The Cases LJP Never Sees: Prosecution Decision Prediction for More Complete Criminal Liability Assessment
Pith reviewed 2026-06-29 12:24 UTC · model grok-4.3
The pith
State-of-the-art LLMs perform substantially worse on predicting prosecution decisions than on legal judgment prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
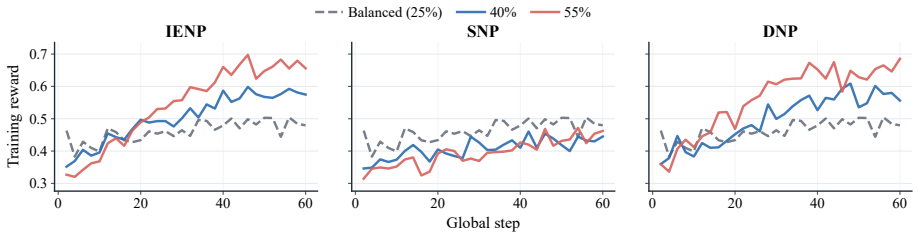
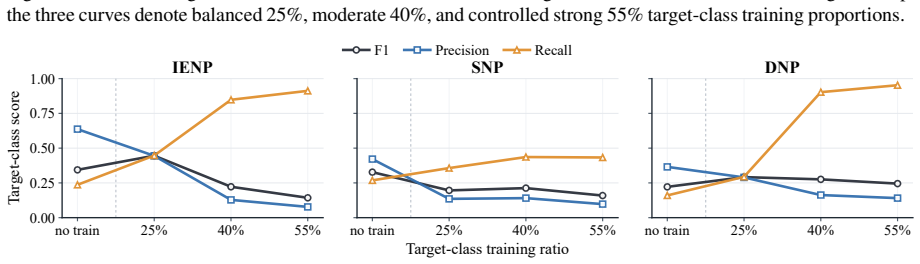
The central claim is that state-of-the-art LLMs perform substantially worse on PDP than on LJP and that mainstream enhancement routes fail to close the gap; controlled RLVR interventions further show that simple outcome rewards fail to produce generalizable PDP discrimination.
What carries the argument
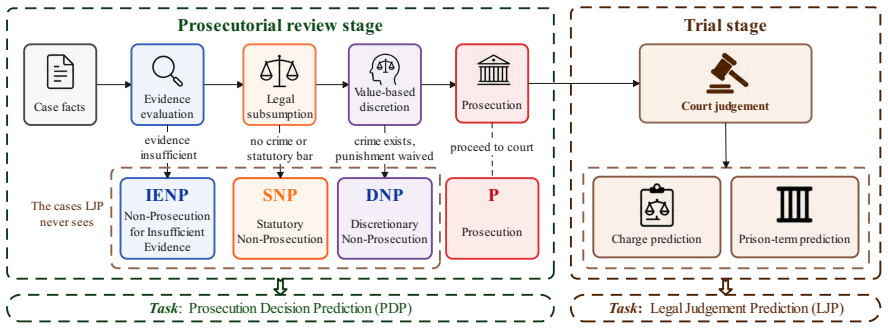
Prosecution Decision Prediction (PDP), a four-way classification task for prosecutorial review outcomes, evaluated via the PDP-Bench dataset of real decisions.
If this is right
- Legal AI evaluations require inclusion of pre-indictment cases to achieve complete criminal liability assessment.
- Current LLMs exhibit clear limitations in evidence evaluation, legal subsumption, and value-based discretion needed for prosecutorial review.
- Standard prompting, fine-tuning, and other mainstream enhancement methods do not sufficiently improve performance on PDP.
- Reinforcement learning using only simple outcome rewards does not produce generalizable discrimination for prosecution decisions.
Where Pith is reading between the lines
- PDP-style tasks could train models to better handle weak-evidence or discretionary cases across legal domains.
- Combining PDP and LJP into a single pipeline might yield more robust end-to-end legal AI systems.
- Similar benchmarks could be built for non-Chinese legal systems to test whether the observed limitations are jurisdiction-specific.
- The gap implies that training data must explicitly include negative prosecution examples to improve discretion modeling.
Load-bearing premise
The PDP-Bench cases accurately represent real-world prosecutorial decisions and that performance gaps reflect genuine limitations in AI evidence evaluation and discretion rather than dataset construction artifacts.
What would settle it
A controlled experiment in which LLMs reach comparable accuracy on PDP-Bench to their LJP performance after matching for case complexity or after improved dataset curation would falsify the performance gap claim.
