intertwinerL∈ R2×k/2, which is required to satisfy: LρCk,3 (gp) =R 2 2pπ k L =R 4pπ k L, (15) forp= 1,
The IntertwinerL The final layer of ourC k-equivariant networks must be at least of size k 2 . We can give a general form of the intertwinerL∈ R2×k/2, which is required to satisfy: LρCk,3 (gp) =R 2 2pπ k L =R 4pπ k L, (15) forp= 1, . . . , k, whereR 4pπ k comes from the equivariance condition of theC k-equivariant networks, ν(ϱCk,0 (gp)x) =R 4pπ k ν(x). 9...
-
[9]
For example, consider the Rectified Linear Unit (ReLU) activation σ(y) = ReLU(y) = (max(0, y0),max(0, y 1),
Equivariant Activations In general, commonly-used activations, such as ReLU or tanh, break equivariance so that for two arbitrary group representations,π 1 andπ 2, they are such that σ(π1(g)y)̸=π 2(g)σ(y) for some vectory. For example, consider the Rectified Linear Unit (ReLU) activation σ(y) = ReLU(y) = (max(0, y0),max(0, y 1), . . . ,max(0, yi)) and def...
-
[10]
take on more responsibility
Equivariant Regularization Batch normalization (BN) [28] is a method used to stabilise the loss landscape and speed-up model training by normalizing the inputs prior to an activation func- tion. Standard BN, however, does not preserve equivari- ance. To show this, consider a symmetry groupGact- ing on feature indices{1,2, . . . , N}. Regular BN breaks the...
-
[11]
Comments on Orbit-regularization OrbitBN and OrbitDropout are therefore just altered forms of the classic batch normalization and dropout methods, which are widely used in neural networks. In- stead of processing features of a layer independently, which would break equivariance constraints, the two methods presented here operate over orbits, which con- ta...
-
[12]
John Ball,Mathematics of liquid crystals, Cambridge Centre for Analysis short course, 13-17 February 2012, https://people.maths.ox.ac.uk/ball/Teaching/ cambridge.pdf
2012
- [13]
-
[14]
Erik J. Bekkers, Maxime W. Lafarge, Mitko Veta, Koen A. J. Eppenhof, Josien P. W. Pluim, and Remco Duits, Roto-translation covariant convolutional networks for medical image analysis, Medical Image Computing and Computer Assisted Intervention – MICCAI 2018 (Cham) (Alejandro F. Frangi, Julia A. Schnabel, Christos Da- vatzikos, Carlos Alberola-L´ opez, and ...
-
[15]
Rebecca Betts and Ingo Dierking,Machine learning clas- sification of polar sub-phases in liquid crystal mhpobc, Soft Matter19(2023), 7502–7512,http://dx.doi.org/ 10.1039/D3SM00902E
-
[16]
Eric R. Beyerle and Pratyush Tiwary,Inferring the isotropic-nematic phase transition with generative ma- chine learning, Phys. Rev. Lett.135(2025), 068102, https://link.aps.org/doi/10.1103/1wdj-ym3s
-
[17]
Gabriele Cesa,E(2)-equivariant steerable cnns, Msc ar- tificial intelligence master thesis, University of Am- sterdam, 2018,https://gabri95.github.io/Thesis/ thesis.pdf
2018
-
[18]
Wallach, H
Taco Cohen, Mario Geiger, and Maurice Weiler,A general theory of equivariant cnns on homogeneous spaces, Advances in Neural Information Processing Systems (H. Wallach, H. Larochelle, A. Beygelz- imer, F. d'Alch´ e-Buc, E. Fox, and R. Garnett, eds.), vol. 32, Curran Associates, Inc., 2019,https: //proceedings.neurips.cc/paper_files/paper/2019/ file/b9cfe8b...
2019
-
[19]
97, PMLR, 09–15 Jun 2019,https://proceedings.mlr.press/v97/cohen19d
Taco Cohen, Maurice Weiler, Berkay Kicanaoglu, and Max Welling,Gauge equivariant convolutional networks and the icosahedral CNN, Proceedings of the 36th In- ternational Conference on Machine Learning (Kamalika Chaudhuri and Ruslan Salakhutdinov, eds.), Proceedings of Machine Learning Research, vol. 97, PMLR, 09–15 Jun 2019,https://proceedings.mlr.press/v9...
