Tabero: Learning Gentle Manipulation with Closed-Loop Force Feedback from Vision, Touch, and Language
Pith reviewed 2026-06-29 12:25 UTC · model grok-4.3
The pith
A robot model learns to reduce grip force by over 70% under gentle language instructions while keeping high task success, by using closed-loop feedback from vision, touch, and language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
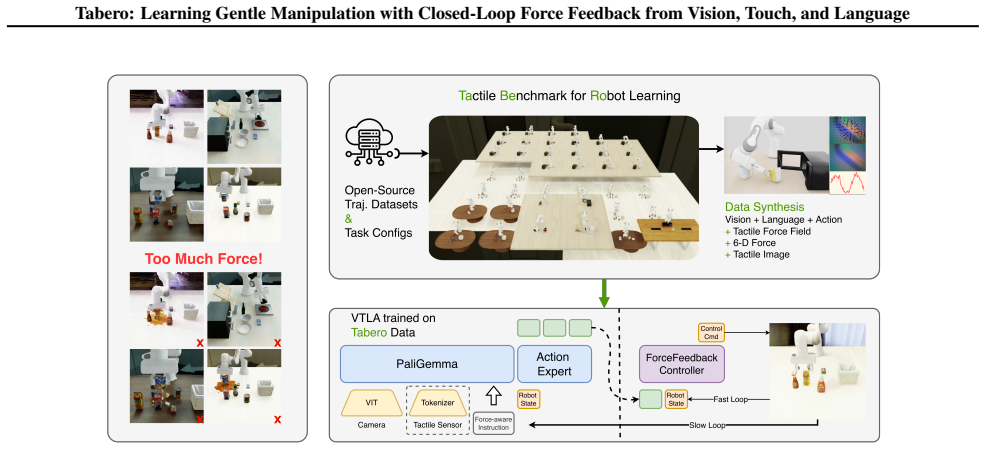
Tabero-VTLA maintains high task success while reducing average grip force by over 70% under gentle instructions by modulating interaction forces based on multimodal experience from vision, touch, and language, using a decoupled force-position command interface executed by a fixed hybrid controller.
What carries the argument
Decoupled force-position command interface in Tabero-VTLA executed by a fixed hybrid controller for real-time closed-loop force-aware manipulation.
If this is right
- Language instructions can directly shape the physical forces applied during contact-rich manipulation tasks.
- Multimodal vision-tactile-language inputs enable closed-loop adjustment of interaction forces without separate force sensors at inference time.
- Existing trajectory datasets can be transformed into sufficient training data for force-sensitive policies when aligned across modalities.
- Manipulation evaluation protocols can jointly assess task completion and physical gentleness metrics.
Where Pith is reading between the lines
- The same data-repurposing approach could apply to other contact-rich skills such as insertion or wiping where force limits matter.
- Deploying such models in unstructured environments might reduce damage risk to fragile objects or surfaces during human-robot collaboration.
- Extending the hybrid controller to handle additional force axes or variable stiffness could broaden the range of gentle tasks.
Load-bearing premise
Repurposing open-source robot manipulation trajectories generates diverse, aligned vision-tactile-language tasks that support training of effective closed-loop force-aware policies.
What would settle it
An experiment in which the trained model receives gentle language instructions on force-sensitive tasks yet either task success falls sharply or average grip force shows no significant reduction compared to non-gentle baselines.