Figures










read the original abstract
Legal Judgment Prediction (LJP) has become a core benchmark for evaluating AI in the criminal legal domain, but it only sees criminal cases that have already passed prosecutorial review and been formally indicted. As a result, LJP leaves a substantial blind spot in assessing criminal liability, overlooking cases involving insufficient evidence, no criminal liability, or guilt exempted from punishment. To fill this gap, we propose \textbf{Prosecution Decision Prediction (PDP)}, the first Legal AI task built around prosecutorial review, which classifies each case into prosecution or one of three non-prosecution decisions and reflects legal AI's capabilities in evidence evaluation, legal subsumption, and value-based discretion. We further construct \textbf{PDP-Bench}, a benchmark of 4{,}630 real Chinese prosecutorial decisions spanning 190 charges. Extensive experiments show that state-of-the-art LLMs perform substantially worse on PDP than on LJP and that mainstream enhancement routes fail to close the gap. Moreover, controlled RLVR interventions show that simple outcome rewards fail to produce generalizable PDP discrimination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that Legal Judgment Prediction (LJP) benchmarks are incomplete because they only cover cases that have already been indicted, missing the prosecutorial screening stage. It introduces Prosecution Decision Prediction (PDP) as a four-class classification task (prosecution vs. three non-prosecution outcomes) that requires evidence evaluation, legal subsumption, and discretionary judgment. The authors construct PDP-Bench, a dataset of 4,630 real Chinese prosecutorial decisions spanning 190 charges, and report that state-of-the-art LLMs perform substantially worse on PDP than on LJP; mainstream prompting, fine-tuning, and retrieval enhancements fail to close the gap, and controlled RLVR experiments show that simple outcome-based rewards do not yield generalizable discrimination.
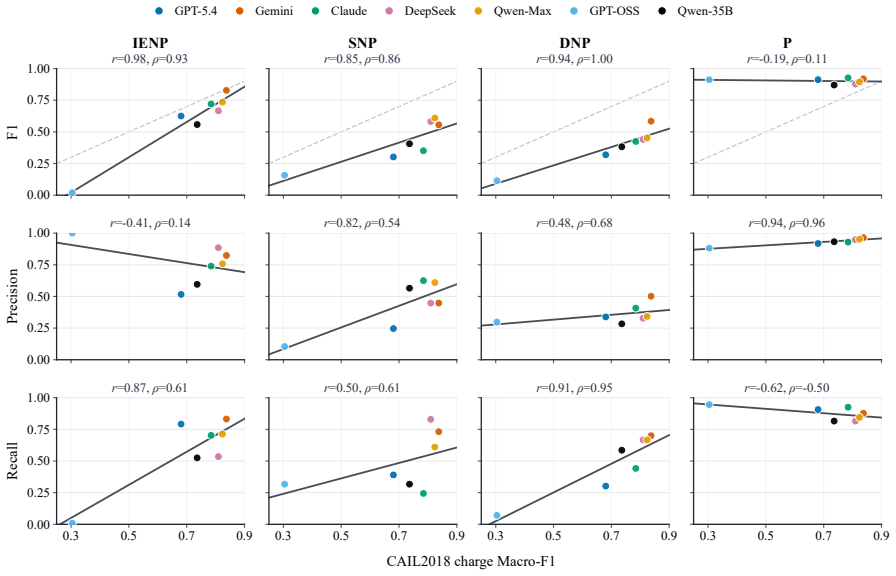
Significance. If the benchmark faithfully captures real prosecutorial decisions, the work identifies a previously unexamined blind spot in legal AI and supplies the first large-scale resource for evaluating models on the full criminal-liability pipeline. The negative results on enhancement methods and RLVR would indicate that current scaling and reward-design paradigms are insufficient for tasks that require nuanced evidence weighing and value-based discretion, which is a substantive contribution to the legal-AI literature.
major comments (3)
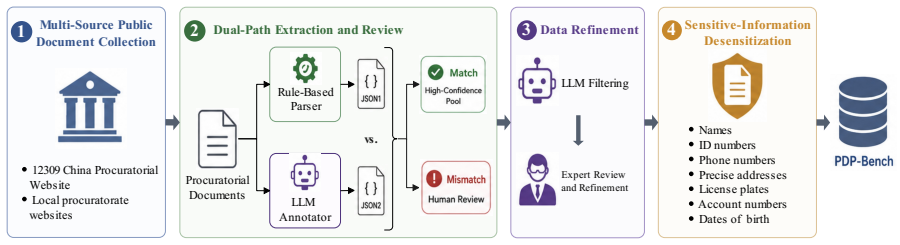
- [Abstract / PDP-Bench construction] Abstract and PDP-Bench construction section: the manuscript states that the 4,630 cases are “real Chinese prosecutorial decisions” but supplies no sampling frame, stratification by charge or decision type, provenance of the four-class labels, or independent re-annotation protocol. Because the headline claim (SOTA LLMs substantially worse on PDP than LJP, enhancements and RLVR fail) rests on the benchmark accurately instantiating the prosecution-decision distribution without selection or label artifacts, the absence of these details renders the performance gap unverifiable from the provided text.
