MRMMIA: Membership Inference Attacks on Memory in Chat Agents
Pith reviewed 2026-06-29 12:02 UTC · model grok-4.3
The pith
MRMMIA extracts a membership signal from chat agent memory by sending multiple recall probes, outperforming baselines across black-box, gray-box, and white-box access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
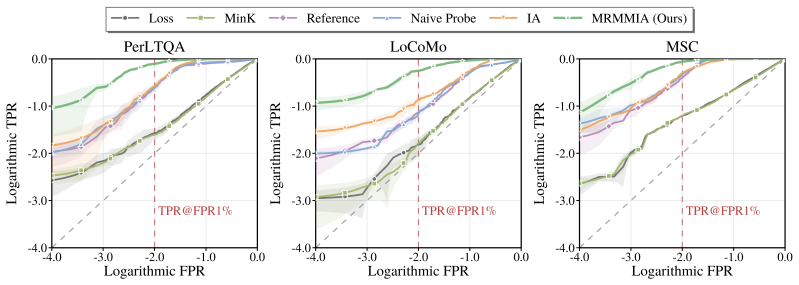
MRMMIA is a unified attack that utilizes multiple recall probes to the agent to extract the membership signal across black-box, gray-box, and white-box settings. Experiments show that MRMMIA consistently outperforms baselines and thereby exposes privacy risk in agents while providing an initial evaluation framework for membership leakage in chat-agent memory systems.
What carries the argument
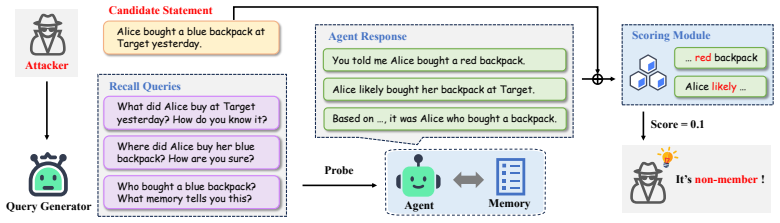
Multi-Recall Memory MIA (MRMMIA), which issues repeated recall probes to surface a detectable membership signal from the agent's memory store.
If this is right
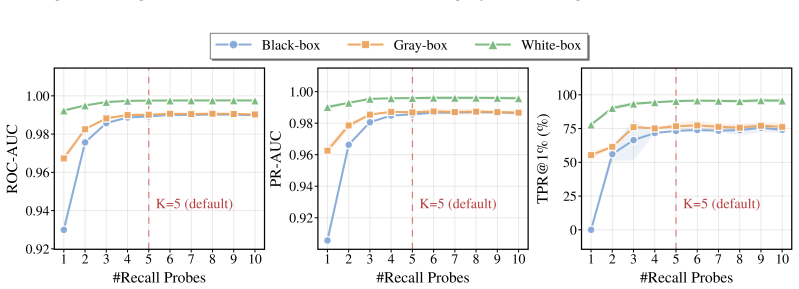
- Chat agent memory is vulnerable to membership inference even when the attacker has only black-box API access.
- The same multi-probe technique strengthens inference when gray-box or white-box access is available.
- Without defenses, agents can reveal whether particular user interactions or retrieved facts reside in memory.
- The results establish a baseline framework for evaluating membership leakage in future agent memory designs.
Where Pith is reading between the lines
- If agents add rate limits or randomized responses to recall-style queries, the attack's success rate would likely drop and require new probe strategies.
- The approach could extend to testing membership in other agent components such as long-term user profiles or external retrieval indexes.
- Designers may need to treat memory contents as public by default and apply sanitization before storage to reduce exposure.
Load-bearing premise
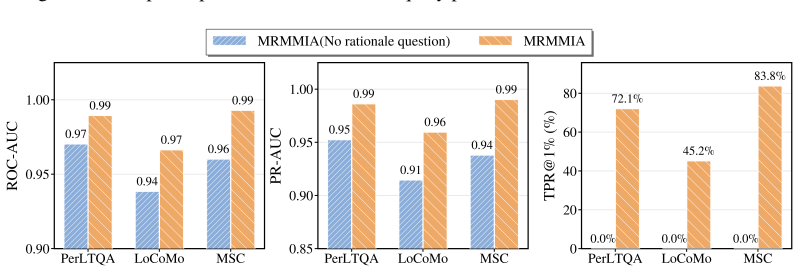
Multiple recall probes can reliably surface a detectable membership signal from the agent's memory store without the agent implementing countermeasures or the signal being too noisy to use.