Figures



read the original abstract
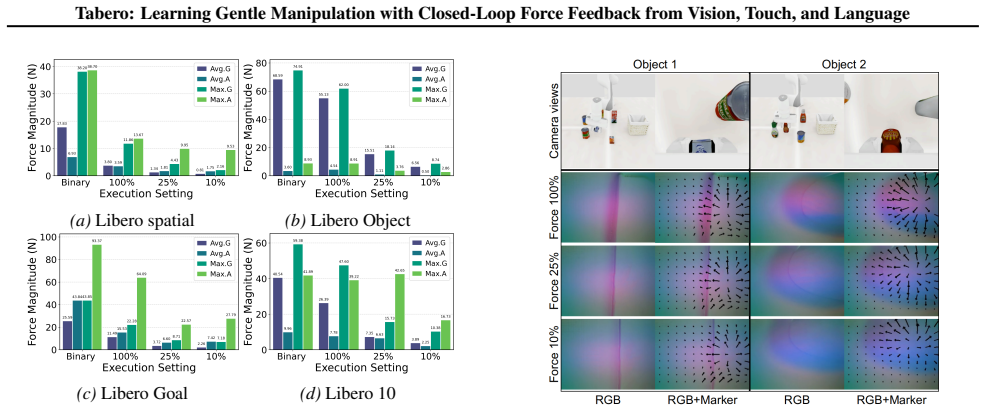
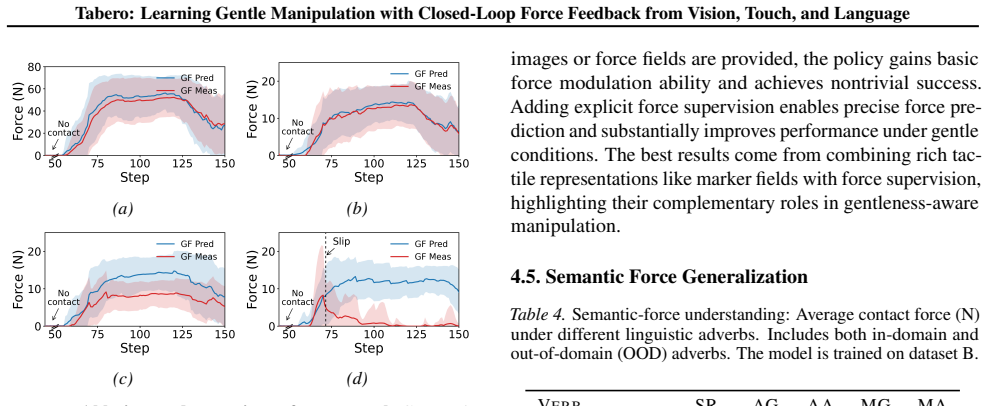
Tactile sensing is essential for robots to achieve human-like gentle manipulation. However, existing Vision-Language-Action (VLA) models struggle to exploit tactile feedback for gentle manipulation due to scarce aligned vision-tactile-language data and the lack of effective closed-loop force feedback mechanisms. To address these challenges, we introduce Tabero, a benchmark and model suite for gentle, language-conditioned robotic manipulation that demands fine-grained contact force perception. First, the Tabero benchmark addresses the scarcity of tactile data by presenting a data-efficient pipeline that repurposes open-source robot manipulation trajectories to generate diverse vision-tactile-language tasks, and establishes a multidimensional evaluation protocol that measures task success alongside physical interaction quality. Second, we propose Tabero-VTLA, an architecture with a decoupled force-position command interface; the resulting force-position commands are executed by a fixed hybrid controller to enable real-time, force-aware manipulation. Evaluated on Tabero, our model maintains high task success while reducing average grip force by over 70\% under gentle instructions, demonstrating its ability to modulate interaction forces based on multimodal experience. Our code is publicly available at https://github.com/NathanWu7/Tabero.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Tabero benchmark for language-conditioned gentle robotic manipulation, which repurposes open-source trajectories into aligned vision-tactile-language tasks, and proposes the Tabero-VTLA model with a decoupled force-position command interface executed by a fixed hybrid controller. The central empirical claim is that the model achieves high task success rates while reducing average grip force by over 70% under gentle instructions, showing effective modulation of interaction forces from multimodal inputs.
Significance. If the performance claims are substantiated with proper controls, the work could meaningfully advance VLA models toward force-aware manipulation by addressing data scarcity through repurposing and enabling closed-loop tactile feedback; the public code release is a clear strength for reproducibility.
major comments (3)
- [Abstract] Abstract: the central claim of >70% grip-force reduction under gentle instructions is stated without any baselines, error bars, dataset sizes, statistical tests, or exclusion criteria, which is load-bearing for assessing whether the empirical outcome supports the multimodal closed-loop contribution.
- [Methods (data generation pipeline)] Data pipeline description: no quantitative validation is provided for tactile signal diversity, force variance across generated tasks, or correlation between language instructions and contact forces, leaving open whether the observed reduction arises from learned use of tactile feedback or from task selection and the fixed hybrid controller.
- [Experiments] Experimental evaluation: the manuscript reports no modality ablations (e.g., vision+language only versus full VTLA) or force-distribution histograms that would confirm the tactile channel supplies actionable information distinct from position commands for the force-modulation result.
minor comments (2)
- [Abstract] The abstract would benefit from a concise statement of the number of tasks, trajectories, and evaluation episodes to contextualize the 70% figure.
