VLA-Hijack: A Transferable Patch Attack against Vision-Language-Action Models via Visual Proprioception Hijacking
Pith reviewed 2026-06-29 12:56 UTC · model grok-4.3
The pith
VLA models can be attacked by patches that suppress their visual self-location of the real arm and inject a phantom one, enabling black-box transfer across different architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By targeting the shared visual self-localization process, VLA-Hijack concurrently optimizes Attention-Guided Proprioceptive Suppression and Multimodal Proprioceptive Injection to sever the semantic relationship between the agent's true embodiment and its control policy, achieving superior optimization efficiency in white-box settings and new SOTA cross-architecture and cross-domain black-box transferability across OpenVLA, UniVLA, and CronusVLA.
What carries the argument
Attention-Guided Proprioceptive Suppression and Multimodal Proprioceptive Injection, which alternate between semantic concept anchoring and visual prototype projection to inhibit real arm features and establish the patch as a phantom embodiment.
If this is right
- Previous white-box patch attacks that overfit to specific action outputs become less necessary, as the new method focuses on the common localization step.
- Black-box attacks no longer need model-specific tuning to achieve high transfer rates across different VLA architectures.
- Cross-domain transfer becomes feasible without retraining the patch for each new environment or robot setup.
- Safety-critical deployments of VLA models must now account for visual proprioception as a distinct attack surface.
Where Pith is reading between the lines
- If the visual self-localization step is universal, then hardening only the policy head or language components would leave models exposed.
- Designers could test whether reducing visual dependence for arm tracking, such as by adding dedicated proprioceptive sensors, reduces vulnerability.
- The same suppression-injection pattern might apply to other embodied agents that rely on vision to track their own body parts.
- Future work could measure how much the transfer rate drops when models are trained with explicit arm-localization defenses.
Load-bearing premise
All VLA models must first use visual information to locate their own robotic arm within the environment before planning any motion, and this process is similar enough across architectures to allow transfer via the hijacking method.
What would settle it
A demonstration that a VLA model can generate actions without first visually identifying its own arm's location in the scene, or that the self-localization step differs so much between architectures that the suppression and injection steps fail to transfer.
Figures

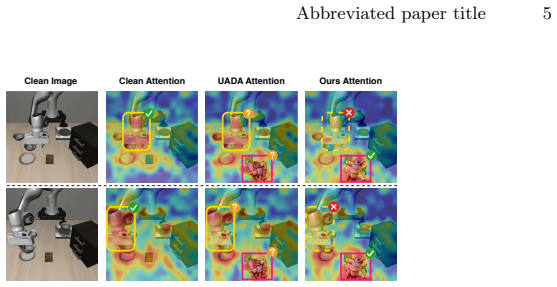
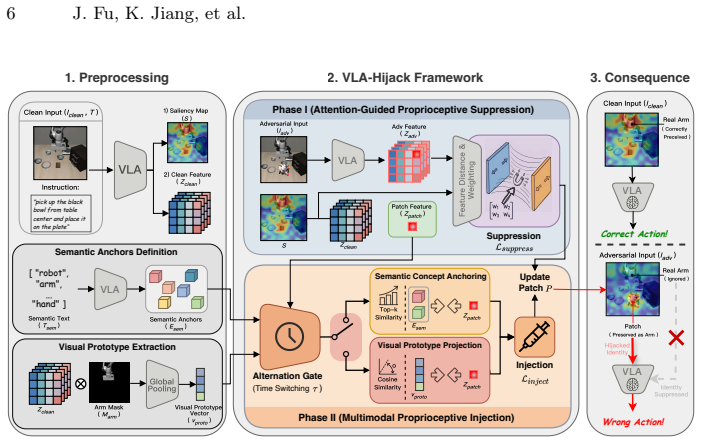
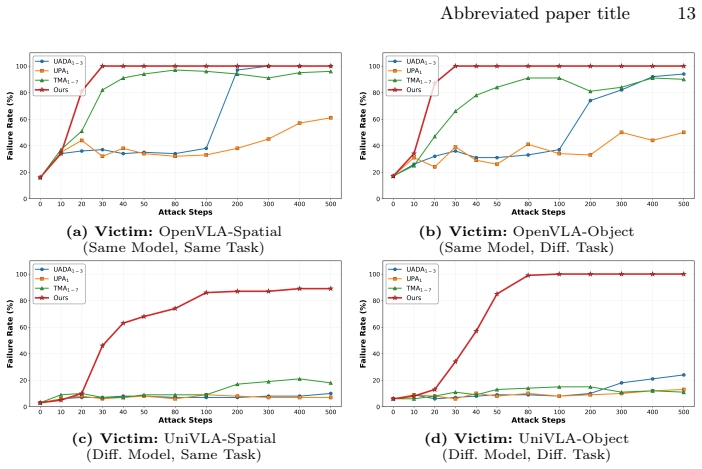
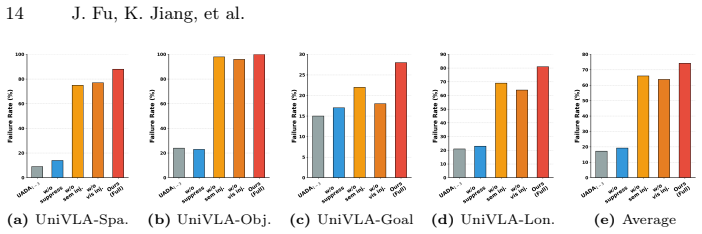

read the original abstract
While Vision-Language-Action (VLA) models have emerged as powerful generalist policies, their severe vulnerability to adversarial patches significantly hinders their deployment in safety-critical domains. Moreover, existing patch attacks primarily focus on white-box settings, heavily overfitting to the specific action output space of the target model, which results in poor cross-architecture transferability. To overcome this limitation, we propose VLA-Hijack, a unified adversarial framework that breaks the transferability bottleneck by exploiting a fundamental vulnerability identified in this work: before planning any motion, a VLA model must first use visual information to locate its own robotic arm within the environment. Targeting this shared visual self-localization process, our approach concurrently optimizes Attention-Guided