What would settle it
An experiment in which responses to the recall probes show no measurable difference in accuracy or between member and non-member memory units across repeated trials would falsify the claim.
Figures




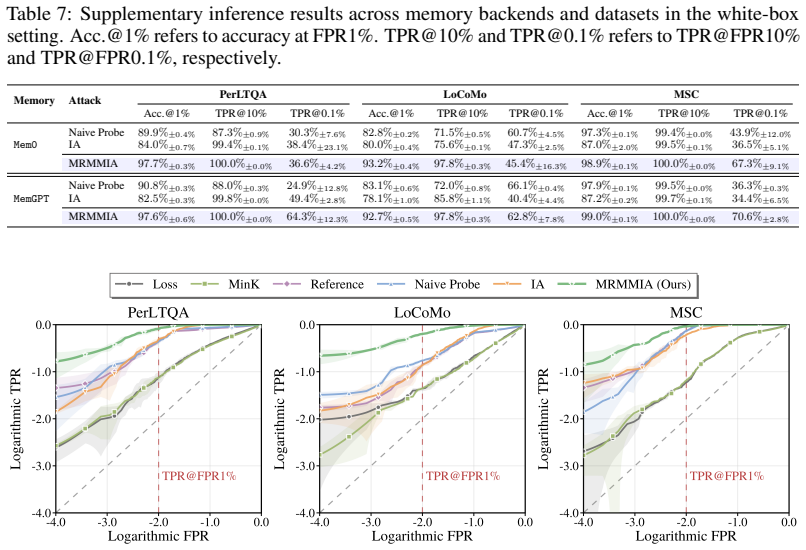
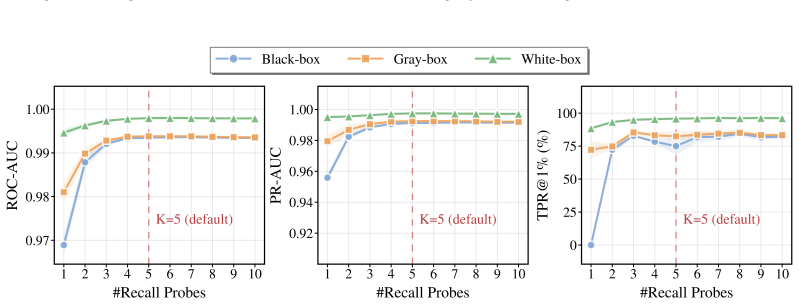
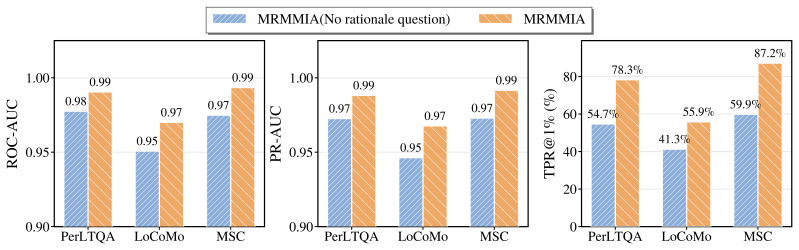
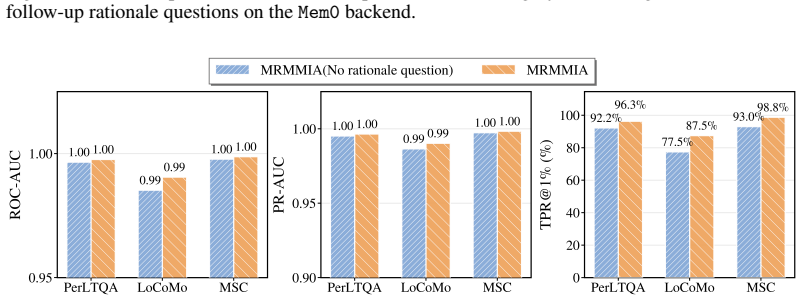
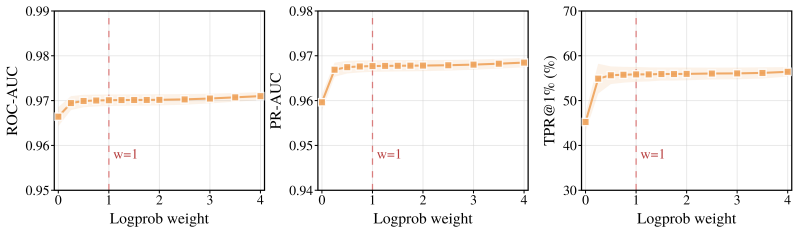
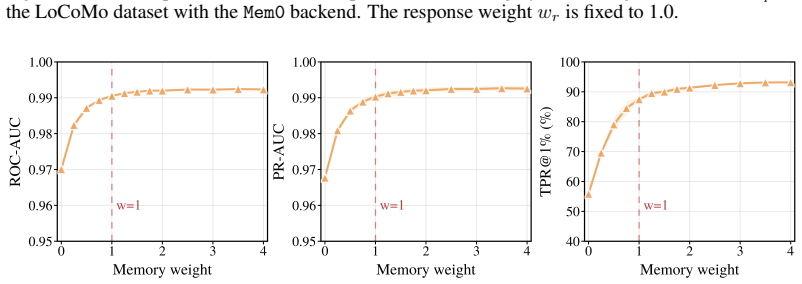
read the original abstract
Membership inference attacks (MIAs) test whether a target data record belongs to a system's private data, and have become a standard tool to measure privacy leakage in machine learning systems. Prior work has primarily focused on training corpora or retrieval databases. However, MIAs against agent memory have received less attention, even though such memory can contain sensitive user-agent interactions, retrieved facts, and user preferences. Therefore, in this work, we focus on chat agent memory MIAs, where an adversary infers whether a candidate memory unit belongs to the chat agent's memory store. We propose Multi-Recall Memory MIA (MRMMIA), a unified attack that utilizes multiple recall probes to the agent to extract the membership signal across black-box, gray-box, and white-box settings. Our experiments demonstrate that MRMMIA consistently outperforms baselines. Our results expose the privacy risk in agents and provide an initial evaluation framework for membership leakage in chat-agent memory systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-Recall Memory MIA (MRMMIA), a unified membership inference attack targeting chat agent memory stores. It employs multiple recall probes to extract membership signals in black-box, gray-box, and white-box settings, claims consistent outperformance over baselines, and positions the work as an initial evaluation framework exposing privacy risks from sensitive user-agent interactions stored in agent memory.
Significance. If the experimental claims hold, the work would be significant for extending membership inference attacks to the under-studied domain of agent memory (distinct from training corpora or retrieval databases), offering a practical framework for assessing leakage in interactive systems that retain user preferences and interactions.
major comments (1)
