Mag-VLA: Vision-Language-Action Model for Bimanual Magnetically Actuated Microrobot Manipulation
Pith reviewed 2026-06-29 11:57 UTC · model grok-4.3
The pith
Mag-VLA adapts a vision-language model to predict coordinated actions for two magnetic arms manipulating microrobots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
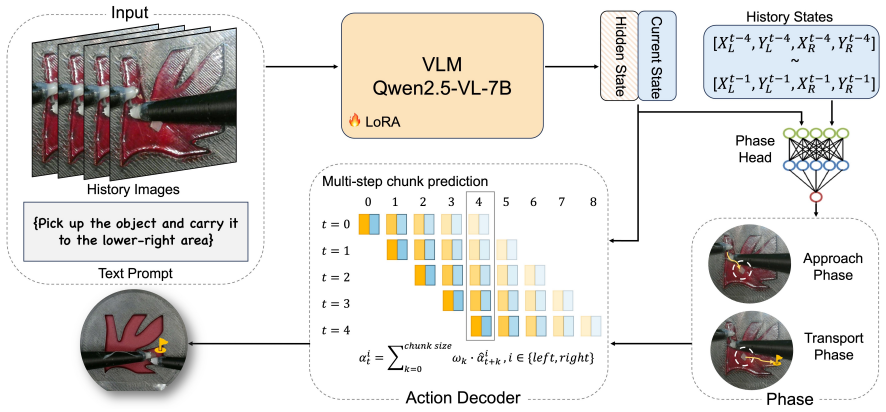
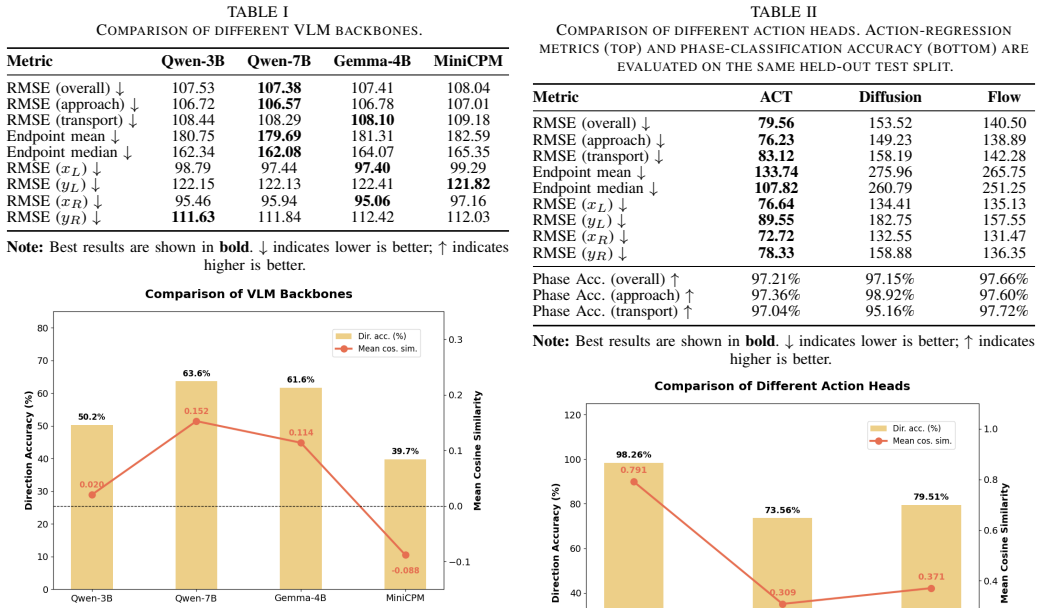
Mag-VLA adapts a vision-language backbone using Low-Rank Adaptation to process visual observations and language instructions, then employs a motion-aware phase classifier and phase-conditioned Action Chunking Transformer decoder to output coordinated multi-step trajectories for two magnetic actuators. This hierarchical structure enables bimanual capabilities such as microrobot reorientation. On a teleoperated dataset of three task configurations, the model achieves a 90 percent approach success rate in real-robot experiments and transport success rates of 80 percent, 70 percent, and 50 percent as task difficulty increases.
What carries the argument
The phase-conditioned Action Chunking Transformer decoder that generates temporally coherent multi-step control actions conditioned on motion phase for bimanual coordination.
If this is right
- Bimanual coordination enables microrobot reorientation that is difficult or infeasible with a single arm.
- The ACT-based decoder substantially outperforms alternative generative action heads in ablation studies.
- Hierarchical VLA modeling supplies a framework that learns task progression through phase classification.
- The approach handles coupled control challenges arising from two actuators operating in one workspace.
Where Pith is reading between the lines
- The same phase-conditioning approach might transfer to other indirect actuation methods if the classifier can be retrained on new sensor data.
- Higher transport success on difficult tasks would likely require expanding the teleoperated dataset to include more varied magnetic nonlinearities.
- Integration with real-time magnetic field sensing could reduce reliance on the assumption that training conditions match deployment conditions.