- [Experiments] Experiments section: the abstract asserts that “mainstream enhancement routes fail to close the gap” and that “controlled RLVR interventions show that simple outcome rewards fail,” yet no concrete metrics (accuracy, macro-F1, etc.), statistical tests, confidence intervals, or controls for case difficulty or class imbalance are reported. Without these, it is impossible to assess whether the observed gap is robust or an artifact of evaluation design.
- [RLVR experiments] RLVR subsection: the claim that outcome rewards do not produce generalizable PDP discrimination is load-bearing for the broader argument that new training paradigms are needed. The manuscript must specify the reward formulation, the training/validation split used for the RLVR runs, and the precise definition of “generalizable discrimination” (e.g., held-out charge types or decision classes) before this negative result can be treated as conclusive.
minor comments (2)
- [Task definition] The four non-prosecution decision classes should be explicitly named and their legal definitions supplied in the task formulation section to allow readers to judge the difficulty of the subsumption and discretion components.
- [Results] Table or figure reporting per-class performance on PDP-Bench would help readers see whether the overall gap is driven by particular non-prosecution categories.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive suggestions. The comments highlight important areas for clarification on benchmark construction and experimental reporting. We address each major comment below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / PDP-Bench construction] Abstract and PDP-Bench construction section: the manuscript states that the 4,630 cases are “real Chinese prosecutorial decisions” but supplies no sampling frame, stratification by charge or decision type, provenance of the four-class labels, or independent re-annotation protocol. Because the headline claim rests on the benchmark accurately instantiating the prosecution-decision distribution without selection or label artifacts, the absence of these details renders the performance gap unverifiable.
Authors: The 4,630 cases were sourced from publicly released Chinese prosecutorial decision documents covering 190 charges, selected to ensure coverage across decision types (prosecution and the three non-prosecution outcomes) while maintaining a representative distribution. The four-class labels are the official recorded decisions from the source documents. No independent re-annotation was performed, as these are authoritative legal outcomes rather than subjective annotations. We agree that explicit documentation of the sampling frame and stratification criteria would improve verifiability and will add a dedicated data-construction subsection with these details, including charge-level distributions and decision-type balance, in the revision. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts that “mainstream enhancement routes fail to close the gap” and that “controlled RLVR interventions show that simple outcome rewards fail,” yet no concrete metrics (accuracy, macro-F1, etc.), statistical tests, confidence intervals, or controls for case difficulty or class imbalance are reported. Without these, it is impossible to assess whether the observed gap is robust.
Authors: The full experiments section contains tables reporting accuracy, macro-F1, and other metrics for LLMs on PDP versus LJP, along with results for prompting, fine-tuning, and retrieval methods. Class imbalance was addressed via macro-F1 and stratified sampling in evaluation; statistical comparisons used paired tests. We will revise the abstract to include key quantitative results (e.g., the magnitude of the performance gap) and add explicit references to the relevant tables, figures, and any controls for difficulty or imbalance. revision: yes
-
Referee: [RLVR experiments] RLVR subsection: the claim that outcome rewards do not produce generalizable PDP discrimination is load-bearing. The manuscript must specify the reward formulation, the training/validation split used for the RLVR runs, and the precise definition of “generalizable discrimination” (e.g., held-out charge types or decision classes) before this negative result can be treated as conclusive.
Authors: The RLVR experiments used an outcome-based reward equal to 1 if the predicted decision class matched the ground-truth label and 0 otherwise. Training used an 80/20 train/validation split on the PDP-Bench cases, with generalization evaluated on held-out charge types (unseen during RLVR training) and across all decision classes. We will expand the RLVR subsection to state the reward function, split ratios, and generalization criteria explicitly, including any additional controls. revision: yes
Circularity Check
No significant circularity; empirical benchmark evaluation is self-contained
full rationale
The paper defines a new task (PDP) and constructs PDP-Bench from external real-world prosecutorial decisions, then reports direct LLM performance comparisons against the existing LJP task. No derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps appear; the central claims rest on empirical results from the constructed benchmark rather than reducing to inputs by construction. This is the expected non-finding for an applied benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InFindings of the association for computa- tional linguistics: EMNLP 2020, pages 2898–2904
Legal-bert: The muppets straight out of law school. InFindings of the association for computa- tional linguistics: EMNLP 2020, pages 2898–2904. Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bom- marito, Ion Androutsopoulos, Daniel Katz, and Niko- laos Aletras. 2022. Lexglue: A benchmark dataset for legal language understanding in english. InProceed- ...
