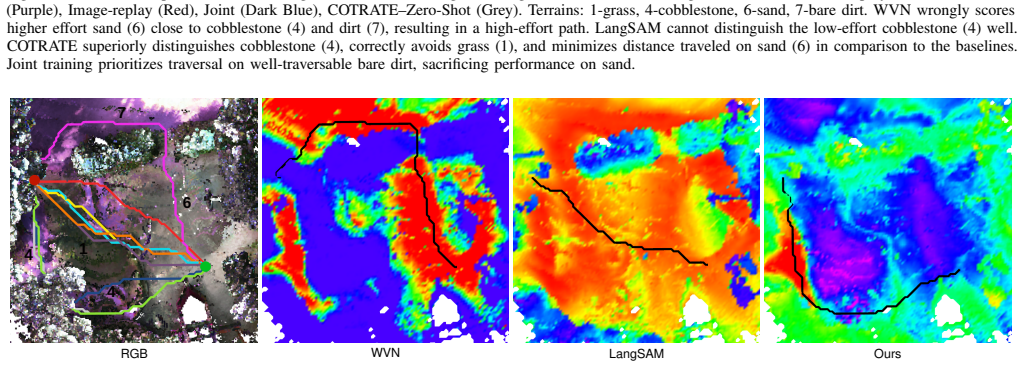
Self-Supervised Online Robot-Agnostic Traversability Estimation for Open-World Environments
Pith reviewed 2026-06-29 12:12 UTC · model grok-4.3
The pith
COTRATE infers traversability scores from proprioceptive signals to supervise visual networks online without labels or prior clustering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
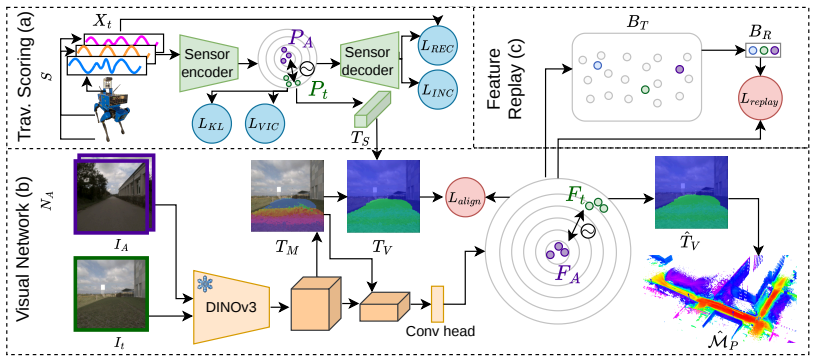
COTRATE performs continuous online traversability estimation by first computing robust traversability scores with a learning-based, robot-agnostic module on proprioceptive and inertial signals, then using those scores to supervise a visual traversability network via a novel alignment loss; a diversity-aware feature selection strategy maintains performance with low-overhead replay memory, and the resulting representation transfers across platforms with differing kinematics.
What carries the argument
Alignment loss that associates visual embeddings with online terrain assessments generated by the proprioceptive module, together with diversity-aware feature selection for replay.
If this is right
- Robots can update traversability estimates continuously from their own unlabeled experience.
- The learned visual representation transfers to robots with different locomotion kinematics.
- Continual learning occurs with only compact replay memory and low compute overhead.
- Navigation performance improves in new outdoor environments without manual labeling or offline clustering.
- Multimodal signals enable robot-agnostic operation across platforms.
Where Pith is reading between the lines
- The same proprioceptive-to-visual supervision pattern could be applied to other perception tasks such as object affordance or surface friction estimation.
- Sharing the compact replay buffer across a fleet might allow collective adaptation without exchanging raw data.
- The method implicitly assumes that terrain properties stable enough to be captured by proprioception are also visible in images; violating that link on highly dynamic surfaces would break the supervision chain.
Load-bearing premise
Proprioceptive and inertial signals can be turned into reliable traversability scores that serve as effective supervision for visual embeddings without any labeled data.
