Reading or Guessing? Visual Grounding Failures of Vision-Language Models for OCR in Ancient Greek Editions
Pith reviewed 2026-06-29 17:49 UTC · model grok-4.3
The pith
VLMs for ancient Greek OCR often output fluent text that ignores the actual image and follows language priors instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
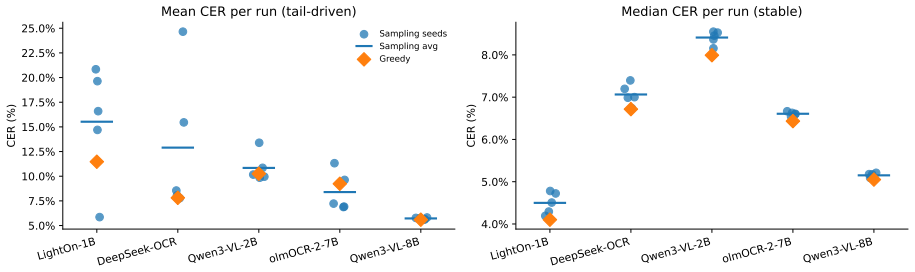
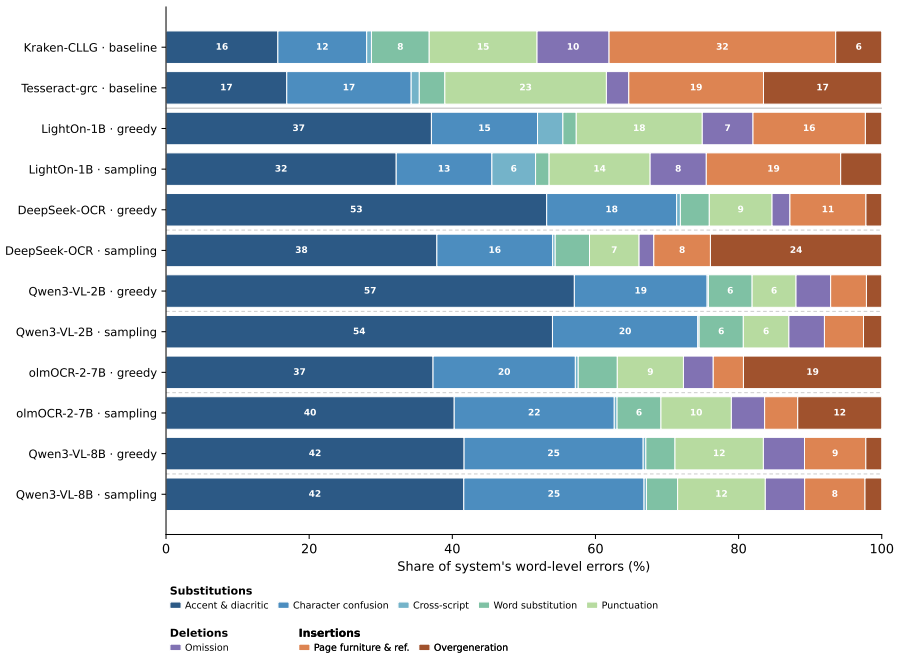
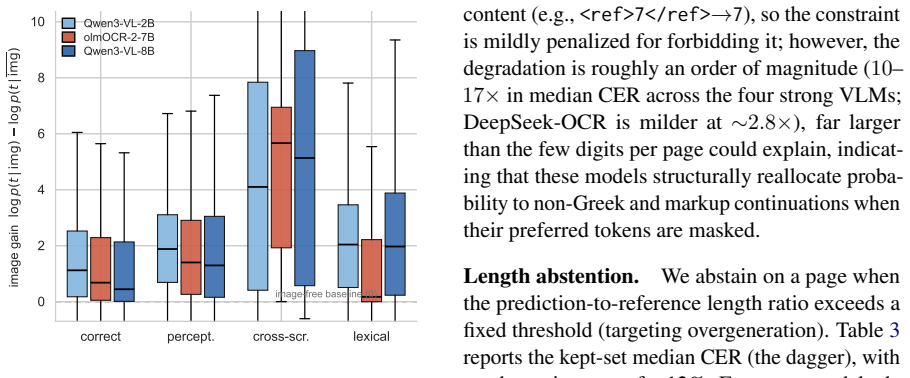
Under controlled character-level perturbations, VLMs diverge sharply from the perturbed ground truth while traditional OCR remains comparatively faithful to the altered image; token-level analysis further reveals that an OCR-specialist VLM produces fluent lexical substitutions with little dependence on the image, whereas general-purpose VLMs stay conditioned on visual input even when their output is wrong.
