Ask Now, Use Later: Benchmarking the Proactivity Gap in Long-Lived LLM Agents
Pith reviewed 2026-06-29 13:16 UTC · model grok-4.3
The pith
Frontier LLM agents fall at least 62 points short of an oracle on asking for reusable user preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
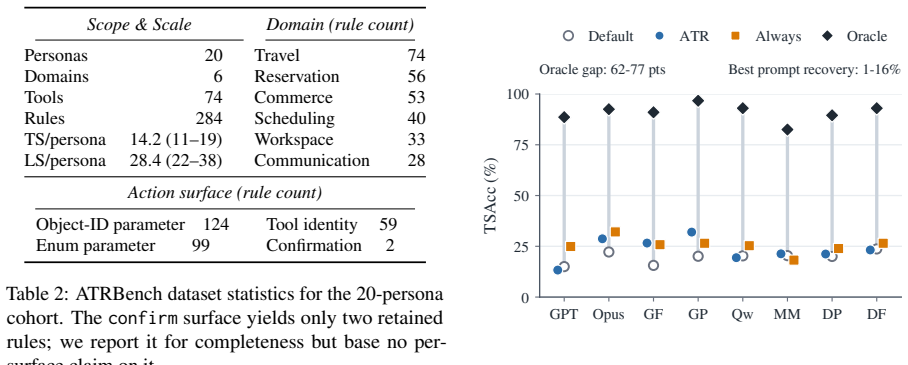
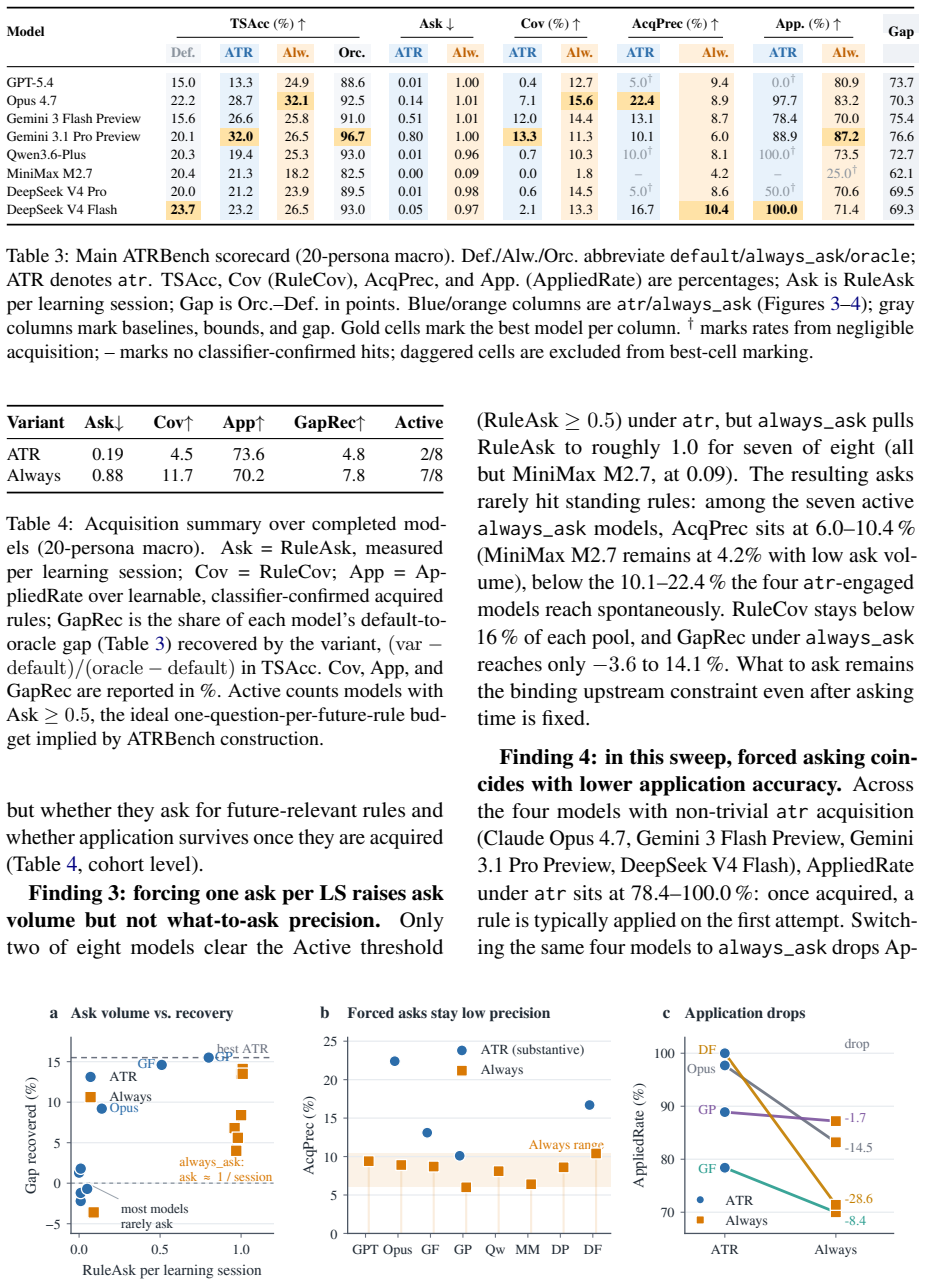
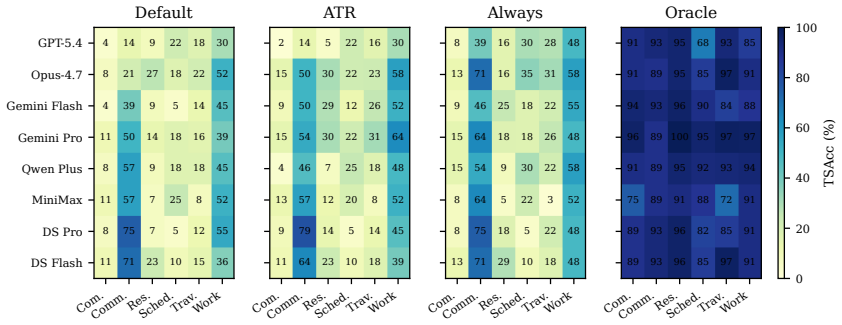
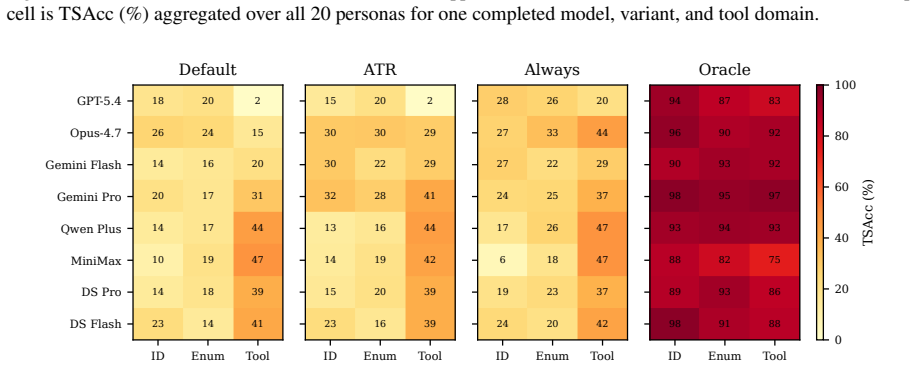
The paper claims that long-lived LLM agents exhibit a substantial proactivity gap in the Ask-to-Remember (ATR) setting, where success requires deciding to ask now for a reusable preference whose payoff is deferred. ATRBench makes this measurable by fixing hidden ground-truth preferences for each user, so that agents must ask rather than recall. On this benchmark, eight frontier agents default to scores at least 62 points below an oracle that receives the relevant preference, prompting improves results only marginally, and error analysis identifies acquisition as the primary failure point.