What would settle it
A controlled test in which a visual network trained solely by COTRATE scores performs no better than a randomly initialized or handcrafted baseline at predicting safe versus unsafe paths on previously unseen terrain.
Figures



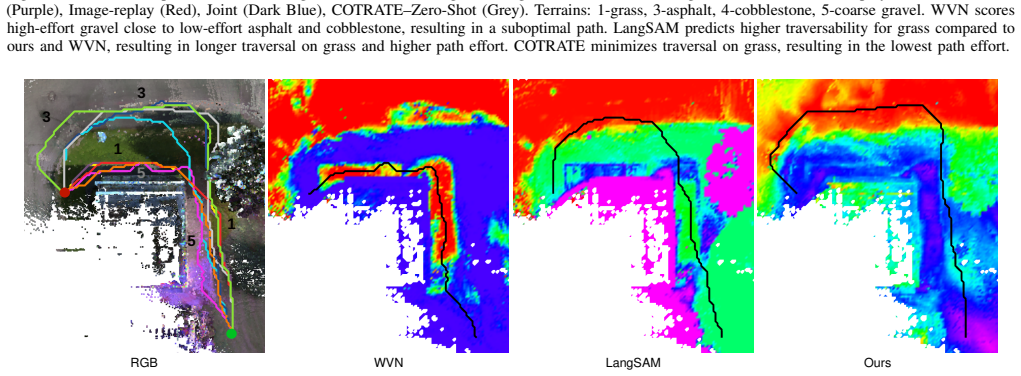
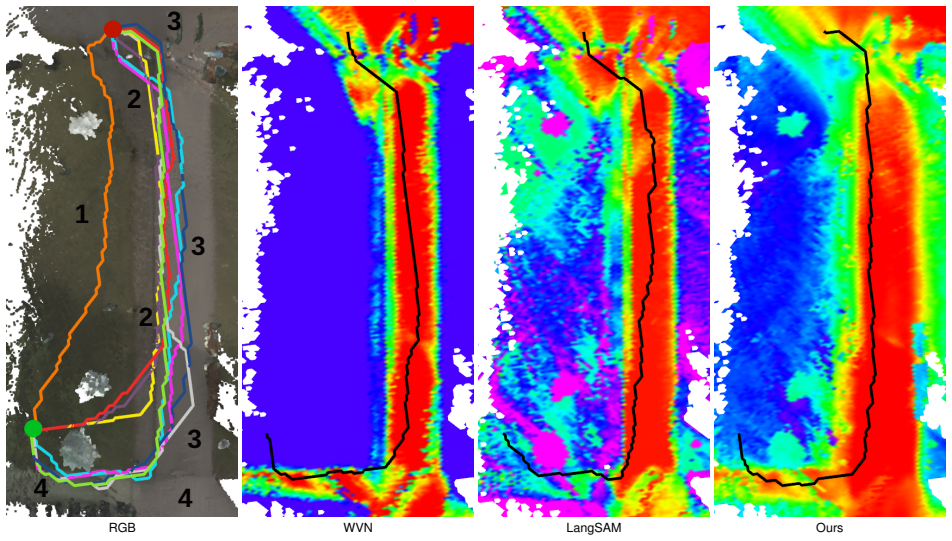
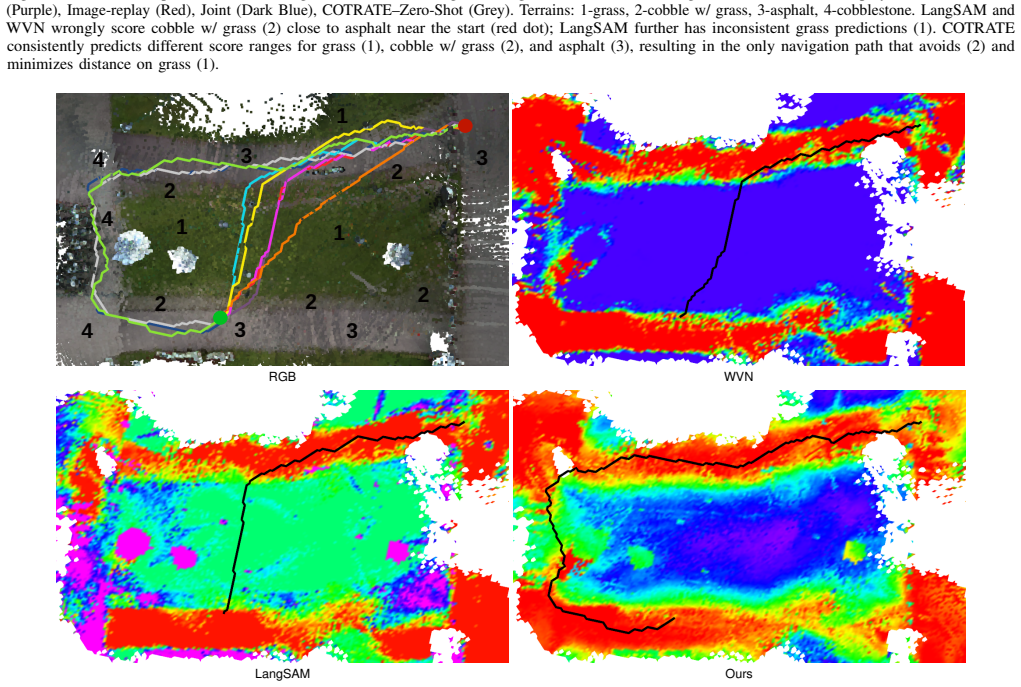
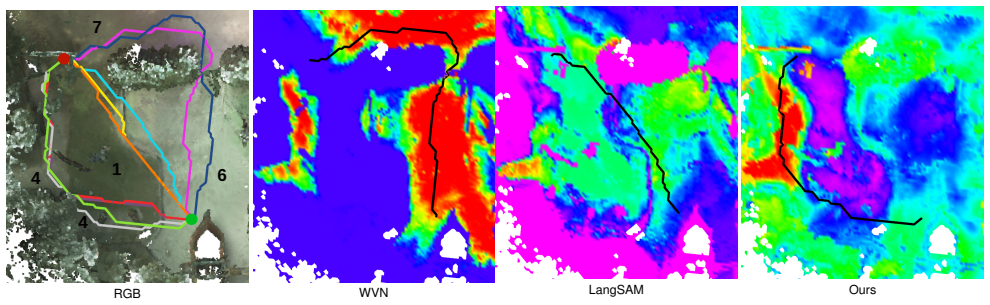
read the original abstract
Self-supervised online traversability estimation enables robots to continuously learn from unlabeled open-world experiences and adapt their navigation behavior toward safe and efficient trajectories. Existing approaches either rely on handcrafted proprioceptive traversability scores, limiting robot-agnosticism, or cluster prior data, preventing online learning. Moreover, many continual learning methods incur substantial memory and computational costs, hindering onboard deployment. We introduce COTRATE, an online learning framework for continuous