MTAVG-Bench 2.0: Diagnosing Failure Modes of Cinematic Expressiveness in Multi-Talker Audio-Video Generation
Pith reviewed 2026-06-29 12:56 UTC · model grok-4.3
The pith
MTAVG-Bench 2.0 supplies over 10,000 QA instances and a four-category taxonomy to diagnose why multi-talker video generators fail at cinematic expressiveness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
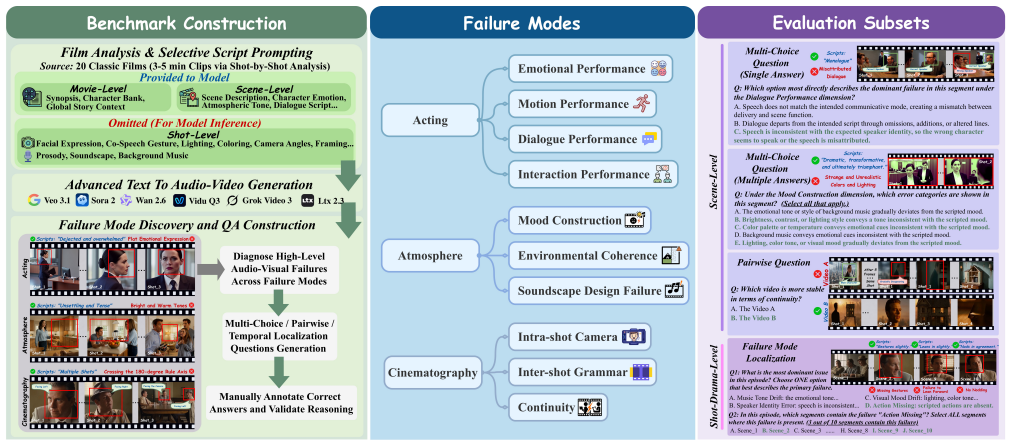
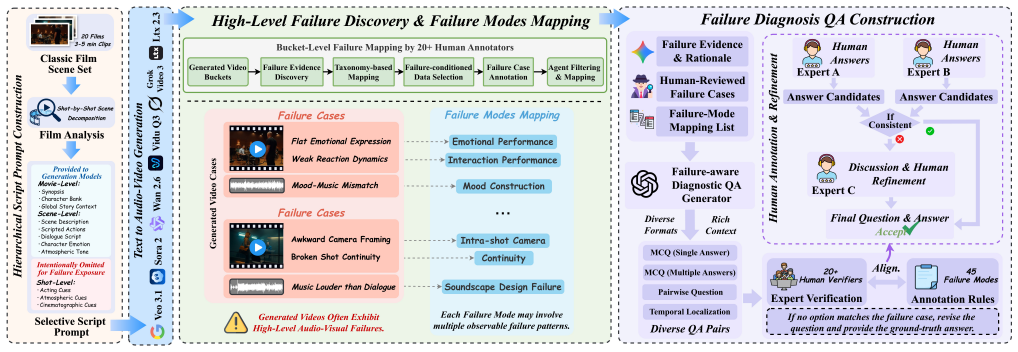
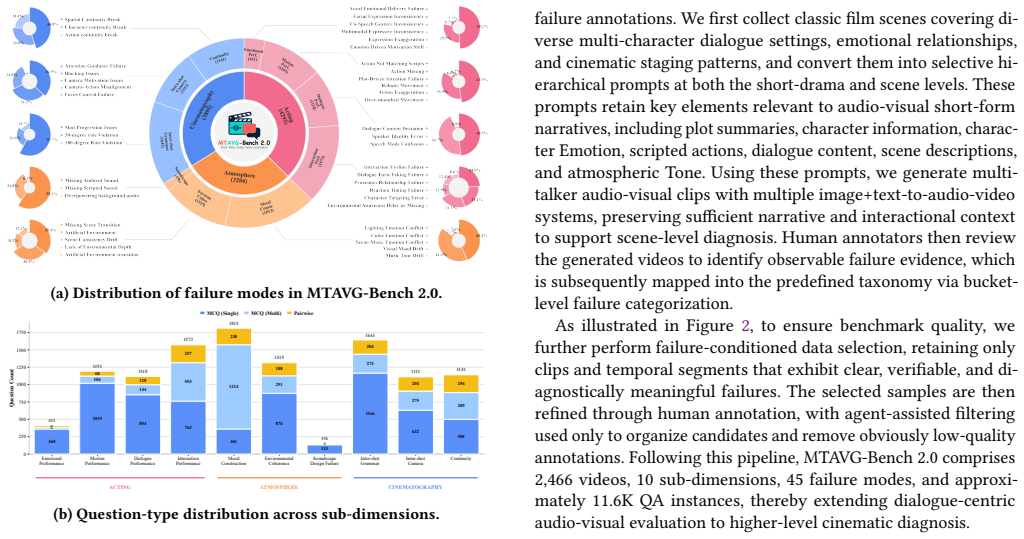
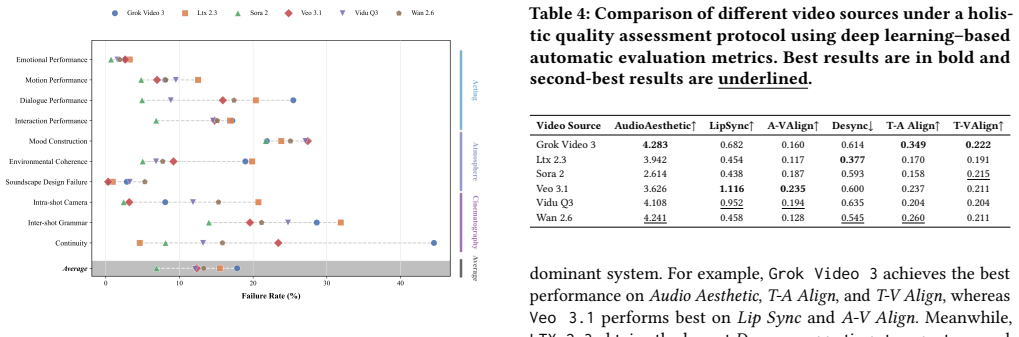
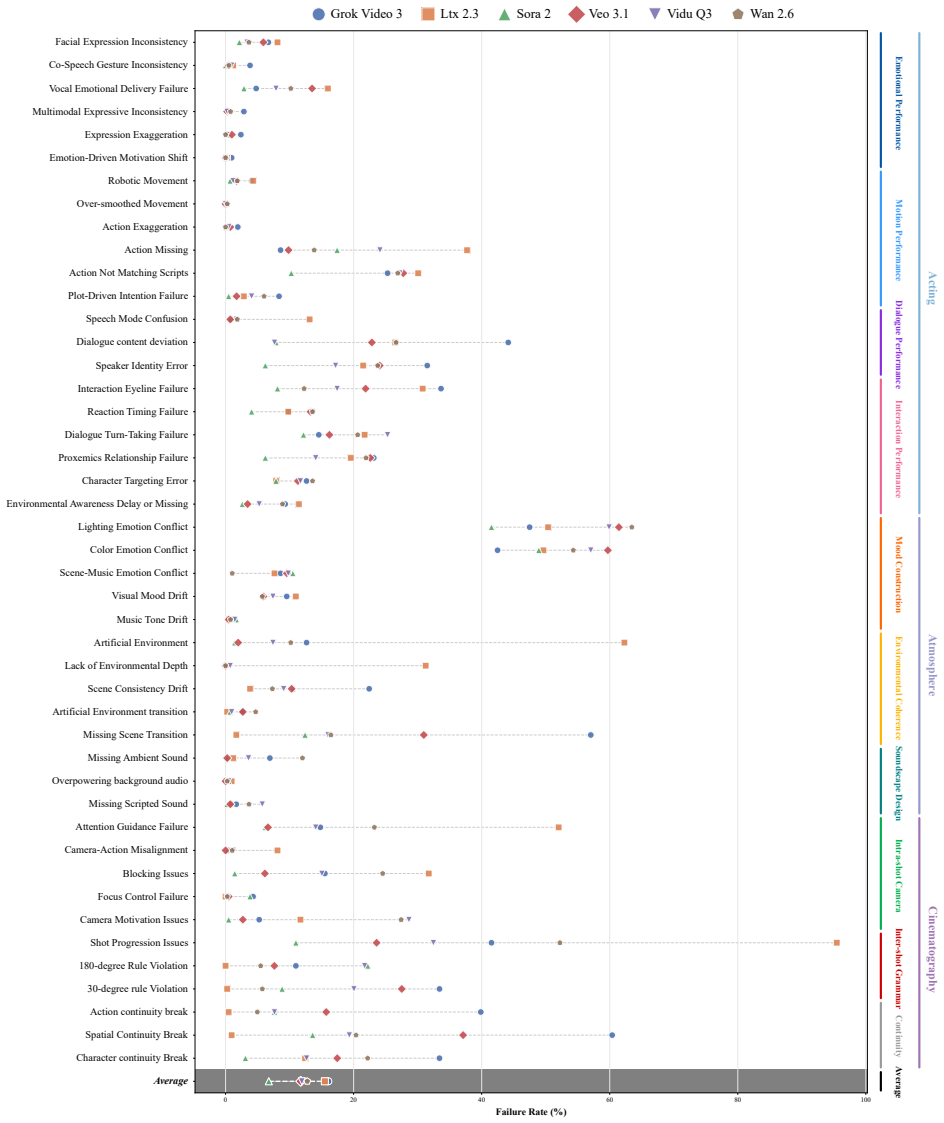