Proprioceptive Suppression to inhibit the real robotic arm's features, and Multimodal Proprioceptive Injection to establish the patch as a surrogate "phantom embodiment". By alternating between semantic concept anchoring and visual prototype projection, VLA-Hijack effectively severs the semantic relationship between the agent's true embodiment and its control policy. Extensive experiments across diverse architectures (OpenVLA, UniVLA, and CronusVLA) demonstrate that VLA-Hijack achieves superior optimization efficiency in white-box settings and sets a new SOTA for cross-architecture and cross-domain black-box transferability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VLA-Hijack, a unified adversarial patch framework for Vision-Language-Action (VLA) models. It identifies a purported fundamental vulnerability—that VLAs must first use visual information to locate their own robotic arm before any motion planning—and concurrently optimizes Attention-Guided Proprioceptive Suppression (to inhibit real-arm features) and Multimodal Proprioceptive Injection (to establish the patch as a phantom embodiment). By alternating semantic concept anchoring and visual prototype projection, the method severs the link between true embodiment and control policy. Experiments across OpenVLA, UniVLA, and CronusVLA are claimed to show superior white-box optimization efficiency and new SOTA cross-architecture/cross-domain black-box transferability.
Significance. If the shared visual self-localization assumption holds and is mechanistically validated, the work would be significant for exposing transferable vulnerabilities in embodied generalist policies and for advancing black-box attack methods beyond overfitting to specific action spaces. The emphasis on cross-architecture transfer addresses a documented limitation of prior patch attacks on VLAs.
major comments (2)
- [Abstract] Abstract: The central claim rests on the assertion that 'before planning any motion, a VLA model must first use visual information to locate its own robotic arm within the environment' as a shared process across architectures. No attention maps, layer-wise ablations, or controlled experiments isolating arm localization from language-conditioned or global scene features are referenced, leaving the mechanistic justification for suppression and injection unverified. If models instead route actions through non-proprioceptive pathways, the transferability results may reflect generic patch optimization rather than hijacking of a common bottleneck.
- [Abstract] Abstract: The claim of 'SOTA for cross-architecture and cross-domain black-box transferability' is load-bearing for the contribution, yet the abstract provides no quantitative baselines, error bars, or architecture-specific transfer rates. Without these, it is impossible to assess whether the gains exceed prior methods or arise from the proposed proprioceptive mechanism.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments point-by-point below. Both concerns can be met by targeted revisions to the abstract and, where appropriate, by referencing existing results from the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim rests on the assertion that 'before planning any motion, a VLA model must first use visual information to locate its own robotic arm within the environment' as a shared process across architectures. No attention maps, layer-wise ablations, or controlled experiments isolating arm localization from language-conditioned or global scene features are referenced, leaving the mechanistic justification for suppression and injection unverified. If models instead route actions through non-proprioceptive pathways, the transferability results may reflect generic patch optimization rather than hijacking of a common bottleneck.