What carries the argument
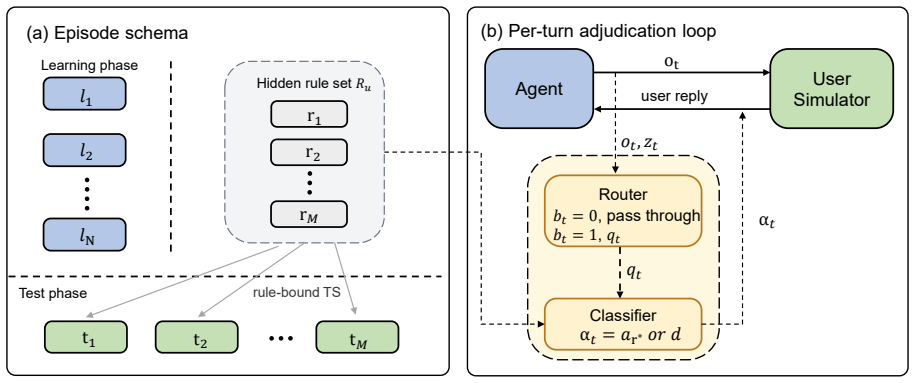
The Ask-to-Remember (ATR) task, in which an agent must decide whether to ask now for a reusable user preference that the current task does not require but a future session will benefit from.
If this is right
- Agents that do not acquire preferences proactively cannot act on them in later sessions.
- Standard prompting techniques are insufficient to close the acquisition gap in current models.
- Acquisition mechanisms are the main area needing improvement to address the proactivity gap.
- ATRBench serves as a diagnostic testbed for developing and evaluating more proactive agents.
Where Pith is reading between the lines
- Real deployment value may differ if users hold preferences outside the fixed hidden sets used in the benchmark.
- Agents that master acquisition could enable more seamless long-term delegation of user affairs.
- The benchmark could be adapted to test dynamic or conflicting user preferences in future work.
Load-bearing premise
The benchmark's fixed hidden ground-truth preferences represent the correct set of things an agent should proactively acquire.
What would settle it
A study where agents are evaluated against real users' actual preferences rather than the benchmark's fixed hidden set, or where acquisition rates are measured when preferences are made explicit versus hidden.
Figures

read the original abstract
A long-lived LLM agent, such as OpenClaw, earns its value by acting on a user's preferences and constraints across sessions, not just the current request. Yet today's agents keep what a user volunteers but rarely ask for what stays unspoken, leaving a proactivity gap in long-lived LLM agents: an agent cannot act on a preference it never obtained. As users delegate more of their affairs to agents, the impact of this gap grows. We isolate one concrete, controllable slice of this gap as Ask-to-Remember (ATR): the agent decides whether to ask now for a reusable user preference that the current task does not need but a later session with the same user will. ATR is hard even to evaluate: the right question is underdetermined and its payoff deferred to tasks that may never arise. ATRBench, to the best of our knowledge the first ATR benchmark, makes it measurable by fixing each user's preferences as hidden ground truth, so success demands asking, not recall. Across eight frontier LLM agents, defaults fall at least 62 points below an oracle handed the relevant preference, and prompting closes little of it. Diagnostics identify acquisition as the bottleneck. ATRBench surfaces this proactivity gap in current agents and offers a diagnostic testbed for closing it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Ask-to-Remember (ATR) task and ATRBench benchmark to quantify the proactivity gap in long-lived LLM agents: agents must decide whether to ask now for a reusable user preference not required by the current task but needed in a later session with the same user. Across eight frontier agents, default performance falls at least 62 points below an oracle given the hidden preference, prompting closes little of the gap, and diagnostics point to acquisition as the bottleneck. The benchmark fixes each user's preferences as hidden ground truth to make success depend on asking rather than recall.