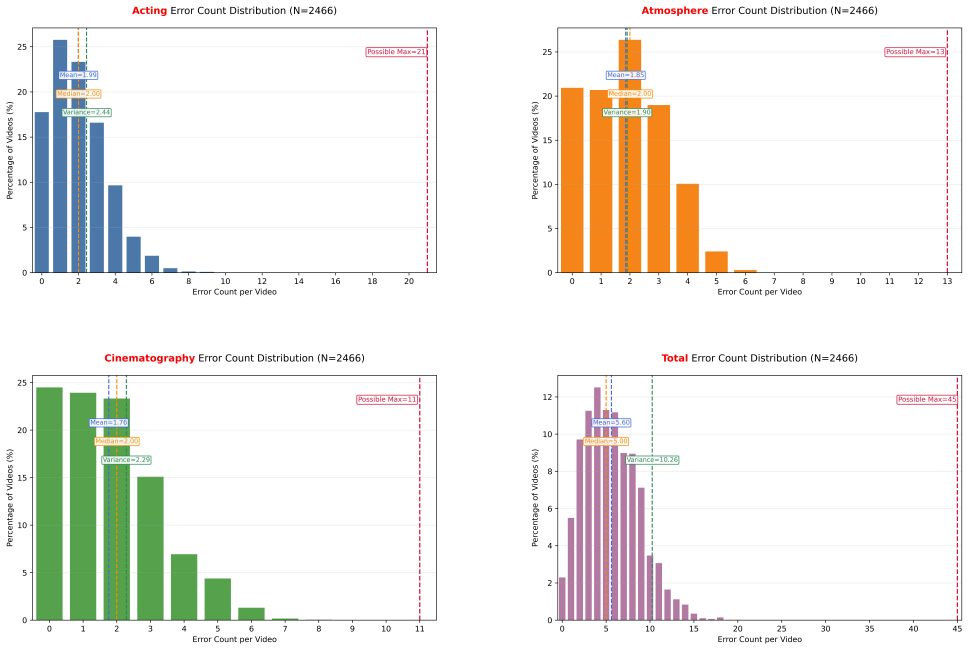
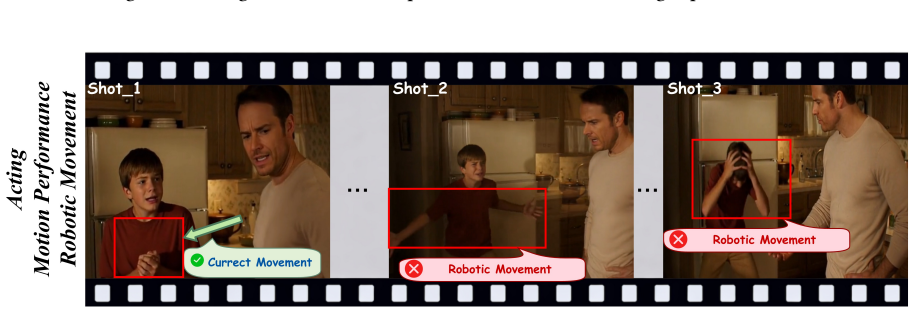
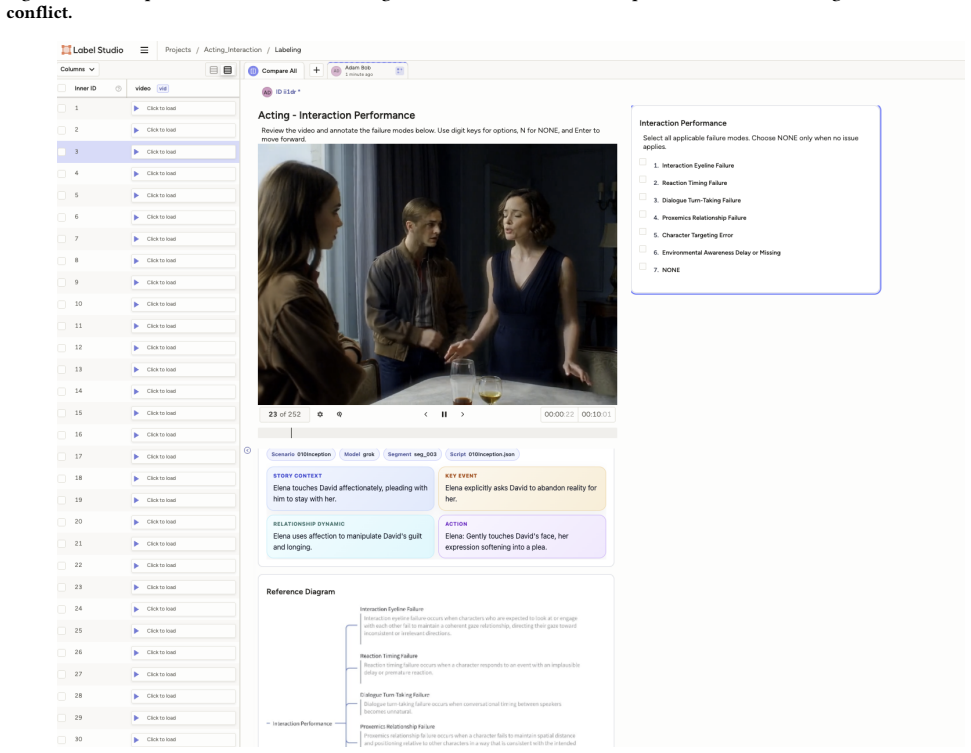
MTAVG-Bench 2.0 establishes a high-level failure taxonomy spanning acting, narrative, atmosphere, and audio-visual language, then uses it to construct more than 10,000 question-answering instances plus short-drama and temporal-localization subsets that let omni large language models diagnose cinematic expressiveness failures in multi-talker scene generation; commercial models lead the evaluations but continue to struggle with complex cases.