What carries the argument
Controlled image perturbations together with token-level grounding measures that compare conditional decoding distributions against image-free decoding distributions.
If this is right
- OCR-specialist VLMs can emit fluent but image-ungrounded lexical substitutions.
- General-purpose VLMs continue to condition on the visual input even on incorrect outputs.
- Decode-time interventions do not reliably increase visual grounding.
- Post-generation language-model correction can improve final text quality without fixing the underlying grounding problem.
Where Pith is reading between the lines
- Evaluation of historical-document OCR should include explicit checks for visual grounding rather than fluency alone.
- Hybrid pipelines that run traditional OCR first and then apply VLM correction only where needed may reduce ungrounded fluent errors.
- The same perturbation-plus-distribution-shift test could be applied to other low-resource scripts to measure prior reliance.
Load-bearing premise
The controlled image perturbations and the conditional-versus-image-free decoding measures accurately reflect how much the model actually uses the image during ordinary decoding.
What would settle it
A direct observation that, under the same character-level perturbations, VLM output distributions remain as close to the perturbed ground truth as traditional OCR output distributions would falsify the claim of language-prior dominance.
Figures



read the original abstract
Recent work has shown that Vision-Language Models (VLMs) used for optical character recognition (OCR) can generate plausible but visually unsupported text, suggesting reliance on language priors. Comparing open-weight VLMs with traditional OCR baselines on low-resource Ancient Greek critical editions, we show that VLM errors often remain fluent even when wrong, producing plausible Greek substitutions where traditional engines produce local recognition noise. To analyze visual evidence during decoding, we introduce controlled image perturbations and token-level grounding measures based on conditional versus image-free decoding distributions. Under character-level perturbations, VLMs diverge sharply from the perturbed ground truth while traditional OCR remains comparatively faithful; however, token-level analysis shows that prior reliance is model-specific: in an OCR-specialist model, fluent lexical errors are produced with little reliance on the image, whereas general-purpose VLMs remain conditioned on the visual input even when wrong. Decode-time interventions fail to reliably restore grounding, while post-OCR language-model correction improves several systems only by repairing text after generation. Our results extend prior evidence of OCR language-prior reliance to low-resource historical documents and a broader set of models, showing that fluent output is not necessarily visually grounded and motivating interpretability-driven evaluation beyond aggregate accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines visual grounding failures in vision-language models (VLMs) applied to OCR on low-resource Ancient Greek critical editions. It claims that VLMs often produce fluent but visually unsupported text by relying on language priors, in contrast to traditional OCR engines that generate more local noise. The authors introduce controlled character-level image perturbations and token-level grounding metrics based on conditional versus image-free decoding distributions. Under these perturbations, VLMs diverge sharply from the perturbed ground truth while traditional OCR remains more faithful; however, the degree of prior reliance is model-specific (fluent errors with little image conditioning in OCR-specialist models versus continued visual conditioning in general-purpose VLMs even when incorrect). Decode-time interventions do not reliably restore grounding, while post-OCR LM correction helps only by repairing output after generation. The work extends prior evidence to historical documents and a broader model set, arguing that fluent output is not necessarily visually grounded.
Significance. If the central empirical findings hold, the paper makes a useful contribution by extending observations of language-prior reliance in VLMs to a challenging low-resource historical domain and by distinguishing behavior across model types. The perturbation-plus-distribution-comparison approach attempts to move beyond aggregate accuracy toward interpretability-driven evaluation, which is a positive direction. The focus on Ancient Greek editions is well-chosen given the domain's sensitivity to fluent substitutions. No machine-checked proofs or parameter-free derivations are present, but the reproducible experimental setup on public editions would be a strength if code and data are released.
major comments (2)
- [Perturbation Analysis] Perturbation Analysis section: the central claim that character-level perturbations plus conditional-vs-image-free token distributions isolate visual grounding (rather than general sensitivity to local noise) is load-bearing for the model-specific prior-reliance conclusions. The manuscript does not appear to include controls such as random non-semantic perturbations of matched magnitude or comparisons against models sharing the same visual encoder; without these, the divergence gap could reflect differences in receptive-field size or training rather than absence of grounding per se.