- [Model architecture] Notation for the decoupled force-position interface could be clarified with a diagram or pseudocode in the model section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of >70% grip-force reduction under gentle instructions is stated without any baselines, error bars, dataset sizes, statistical tests, or exclusion criteria, which is load-bearing for assessing whether the empirical outcome supports the multimodal closed-loop contribution.
Authors: We agree that the abstract would be strengthened by including supporting details from the experiments. In the revision we will update the abstract to reference the specific baselines, report error bars and dataset sizes, and note the statistical tests used to substantiate the force-reduction result. revision: yes
-
Referee: [Methods (data generation pipeline)] Data pipeline description: no quantitative validation is provided for tactile signal diversity, force variance across generated tasks, or correlation between language instructions and contact forces, leaving open whether the observed reduction arises from learned use of tactile feedback or from task selection and the fixed hybrid controller.
Authors: The pipeline reuses existing trajectories while attempting to preserve contact-force characteristics. We acknowledge that explicit quantitative validation would help rule out alternative explanations. We will add analyses of tactile-signal diversity, force variance across tasks, and correlation between language instructions and measured contact forces in the revised methods section. revision: yes
-
Referee: [Experiments] Experimental evaluation: the manuscript reports no modality ablations (e.g., vision+language only versus full VTLA) or force-distribution histograms that would confirm the tactile channel supplies actionable information distinct from position commands for the force-modulation result.
Authors: Modality ablations and force-distribution histograms would provide clearer evidence that the tactile channel contributes distinct information. We will add these analyses, including a vision+language-only ablation and force histograms, to the experimental evaluation in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical claims rest on evaluation, not derivation
full rationale
The manuscript presents a benchmark construction pipeline and a model architecture whose performance (task success + 70% grip-force reduction) is reported as an empirical outcome on the generated Tabero tasks. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The data-generation and controller-interface choices are described as design decisions whose validity is tested by downstream metrics rather than assumed by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ISSN 1941-0468. doi: 10.1109/tro.2025.3547267. Bi, J., Ma, K. Y ., Hao, C., Shou, M. Z., and Soh, H. Vla- touch: Enhancing vision-language-action models with dual-level tactile feedback.CoRR, abs/2507.17294,
-
[2]
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M. R., Finn, C., Fusai, N., Galliker, M. Y ., Ghosh, D., Groom, L., Hausman, K., ichter, b., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A. Z., Shi, L. X., Smith, L., Springenberg, J. T., Stachowicz, K., T...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.15607/rss.2025.xxi.010 2025
-
[3]
Tacumi: A multi-modal uni- versal manipulation interface for contact-rich tasks,
Cheng, T., Chen, K., Chen, L., Zhang, L., Zhang, Y ., Ling, Y ., Hamad, M., Bing, Z., Wu, F., Sharma, K., and Knoll, A. Tacumi: A multi-modal universal manipulation in- terface for contact-rich tasks.CoRR, abs/2601.14550,
-
[4]
Cheng, Z., Zhang, Y ., Zhang, W., Li, H., Wang, K., Song, L., and Zhang, H. Omnivtla: Vision-tactile-language-action model with semantic-aligned tactile sensing.CoRR, abs/2508.08706,
-
[5]
Tla: Tactile-language-action model for contact- rich manipulation.CoRR, abs/2503.08548,
Hao, P., Zhang, C., Li, D., Cao, X., Hao, X., Cui, S., and Wang, S. Tla: Tactile-language-action model for contact- rich manipulation.CoRR, abs/2503.08548,
-
[6]