traversability estimation from multimodal, unlabeled robot experience. Our method first infers robust traversability scores using a robot-agnostic, learning-based online terrain assessment module operating on proprioceptiveand inertial signals. These scores then supervise a visual traversability network through a novel alignment loss that associates visual embeddings with online terrain assessments. To mitigate forgetting during continual learning with minimal overhead, we propose a diversity-aware feature selection strategythat preserves performance using a compact replay memory. We further show that the learned traversability representation supports knowledge transfer across different robot platforms with different locomotion kinematics. We evaluate COTRATE on a dataset of $\approx$ 50,000 images collected with two robotic platforms across 11 outdoor terrains, and benchmark it on navigation tasks in three representative outdoor environments. We make the dataset, code, and trained models publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
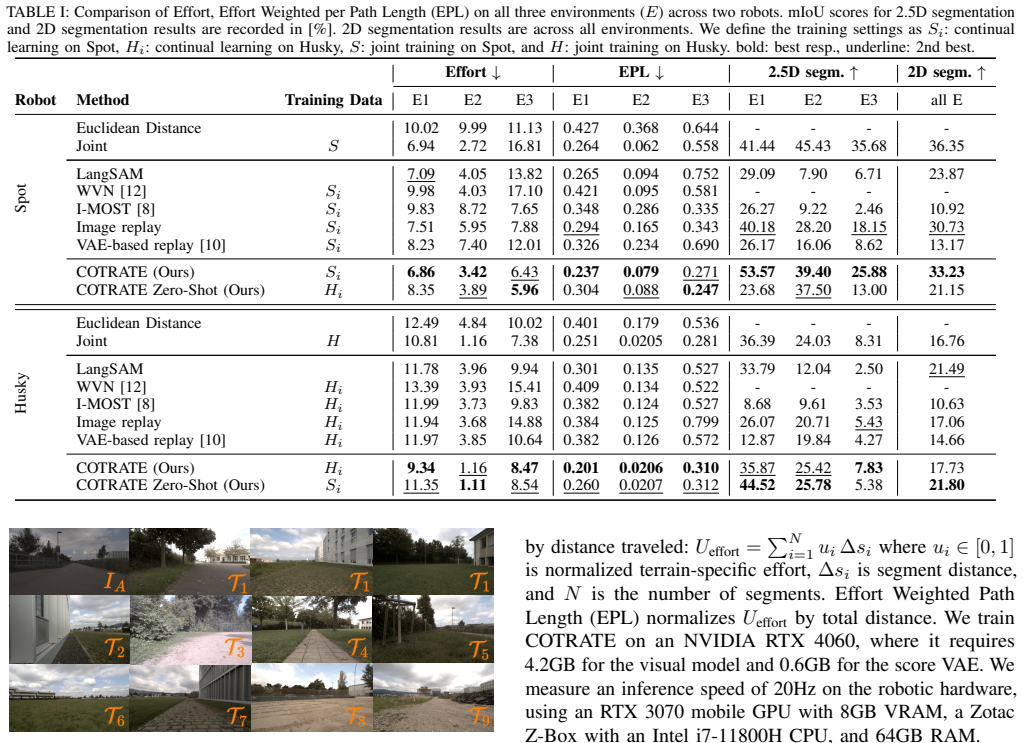
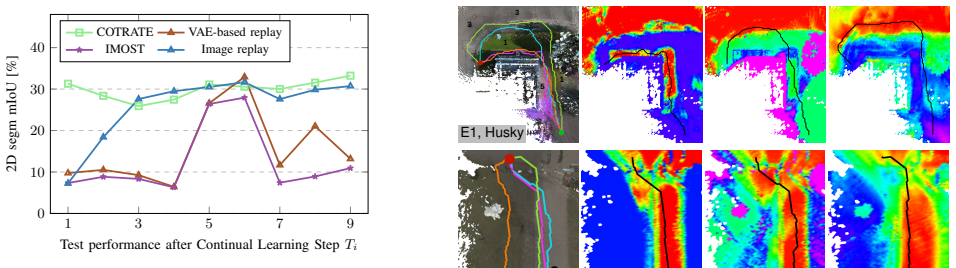
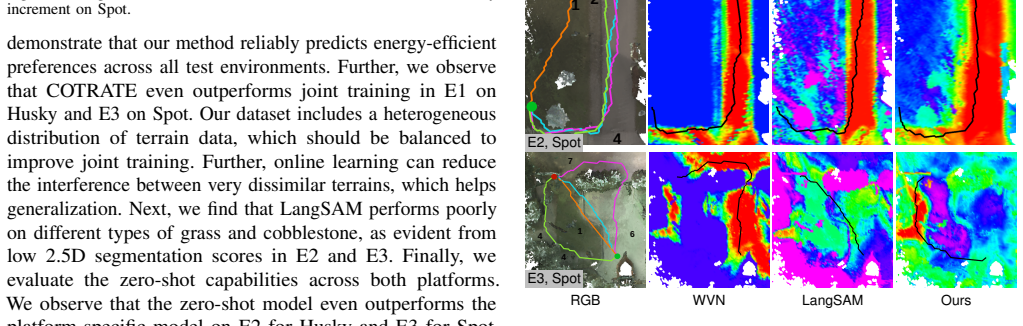
Summary. The manuscript presents COTRATE, a framework for self-supervised online robot-agnostic traversability estimation from unlabeled multimodal robot experience. It first uses a learning-based proprioceptive module on proprioceptive and inertial signals to infer traversability scores; these scores supervise a visual traversability network via a novel alignment loss. A diversity-aware feature selection strategy with compact replay memory supports low-overhead continual learning, and the learned representation enables cross-platform transfer. Evaluation is reported on a dataset of approximately 50,000 images collected with two robotic platforms across 11 outdoor terrains, plus navigation benchmarks in three environments; the dataset, code, and models are released publicly.