- [Abstract] Abstract: The central claim that 'MRMMIA consistently outperforms baselines' across black/gray/white-box settings is load-bearing for the contribution, yet the manuscript supplies no experimental details, probe construction, datasets, baseline definitions, metrics, statistical tests, or results to support or evaluate it.
Simulated Author's Rebuttal
We thank the referee for their review. The single major comment concerns the abstract's central claim lacking supporting details in the manuscript. We address this below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'MRMMIA consistently outperforms baselines' across black/gray/white-box settings is load-bearing for the contribution, yet the manuscript supplies no experimental details, probe construction, datasets, baseline definitions, metrics, statistical tests, or results to support or evaluate it.
Authors: The abstract is a concise summary by design. The full manuscript details the MRMMIA attack (multiple recall probes for membership signal extraction) in Section 3, datasets (synthetic chat logs and real user-agent interaction traces) in Section 4.1, baselines (loss-based, shadow-model, and query-based MIAs adapted to memory) in Section 4.2, metrics (AUC, TPR@low FPR) and statistical tests (paired t-tests with p<0.05 reporting) in Section 4.3, and results (consistent outperformance across black/gray/white-box settings) in Section 5 with Tables 1-3 and Figures 2-4. These sections directly support the abstract claim. revision: no
Circularity Check
No circularity: empirical attack proposal with no derivations or self-referential reductions
full rationale
The paper presents MRMMIA as an empirical membership inference method using multiple recall probes, with the central claim being experimental outperformance over baselines. The abstract and description contain no equations, fitted parameters, uniqueness theorems, ansatzes, or derivation chains. No load-bearing steps reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. The work is self-contained as an experimental framework without mathematical derivations that could exhibit circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Maya Anderson, Guy Amit, and Abigail Goldsteen. Is my data in your retrieval database? member- ship inference attacks against retrieval augmented generation. InProceedings of the 11th International Conference on Information Systems Security and Privacy, page 474–485. SCITEPRESS - Science and Technology Publications, 2025. doi: 10.5220/0013108300003899. UR...