2019
-
[20]
Wein- berger, eds.), Proceedings of Machine Learning Research, vol
Taco Cohen and Max Welling,Group equivariant con- volutional networks, Proceedings of The 33rd Interna- tional Conference on Machine Learning (New York, New York, USA) (Maria Florina Balcan and Kilian Q. Wein- berger, eds.), Proceedings of Machine Learning Research, vol. 48, PMLR, 20–22 Jun 2016,https://proceedings. mlr.press/v48/cohenc16.html, pp. 2990–2999
2016
-
[21]
Cohen, Mario Geiger, Jonas K¨ ohler, and Max Welling,Spherical CNNs, International Conference on Learning Representations, 2018,https://openreview
Taco S. Cohen, Mario Geiger, Jonas K¨ ohler, and Max Welling,Spherical CNNs, International Conference on Learning Representations, 2018,https://openreview. net/forum?id=Hkbd5xZRb
2018
-
[22]
Cohen and Max Welling,Steerable cnns, Inter- national Conference on Learning Representations (2017), 1–14,https://openreview.net/pdf?id=rJQKYt5ll
Taco S. Cohen and Max Welling,Steerable cnns, Inter- national Conference on Learning Representations (2017), 1–14,https://openreview.net/pdf?id=rJQKYt5ll
2017
-
[23]
Red- ford, Linnea M
Jonathan Colen, Ming Han, Rui Zhang, Steven A. Red- ford, Linnea M. Lemma, Link Morgan, Paul V. Ruij- grok, Raymond Adkins, Zev Bryant, Zvonimir Dogic, Margaret L. Gardel, Juan J. de Pablo, and Vincenzo Vitelli,Machine learning active-nematic hydrodynamics, Proceedings of the National Academy of Sciences118 (2021), no. 10, e2016708118,https://doi.org/10.1...
2021
-
[24]
Cybenko,Approximation by superpositions of a sigmoidal function, Mathematics of Control, Signals and Systems2(1989), 303–314,https://doi.org/10
George V. Cybenko,Approximation by superpositions of a sigmoidal function, Mathematics of Control, Signals and Systems2(1989), 303–314,https://doi.org/10. 1007/BF02551274
1989
-
[25]
Francesco de Anna and Arghir D. Zarnescu,Uniqueness of weak solutions of the full coupled navier–stokes andq- tensor system in 2d, Communications in Mathematical Sciences14(2016), no. 8, 2127–2178,https://dx.doi. org/10.4310/CMS.2016.v14.n8.a3
-
[26]
14 press/v48/dieleman16.html
Sander Dieleman, Jeffrey De Fauw, and Koray Kavukcuoglu,Exploiting cyclic symmetry in convolu- tional neural networks, International Conference on Machine Learning, 2016,https://proceedings.mlr. 14 press/v48/dieleman16.html
2016
-
[27]
7-10, 1526–1540,https://doi.org/10.1080/ 02678292.2022.2150790
Ingo Dierking, Jason Dominguez, James Harbon, and Joshua Heaton,Classification of liquid crystal textures using convolutional neural networks, Liquid Crystals50 (2022), no. 7-10, 1526–1540,https://doi.org/10.1080/ 02678292.2022.2150790
-
[28]
Ingo Dierking, Jason Dominguez, James Harbon, and Joshua Heaton,Deep learning techniques for the localiza- tion and classification of liquid crystal phase transitions, Frontiers in Soft MatterV olume 3 - 2023(2023), 1–11, https://doi.org/10.3389/frsfm.2023.1114551
-
[29]
7-10, 1461–1477, https://doi.org/10.1080/02678292.2023.2221654
Ingo Dierking, Jason Dominguez, James Harbon, and Joshua Heaton,Testing different supervised machine learning architectures for the classification of liquid crys- tals, Liquid Crystals50(2023), no. 7-10, 1461–1477, https://doi.org/10.1080/02678292.2023.2221654
-
[30]
119, PMLR, 13–18 Jul 2020,https://proceedings
Marc Finzi, Samuel Stanton, Pavel Izmailov, and An- drew Gordon Wilson,Generalizing convolutional neural networks for equivariance to lie groups on arbitrary con- tinuous data, Proceedings of the 37th International Con- ference on Machine Learning (Hal Daum´ e III and Aarti Singh, eds.), Proceedings of Machine Learning Research, vol. 119, PMLR, 13–18 Jul ...