Significance. If the central claims hold, the work would advance self-supervised robotics by enabling continuous, label-free adaptation in open-world settings while avoiding handcrafted heuristics and offline clustering. The robot-agnostic proprioceptive supervision, alignment loss, and diversity-aware replay address practical deployment constraints, and the cross-platform transfer result is potentially impactful. Public release of the dataset, code, and models is a clear strength for reproducibility and follow-on work.
major comments (2)
- [Abstract] Abstract: the proprioceptive module is described as 'learning-based' and able to 'infer robust traversability scores' that serve as direct supervision for the visual network, yet no training objective, loss function, architecture details, or validation procedure are provided. This is load-bearing for the self-supervised pipeline, because the visual network's performance is entirely downstream of these scores and the claim of avoiding handcrafted heuristics cannot be assessed without them.
- [Abstract] Abstract: the evaluation is stated to cover ≈50,000 images and navigation benchmarks in three environments, but the available text supplies no quantitative metrics, error bars, ablation results, or baseline comparisons. Without these, the performance claims and the contribution of the alignment loss and diversity-aware selection cannot be verified.
minor comments (1)
- [Abstract] Abstract: 'proprioceptiveand' is missing a space.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance and reproducibility. We address the two major comments on the abstract below. Both points are valid regarding the level of detail in the abstract, and we will revise it accordingly while ensuring the body of the paper already contains the supporting details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the proprioceptive module is described as 'learning-based' and able to 'infer robust traversability scores' that serve as direct supervision for the visual network, yet no training objective, loss function, architecture details, or validation procedure are provided. This is load-bearing for the self-supervised pipeline, because the visual network's performance is entirely downstream of these scores and the claim of avoiding handcrafted heuristics cannot be assessed without them.
Authors: We agree the abstract is concise and omits these specifics. The full manuscript details the proprioceptive module's CNN-LSTM architecture in Section III-A, its training as a regression task on synchronized proprioceptive/inertial signals with an MSE loss in Section III-B, and validation via cross-terrain hold-out experiments in Section IV-A (showing correlation with human-labeled traversability). This establishes the learning-based, heuristic-free supervision. To improve clarity, we will expand the abstract with a brief clause on the module's learning objective and validation. revision: yes
-
Referee: [Abstract] Abstract: the evaluation is stated to cover ≈50,000 images and navigation benchmarks in three environments, but the available text supplies no quantitative metrics, error bars, ablation results, or baseline comparisons. Without these, the performance claims and the contribution of the alignment loss and diversity-aware selection cannot be verified.