What carries the argument
The four-part failure taxonomy (acting, narrative, atmosphere, audio-visual language) together with the constructed QA instances that turn those categories into diagnostic tests for generation outputs.
If this is right
- Evaluation of MTAVG models must incorporate scene-level criteria for character performance and narrative coherence rather than relying only on low-level alignment metrics.
- Omni large language models can serve as evaluators for these higher-level failures, though even the strongest ones require further improvement on complex cases.
- Short-drama and temporal localization subsets enable more granular diagnosis of where and how failures occur within generated clips.
- Development of next MTAVG systems should target the specific failure modes identified in the taxonomy.
Where Pith is reading between the lines
- The benchmark could be used as a training signal to steer generation models toward better cinematic qualities during fine-tuning.
- Similar taxonomies might be adapted to single-talker or non-dialogue video generation tasks.
- If the taxonomy proves stable across new model releases, it could become a standard yardstick for progress in expressive multi-character video.
Load-bearing premise
The chosen failure categories and the 10,000 QA instances fully and fairly represent the cinematic expressiveness problems that actually occur in multi-talker scene generation.
What would settle it
Release a new MTAVG model that scores high on the benchmark yet produces scenes judged incoherent by human viewers on acting or narrative grounds, or conversely a model that improves dramatically on human cinematic judgments while scoring low on the benchmark.
Figures












read the original abstract
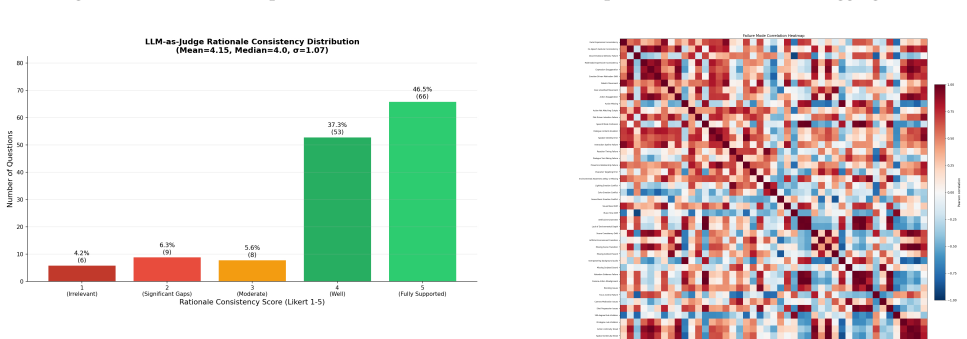
In recent years, Multi-Talker Audio-Video Generation (MTAVG) models have shown promising performance on fundamental metrics such as lip-sync and audio-visual alignment. However, these metrics remain insufficient for assessing cinematic expressiveness in scene-level generation. In multi-character scenes, generation models must go beyond audio-visual realism to convey coherent character performance and other higher-level cinematic qualities. To fill this gap, we introduce MTAVG-Bench 2.0, a benchmark for diagnosing failure modes of cinematic expressiveness in multi-talker audio-video generation. Unlike prior settings that mainly focus on the quality of basic multi-turn dialogue, MTAVG-Bench 2.0 targets short-drama and scene-level generation, and establishes a high-level failure taxonomy spanning acting, narrative, atmosphere, and audio-visual language. Based on this taxonomy, we construct more than 10,000 question-answering evaluation instances, together with subsets for short-drama-level assessment and temporal localization of failure modes, to systematically evaluate the ability of omni large language models to diagnose high-level audio-visual failures. Experimental results show that commercial omni models such as Gemini substantially outperform other evaluators, yet even the strongest models continue to struggle with complex failures in our benchmark. These results demonstrate that MTAVG-Bench 2.0 provides a systematic benchmark for failure diagnosis in cinematic multi-talker audio-video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MTAVG-Bench 2.0, a benchmark for diagnosing failure modes of cinematic expressiveness in multi-talker audio-video generation. It defines a four-category taxonomy (acting, narrative, atmosphere, audio-visual language), constructs over 10,000 QA instances plus subsets for short-drama assessment and temporal localization, and evaluates omni LLMs, finding that commercial models such as Gemini substantially outperform others yet all struggle with complex failures.