2020
-
[2]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, and 1 others
Legaldelta: Enhancing legal reasoning in llms via reinforcement learning with chain-of- thought guided information gain.arXiv preprint arXiv:2508.12281. DeepSeek-AI. 2026. DeepSeek-V4-Pro. Hugging Face model card. Chenlong Deng, Kelong Mao, Yuyao Zhang, and Zhicheng Dou. 2024. Enabling discriminative rea- soning in llms for legal judgment prediction. InFi...
-
[3]
CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction
New horizons of legal judgement predication via multi-task learning and lora. InLegal Knowledge and Information Systems: JURIX 2023: The Thirty- sixth Annual Conference, Maastricht, the Netherlands, 10 18–20 December 2023, pages 207–216. SAGE Publi- cations 1 Oliver’s Yard, 55 City Road, London, EC1Y 1SP. Yiquan Wu, Yifei Liu, Weiming Lu, Yating Zhang, Ju...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Do not fabricate facts, law articles, times, places, relationships, or dispositions that do not appear in the document
Be faithful to the original text. Do not fabricate facts, law articles, times, places, relationships, or dispositions that do not appear in the document
-
[5]
You may think, compare, locate paragraphs, and self-check internally, but the final answer must contain only one valid JSON object
-
[6]
Do not output reasoning, explanations, markdown, prefixes, suffixes, or any extra text in the final answer
-
[7]
id”:“Qi Xin Procuratorial Criminal Indictment [2024] No. 74
If uncertain, use an empty string or an empty array. Do not guess. - - - User Prompt: One-Shot Example Input [Example input directory type]Prosecution [Example input case number]Qi Xin Procuratorial Criminal Indictment [2024] No. 74 [Example input full text]The example is a public indictment for a dangerous-driving case. It contains a webpage source line,...
2024
-
[8]
Convertperson_info,procedure, andfactuniformly to “suspect”. 2.factmust retain concrete conduct facts; immediately following investigation supplements and the evidence catalogue may be retained, but it cannot contain only an evidence catalogue
-
[9]
this Procuratorate holds
If the document contains multiple fact versions, keep the last version, namely the version confirmed by this Procuratorate. 4.factmust not contain reasoning or conclusions such as “this Procuratorate holds”, “according to”, “decision as follows”, “file a public prosecution”, or “decide not to prosecute”. 5.raw_reasoning_and_decisionkeeps only the reasonin...
-
[10]
prosecution
If the actual document is an indictment,decisionmust be “prosecution”
-
[11]
discretionary non-prosecution
If the actual document is a non-prosecution decision, infer whetherdecisionis “discretionary non-prosecution”, “statutory non-prosecution”, or “insufficient-evidence non-prosecution”. 3.person_info,procedure, andfactmust uniformly use “suspect”; do not retain “defendant” or “non-prosecuted person”. 4.person_infokeeps only identity, residence, coercive mea...
-
[12]
the above evidence was collected lawfully
If several fact versions appear, keep the last one, namely the version confirmed by procuratorial review. 8.factmust not contain only an evidence catalogue, evidence evaluation, or summary such as “the above evidence was collected lawfully”, and must not mix in reasoning or conclusions. 9.raw_reasoning_and_decisionkeeps only the reasoning and dispositive ...
-
[13]
Normalizemeta.dateto YYYY-MM-DD andmeta.provinceto the full provincial-level administrative-region name
-
[14]
Delete webpage noise such as source, author, editor, time, font, and HTML fragments
-
[15]
If uncertain, leave blank
Be faithful to the original. If uncertain, leave blank. Do not fabricate. [File-name case number]{stem_id} [Original full document]{raw_text} Figure 8: Actual input template used by the LLM extraction track. Extraction Review Prompt System Prompt You are a quality-control and revision assistant for Chinese criminal prosecutorial-document data. You will se...
-
[16]
Do not add or delete keys
Preserve the original schema. Do not add or delete keys
-
[17]
3.person_info,procedure, andfactmust use the neutral term “suspect”
Prioritize fixing empty fields, decision errors, fact–reasoning mixing, label-leaking appellations, and missing or inconsistent law articles. 3.person_info,procedure, andfactmust use the neutral term “suspect”. 4.factmust retain concrete conduct facts; investigation supplements and the evidence catalogue may be retained, but it cannot contain only an evid...