Authors: We agree the abstract lacks specific numbers. The manuscript reports quantitative results in Section IV, including mean absolute error for traversability estimation (with standard deviation across 5 runs), navigation success rates in the three environments, and ablations isolating the alignment loss and diversity-aware replay (Tables II-IV). We will revise the abstract to include 1-2 key metrics (e.g., estimation accuracy and navigation improvement) and note the ablations to substantiate the claims. revision: yes
Circularity Check
No circularity: proprioceptive inference and alignment loss form independent supervision chain
full rationale
The paper's core pipeline infers traversability scores from a separate robot-agnostic proprioceptive/inertial module and then applies an alignment loss to supervise the visual network. No quoted equations or steps reduce a claimed prediction back to its own fitted inputs by construction, nor does any load-bearing premise collapse to a self-citation whose content is unverified. The continual-learning component (diversity-aware feature selection) is presented as an engineering addition rather than a renaming or self-referential fit. The derivation therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proprioceptive and inertial signals provide sufficient information to infer robust traversability scores without labels
Reference graph
Works this paper leans on
-
[1]
INoD: Injected Noise Discriminator for Self-Supervised Representation Learning in Agricultural Fields,
J. Hindel, N. Gosala, K. Bregler, and A. Valada, “INoD: Injected Noise Discriminator for Self-Supervised Representation Learning in Agricultural Fields,”IEEE Rob. and Auto. Let., 2023
2023
-
[2]
Towards robust semantic segmentation using deep fusion,
A. Valada, G. Oliveira, T. Brox, and W. Burgard, “Towards robust semantic segmentation using deep fusion,” inRSS workshop: are the sceptics right? Limits and potentials of deep learning in robotics, 2016
2016
-
[3]
Evora: Deep evidential traversability learning for risk-aware off-road autonomy,
X. Cai, S. Ancha, L. Sharmaet al., “Evora: Deep evidential traversability learning for risk-aware off-road autonomy,”IEEE Trans. on Rob., 2024
2024
-
[4]
M. Endo, T. Taniai, and G. Ishigami, “Deep Probabilistic Traversability with Test-time Adaptation for Uncertainty-aware Planetary Rover Navigation,”arXiv preprint arXiv:2409.00641, 2024
-
[5]
How Does It Feel? Self-Supervised Costmap Learning for Off-Road Vehicle Traversability,
M. G. Castro, S. Triest, W. Wang, J. M. Gregory, F. Sanchez, J. G. Rogers, and S. Scherer, “How Does It Feel? Self-Supervised Costmap Learning for Off-Road Vehicle Traversability,” inProc. IEEE Int. Conf. on Rob. and Auto., 2023, pp. 931–938
2023
-
[6]
STERLING: Self-Supervised Terrain Representation Learning from Unconstrained Robot Experience,
H. Karnan, E. Yang, D. Farkash, G. Warnell, J. Biswas, and P. Stone, “STERLING: Self-Supervised Terrain Representation Learning from Unconstrained Robot Experience,” inProc. Conf. on Rob. Learn., 2023
2023
-
[7]
Taxonomy-aware continual semantic segmentation in hyperbolic spaces for open-world perception,
J. Hindel, D. Cattaneo, and A. Valada, “Taxonomy-aware continual semantic segmentation in hyperbolic spaces for open-world perception,” IEEE Rob. and Auto. Let., vol. 10, no. 2, pp. 1904–1911, 2025
1904
-
[8]
IMOST: Incremental Memory Mechanism with Online Self-Supervision for Continual Traversability Learning,