Authors: The full manuscript supports the shared visual self-localization premise through the consistent cross-architecture transfer gains obtained only when both suppression and injection are applied; prior patch methods that ignore this step show markedly lower transfer. We will revise the abstract to explicitly reference the ablation results on the two components and the three-architecture transfer tables that isolate the contribution of proprioceptive targeting. If the editor requests, we can also add attention-map figures to the supplement. revision: partial
-
Referee: [Abstract] Abstract: The claim of 'SOTA for cross-architecture and cross-domain black-box transferability' is load-bearing for the contribution, yet the abstract provides no quantitative baselines, error bars, or architecture-specific transfer rates. Without these, it is impossible to assess whether the gains exceed prior methods or arise from the proposed proprioceptive mechanism.
Authors: We agree that the abstract should contain the key quantitative evidence. We will revise it to report the principal black-box transfer success rates (with standard deviations over repeated trials) for each source-target pair and the corresponding margins over the strongest prior patch baseline. revision: yes
Circularity Check
No circularity: empirical attack framework rests on stated assumption without self-referential derivations or fitted predictions
full rationale
The provided abstract and description contain no equations, parameter-fitting steps, or derivation chains. The central premise—that VLA models must first perform visual self-localization of the robotic arm—is presented as an identified vulnerability rather than derived from prior results or self-citations. The attack components (Attention-Guided Proprioceptive Suppression and Multimodal Proprioceptive Injection) are described as optimization procedures without any indication that outputs reduce to inputs by construction or that uniqueness is imported via author self-citation. This is an empirical proposal whose validity depends on external validation experiments, not internal definitional closure. No load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Before planning any motion, a VLA model must first use visual information to locate its own robotic arm within the environment.
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Shi, L.X., Tanner, J., Vuong, Q., Walling, A., Wang, H., Zhilinsky, U.:π0: A vision-language-action flow model for general robot control. CoRRabs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., Florence, P., Fu, C., Arenas, M.G., Gopalakrishnan, K., Han, K., Hausman, K., Herzog, A., Hsu, J., Ichter, B., Irpan, A., Joshi, N.J., Julian, R., Kalashnikov, D., Kuang, Y., Leal, I., Lee, L., Lee, T.E., Levine, S., Lu, Y., Michalewski...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Bu, Q., Yang, Y., Cai, J., Gao, S., Ren, G., Yao, M., Luo, P., Li, H.: Univla: Learning to act anywhere with task-centric latent actions. CoRRabs/2505.06111 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., Doll...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
IEEE Trans
Chen, Z., Li, B., Wu, S., Ding, S., Zhang, W.: Query-efficient decision-based black- box patch attack. IEEE Trans. Inf. Forensics Secur.18, 5522–5536 (2023)
2023
-
[6]
Fu, J., Chen, Z., Jiang, K., Guo, H., Gao, S., Zhang, W.: Pg-attack: A precision- guided adversarial attack framework against vision foundation models for au- tonomous driving. CoRRabs/2407.13111(2024)
-
[7]
arXiv preprint arXiv:2403.10883 (2024)
Fu, J., Chen, Z., Jiang, K., Guo, H., Wang, J., Gao, S., Zhang, W.: Improving adversarial transferability of visual-language pre-training models through collabo- rative multimodal interaction. CoRRabs/2403.10883(2024)
-
[8]
LingoLoop Attack: Trapping MLLMs via Linguistic Context and State Entrapment into Endless Loops
Fu, J., Jiang, K., Hong, L., Li, J., Guo, H., Yang, D., Chen, Z., Zhang, W.: Lin- goloop attack: Trapping mllms via linguistic context and state entrapment into endless loops. CoRRabs/2506.14493(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Guo, J., Jiang, W., Lin, Y., Liu, Y., Zhang, R., Lu, G., Chen, A., Han, X., Li, H., Niyato, D.: State backdoor: Towards stealthy real-world poisoning attack on vision-language-action model in state space. CoRRabs/2601.04266(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023
Jiang, K., Chen, Z., Huang, H., Wang, J., Yang, D., Li, B., Wang, Y., Zhang, W.: Efficient decision-based black-box patch attacks on video recognition. In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 4356–4366. IEEE (2023)
2023
-
[11]
In: Agrawal, P., Kroemer, O., Burgard, W
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E.P., Sanketi, P.R., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., Finn, C.: Openvla: An open-source vision-language-action model. In: Agrawal, P., Kroemer, O., Burgard, W. (eds.) Conference on Robot Learning, 6-9 Nove...