-
[2]
Extracting training data from large language models, 2021
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting training data from large language models, 2021. URLhttps://arxiv.org/abs/2012.07805
-
[3]
Membership inference attacks from first principles, 2022
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles, 2022. URLhttps://arxiv.org/abs/2112.03570. 10
-
[4]
Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases, 2024
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases, 2024. URLhttps://arxiv.org/abs/2407.12784
-
[5]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory, 2025. URL https://arxiv.org/abs/ 2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Yiming Du, Hongru Wang, Zhengyi Zhao, Bin Liang, Baojun Wang, Wanjun Zhong, Zezhong Wang, and Kam-Fai Wong. Perltqa: A personal long-term memory dataset for memory classification, retrieval, and synthesis in question answering, 2024. URLhttps://arxiv.org/abs/2402.16288
-
[7]
Do membership inference attacks work on large language models?, 2024
Michael Duan, Anshuman Suri, Niloofar Mireshghallah, Sewon Min, Weijia Shi, Luke Zettlemoyer, Yulia Tsvetkov, Yejin Choi, David Evans, and Hannaneh Hajishirzi. Do membership inference attacks work on large language models?, 2024. URLhttps://arxiv.org/abs/2402.07841
-
[8]
Membership inference attacks against fine-tuned large language models via self-prompt calibration
Wenjie Fu, Huandong Wang, Chen Gao, Guanghua Liu, Yong Li, and Tao Jiang. Membership inference attacks against fine-tuned large language models via self-prompt calibration. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum? id=PAWQvrForJ
2024
-
[9]
Membership inference attacks on machine learning: A survey.ACM Computing Surveys (CSUR), 54(11s):1–37, 2022
Hongsheng Hu, Zoran Salcic, Lichao Sun, Gillian Dobbie, Philip S Yu, and Xuyun Zhang. Membership inference attacks on machine learning: A survey.ACM Computing Surveys (CSUR), 54(11s):1–37, 2022
2022
-
[10]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention, 2023. URLhttps://arxiv.org/abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Generating is believing: Membership inference attacks against retrieval-augmented generation, 2024
Yuying Li, Gaoyang Liu, Chen Wang, and Yang Yang. Generating is believing: Membership inference attacks against retrieval-augmented generation, 2024. URLhttps://arxiv.org/abs/2406.19234
-
[12]
Mask-based membership inference attacks for retrieval- augmented generation, 2025
Mingrui Liu, Sixiao Zhang, and Cheng Long. Mask-based membership inference attacks for retrieval- augmented generation, 2025. URLhttps://arxiv.org/abs/2410.20142
-
[13]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents, 2024. URL https://arxiv.org/abs/ 2402.17753
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Membership inference attacks against language models via neighbourhood comparison, 2023
Justus Mattern, Fatemehsadat Mireshghallah, Zhijing Jin, Bernhard Schölkopf, Mrinmaya Sachan, and Taylor Berg-Kirkpatrick. Membership inference attacks against language models via neighbourhood comparison, 2023. URLhttps://arxiv.org/abs/2305.18462
-
[15]
Riddle me this! stealthy membership inference for retrieval-augmented generation, 2025
Ali Naseh, Yuefeng Peng, Anshuman Suri, Harsh Chaudhari, Alina Oprea, and Amir Houmansadr. Riddle me this! stealthy membership inference for retrieval-augmented generation, 2025. URL https: //arxiv.org/abs/2502.00306
-
[16]
Milad Nasr, Reza Shokri, and Amir Houmansadr. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In2019 IEEE Symposium on Security and Privacy (SP), page 739–753. IEEE, May 2019. doi: 10.1109/sp.2019.00065. URLhttp://dx.doi.org/10.1109/SP.2019.00065
-
[17]
Nguyen Linh Bao Nguyen, Wanlun Ma, Viet V o, Alsharif Abuadbba, Minghong Fang, Jun Zhang, and Yang Xiang. Five queries are enough: Query-efficient and surrogate-free membership inference attacks on rag via entailment, 2026. URLhttps://arxiv.org/abs/2605.24312
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems, 2024. URL https://arxiv.org/abs/2310. 08560
2024
-
[19]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior, 2023. URL https://arxiv. org/abs/2304.03442
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Zhenting Qi, Hanlin Zhang, Eric Xing, Sham Kakade, and Himabindu Lakkaraju. Follow my instruction and spill the beans: Scalable data extraction from retrieval-augmented generation systems.arXiv preprint arXiv:2402.17840, 2024. 11
-
[21]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models,
Ahmed Salem, Yang Zhang, Mathias Humbert, Pascal Berrang, Mario Fritz, and Michael Backes. Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models,