Significance. If the taxonomy and instances are shown to be exhaustive and reliably annotated, the benchmark would fill a clear gap by moving beyond low-level metrics (lip-sync, alignment) to scene-level cinematic qualities, offering a diagnostic tool for MTAVG model development.
major comments (2)
- [Abstract] Abstract and construction description: the central claim that MTAVG-Bench 2.0 supplies a 'systematic benchmark' for failure diagnosis rests on the taxonomy being exhaustive and the >10k QA instances being reliable, yet no details are provided on taxonomy derivation, annotation protocol, inter-annotator agreement, or external validation. This omission directly undermines trustworthiness of the reported failure diagnoses.
- [Experiments] Experimental results section: the claim that Gemini 'substantially outperform[s] other evaluators' and that 'even the strongest models continue to struggle' cannot be interpreted without evidence that the evaluation instances faithfully instantiate the taxonomy without annotator bias or omitted modes; the reported performance gaps may reflect benchmark artifacts rather than model capabilities.
minor comments (1)
- [Abstract] The abstract refers to 'subsets for short-drama-level assessment and temporal localization' without clarifying how these subsets are constructed or sampled from the main 10k instances.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of benchmark reliability and construction details. We will revise the manuscript to incorporate the requested information on taxonomy derivation, annotation protocols, and validation, which will strengthen the claims regarding the systematic nature of MTAVG-Bench 2.0.
read point-by-point responses
-
Referee: [Abstract] Abstract and construction description: the central claim that MTAVG-Bench 2.0 supplies a 'systematic benchmark' for failure diagnosis rests on the taxonomy being exhaustive and the >10k QA instances being reliable, yet no details are provided on taxonomy derivation, annotation protocol, inter-annotator agreement, or external validation. This omission directly undermines trustworthiness of the reported failure diagnoses.
Authors: We agree that these methodological details are critical for establishing trustworthiness. In the revised manuscript, we will add a new subsection under 'Benchmark Construction' detailing: (1) taxonomy derivation via systematic review of cinematic expressiveness literature (e.g., acting theory, narrative structure) combined with iterative expert input from film studies collaborators; (2) the full annotation protocol, including guidelines, training procedures, and quality control steps; (3) inter-annotator agreement statistics (e.g., Fleiss' kappa) computed across multiple annotators on sampled instances; and (4) external validation efforts, such as alignment checks against existing scene-level video analysis resources. These additions will directly support the claim of a systematic benchmark. revision: yes
-
Referee: [Experiments] Experimental results section: the claim that Gemini 'substantially outperform[s] other evaluators' and that 'even the strongest models continue to struggle' cannot be interpreted without evidence that the evaluation instances faithfully instantiate the taxonomy without annotator bias or omitted modes; the reported performance gaps may reflect benchmark artifacts rather than model capabilities.
Authors: We concur that the experimental claims require supporting evidence of instance fidelity. The planned revisions to the construction section will provide this by documenting the taxonomy's coverage, annotation reliability metrics, and steps taken to minimize bias (e.g., diverse annotator backgrounds and adjudication processes). We will also add a limitations paragraph acknowledging that while the taxonomy targets major cinematic failure modes, complete exhaustiveness cannot be formally proven; however, the >10k instances and subsets for short-drama and temporal localization offer broad coverage. This will allow readers to evaluate whether performance differences reflect model capabilities rather than artifacts. revision: yes
Circularity Check
No significant circularity; benchmark construction is self-contained
full rationale
The paper introduces MTAVG-Bench 2.0 by defining a four-category failure taxonomy (acting, narrative, atmosphere, audio-visual language) and constructing >10k QA instances plus subsets for short-drama and temporal localization. This is the standard, non-circular workflow for benchmark papers: the taxonomy and instances are new artifacts created by the authors, and model evaluations (e.g., Gemini outperforming others) are performed against them without any equation, fitted parameter, or self-citation reducing a claimed result to its own inputs by construction. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided abstract or description. The central claim remains independent of the benchmark's internal construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The proposed taxonomy of acting, narrative, atmosphere, and audio-visual language covers the relevant high-level cinematic qualities without significant omissions or overlaps.