2024
-
[12]
Li, H., Yang, S., Chen, Y., Tian, Y., Yang, X., Chen, X., Wang, H., Wang, T., Zhao, F., Lin, D., Pang, J.: Cronusvla: Transferring latent motion across time for multi-frame prediction in manipulation. CoRRabs/2506.19816(2025)
-
[13]
What Matters in Building Vision-Language-Action Models for Generalist Robots
Li, X., Li, P., Liu, M., Wang, D., Liu, J., Kang, B., Ma, X., Kong, T., Zhang, H., Liu, H.: Towards generalist robot policies: What matters in building vision- language-action models. CoRRabs/2412.14058(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
In: The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Li, X., Liu, M., Zhang, H., Yu, C., Xu, J., Wu, H., Cheang, C., Jing, Y., Zhang, W., Liu, H., Li, H., Kong, T.: Vision-language foundation models as effective robot imitators. In: The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net (2024)
2024
-
[15]
arXiv preprint arXiv:2602.03153 (2026)
Li, X., Fu, P., Huang, W., Pan, N., Yang, S., Zhao, K., Wan, G., Li, M., Xuan, J., Li, M.: When attention betrays: Erasing backdoor attacks in robotic policies by reconstructing visual tokens. arXiv preprint arXiv:2602.03153 (2026)
-
[16]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: LIBERO: bench- marking knowledge transfer for lifelong robot learning. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Infor- mation Processing Systems 36: Annual Conference on Neural Information Process- ing Systems 2023, NeurIPS 2023, Ne...
2023
-
[17]
Lu, H., Yu, Y., Yang, Y., Yi, C., Zhang, Q., Shen, B., Kot, A.C., Jiang, X.: When robots obey the patch: Universal transferable patch attacks on vision-language- action models. CoRRabs/2511.21192(2025)
-
[18]
Lu, X., Chen, J., Xiao, S., Jin, Z., Chen, Z., Yu, H., Qian, B., Zhou, R., Ji, X., Xu, W.: Phantom menace: Exploring and enhancing the robustness of VLA models against physical sensor attacks. CoRRabs/2511.10008(2025)
-
[19]
In: IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022, Waikoloa, HI, USA, January 3-8, 2022
Nesti, F., Rossolini, G., Nair, S., Biondi, A., Buttazzo, G.C.: Evaluating the robust- ness of semantic segmentation for autonomous driving against real-world adversar- ial patch attacks. In: IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022, Waikoloa, HI, USA, January 3-8, 2022. pp. 2826–2835. IEEE (2022)
2022
-
[20]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Qu, D., Song, H., Chen, Q., Yao, Y., Ye, X., Ding, Y., Wang, Z., Gu, J., Zhao, B., Wang, D., Li, X.: Spatialvla: Exploring spatial representations for visual-language- action model. CoRRabs/2501.15830(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
IEEE Trans
Ran, Y., Wang, W., Li, M., Li, L., Wang, Y., Li, J.: Cross-shaped adversarial patch attack. IEEE Trans. Circuits Syst. Video Technol.34(4), 2289–2303 (2024)
2024
-
[22]
In: Tan, J., Toussaint, M., Darvish, K
Walke, H.R., Black, K., Zhao, T.Z., Vuong, Q., Zheng, C., Hansen-Estruch, P., He, A.W., Myers, V., Kim, M.J., Du, M., Lee, A., Fang, K., Finn, C., Levine, S.: Bridgedata V2: A dataset for robot learning at scale. In: Tan, J., Toussaint, M., Darvish, K. (eds.) Conference on Robot Learning, CoRL 2023, 6-9 November 2023, Atlanta, GA, USA. Proceedings of Mach...
