From Knowing to Doing: A Memory-Controlled Benchmark for LLM Trading Agents on Stock Markets
Pith reviewed 2026-06-29 12:26 UTC · model grok-4.3
The pith
A leakage-controlled benchmark shows LLM trading agents derive most returns from market and style exposure rather than stock-selection skill.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the KTD-Fin protocol, which applies consistent data-side masking to remove identifiable market history, LLM agents' cumulative returns on the CSI300 are largely explained by passive market beta and style exposure; evidence of persistent stock-selection alpha remains limited even after agents adapt their rationales to anonymized inputs.
What carries the argument
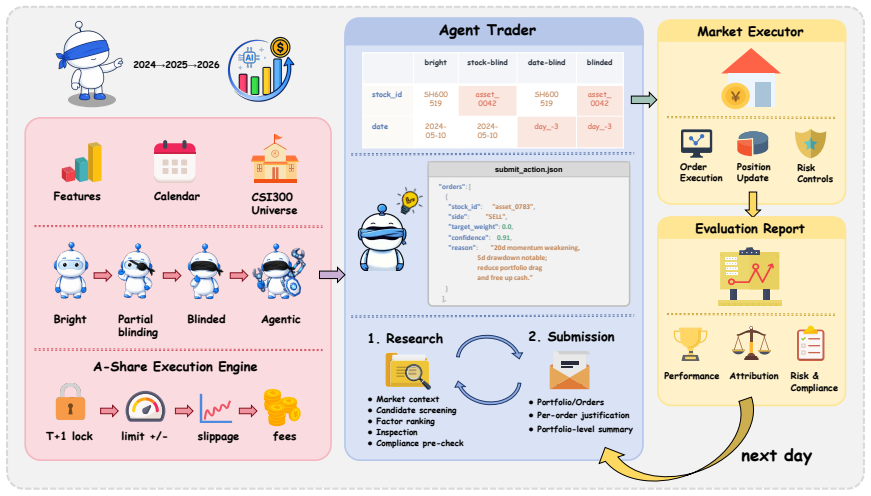
KTD-Fin benchmark, built around a data-side masking protocol that anonymizes identifiers and calendar information across all prompts and tools, paired with a Barra-style attribution model that decomposes returns into market, style, and stock-selection alpha components.
If this is right
- Masking changes agent rationales from ticker-specific narratives to anonymized factor reasoning.
- Cumulative returns under controlled conditions trace mainly to market and style factors rather than alpha.
- Benchmarks should report the source of returns, not only total profit, to assess transferable skill.
- Evaluation windows that overlap LLM knowledge cutoffs require explicit leakage controls to remain informative.
Where Pith is reading between the lines
- Similar masking could be applied to other agent benchmarks where memorized facts substitute for reasoning.
- Agents might need new internal mechanisms to maintain performance once external identifiers are stripped.
- Style and market exposures could themselves be tested for persistence across different anonymized regimes.
Load-bearing premise
The masking protocol removes enough historical identifiers and timing cues that agents must reason without relying on memorized market facts.
What would settle it
An experiment in which the same agents, run on the identical 2024-2026 window but with identifiers and dates unmasked, produce materially higher and more persistent stock-selection alpha that vanishes only when masking is restored.
Figures

read the original abstract
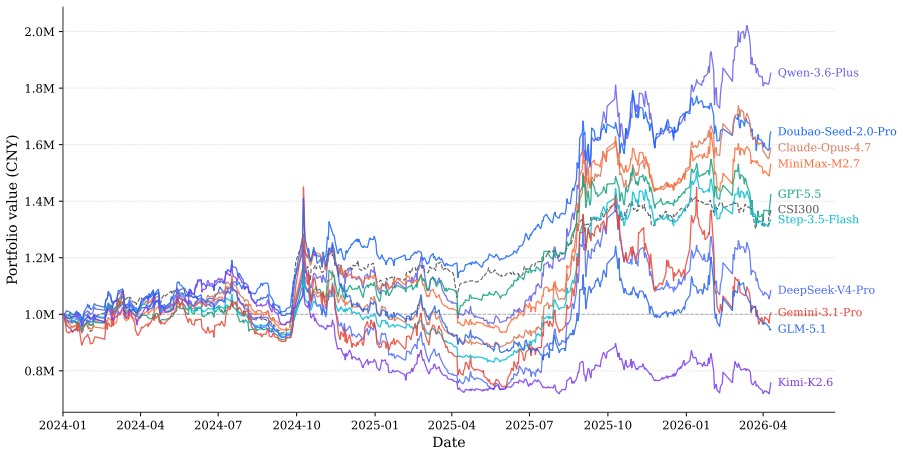
Evaluating whether large language model (LLM) agents can profit in capital markets is increasingly framed as end-to-end trading: place an agent in a historical market, let it trade, and measure portfolio returns. This setup is vulnerable to two evaluation failures. First, long backtests often overlap with the knowledge cutoffs of frontier LLMs, allowing memorized tickers, dates, prices, and market narratives to substitute for investment reasoning. Second, raw returns are a noisy proxy for stock-selection ability, since positive performance may come from market beta, style exposure, or favorable regimes rather than genuine alpha. We introduce KTD-Fin (Knowing-To-Doing Financial Benchmark), an end-to-end stock-market trading benchmark that addresses both issues. KTD-Fin uses a data-side masking protocol to anonymize key identifiers and calendar information consistently across prompts and tools, separating historical market memory from investment decision-making. It also incorporates a Barra-style performance attribution framework that decomposes portfolio returns into market, style, and stock-selection alpha components. Across ten frontier LLM agents evaluated on the Chinese CSI300 over a 2024--2026 window, masking substantially changes agent rationales, pushing them towards anonymized factor-based reasoning. Attribution analysis further shows that LLM agents' cumulative returns under leakage-controlled evaluation are largely explained by passive market and style exposure, with limited evidence of persistent stock-selection alpha. These findings suggest that financial LLM benchmarks should evaluate not only whether an agent makes money, but also whether the source of returns reflects transferable investment skill. We release KTD-Fin as a reproducible template for leakage-controlled and attribution-aware evaluation of LLM trading agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KTD-Fin, an end-to-end benchmark for LLM trading agents that applies a data-side masking protocol to anonymize tickers, dates, and calendar information across prompts and tools, thereby aiming to isolate investment reasoning from memorized market knowledge. It further incorporates a Barra-style attribution framework to decompose cumulative returns into market beta, style factors, and stock-selection alpha. On ten frontier LLMs evaluated over the CSI300 index from 2024–2026, the authors report that masking alters agent rationales toward anonymized factor-based reasoning and that observed returns are largely attributable to passive exposures rather than persistent alpha.