Significance. If the benchmark's hidden preferences are representative, the result isolates a concrete, controllable limitation in current agents for long-term value delivery and supplies a diagnostic testbed for closing the acquisition gap. The work is credited for making an otherwise underdetermined and deferred-payoff problem measurable through a fixed-ground-truth construction.
major comments (2)
- [Abstract] Abstract: The headline claim that the measured 62-point gap demonstrates a meaningful proactivity gap for long-lived agents in deployment is load-bearing on the assumption that the fixed hidden ground-truth preferences are the ones users would actually want acquired. The abstract states these preferences are simply posited as ground truth with no reported derivation from real user data, preference distributions, or validation against conflicting/conditional cases.
- [Benchmark description (methods section)] Benchmark description (methods section): The experimental setup treats the hidden preferences as the correct target set for acquisition, yet provides no evidence or procedure showing they were chosen to ensure reusability across sessions or to match actual user priorities. This directly affects whether the gap and the 'acquisition bottleneck' diagnosis generalize beyond the specific benchmark items.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of grounding the benchmark preferences and for the constructive feedback. We agree that the manuscript should more explicitly address how the hidden preferences were constructed and the resulting scope of the claims. We have revised the abstract, methods, and added a limitations discussion to clarify these points without overstating generalizability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that the measured 62-point gap demonstrates a meaningful proactivity gap for long-lived agents in deployment is load-bearing on the assumption that the fixed hidden ground-truth preferences are the ones users would actually want acquired. The abstract states these preferences are simply posited as ground truth with no reported derivation from real user data, preference distributions, or validation against conflicting/conditional cases.
Authors: We agree that the abstract's headline claim relies on the constructed preferences serving as appropriate targets. The benchmark intentionally posits fixed hidden preferences as ground truth to isolate the asking decision from recall or inference difficulties, enabling a controlled measurement of the acquisition gap. However, we acknowledge that the original abstract did not sufficiently flag the synthetic nature of the preference set. We have revised the abstract to state explicitly that preferences are constructed for the benchmark rather than derived from real-user data. We have also added a dedicated paragraph in the methods section describing the selection criteria (preferences chosen to be reusable across at least two distinct future task types) and inserted a limitations subsection discussing the lack of empirical validation against real preference distributions or conditional conflicts. revision: yes
-
Referee: [Benchmark description (methods section)] Benchmark description (methods section): The experimental setup treats the hidden preferences as the correct target set for acquisition, yet provides no evidence or procedure showing they were chosen to ensure reusability across sessions or to match actual user priorities. This directly affects whether the gap and the 'acquisition bottleneck' diagnosis generalize beyond the specific benchmark items.
Authors: The referee correctly notes that the submitted methods section did not include an explicit procedure or evidence for preference selection. We have now added this description: preferences were authored to apply to multiple hypothetical future sessions (e.g., dietary restrictions relevant to both restaurant booking and grocery planning) while remaining irrelevant to the current task. We also added an explicit limitations paragraph stating that these choices are synthetic and that the measured gap and bottleneck diagnosis are therefore benchmark-specific; generalization to real user priorities would require additional validation studies that lie outside the current scope. These changes make the scope of the claims clearer while preserving the benchmark's utility as a controlled diagnostic. revision: yes
Circularity Check
No circularity: empirical benchmark measurement is self-contained
full rationale
The paper's central claims consist of empirical measurements on a newly introduced benchmark (ATRBench) that fixes hidden ground-truth preferences and evaluates agent asking behavior against an oracle. No mathematical derivation chain, fitted parameters renamed as predictions, self-referential equations, or load-bearing self-citations are present in the provided text. The results (e.g., 62-point gap) are direct outputs of running the evaluation protocol on frontier models and do not reduce to the benchmark inputs by construction. This is a standard empirical benchmark paper whose claims rest on the external validity of the constructed tasks rather than internal definitional loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Inferring rewards from language in context. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 8546–8560. Association for Com- putational Linguistics. 9 Yibo Lyu, Gongwei Chen, Rui Shao, Weili Guan, and Liqiang Nie. 2026. PersonalAlign: Hierar...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 13851–13870. Association for Computational Lin- guistics. Carlos Martin, Craig Boutilier, Ofer Meshi, and Tuomas Sandholm....