Reference graph
Works this paper leans on
- [1]
-
[2]
Zhe Cao, Tao Wang, Jiaming Wang, Yanghai Wang, Yuanxing Zhang, Jialu Chen, Miao Deng, Jiahao Wang, Yubin Guo, Chenxi Liao, et al. 2025. T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation.arXiv preprint arXiv:2512.21094(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. 2024. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Ziyun Dai, Xiaoqiang Li, Shaohua Zhang, Yuanchen Wu, and Jide Li. 2025. See different, think better: Visual variations mitigating hallucinations in lvlms. In Proceedings of the 33rd ACM International Conference on Multimedia. 3310–3319
2025
-
[5]
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. 2025. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
Yuwei Guo, Ceyuan Yang, Ziyan Yang, Zhibei Ma, Zhijie Lin, Zhenheng Yang, Dahua Lin, and Lu Jiang. 2025. Long context tuning for video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 17281– 17291
2025
-
[8]
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. 2026. LTX-2: Efficient Joint Audio-Visual Foundation Model. arXiv preprint arXiv:2601.03233(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Hui Han, Siyuan Li, Jiaqi Chen, Yiwen Yuan, Yuling Wu, Yufan Deng, Chak Tou Leong, Hanwen Du, Junchen Fu, Youhua Li, et al. 2025. Video-bench: Human- aligned video generation benchmark. InProceedings of the Computer Vision and Pattern Recognition Conference. 18858–18868
2025
- [10]
-
[11]
Daili Hua, Xizhi Wang, Bohan Zeng, Xinyi Huang, Hao Liang, Junbo Niu, Xinlong Chen, Quanqing Xu, and Wentao Zhang. 2025. Vabench: A comprehensive benchmark for audio-video generation.arXiv preprint arXiv:2512.09299(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
Xuekun Jiang, Anyi Rao, Jingbo Wang, Dahua Lin, and Bo Dai. 2024. Cinematic behavior transfer via nerf-based differentiable filming. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6723–6732
2024
-
[14]
Jie Li, Hongyi Cai, Mingkang Dong, Muxin Pu, Shan You, Fei Wang, and Tao Huang. 2025. Pistachio: Towards Synthetic, Balanced, and Long-Form Video Anomaly Benchmarks.arXiv preprint arXiv:2511.19474(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [15]
- [16]
- [17]
- [18]
- [19]
- [20]
-
[21]
Chetwin Low, Weimin Wang, and Calder Katyal. 2025. Ovi: Twin backbone cross-modal fusion for audio-video generation.arXiv preprint arXiv:2510.01284 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Yuxin Mao, Xuyang Shen, Jing Zhang, Zhen Qin, Jinxing Zhou, Mochu Xiang, Yiran Zhong, and Yuchao Dai. 2024. Tavgbench: Benchmarking text to audible- video generation. InProceedings of the 32nd ACM International Conference on Multimedia. 6607–6616
2024
-
[23]
Chenyu Mu, Xin He, Qu Yang, Wanshun Chen, Jiadi Yao, Huang Liu, Zihao Yi, Bo Zhao, Xingyu Chen, Ruotian Ma, et al. 2026. The Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation. arXiv preprint arXiv:2601.17737(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Anyi Rao, Xuekun Jiang, Yuwei Guo, Linning Xu, Lei Yang, Libiao Jin, Dahua Lin, and Bo Dai. 2023. Dynamic storyboard generation in an engine-based virtual environment for video production. InACM SIGGRAPH 2023 Posters. 1–2