2020
-
[31]
139, PMLR, 2021,https://proceedings.mlr.press/v139/ finzi21a.html, pp
Marc Finzi, Max Welling, and Andrew Gordon Wil- son,A practical method for constructing equivariant multilayer perceptrons for arbitrary matrix groups, Pro- ceedings of the 38th International Conference on Ma- chine Learning (Marina Meila and Tong Zhang, eds.), Proceedings of Machine Learning Research, vol. 139, PMLR, 2021,https://proceedings.mlr.press/v1...
2021
-
[32]
W.T. Freeman and E.H. Adelson,The design and use of steerable filters, IEEE Transactions on Pattern Anal- ysis and Machine Intelligence13(1991), no. 9, 891–906, https://doi.org/10.1109/34.93808
-
[33]
P G De Gennes and J Prost,The physics of liquid crys- tals, Oxford University Press, 12 1993,https://doi. org/10.1093/oso/9780198520245.001.0001
-
[34]
Jan E. Gerken, Oscar Carlsson, Hampus Linander, Fredrik Ohlsson, Christoffer Petersson, and Daniel Persson,Equivariance versus augmentation for spher- ical images, Proceedings of the 39th International Conference on Machine Learning (Kamalika Chaud- huri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, eds.), Proceedings of Machin...
2022
-
[35]
235, PMLR, 21–27 Jul 2024,https://proceedings.mlr
Jan E Gerken and Pan Kessel,Emergent equivariance in deep ensembles, Proceedings of the 41st International Conference on Machine Learning (Ruslan Salakhutdi- nov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, eds.), Proceedings of Machine Learning Research, vol. 235, PMLR, 21–27 Jul 2024,https://proce...
2024
-
[36]
Dan Hendrycks and Kevin Gimpel,Gaussian error lin- ear units (gelus), 2023,https://arxiv.org/abs/1606. 08415
2023
-
[37]
5, 359–366,https: //doi.org/10.1016/0893-6080(89)90020-8
Kurt Hornik, Maxwell Stinchcombe, and Halbert White, Multilayer feedforward networks are universal approxima- tors, Neural Networks2(1989), no. 5, 359–366,https: //doi.org/10.1016/0893-6080(89)90020-8
-
[39]
37, PMLR, 2015,https://proceedings
Sergey Ioffe and Christian Szegedy,Batch normaliza- tion: Accelerating deep network training by reducing in- ternal covariate shift, Proceedings of the 32nd Interna- tional Conference on Machine Learning (Francis Bach and David Blei, eds.), Proceedings of Machine Learning Research, vol. 37, PMLR, 2015,https://proceedings. mlr.press/v37/ioffe15.html, pp. 448–456
2015
-
[40]
Gautam Iyer, Xiang Xu, and Arghir D. Zarnescu,Dy- namic cubic instability in a 2d q-tensor model for liq- uid crystals, Mathematical Models and Methods in Ap- plied Sciences25(2015), no. 08, 1477–1517,https: //doi.org/10.1142/S0218202515500396
-
[41]
Helge Kr¨ anz, Volkmar Vill, and Bernd Meyer,Predic- tion of material properties from chemical structures. the clearing temperature of nematic liquid crystals derived from their chemical structures by artificial neural net- works, Journal of Chemical Information and Computer Sciences36(1996), no. 6, 1173–1177,https://doi.org/ 10.1021/ci960482r
-
[42]
Hin- ton,Imagenet classification with deep convolutional neu- ral networks, Commun
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hin- ton,Imagenet classification with deep convolutional neu- ral networks, Commun. ACM60(2017), no. 6, 84–90, https://doi.org/10.1145/3065386
-
[43]
Maxime W. Lafarge, Erik J. Bekkers, Josien P.W. Pluim, Remco Duits, and Mitko Veta,Roto-translation equivariant convolutional networks: Application to histopathology image analysis, Medical Image Analysis 68(2021), 101849,https://doi.org/10.1016/j.media. 2020.101849