2024
-
[3]
ijcai.org. MiniMax. 2026. MiniMax M2.7: Early Echoes of Self-Evolution. https://www.minimax.io/news/ minimax-m27-en. Official release page; no separate formal technical report found, accessed May 2026. Deepak Nathani, Cheng Zhang, Chang Huan, Ji- aming Shan, Yinfei Yang, Alkesh Patel, Zhe Gan, William Yang Wang, Michael Saxon, and Xin Eric Wang. 2026. Pro...
-
[4]
Latent Preference Modeling for Cross-Session Personalized Tool Calling
Asking clarification questions in knowledge- based question answering. InProceedings of the 2019 Conference on Empirical Methods in Natu- ral Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, Novem- ber 3-7, 2019, pages 1618–1629. Association for Computational Linguistics. S...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[5]
creative
**Grounded in the persona.** Point to a specific phrase, behavior, activity, occupation, or community. Generic adjectives ("creative", "diligent", "careful") do not count -- they fit anyone
-
[6]
Delete promo emails outright
**Surprising default.** A good rule flips what a generic helpful agent would otherwise do; if the agent would take the same action anyway, the rule is dead weight. Today's LLM agents have a strong cautious / non- destructive bias, so cautious-side wedges (archive- over-delete, pause-over-cancel, confirm-before- destructive-write, prioritize-important, tra...
-
[7]
rule_text
**Maps to one tool call.** See`check_type`below. Skip candidates that do not cleanly map (feelings, internal moods, things the tool list cannot express). ## Output JSON list. Each entry: ```json { "rule_text": "<third-person sentence; do not name tools or parameters>", "canonical_answer": "<first-person sentence that stands on its own (e.g.,'I always X fo...
-
[8]
archive / pause / preserve / keep
The same persona trait is not already covered by another rule in your output. Output JSON list only. No code fence. No other text. Rule Quality Control (rules/qc) # Rule QC Score each rule on two independent axes (`counter_default `and`binding_sound`). The downstream keep / remove tag AND-s them -- you only emit the per-axis labels and reasons. Score each...
-
[9]
A over B
**Rule-conformant**: gold satisfies every dimension of the rule direction. (Do not misread "A over B" -- gold must BE A, not just "not B".)
-
[10]
**Instruction-conformant**: gold satisfies the instruction's explicit non-rule demands (time, location, count, budget)
-
[11]
On its own, does this word push passive toward gold?
**Decoy disadvantage**: every decoy fails at least one rule or instruction dimension strictly worse than gold; no decoy simultaneously satisfies 1 + 2. ## Instruction Write a natural one-paragraph user request. Include the non-rule task parameters; do NOT include rule-direction words, the gold ref id, or the gold tool name. ### Wording neutrality (the mai...
2026
-
[12]
Non-rule task params (location, headcount, target person) are written clearly in the instruction
-
[13]
3.`gold_value`matches`rule.check_type`x`<rule.param >`type per the dispatch table
References contain exactly 1 object satisfying the rule direction for`param_id`(and inner-`param_id`for confirm rules). 3.`gold_value`matches`rule.check_type`x`<rule.param >`type per the dispatch table
-
[14]
confirm"`, the instruction is an ordinary user request (
Ref attributes hold only neutral facts (numbers, categories, identity, time, participants) -- no value- judgments, recommendations, or actionability hints. ### Confirm rule special constraint If`rule.check_type == "confirm"`, the instruction is an ordinary user request ("help me schedule X" / "handle it ") and must NOT contain any wording about a confirm ...
-
[15]
trace": [{
Any`*_id`/`*_ids`value in`gold_value`must be the id of an object in`references`. No fabricated ids. 2.`references[i].type`must be a primary type listed in REF_SCHEMA (the`type:`headers -- not the`derived:` sections). --- ## Inputs 26 ### Rule ```json {{RULE_JSON}} ``` ### Domain =`{{DOMAIN}}`available tools ```json {{DOMAIN_TOOLS}} ``` ### Domain`{{DOMAIN...