- [Intervention Experiments] Results on decode-time interventions: the statement that such interventions 'fail to reliably restore grounding' is central to the practical takeaway, yet the quantitative effect sizes and failure modes (e.g., which tokens are affected) are not reported with sufficient detail to assess whether the interventions were applied at the appropriate decoding stage or with appropriate strength.
minor comments (2)
- [Abstract] Abstract: the claim that 'traditional OCR remains comparatively faithful' would benefit from a brief quantitative anchor (e.g., character error rate delta) even in the abstract.
- [Methods] Notation: the token-level grounding measure is described as comparing 'conditional versus image-free decoding distributions'; a short equation or pseudocode in the methods would clarify whether this is a KL divergence, probability ratio, or other statistic.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and note planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Perturbation Analysis] Perturbation Analysis section: the central claim that character-level perturbations plus conditional-vs-image-free token distributions isolate visual grounding (rather than general sensitivity to local noise) is load-bearing for the model-specific prior-reliance conclusions. The manuscript does not appear to include controls such as random non-semantic perturbations of matched magnitude or comparisons against models sharing the same visual encoder; without these, the divergence gap could reflect differences in receptive-field size or training rather than absence of grounding per se.
Authors: We appreciate the referee's identification of this potential confound. Our character-level perturbations target visually similar substitutions typical of Greek OCR errors, and the contrast with traditional OCR (which remains locally faithful) provides evidence that the observed divergence is not solely general noise sensitivity. To further address the concern, we will add a control experiment using random non-semantic perturbations of matched magnitude. Direct comparisons with models sharing an identical visual encoder are constrained by the set of available open-weight VLMs; we will explicitly discuss this architectural limitation and its implications in the revised text. revision: partial
-
Referee: [Intervention Experiments] Results on decode-time interventions: the statement that such interventions 'fail to reliably restore grounding' is central to the practical takeaway, yet the quantitative effect sizes and failure modes (e.g., which tokens are affected) are not reported with sufficient detail to assess whether the interventions were applied at the appropriate decoding stage or with appropriate strength.
Authors: We agree that additional quantitative detail is needed to evaluate the interventions. In the revised manuscript we will report effect sizes on the grounding metrics, token-level breakdowns of affected positions, and explicit information on the decoding stages and intervention strengths applied. revision: yes
Circularity Check
No significant circularity; empirical evaluation is self-contained
full rationale
The paper is an empirical study that compares VLMs against traditional OCR baselines on perturbed Ancient Greek edition images. It defines token-level grounding measures operationally as differences between conditional and image-free decoding distributions, then reports observed divergences under character-level perturbations. No equations, fitted parameters, or predictions reduce to their own inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. The central observations rely on external baselines and direct experimental outputs rather than any self-referential chain, so the derivation chain contains no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Controlled image perturbations and token-level measures based on conditional versus image-free decoding distributions accurately reflect visual grounding during normal OCR decoding.
Reference graph
Works this paper leans on
-
[1]
From Plausibility to Verifiability: Risk-Controlled Generative OCR with Vision-Language Models
Multi-modal hallucination control by visual information grounding. In2024 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 14303–14312. Yulin Fei, Yuhui Gao, Xingyuan Xian, Xiaojin Zhang, Tao Wu, and Wei Chen. 2025. Do current video LLMs have strong OCR abilities? a preliminary study. InProceedings of the 31st International C...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Mitigating object hallucinations in large vision- language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 13872–13882. Yunhao Liang, Ruixuan Ying, Bo Li, Hong Li, Kai Yan, Qingwen Li, Min Yang, Okamoto Satoshi, Zhe Cui, and Shiwen Ni. 2026. Visual merit or lin...
-
[3]
LightOnOCR: A 1b end-to-end multilingual vision-language model for state-of-the-art OCR,
Association for Computing Machinery. R. Smith. 2007. An overview of the tesseract ocr engine. InNinth International Conference on Document Anal- ysis and Recognition (ICDAR 2007), volume 2, pages 629–633. Said Taghadouini, Adrien Cavaillès, and Baptiste Aubertin. 2026. Lightonocr: A 1b end-to-end mul- tilingual vision-language model for state-of-the-art o...
work page internal anchor Pith review arXiv 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.