K. Ma, Z. Sun, C. Xiong, Q. Zhu, K. Wang, and L. Pei, “IMOST: Incremental Memory Mechanism with Online Self-Supervision for Continual Traversability Learning,” inProc. IEEE Int. Conf. on Rob. and Auto., 2025, pp. 8788–87 949
2025
-
[9]
Adaptive robot traversability estimation based on self-supervised online continual learning in unstructured environments,
H.-S. Yoon, J.-H. Hwang, C. Kim, E. I. Son, S.-W. Yoo, and S.-W. Seo, “Adaptive robot traversability estimation based on self-supervised online continual learning in unstructured environments,”IEEE Rob. and Auto. Let., vol. 9, no. 6, pp. 4902–4909, 2024
2024
-
[10]
Continual Learning for Traversability Prediction With Uncertainty-Aware Adaptation,
H. Lee, Y . Lee, D. A. Duecker, and C. Kwon, “Continual Learning for Traversability Prediction With Uncertainty-Aware Adaptation,”IEEE Rob. and Auto. Let., vol. 10, no. 11, pp. 12 109–12 116, 2025
2025
-
[11]
Learning Self-Supervised Traversability With Navigation Experiences of Mobile Robots: A Risk-Aware Self-Training Approach,
I. Cho and W. Chung, “Learning Self-Supervised Traversability With Navigation Experiences of Mobile Robots: A Risk-Aware Self-Training Approach,”IEEE Rob. and Auto. Let., 2024
2024
-
[12]
Fast traversability estimation for wild visual navigation,
J. Frey, M. Mattamala, N. Chebrolu, C. Cadena, M. Fallon, and M. Hutter, “Fast traversability estimation for wild visual navigation,” in Proc. Rob.: Sci. and Syst., 2023
2023
-
[13]
V-STRONG: Visual Self-Supervised Traversability Learning for Off-road Navigation,
S. Jung, J. Lee, X. Meng, B. Boots, and A. Lambert, “V-STRONG: Visual Self-Supervised Traversability Learning for Off-road Navigation,” inProc. IEEE Int. Conf. on Rob. and Auto., 2024, pp. 1766–1773
2024
-
[14]
BADGR: An Autonomous Self- Supervised Learning-Based Navigation System,
G. Kahn, P. Abbeel, and S. Levine, “BADGR: An Autonomous Self- Supervised Learning-Based Navigation System,”IEEE Rob. and Auto. Let., vol. 6, no. 2, pp. 1312–1319, 2021
2021
-
[15]
Self-Supervised Visual Terrain Classification From Unsupervised Acoustic Feature Learning,
J. Zurn, W. Burgard, and A. Valada, “Self-Supervised Visual Terrain Classification From Unsupervised Acoustic Feature Learning,”IEEE Trans. on Rob., vol. 37, pp. 466–481, 2019
2019
-
[16]
WayFAST: Navigation With Predictive Traversability in the Field,
M. V . Gasparino, A. N. Sivakumar, Y . Liu, A. E. B. Velasquez, V . A. H. Higuti, J. Rogers, H. Tran, and G. Chowdhary, “WayFAST: Navigation With Predictive Traversability in the Field,”IEEE Rob. and Auto. Let., vol. 7, no. 4, pp. 10 651–10 658, 2022
2022
-
[17]
Wayfaster: a self-supervised traversability prediction for increased navigation awareness,
M. V . Gasparino, A. N. Sivakumar, and G. Chowdhary, “Wayfaster: a self-supervised traversability prediction for increased navigation awareness,” inProc. IEEE Int. Conf. on Rob. and Auto., 2024
2024
-
[18]
A Survey on Terrain Traversability Analysis for Autonomous Ground Vehicles: Methods, Sensors, and Challenges
P. V . Borges, T. Peynot, S. Lianget al., “A Survey on Terrain Traversability Analysis for Autonomous Ground Vehicles: Methods, Sensors, and Challenges.”IEEE Trans. on Field Rob., 2022
2022
-
[19]
TerraPN: Unstructured Terrain Navigation using Online Self-Supervised Learning,
A. J. Sathyamoorthy, K. Weerakoon, T. Guan, J. Liang, and D. Manocha, “TerraPN: Unstructured Terrain Navigation using Online Self-Supervised Learning,” inProc. IEEE Int. Conf. on Intel. Rob. and Syst., 2022
2022
-
[20]