-
[44]
Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE86(1998), no. 11, 2278–2324, https://doi.org/10.1109/5.726791
-
[45]
7553, 436–444, https://doi.org/10.1038/nature14539
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton,Deep learning, Nature (London)521(2015), no. 7553, 436–444, https://doi.org/10.1038/nature14539
-
[46]
A. H. Lewis, D. G. A. L. Aarts, P. D. Howell, and A. Ma- jumdar,Nematic equilibria on a two-dimensional annu- lus, Studies in Applied Mathematics138(2017), no. 4, 438–466,https://doi.org/10.1111/sapm.12161
-
[47]
10, 104410,http: //dx.doi.org/10.1103/PhysRevB.99.104410
Ke Liu, Jonas Greitemann, and Lode Pollet,Learning multiple order parameters with interpretable machines, Physical Review B99(2019), no. 10, 104410,http: //dx.doi.org/10.1103/PhysRevB.99.104410
-
[48]
Pui-Wai Ma and T.-H. Hubert Chan,A feedforward uni- tary equivariant neural network, Neural Networks161 (2023), 154–164,https://doi.org/10.1016/j.neunet. 2023.01.042
-
[49]
Introduction to Q-tensor theory
Nigel J. Mottram and Christopher J. P. Newton,Intro- duction to q-tensor theory, 2014,https://arxiv.org/ abs/1409.3542
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[50]
2, 255–264,https://doi.org/10.1080/02678292
Natalia Osiecka-Drewniak, Anna Drzewicz, and Ewa Juszynska-Galazka,Machine learning studies for liquid crystal texture recognition, Liquid Crystals51(2024), no. 2, 255–264,https://doi.org/10.1080/02678292. 2023.2292635
-
[51]
70, PMLR, 06–11 Aug 2017,https://proceedings.mlr
Siamak Ravanbakhsh, Jeff Schneider, and Barnab´ as P´ oczos,Equivariance through parameter-sharing, Pro- ceedings of the 34th International Conference on Ma- 15 chine Learning (Doina Precup and Yee Whye Teh, eds.), Proceedings of Machine Learning Research, vol. 70, PMLR, 06–11 Aug 2017,https://proceedings.mlr. press/v70/ravanbakhsh17a.html, pp. 2892–2901
2017
-
[52]
1, 421–441, https://doi.org/10.1007/BF01516710
Friedrich Reinitzer,Beitr¨ age zur kenntniss des cholesterins, Monatshefte f¨ ur Chemie und verwandte Teile anderer Wissenschaften9(1888), no. 1, 421–441, https://doi.org/10.1007/BF01516710
-
[53]
J. Rotman,An introduction to the theory of groups, Graduate Texts in Mathematics, Springer New York, 1999,https://doi.org/10.1007/978-1-4612-4176-8
-
[54]
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams,Learning representations by back-propagating errors, Nature323(1986), 533–536,https://doi.org/ 10.1038/323533a0
-
[55]
1007/978-1-4684-9458-7
Jean-Pierre Serre,Linear representations of finite groups, Springer-Verlag, New York, 1977,https://doi.org/10. 1007/978-1-4684-9458-7. MR 0450380 (56 #8675)
1977
-
[56]
Shawe-Taylor,Building symmetries into feedfor- ward networks, Artificial Neural Networks, 1989., First IEE International Conference, Conf
J. Shawe-Taylor,Building symmetries into feedfor- ward networks, Artificial Neural Networks, 1989., First IEE International Conference, Conf. Publ. No. 313, IET, 1989,https://ieeexplore.ieee.org/abstract/ document/51951, pp. 158–162
1989
-
[57]
Baoming Shi, Apala Majumdar, and Lei Zhang,Neu- ral network-based tensor models for liquid crystals with molecular-level information, Phys. Rev. E113 (2026), 015401,https://link.aps.org/doi/10.1103/ 7v32-lr9w
2026
-
[58]
