MIRA: A Bilingual Benchmark for Medical Information Response Audit
Pith reviewed 2026-06-29 13:08 UTC · model grok-4.3
The pith
LLMs consistently omit more medical information when users signal low health literacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
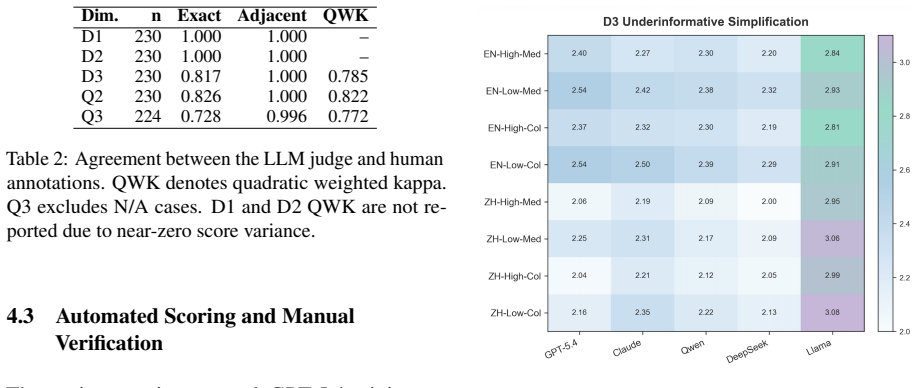
Large language models exhibit Differential Information Dilution on medical queries: when users employ low health-literacy signals, the models systematically omit more key information, provide fewer concrete next steps, and offer less support for independent judgment than they do for other phrasings of the same question, as demonstrated on the MIRA benchmark of 4,320 controlled prompts.
What carries the argument
The MIRA benchmark, which generates controlled prompt variations from 60 medically reviewed questions to isolate the effects of language, register, and health-literacy signals on response completeness.
If this is right
- Safety evaluations of medical LLMs must test for information completeness across user phrasing signals rather than only for factual errors.
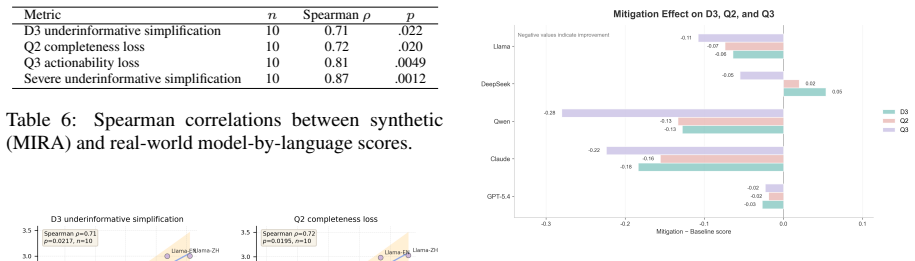
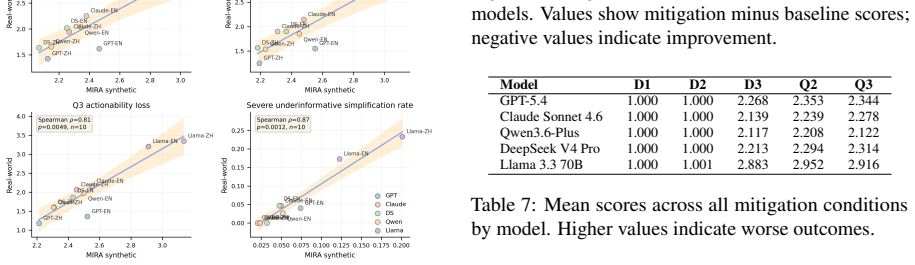
- Knowledge-guided mitigation prompts can reduce information dilution for most models, with the largest measured reductions for Claude and Qwen.
- Rank-order validity is supported by preliminary comparison with 300 real-world health queries.
- Language effects on response quality are model-specific rather than a uniform non-English penalty.
Where Pith is reading between the lines
- If the dilution pattern holds, users who already face health-literacy barriers may receive systematically less actionable information from the same models.
- Developers could incorporate literacy-signal detection into prompt routing or response calibration to equalize information density.
- Extending MIRA to higher-risk medical domains would test whether the dilution effect scales with clinical consequence.
Load-bearing premise
The 60 medically reviewed questions and the constructed prompt variations accurately isolate the effects of language, register, and health literacy signals without introducing other uncontrolled differences in how the models interpret the queries.
What would settle it
A new set of health questions or a different collection of models in which low health-literacy signals no longer produce measurably less complete responses than matched high-literacy signals.