2023
-
[23]
Wang, T., Liu, D., Liang, J.C., Yang, W., Wang, Q., Han, C., Luo, J., Tang, R.: Exploring the adversarial vulnerabilities of vision-language-action models in robotics. CoRRabs/2411.13587(2024)
-
[24]
Wang, Y., Zhang, H., Pan, H., Zhou, Z., Wang, X., Guo, P., Xue, L., Hu, S., Li, M., Zhang, L.Y.: Advedm:fine-grained adversarial attack against vlm-based embodied agents. CoRRabs/2509.16645(2025)
-
[25]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Wen,J.,Zhu,Y.,Li,J.,Tang,Z.,Shen,C.,Feng,F.:Dexvla:Vision-languagemodel with plug-in diffusion expert for general robot control. CoRRabs/2502.05855 (2025) 18 J. Fu, K. Jiang, et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
IEEE Robotics Autom
Wen, J., Zhu, Y., Li, J., Zhu, M., Tang, Z., Wu, K., Xu, Z., Liu, N., Cheng, R., Shen, C., Peng, Y., Feng, F., Tang, J.: Tinyvla: Toward fast, data-efficient vision- language-action models for robotic manipulation. IEEE Robotics Autom. Lett. 10(4), 3988–3995 (2025)
2025
-
[27]
Xu, B., Shang, Y., Wang, B., Ferrara, E.: Silentdrift: Exploiting action chunk- ing for stealthy backdoor attacks on vision-language-action models. CoRR abs/2601.14323(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Xu, H., Koh, Y.S., Huang, S., Zhou, Z., Wang, D., Sakuma, J., Zhang, J.: Model- agnostic adversarial attack and defense for vision-language-action models. CoRR abs/2510.13237(2025)
-
[29]
Xu, Z., Zheng, X., Ma, X., Jiang, Y.: Tabvla: Targeted backdoor attacks on vision- language-action models. CoRRabs/2510.10932(2025)
-
[30]
In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J
Yang, C., Kortylewski, A., Xie, C., Cao, Y., Yuille, A.L.: Patchattack: A black- box texture-based attack with reinforcement learning. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J. (eds.) Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XXVI. Lecture Notes in Computer Science, vol. 12371, pp. 6...
2020
-
[31]
Yang, S., Li, H., Chen, Y., Wang, B., Tian, Y., Wang, T., Wang, H., Zhao, F., Liao, Y., Pang, J.: Instructvla: Vision-language-action instruction tuning from un- derstanding to manipulation. CoRRabs/2507.17520(2025)
-
[32]
SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Constrained Learning
Zhang, B., Zhang, Y., Ji, J., Lei, Y., Dai, J., Chen, Y., Yang, Y.: Safevla: Towards safety alignment of vision-language-action model via constrained learning. arXiv preprint arXiv:2503.03480 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Zhang, N., Tao, W., Xiao, X., Sun, Q., Zheng, Y., Mo, W., Wang, P., Zhang, N.: Attention-guided patch-wise sparse adversarial attacks on vision-language-action models. CoRRabs/2511.21663(2025)
-
[34]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Zhao, Y., Pang, T., Du, C., Yang, X., Li, C., Cheung, N., Lin, M.: On evaluating adversarial robustness of large vision-language models. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Infor- mation Processing Systems 36: Annual Conference on Neural Information Process- ing Systems 2023, NeurIPS 2023, Ne...
2023
-
[35]
arXiv preprint arXiv:2602.00500 (2026)
Zhou, J., Wei, Y., Zhen, R., Zhao, B., Xia, X., Shao, R., Su, X., Yang, S.: Inject once survive later: Backdooring vision-language-action models to persist through downstream fine-tuning. arXiv preprint arXiv:2602.00500 (2026)
-
[36]
Zhou, X., Tie, G., Zhang, G., Wang, H., Zhou, P., Sun, L.: Badvla: Towards back- door attacks on vision-language-action models via objective-decoupled optimiza- tion. CoRRabs/2505.16640(2025)
-
[37]
Zhou, Z., Xiao, Z., Xu, H., Sun, J., Wang, D., Zhang, J.: Goal-oriented back- door attack against vision-language-action models via physical objects. CoRR abs/2510.09269(2025)
-
[38]
Zhu, M., Zhu, Y., Li, J., Zhou, Z., Wen, J., Liu, X., Shen, C., Peng, Y., Feng, F.: Objectvla: End-to-end open-world object manipulation without demonstration. CoRRabs/2502.19250(2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.