Significance. If the masking protocol proves complete and the attribution decomposition is robust, the work would be significant for shifting financial LLM evaluation from raw profitability to leakage-controlled, skill-isolated metrics. It supplies a reproducible template and highlights that apparent trading gains may reflect exposure rather than transferable reasoning. The release of the benchmark as an open template is a concrete strength.
major comments (2)
- [masking protocol description (abstract and methods)] The central claim that masking separates historical memory from decision-making (and thereby produces attribution results showing limited stock-selection alpha) rests on the assumption that anonymization is complete and uniform. The manuscript provides no verification—such as example tool outputs before/after masking, checks for residual calendar cues in multi-turn contexts, or ablation on partial masking—that would confirm the protocol prevents inference of original CSI300 identifiers or dates.
- [attribution framework and results] The attribution analysis concludes that returns are largely explained by market and style exposure. However, the manuscript does not report the exact Barra factor model specification (e.g., which style factors are included), the regression window, or robustness checks against alternative factor sets or regime splits; without these, it is unclear whether the “limited alpha” result is sensitive to modeling choices.
minor comments (2)
- [evaluation setup] The abstract states the evaluation window as 2024–2026; clarify whether this is a forward-looking or simulated period and how out-of-sample status is maintained relative to each model’s knowledge cutoff.
- [performance attribution] Notation for the decomposed return components (market, style, alpha) should be defined explicitly with equations in the attribution section to avoid ambiguity when comparing across agents.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of the masking protocol and attribution framework. We address each point below and will incorporate the suggested details in the revised manuscript.
read point-by-point responses
-
Referee: [masking protocol description (abstract and methods)] The central claim that masking separates historical memory from decision-making rests on the assumption that anonymization is complete and uniform. The manuscript provides no verification—such as example tool outputs before/after masking, checks for residual calendar cues in multi-turn contexts, or ablation on partial masking—that would confirm the protocol prevents inference of original CSI300 identifiers or dates.
Authors: We agree that explicit verification strengthens the central claim. The revised manuscript will include (i) side-by-side examples of tool outputs and prompts before and after masking, (ii) explicit checks for residual calendar or identifier cues across multi-turn dialogues, and (iii) an ablation comparing full versus partial masking to quantify leakage risk. These additions will be placed in the Methods section. revision: yes
-
Referee: [attribution framework and results] The attribution analysis concludes that returns are largely explained by market and style exposure. However, the manuscript does not report the exact Barra factor model specification (e.g., which style factors are included), the regression window, or robustness checks against alternative factor sets or regime splits.
Authors: We acknowledge the need for full transparency on the attribution model. The revision will specify the exact Barra-style factors employed, the regression window and estimation procedure, and will add robustness tables using alternative factor sets and regime splits (e.g., pre- and post-2025). These details will confirm that the limited stock-selection alpha result is not sensitive to modeling choices. revision: yes
Circularity Check
No significant circularity; evaluation protocol with independent empirical content
full rationale
The paper proposes KTD-Fin, a benchmark using a data-side masking protocol and Barra-style attribution to evaluate LLM trading agents. No equations, fitted parameters, or derivations are present that reduce results to inputs by construction. Masking is a methodological choice whose effectiveness is an external assumption, not self-defined. Attribution decomposes returns using a standard external framework. Results (changed rationales, limited alpha) are empirical observations under the protocol, not forced by self-citation chains or renaming. Self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
CLQT: A Closed-Loop, Cost-Aware, Strategy-Consistent Benchmark for Diagnostic Evaluation of LLM Portfolio-Management Agents
CLQT is a new closed-loop, cost-aware benchmark that diagnoses LLM trading agent capabilities through strategy-consistent metrics and hash-verifiable trails rather than outcome rankings.