2023
- [25]
-
[26]
Yufei Shi, Weilong Yan, Gang Xu, Yumeng Li, Yucheng Chen, Zhenxi Li, Fei Yu, Ming Li, and Si Yong Yeo. 2025. Pvchat: Personalized video chat with one-shot learning. InProceedings of the IEEE/CVF International Conference on Computer Vision. 23321–23331
2025
-
[27]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [28]
- [29]
- [30]
-
[31]
Weijia Wu, Mingyu Liu, Zeyu Zhu, Xi Xia, Haoen Feng, Wen Wang, Kevin Qinghong Lin, Chunhua Shen, and Mike Zheng Shou. 2025. Moviebench: A hierarchical movie level dataset for long video generation. InProceedings of the Computer Vision and Pattern Recognition Conference. 28984–28994
2025
-
[32]
Junfei Xiao, Ceyuan Yang, Lvmin Zhang, Shengqu Cai, Yang Zhao, Yuwei Guo, Gordon Wetzstein, Maneesh Agrawala, Alan Yuille, and Lu Jiang. 2025. Cap- tain cinema: Towards short movie generation. InThe Fourteenth International Conference on Learning Representations
2025
-
[33]
Tianxin Xie, Wentao Lei, Guanjie Huang, Pengfei Zhang, Kai Jiang, Chunhui Zhang, Fengji Ma, Haoyu He, Han Zhang, Jiangshan He, et al. 2025. PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation.arXiv preprint arXiv:2512.23994(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. 2025. Qwen2.5-Omni Technical Report. arXiv:2503.20215 [cs.CL] https://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Songlin Yang, Zhe Wang, Xuyi Yang, Songchun Zhang, Xianghao Kong, Taiyi Wu, Xiaotong Zhao, Ran Zhang, Alan Zhao, and Anyi Rao. [n. d.]. ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation. ([n. d.])
-
[36]
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, Qianyu Chen, Huarong Zhou, Zhensheng Zou, Haoye Zhang, Shengding Hu, Zhi Zheng, Jie Zhou, Jie Cai, Xu Han, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. MiniCPM-V: A GPT-4V Level MLLM on Your Phone. arXiv:2408.01800 [cs.CV] http...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [37]
-
[38]
Fan Zhang, Shulin Tian, Ziqi Huang, Yu Qiao, and Ziwei Liu. 2025. Evaluation agent: Efficient and promptable evaluation framework for visual generative mod- els. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7561–7582
2025
- [39]
- [40]
-
[41]
Yang-Hao Zhou, Haitian Li, Rexar Lin, Heyan Huang, Jinxing Zhou, Changsen Yuan, Tian Lan, Ziqin Zhou, Yudong Li, Jiajun Xu, et al. 2026. MTAVG-Bench: A Comprehensive Benchmark for Evaluating Multi-Talker Dialogue-Centric Audio- Video Generation.arXiv preprint arXiv:2602.00607(2026). 9
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Ziwei Zhou, Zeyuan Lai, Rui Wang, Yifan Yang, Zhen Xing, Yuqing Yang, Qi Dai, Lili Qiu, and Chong Luo. 2026. AVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation.arXiv preprint arXiv:2604.08540(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
clip_summary
Junchen Zhu, Huan Yang, Huiguo He, Wenjing Wang, Zixi Tuo, Wen-Huang Cheng, Lianli Gao, Jingkuan Song, and Jianlong Fu. 2023. Moviefactory: Auto- matic movie creation from text using large generative models for language and images. InProceedings of the 31st ACM International Conference on Multimedia. 9313–9319. 10 Appendix A Prompt Design for Benchmark Co...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.