Huang, J., Wang, S., Lin, F., Hu, Y ., Wen, C., and Gao, Y . Tactile-vla: Unlocking vision-language-action model’s physical knowledge for tactile generalization.CoRR, abs/2507.09160,
-
[7]
Johnson, M. K. and Adelson, E. H. Retrographic sensing for the measurement of surface texture and shape.2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1070–1077,
2009
-
[8]
Rdt-1b: a diffusion foundation model for bimanual manipulation
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., and Zhu, J. Rdt-1b: a diffusion foundation model for bimanual manipulation. In Yue, Y ., Garg, A., Peng, N., Sha, F., and Yu, R. (eds.),International Conference on Learning Representations, volume 2025, pp. 29982– 30009,
2025
-
[9]
doi: 10.1109/LRA.2022.3180108. Mu, Y ., Chen, T., Chen, Z., Peng, S., Lan, Z., Gao, Z., Liang, Z., Yu, Q., Zou, Y ., Xu, M., Lin, L., Xie, Z., Ding, M., and Luo, P. Robotwin: Dual-arm robot benchmark with generative digital twins. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 27649–27660, June
-
[10]
K., Hoffmann, M., and Mikolajczyk, K
Nazarczuk, M., Stepanova, K., Behrens, J. K., Hoffmann, M., and Mikolajczyk, K. Muble: Mujoco and blender simulation environment and benchmark for task planning in robot manipulation.CoRR, abs/2503.02834,
-
[11]
NVIDIA, Bjorck, J., Casta˜neda, F., Cherniadev, N., Da, X., Ding, R., Fan, L. J., Fang, Y ., Fox, D., Hu, F., Huang, S., Jang, J., Jiang, Z., Kautz, J., Kundalia, K., Lao, L., Li, Z., Lin, Z., Lin, K., Liu, G., Llontop, E., Magne, L., Mandlekar, A., Narayan, A., Nasiriany, S., Reed, S., Tan, Y . L., Wang, G., Wang, Z., Wang, J., Wang, Q., Xiang, J., Xie, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Si, Z., Zhang, G., Ben, Q., Romero, B., Xian, Z., Liu, C., and Gan, C
doi: 10.1109/ LRA.2022.3142412. Si, Z., Zhang, G., Ben, Q., Romero, B., Xian, Z., Liu, C., and Gan, C. Difftactile: A physics-based differen- tiable tactile simulator for contact-rich robotic manipula- tion. In Kim, B., Yue, Y ., Chaudhuri, S., Fragkiadaki, K., Khan, M., and Sun, Y . (eds.),International Conference on Learning Representations, volume 2024...
-
[13]
ISSN 2377-3774. doi: 10.1109/lra.2022.3146945. Wu, L., Yu, C., Ren, J., Chen, L., Jiang, Y ., Huang, R., Gu, G., and Li, H. Freetacman: Robot-free visuo-tactile data collection system for contact-rich manipulation.CoRR, abs/2506.01941,
-
[14]
ISSN 1424-8220. doi: 10.3390/s17122762. Zhang, C., Hao, P., Cao, X., Hao, X., Cui, S., and Wang, S. Vtla: Vision-tactile-language-action model with preference learning for insertion manipulation.CoRR, abs/2505.09577, 2025a. Zhang, Z., Xu, H., Yang, Z., Yue, C., Lin, Z., Gao, H.-a., Wang, Z., and Zhao, H. Elucidating the design space of torque-aware vision...
-
[15]
ISBN 979-8- 3315-4139-2. doi: 10.1109/ICRA55743.2025.11128816. Zhao, Y ., Qian, K., Duan, B., and Luo, S. Fots: A fast optical tactile simulator for sim2real learning of tactile- motor robot manipulation skills.IEEE Robotics and Automation Letters, 9(6):5647–5654,
-
[16]
Zhu, Y ., Wong, J., Mandlekar, A., and Mart´ın-Mart´ın, R
doi: 10.1109/ LRA.2024.3396665. Zhu, Y ., Wong, J., Mandlekar, A., and Mart´ın-Mart´ın, R. robosuite: A modular simulation framework and bench- mark for robot learning.CoRR, abs/2009.12293,
-
[17]
Hyperparameters The following table (Tab.5, Tab.6) presents some hyperparameters of the Tabero VTLA
10 Tabero: Learning Gentle Manipulation with Closed-Loop Force Feedback from Vision, Touch, and Language A. Hyperparameters The following table (Tab.5, Tab.6) presents some hyperparameters of the Tabero VTLA. Table 5.Common training hyperparameters for Tabero. PARAMETERVALUE MODEL FAMILY PI0 (JAX) ACTION DIM(PADDED) 32 EFFECTIVE ACTION DIM(SEMANTIC) 13 TA...
2048
-
[18]
11 Tabero: Learning Gentle Manipulation with Closed-Loop Force Feedback from Vision, Touch, and Language Table 8.Hyperparameters of TCN tactile tokenizer PARAMETERVALUE/ CONSTRAINT EXPERT WIDTH(W)PREFIX: 2048; NUM LAYERS2 KERNEL SIZE3 (CAUSAL) HISTORY(H) 8 ACTIVATION SWISH INPUT DIM11×9×2×9×2 = 3564 Table 9.Controller parameters (Hybrid+Tactile configurat...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.