-
[18]
6.raw_reasoning_and_decisionkeeps only reasoning and dispositive text, excluding submission text, attachments, signatures, dates, and webpage noise
If the fact section contains multiple versions, keep the last one, namely the version confirmed by this Procuratorate; do not mix in reasoning conclusions. 6.raw_reasoning_and_decisionkeeps only reasoning and dispositive text, excluding submission text, attachments, signatures, dates, and webpage noise. 7.relevant_articleskeeps only law articles that trul...
-
[19]
If uncertain, leave blank
Be faithful to the original. If uncertain, leave blank. [Original full document]{raw_text} Figure 9: Prompt used to review and revise extraction outputs flagged by validation. government in land-acquisition compensation man- agement”), so the conduct is governed by CL Arti- cle 271 (embezzlement by company personnel, with a 60,000-yuan threshold). Because...
-
[20]
Do not add facts or delete conduct, amounts, times, evidence names, or law articles that affect factual judgment
Be faithful to the original. Do not add facts or delete conduct, amounts, times, evidence names, or law articles that affect factual judgment
-
[21]
Within the same record, the same natural person must use a consistent de-identified name; existing de-identified names may be preserved
-
[22]
Real names of suspects, victims, witnesses, accomplices, relatives, vehicle owners, recipients, bank-card holders, and other natural persons must be de-identified
-
[23]
Public institutions and public places such as public security organs, procuratorates, courts, forensic centers, administrative agencies, roads, expressways, and toll stations generally should not be de-identified
-
[24]
Private addresses, precise registered-residence house numbers, delivery addresses, private companies, shops, training schools, residential compounds, and other information that can identify a person or private entity must be de-identified
-
[25]
person_info
Return only four keys:person_info,procedure,fact, andraw_reasoning_and_decision; do not add, delete, or rename keys. Figure 10: System instruction for sensitive-information de-identification. Sensitive-Information De-Identification Prompt: User Please de-identify sensitive information in the text fields of the following JSON record. You may think first, b...
-
[26]
Mou”; names with three or more characters as surname + “Moumou
Names of natural persons, including suspects, victims, witnesses, accomplices, recipients, relatives, vehicle owners, and bank-card holders. Two-character Chinese names are usually de-identified as surname + “Mou”; names with three or more characters as surname + “Moumou”; multiple persons with the same surname may be distinguished as “Mou A/Mou B”. Alrea...
-
[27]
Province, city, county/district, township/street, and other coarse locations may be kept; private precise details should be masked
Addresses, including registered residence, current residence, home address, delivery address, private residence, house number, building, unit, room number, and village group. Province, city, county/district, township/street, and other coarse locations may be kept; private precise details should be masked
-
[28]
suspect” into “defendant
Full or partially masked ID numbers, phone numbers, birth dates, bank-card/account numbers, Alipay/WeChat/QQ/email, express/logistics numbers, full license plate numbers, and identifiable private company/shop/school names. [Do not change] Do not change case number, metadata, source URL, decision, relevant articles, charges, amounts, quantities, incident d...
2048
-
[29]
Applicability: the criminal facts have been ascertained, the evidence is reliable and sufficient, and criminal liability should be pursued
Prosecution Legal basis: Article 176 of the Criminal Procedure Law. Applicability: the criminal facts have been ascertained, the evidence is reliable and sufficient, and criminal liability should be pursued
-
[30]
Statutory non-prosecution Legal basis: Article 177(1) and Article 16 of the Criminal Procedure Law. Applicability: there is no criminal fact, or criminal liability is legally barred, including obviously minor circumstances not deemed criminal, expiration of the limitation period, special amnesty, withdrawal or absence of complaint for complaint-only offen...
-
[31]
Applicability: after supplementary investigation, the evidence remains insufficient and the conditions for prosecution are not met
Insufficient-evidence non-prosecution Legal basis: Article 175(4) of the Criminal Procedure Law. Applicability: after supplementary investigation, the evidence remains insufficient and the conditions for prosecution are not met. This includes doubtful evidence, missing proof for offense elements, unresolved contradictions among evidence, or alternative ex...
-
[32]
Discretionary non-prosecution Legal basis: Article 177(2) of the Criminal Procedure Law and Article 370 of the Rules of Criminal Procedure for People’s Procuratorates. Applicability: the facts are clear, the evidence is reliable and sufficient, and the conduct constitutes a crime, but the circumstances are minor and punishment is unnecessary or may be exe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.