H. Y. D. Sigaki, R. F. de Souza, R. T. de Souza, R. S. Zola, and H. V. Ribeiro,Estimating physical prop- erties from liquid crystal textures via machine learn- ing and complexity-entropy methods, Phys. Rev. E99 (2019), 013311,https://doi.org/10.1103/PhysRevE. 99.013311
-
[59]
Higor Y. D. Sigaki, Ervin K. Lenzi, Rafael S. Zola, Matjaˇ z Perc, and Haroldo V. Ribeiro,Learning physical properties of liquid crystals with deep convolutional neu- ral networks, Scientific Reports10(2020), no. 1, 1–10, http://dx.doi.org/10.1038/s41598-020-63662-9
-
[60]
Andr´ e Sonnet and Epifanio Virga,Dissipative or- dered fluids: Theories for liquid crystals, Springer New York, NY, 11 2013,https://doi.org/10.1007/ 978-0-387-87815-7
2013
-
[61]
56, 1929–1958,http://jmlr.org/papers/ v15/srivastava14a.html
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov,Dropout: A simple way to prevent neural networks from over- fitting, Journal of Machine Learning Research15 (2014), no. 56, 1929–1958,http://jmlr.org/papers/ v15/srivastava14a.html
2014
-
[62]
Karakasidis,Machine learning-enhanced molecular dy- namics: Current state, challenges and perspectives, Archives of Computational Methods in Engineering33 (2026), no
Christos Stavrogiannis, Filippos Sofos, and Theodoros E. Karakasidis,Machine learning-enhanced molecular dy- namics: Current state, challenges and perspectives, Archives of Computational Methods in Engineering33 (2026), no. 4, 6125–6147,https://doi.org/10.1007/ s11831-026-10505-x
2026
-
[63]
Kazuaki Z. Takahashi,Molecular cluster analysis us- ing local order parameters selected by machine learning, Physical Chemistry Chemical Physics25(2022), no. 1, 658–672,https://doi.org/10.1039/D2CP03696G
-
[64]
Terroa, M
J. Terroa, M. Tasinkevych, and C. S. Dias,Con- volutional neural network analysis of optical texture patterns in liquid-crystal skyrmions, Scientific Reports 15(2025), no. 1, 10921,https://doi.org/10.1038/ s41598-025-89699-2
2025
-
[65]
31, Curran Associates, Inc., 2018, https://proceedings.neurips.cc/paper/2018/hash/ 488e4104520c6aab692863cc1dba45af-Abstract.html
Maurice Weiler, Mario Geiger, Max Welling, Wouter Boomsma, and Taco S Cohen,3d steerable cnns: Learning rotationally equivariant features in volumet- ric data, Advances in Neural Information Processing Systems, vol. 31, Curran Associates, Inc., 2018, https://proceedings.neurips.cc/paper/2018/hash/ 488e4104520c6aab692863cc1dba45af-Abstract.html
2018
-
[66]
Guyon, U
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexander Smola,Deep sets, Advances in Neural Information Pro- cessing Systems (I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Gar- nett, eds.), vol. 30, Curran Associates, Inc., 2017,https: //proceedings.neurips.cc/paper_files...
2017
-
[67]
J. Zaplotnik, J. Piˇ sljar, M. ˇSkarabot, and M. Ravnik, Neural networks determination of material elastic con- stants and structures in nematic complex fluids, Scien- tific Reports13(2023), no. 1, 6028,https://doi.org/ 10.1038/s41598-023-33134-x. 16 Appendix A: Model T ables Model Architectures TABLE VII: Model architectures equivariant to different cycl...
-
[68]
rotation-angle
Construction Process A representationϱ Ck(g) :C k →GL(N 2) is constructed by first defining the representation of the generator element g∈C k, and then extending these to the remaining elements byϱ Ck(gp) =ϱ Ck(g)p. We follow these 4 steps: •Partition the image into concentric rings and fixed points •Impose angular ordering on the pixels within each ring ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.