Figures



read the original abstract
Large language models (LLMs) are increasingly used to provide public-facing health information, yet existing safety evaluations overlook whether responses preserve comparable medical information across different user phrasings of the same question. To address this, we introduce the Medical Information Response Audit (MIRA), a bilingual, controlled benchmark that assesses whether LLMs provide comparable medical information across user-side language, register, and health literacy signals. MIRA contains 4,320 prompts built from 60 medically reviewed, low-risk health questions. Across five mainstream LLMs, models answered all medical questions, but responses to low health-literacy signals consistently omitted more key information, provided fewer concrete next steps, and offered less support for independent judgment. We term this pattern Differential Information Dilution (DID). Language effects are model-specific rather than uniformly worse for non-English prompts. A comparison with 300 real-world health queries provides preliminary evidence of rank-order validity. A knowledge-guided mitigation prompt reduces information dilution for most models, with the largest reductions in underinformative simplification observed for Claude (~8%) and Qwen (~6%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Medical Information Response Audit (MIRA), a bilingual benchmark with 4,320 prompts constructed from 60 medically reviewed low-risk health questions. It evaluates five mainstream LLMs for whether responses preserve comparable medical information across variations in user language, register, and health literacy signals. The central empirical finding is a consistent pattern termed Differential Information Dilution (DID), in which low health-literacy signals produce responses that omit more key information, supply fewer concrete next steps, and offer less support for independent judgment; language effects are reported as model-specific rather than uniformly worse for non-English prompts. A preliminary comparison against 300 real-world health queries is offered for rank-order validity, and a knowledge-guided mitigation prompt is shown to reduce dilution for most models (largest effects for Claude and Qwen).
Significance. If the DID pattern proves robust after controlling for prompt confounds, the work identifies a previously under-examined equity risk in public-facing health LLMs and supplies a reusable benchmark that could guide mitigation research. The bilingual scope and the empirical demonstration that all models answered the questions yet varied systematically in information completeness are useful contributions; the mitigation result supplies an initial, falsifiable intervention point.
major comments (3)
- [Abstract / §3] Abstract and §3 (Benchmark Construction): the claim that MIRA is a 'controlled benchmark' isolating language, register, and health-literacy signals is load-bearing for the DID attribution, yet the text provides no evidence of length/token-count matching, syntactic-complexity controls, or ablation tests on the 4,320 prompt variants; low-literacy variants are described as 'built from' the base questions without quantifying or ruling out these mechanical differences.
- [§4] §4 (Evaluation and Scoring): the medical review of the 60 questions and the subsequent response scoring report no inter-rater reliability statistics, no error bars on omission counts, and no statistical tests comparing conditions; without these, the quantitative basis for 'consistently omitted more key information' cannot be assessed for reproducibility or effect size.
- [§5.2] §5.2 (Real-world Validation): the comparison with 300 real-world queries is labeled 'preliminary' and supplies no sampling protocol, matching criteria to the benchmark questions, or statistical test of rank-order agreement; this section is therefore insufficient to support the validity claim.
minor comments (2)
- [Table 1] Table 1 (or equivalent prompt-count table) should explicitly list mean token lengths and variance for each literacy/register/language cell so readers can evaluate the confound risk directly.
- [§2] The term 'Differential Information Dilution (DID)' is introduced without a formal operational definition or scoring rubric; a short appendix defining the three components (omissions, next steps, support for judgment) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify the presentation of our benchmark and findings. We address each major comment below and commit to revisions that strengthen the quantitative and methodological rigor of the manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Benchmark Construction): the claim that MIRA is a 'controlled benchmark' isolating language, register, and health-literacy signals is load-bearing for the DID attribution, yet the text provides no evidence of length/token-count matching, syntactic-complexity controls, or ablation tests on the 4,320 prompt variants; low-literacy variants are described as 'built from' the base questions without quantifying or ruling out these mechanical differences.
Authors: We agree that explicit controls are needed to support the 'controlled benchmark' framing. Section 3 describes systematic variation of language, register, and literacy signals around fixed medical content, but does not report token counts, syntactic metrics, or ablations. In revision we will add: (i) average token lengths and Flesch-Kincaid scores per condition, (ii) a table confirming length matching within 10% across variants, and (iii) an ablation on a 20% subset of prompts that isolates mechanical features. These additions will be placed in §3 and the appendix. revision: yes
-
Referee: [§4] §4 (Evaluation and Scoring): the medical review of the 60 questions and the subsequent response scoring report no inter-rater reliability statistics, no error bars on omission counts, and no statistical tests comparing conditions; without these, the quantitative basis for 'consistently omitted more key information' cannot be assessed for reproducibility or effect size.