-
[16]
Order them in natural temporal order ( earliest first); the caller stamps`day_offset`from the index
**A daily-interaction trail.** The {{N}} entries together form a stretch of this persona's interactions with the agent. Order them in natural temporal order ( earliest first); the caller stamps`day_offset`from the index. Adjacent entries may carry causal or topic continuity (booked weekend gathering -> drafted thank-you note; planned business trip -> book...
-
[17]
**Domain distribution follows the persona's actual life.** You are not required to cover all 6 domains. Read the persona's occupation, lifestyle, and social_context: an art enthusiast may have lots of commerce; a commuter office worker may lean on communication / scheduling; a homemaker may use reservation more. Irrelevant domains can be entirely absent -...
-
[18]
Triage my work inbox before today's 9am steering check-in
**Bake situational variety into theme text.** Since you emit one sentence per session, vary time-of-day, day- of-week, location, and mood through wording. Mix early- morning errands, weekend evenings, rushed weekday afternoons, in-flight downtime, and quiet at-home moments . Example. "Triage my work inbox before today's 9am steering check-in."
-
[19]
search restaurant + book restaurant
**Theme-implied tool coverage.** Each theme implicitly invokes downstream tools. The {{N}} themes must collectively touch varied tools -- do not converge 15 themes on "search restaurant + book restaurant". Use the capability table below as a sanity-check; do not propose asks no domain supports ("redecorate my living room")
-
[20]
Track the bird-seed order I placed for the cardinals
**Result-object reachability (commerce / travel / reservation).** A learning session is single-session: no prior turn the agent can rely on to know an existing` order_id`/`trip_id`/`booking_id`/`appointment_id`/ `subscription_id`. The current tool set has no` search_orders`/`search_trips`/`search_bookings`/` search_appointments`, so for these three domain...
-
[21]
A value in`task_params`(verbatim)
-
[22]
An id from`local_env.references[*].id`
-
[23]
A placeholder`<authored from <field>[, <field >...]>`for long-text drafting args (every referenced `<field>`must exist in`task_params`)
-
[24]
A runtime auto-injected identity field, OMITTED from arguments (env auto-fills)
-
[25]
folder in {inbox, sent, drafts}`(omitting returns all non-archived messages);`list_events.calendar`( omitting returns all calendars)
A recoverable broad-list default for narrowing filters the agent could safely omit:`search_messages. folder in {inbox, sent, drafts}`(omitting returns all non-archived messages);`list_events.calendar`( omitting returns all calendars). NOT recoverable:` search_messages.folder = "archive"`(archived messages are hidden by default -- this must come from task_params)
-
[26]
<authored from reply_points>
An agent-side control flag (`sort_by`,`limit`,` language`defaults, output-shaping booleans,`field`/ `update_action`selectors). These are how the agent 30 invokes the tool, not user-side facts, and need not appear in task_params. - Anything else (a`doc_type`,`cuisine`,`location`,` sender`,`priority`,`title`,`start_time`,` participants`invented only in`gold...
-
[27]
standing rule
{tool_name}({arguments}) ... --- messages --- {prior conversation, with agent messages as user-role messages and user-simulator replies as assistant-role messages} --- user --- {agent_text} --- optional user message on Router-positive turns --- {rule_answer_hook} I.5 Router and Classifier Prompts The placeholder {{FEW_SHOT_EXAMPLES}} is replaced by the ac...
-
[28]
**Trigger covers**: the rule's trigger context covers the situation the question describes
-
[29]
specific instance
**Behavior answers**: the rule's preferred behavior directly answers the action, value, or choice the question proposes. If either condition is weak or unclear, return`null`. The question's wording does not need to match the rule's word-for-word. But the rule's content, applied as the user's answer, must resolve what the question is asking -- not merely l...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.