Reference graph
Works this paper leans on
-
[1]
FinanceBench: A New Benchmark for Financial Question Answering
Financebench: A new benchmark for financial question answering.Preprint, arXiv:2311.11944. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica. 2024. Live- CodeBench: Holistic and contamination free evalu- ation of large language models for code.Preprint, arXiv:2403.07974. Gu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
InAdvances in Neural Information Processing Systems 30 (NIPS)
LightGBM: A highly efficient gradient boost- ing decision tree. InAdvances in Neural Information Processing Systems 30 (NIPS). Changlun Li, Yao Shi, Chen Wang, Lingling Zhao, Bo Zheng, Minyi Qin, Jiayi Sun, Wentao Zhang, Xiang Liu, and Tie-Yan Liu. 2025. Time travel is cheating: Going live with deepfund for real- time fund investment benchmarking.Preprint...
-
[3]
AgentBench: Evaluating LLMs as agents. In International Conference on Learning Representa- tions (ICLR). Xiao-Yang Liu, Ziyi Xia, Jingyang Rui, Jiechao Gao, Hongyang Yang, Ming Zhu, Christina Dan Wang, Zhaoran Wang, and Jian Guo. 2022. FinRL-Meta: Market environments and benchmarks for data-driven financial reinforcement learning. InAdvances in Neural Inf...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
FinRobot: An open-source AI agent platform for financial applications using large language mod- els.Preprint, arXiv:2405.14767. Xiao Yang, Weiqing Liu, Dong Zhou, Jiang Bian, and Tie-Yan Liu. 2020. Qlib: An ai-oriented quantitative investment platform. InProceedings of the First ACM International Conference on AI in Finance. Shunyu Yao, Noah Shinn, Pedram...
-
[5]
Long-only; no shorting
-
[6]
Only stocks in today's tradable universe may be operated on
-
[7]
A-share T+1: a stock bought today can only be sold the next day
-
[8]
Each order must contain`stock_id`,`side`,`confidence`, and `reason`, with`reason`of at least 10 characters
-
[9]
## Autonomous decision space - Neither concentration nor the number of holdings has a hard upper bound; you may concentrate heavily (e.g., 1-3 names) or diversify broadly
If no action is intended, return an empty`orders`list. ## Autonomous decision space - Neither concentration nor the number of holdings has a hard upper bound; you may concentrate heavily (e.g., 1-3 names) or diversify broadly. Weigh win rate, risk budget, and candidate quality on your own. - State your portfolio-construction rationale in`overall_reason`. ...
-
[10]
tool_callget_market_context()
-
[11]
tool_result{as_of_date: day_+0, data_cutoff: day_-3, contains_current_day_market_data: false, market: csi300, universe_size: 300, ...}
-
[12]
tool_callscreen_candidates(sort_by=ret_20d, top_k=15)
-
[13]
tool_result{as_of_date: day_+0, data_cutoff: day_-3, candidates: [ {stock_id:asset_0001, prev_close: 3.034, ret_1d: 0.0185, ret_5d: 0.1123, ret_20d: 0.3355, vol_20d: 0.0302, drawdown_20d:−0.055, rank: 1}, {stock_id:asset_0002, prev_close: 0.567, ret_1d: 0.0996, ret_5d: 0.2213, ret_20d: 0.3104, vol_20d: 0.0272, drawdown_20d:−0.045, rank: 2}, ...}
-
[14]
20-day return ranks #1 (+33.6%); short-term momentum strong; core allocation
tool_callrisk_check(draft_orders=[ {stock_id:asset_0001, side: BUY, target_weight: 0.10, confidence: 0.85, reason: “20-day return ranks #1 (+33.6%); short-term momentum strong; core allocation”}, {stock_id:asset_0002, side: BUY, target_weight: 0.10, confidence: 0.82, reason: “1-day +9.96% and 5-day +22.1% both rank #1; explosive short-term strength”}, ...])
-
[15]
”}, {stock_id:asset_0002, side: BUY, target_weight: 0.10, confidence: 0.82, reason: “
tool_result{valid: true, violations: [], projected_weights: {asset_0001: 0.10, asset_0002: 0.10, ...}} [final] submit_action{orders: [ {stock_id:asset_0001, side: BUY, target_weight: 0.10, confidence: 0.85, reason: “...”}, {stock_id:asset_0002, side: BUY, target_weight: 0.10, confidence: 0.82, reason: “...”}, ...], overall_reason: “High-momentum, low-vola...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.