META Verse: Meta-Learning Traversability Cost Map for Off-Road Navigation,
J. Seo, T. Kim, S. Ahn, and K. Kwak, “META Verse: Meta-Learning Traversability Cost Map for Off-Road Navigation,” inProc. IEEE Int. Conf. on Intel. Rob. and Syst., 2024, pp. 13 190–13 197
2024
-
[21]
Salon: Self-supervised adaptive learning for off-road navigation,
M. Sivaprakasam, S. Triest, C. Ho, S. Aich, J. Lew, I. Adu, W. Wang, and S. Scherer, “SALON: Self-supervised Adaptive Learning for Off- road Navigation,”arXiv preprint arXiv:2412.07826, 2024
-
[22]
G. Seneviratne, K. Weerakoonet al., “CROSS-GAiT: Cross-Attention- Based Multimodal Representation Fusion for Parametric Gait Adaptation in Complex Terrains,”arXiv preprint arXiv:2409.17262, 2025
-
[23]
Amco: Adap- tive multimodal coupling of vision and proprioception for quadruped robot navigation in outdoor environments,
M. B. Elnoor, K. Weerakoon, A. J. Sathyamoorthyet al., “Amco: Adap- tive multimodal coupling of vision and proprioception for quadruped robot navigation in outdoor environments,”Proc. IEEE Int. Conf. on Intel. Rob. and Syst., pp. 7687–7694, 2024
2024
-
[24]
Pronav: Proprioceptive traversability estimation for legged robot navi- gation in outdoor environments,
M. Elnoor, A. J. Sathyamoorthy, K. Weerakoon, and D. Manocha, “Pronav: Proprioceptive traversability estimation for legged robot navi- gation in outdoor environments,”IEEE Rob. and Auto. Let., 2024
2024
-
[25]
Class-incremental learning: A survey,
D.-W. Zhou, Q.-W. Wang, Z.-H. Qi, H.-J. Ye, D.-C. Zhan, and Z. Liu, “Class-incremental learning: A survey,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, p. 9851–9873, 2024
2024
-
[26]
Fast-lio: A fast, robust lidar-inertial odometry package by tightly-coupled iterated kalman filter,
W. Xu and F. Zhang, “Fast-lio: A fast, robust lidar-inertial odometry package by tightly-coupled iterated kalman filter,”IEEE Rob. and Auto. Let., vol. 6, no. 2, pp. 3317–3324, 2021
2021
-
[27]
Universal Time-Series Representation Learning: A Survey
P. Trirat, Y . Shin, J. Kang, Y . Nam, J. Na, M. Bae, J. Kim, B. Kim, and J.-G. Lee, “Universal Time-Series Representation Learning: A Survey,” arXiv preprint arXiv:2401.03717, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Vicreg: Variance-invariance- covariance regularization for self-supervised learning,
A. Bardes, J. Ponce, and Y . LeCun, “Vicreg: Variance-invariance- covariance regularization for self-supervised learning,” inInt. Conf. Learn. Represent., 2022
2022
-
[29]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquabet al., “DINOv3,”arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
arXiv preprint arXiv:2306.12156 (2023)
X. Zhao, W. Ding, Y . An, Y . Du, T. Yu, M. Li, M. Tang, and J. Wang, “Fast Segment Anything,”arXiv preprint arXiv:2306.12156, 2023
-
[31]
Unsupervised Semantic Segmentation by Distilling Feature Correspon- dences,
M. Hamilton, Z. Zhang, B. Hariharan, N. Snavely, and W. T. Freeman, “Unsupervised Semantic Segmentation by Distilling Feature Correspon- dences,” inInt. Conf. Learn. Represent., 2022
2022
-
[32]
Real-time multi-modal semantic fusion on unmanned aerial vehicles,
S. Bultmann, J. Quenzel, and S. Behnke, “Real-time multi-modal semantic fusion on unmanned aerial vehicles,”Rob. and Autonomous Systems, vol. 159, p. 104286, 2023. Self-Supervised Online Robot-Agnostic Traversability Estimation for Open-World Environments - Supplementary Material - Julia Hindel, Simon Bultmann, Houman Masnavi, Daniele Cattaneo and Abhinav...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.