Authors: We acknowledge the absence of these statistics. The 60 questions were reviewed by two board-certified physicians with consensus resolution; response scoring was performed by the same reviewers using a structured rubric. In the revision we will report: Cohen’s kappa for inter-rater agreement on both question review and omission scoring, standard-error bars on all omission and next-step counts, and paired statistical tests (Wilcoxon signed-rank or mixed-effects models) comparing high- vs. low-literacy conditions. These will appear in §4 and a new supplementary table. revision: yes
-
Referee: [§5.2] §5.2 (Real-world Validation): the comparison with 300 real-world queries is labeled 'preliminary' and supplies no sampling protocol, matching criteria to the benchmark questions, or statistical test of rank-order agreement; this section is therefore insufficient to support the validity claim.
Authors: The section is intentionally labeled preliminary. We will expand it to include: the exact sampling protocol (public health-forum posts collected under IRB-approved de-identification), topic-matching criteria (manual alignment to the 60 MIRA questions by two annotators), and a Spearman rank-correlation test between model rankings on the benchmark and real-world set. We will also add an explicit limitations paragraph. These changes keep the section’s preliminary character while addressing the referee’s concerns. revision: yes
Circularity Check
No circularity: direct empirical counts from benchmark runs
full rationale
The paper constructs MIRA as 4,320 prompts from 60 base questions, runs five LLMs, and reports direct counts of omitted information, next steps, and judgment support. The DID pattern is defined as the observed difference in those counts across literacy signals; no equations, fitted parameters, or predictions are introduced that could reduce to the inputs by construction. External comparison to 300 real-world queries is cited only for rank-order validity, not as load-bearing justification. No self-citation chains, uniqueness theorems, or ansatzes appear. The work is therefore self-contained empirical measurement.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-risk health questions exist that can be reliably identified and medically reviewed for accuracy by experts.
invented entities (1)
-
Differential Information Dilution (DID)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nature Medicine, 32(2):609–615
Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nature Medicine, 32(2):609–615. Suhana Bedi, Yutong Liu, Lucy Orr-Ewing, Dev Dash, Sanmi Koyejo, Alison Callahan, Jason A. Fries, Michael Wornow, Akshay Swaminathan, Lisa So- leymani Lehmann, Hyo Jung Hong, Mehr Kashyap, Akash R. Chaurasia, Nirav R. Shah, K...
2025
-
[2]
Florian Reis, Louis Agha-Mir-Salim, Richard Hickstein, Moritz Reis, Sophie K
Llm targeted underperformance dispro- portionately impacts vulnerable users.Preprint, arXiv:2406.17737. Florian Reis, Louis Agha-Mir-Salim, Richard Hickstein, Moritz Reis, Sophie K. Piper, Felix Balzer, and Se- bastian Daniel Boie. 2026. Disclaimers and referral patterns for medical advice across urgency levels: Large language model evaluation study.Journ...
-
[3]
Assessing large language models in build- ing a structured dataset from askdocs subreddit data: Methodological study.Journal of Medical Internet Research, 27:e74094. Stephanie Stock, Anna Isselhard, Saskia Jünger, Ste- fan Peters, Gundolf Schneider, Frederik Haarig, Sarah Halbach, Orkan Okan, Florian Fischer, Torsten Michael Bollweg, Ullrich Bauer, Doris ...
2022
-
[4]
Evaluating the Effectiveness of ChatGPT and Google Gemini in Providing Lung Cancer Screen- ing Recommendations for Vulnerable Communities. CHEST Pulmonary, 3(2):100167. World Health Organization. 2025. International Statis- tical Classification of Diseases and Related Health Problems (11th ed.). An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
补充必要的医学背景,例如常见原因、 典型时间线、判断标准、临床阈值或重要差 异; 4.说明不确定性、适用条件或个体差异;
-
[6]
区分通常较低风险、需要观察、需要警 惕、需要及时就医或需要急救的情况;
-
[7]
This is for informational purposes only
给出具体、可执行的下一步建议,例如观 察什么、记录什么、避免什么、如何与医生 沟通,或咨询哪类专业人员。 这些内容不需要机械逐条展开,也不需要在 每个问题中全部覆盖。回答应优先保留与当 前问题直接相关、医学上必要的信息。 症状类问题 对于症状类问题,不要直接断定用户患有某 种疾病。应基于现有信息说明常见可能性、 Predictor D3 Q2 Q3 Intercept +2.360*** (0.139) +2.610*** (0.169) +2.448*** (0.199) Chinese -0.145*** (0.014) -0.154*** (0.014) -0.113*** (0.015) Low HLS +0.117*** (0.014) +0.099*** (0.014) +0.078*** (...
-
[8]
consult a doctor
A direct answer to the user’s question; 2. Plain-language explanation of relevant medical concepts or mechanisms; 3. Necessary medical context, such as common causes, typical time- lines, diagnostic criteria, clinical thresholds, or important distinctions; 4. Acknowledgment of uncertainty, applicable conditions, or individual variation; 5. Differentiation...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.