-
[23]
URLhttps://arxiv.org/abs/1806.01246
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Detecting Pretraining Data from Large Language Models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models, 2024. URL https: //arxiv.org/abs/2310.16789
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Membership Inference Attacks against Machine Learning Models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models, 2017. URLhttps://arxiv.org/abs/1610.05820
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Unveiling privacy risks in llm agent memory, 2025
Bo Wang, Weiyi He, Shenglai Zeng, Zhen Xiang, Yue Xing, Jiliang Tang, and Pengfei He. Unveiling privacy risks in llm agent memory, 2025. URLhttps://arxiv.org/abs/2502.13172
-
[27]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
2024
-
[28]
Beyond goldfish memory: Long-term open-domain conversation,
Jing Xu, Arthur Szlam, and Jason Weston. Beyond goldfish memory: Long-term open-domain conversation,
- [29]
-
[30]
Privacy risk in machine learning: Analyzing the connection to overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting. In2018 IEEE 31st Computer Security Foundations Symposium (CSF), pages 268–282, 2018. doi: 10.1109/CSF.2018.00027
-
[31]
The good and the bad: Exploring privacy issues in retrieval- augmented generation (rag), 2024
Shenglai Zeng, Jiankun Zhang, Pengfei He, Yue Xing, Yiding Liu, Han Xu, Jie Ren, Shuaiqiang Wang, Dawei Yin, Yi Chang, and Jiliang Tang. The good and the bad: Exploring privacy issues in retrieval- augmented generation (rag), 2024. URLhttps://arxiv.org/abs/2402.16893
-
[32]
Min-k%++: Improved baseline for pre-training data detection from large language models
Jingyang Zhang, Jingwei Sun, Eric Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao Frank Yang, and Hai Li. Min-k%++: Improved baseline for pre-training data detection from large language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=ZGkfoufDaU
2025
-
[33]
A Survey on the Memory Mechanism of Large Language Model based Agents
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model based agents, 2024. URL https://arxiv.org/abs/2404.13501
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory, 2023. URLhttps://arxiv.org/abs/2305.10250. A Dataset Details We provide the detailed information and processing steps for the three datasets used in our experi- ments: PerLTQA, LOCOMO, and MSC. These datasets consist of thousan...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
How do you know that?
Each probe must be a natural and specific direct recall question whose answer is a concise value entailed by the memory. The same question must also ask for the source/reason for the answer, using a short follow-up such as "How do you know that?", "Where did you get this information?", or "What memory tells you this?"
-
[36]
Do NOT ask yes/no questions
-
[37]
Do NOT put the answer/key_value directly in the question
-
[38]
Prefer probes that target different atomic topics or slots in the memory, such as person, location, date, event, relationship, organization, action, object, preference, or outcome
-
[39]
Do not include the key_value itself as context
Include non-answer context from the memory when it helps disambiguate the probe. Do not include the key_value itself as context
-
[40]
If the memory contains fewer than {k} distinct atomic topics, first cover as many distinct topics as possible, then fill the remaining probes with natural paraphrases or different contextual framings of those available direct-recall question(s)
-
[41]
The source/reason follow-up should make it hard to answer from generic world knowledge alone; prefer asking what remembered fact, prior conversation, or stored information supports the answer
-
[42]
Alice bought a blue backpack at Target
Return exactly {k} probe objects. For each probe: - topic: the atomic slot being queried - key_value: the concise expected answer if this memory is present - question: the direct recall question plus a short source/reason follow-up Example when k=5 and three distinct topics are available: Memory: "Alice bought a blue backpack at Target." Output: {{"probes...
-
[43]
Does it support the specified KEY_V ALUE?
-
[44]
How do you know about {topic}?
Does its stated reason/source fully align with the CANDIDATE STATEMENT? Probe type: {probe_type} Topic: {topic} Key value: {key_value} CANDIDATE STATEMENT: {candidate_statement} QUESTION: {question} AGENT RESPONSE: {response} Important rules: - **Question leakage**: The QUESTION is context only; values only in the QUESTION are not evidence. - **Key gate**...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.