Load-bearing premise
The teleoperated dataset and real-robot test conditions sufficiently capture the nonlinear magnetic interactions and workspace constraints that occur in the intended minimally invasive applications.
What would settle it
A controlled test in which success rates fall below 50 percent when the model is evaluated on microrobot poses or magnetic field strengths outside the three training task configurations.
Figures



read the original abstract
Magnetically actuated microrobots have been used as wireless, non-contact manipulation tools at microscales, making them promising for minimally invasive applications. However, their control remains challenging due to indirect actuation, limited sensing, and nonlinear magnetic interactions. In this work, we propose Mag-VLA, a vision-language-action (VLA) model for dexterous magnetic microrobot manipulation using two robotic arms with mounted magnets for dynamic magnetic-field construction. Bimanual coordination enables capabilities such as microrobot reorientation that are difficult or infeasible with a single arm, but it also introduces coupled control challenges, as the policy must generate coordinated trajectories for both actuators within a shared workspace. Our framework adapts a Qwen2.5-VL-7B backbone using Low-Rank Adaptation (LoRA) to process visual observations and language instructions for action prediction. To capture task progression, we introduce a motion-aware phase classifier and a phase-conditioned Action Chunking Transformer (ACT) decoder for temporally coherent multi-step control. We further construct a teleoperated magnetic microrobot manipulation dataset covering three task configurations. Ablation studies show that the ACT-based decoder substantially outperforms alternative generative action heads. In real-robot experiments, Mag-VLA achieves a 90% approach success rate across all tasks and transport success rates of 80%, 70%, and 50% as task difficulty increases. These results demonstrate that hierarchical VLA modeling provides a promising framework for magnetic microrobot manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Mag-VLA, a vision-language-action model for bimanual magnetically actuated microrobot manipulation. It adapts the Qwen2.5-VL-7B backbone with LoRA, introduces a motion-aware phase classifier and phase-conditioned Action Chunking Transformer (ACT) decoder, and trains on a new teleoperated dataset spanning three task configurations. Ablation studies compare the ACT decoder against alternative generative heads. Real-robot experiments report a 90% approach success rate across tasks and transport success rates of 80%, 70%, and 50% as task difficulty increases.
Significance. If the reported success rates prove statistically robust and the teleoperated data generalizes beyond open-workspace conditions, the hierarchical VLA approach with bimanual coordination could offer a practical route to dexterous control of microrobots under indirect actuation. The explicit ablation of the phase-conditioned ACT decoder and the construction of a task-progression-aware dataset constitute concrete, reproducible contributions that future work in learned magnetic control can build upon.
major comments (2)
- [Abstract] Abstract: The central performance claims (90% approach success; 80/70/50% transport success) are stated without trial counts, standard deviations, confidence intervals, or any statistical test, making it impossible to evaluate whether the numbers support the generalization to minimally invasive settings.
- [Dataset Construction and Experiments] Dataset and real-robot experiments description: No quantitative metrics (e.g., field nonlinearity error, workspace overlap with tissue constraints, or sensing noise levels) are supplied to show that the teleoperated open-workspace data reproduces the coupled magnetic interactions and limited observability of the intended applications; this assumption is load-bearing for the application-level conclusions.
minor comments (1)
- [Abstract] The abstract introduces the motion-aware phase classifier and phase-conditioned ACT decoder without a one-sentence statement of how phase information is obtained at inference time.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. The comments highlight important aspects for improving the clarity and applicability of our results. We provide point-by-point responses below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (90% approach success; 80/70/50% transport success) are stated without trial counts, standard deviations, confidence intervals, or any statistical test, making it impossible to evaluate whether the numbers support the generalization to minimally invasive settings.
Authors: We agree with this observation. The abstract currently presents aggregate success rates without accompanying statistical details. In the revised version, we will include the number of trials conducted for each task configuration, along with standard deviations and confidence intervals where applicable. This will allow readers to better assess the robustness of the reported performance. revision: yes
-
Referee: [Dataset Construction and Experiments] Dataset and real-robot experiments description: No quantitative metrics (e.g., field nonlinearity error, workspace overlap with tissue constraints, or sensing noise levels) are supplied to show that the teleoperated open-workspace data reproduces the coupled magnetic interactions and limited observability of the intended applications; this assumption is load-bearing for the application-level conclusions.
Authors: We acknowledge that our experiments are conducted in an open workspace and do not include direct quantitative comparisons to tissue-constrained environments, such as field nonlinearity errors or workspace overlaps with tissue. The teleoperated dataset captures the core challenges of bimanual magnetic actuation, including coupled interactions between the two arms and the microrobot. However, we recognize this as a limitation for claiming direct applicability to minimally invasive settings. In the revision, we will expand the discussion section to explicitly address the differences between open-workspace conditions and in vivo scenarios, and outline future work to bridge this gap. We believe the current results provide a valuable baseline for the VLA approach in magnetic microrobot control. revision: partial
Circularity Check
No circularity: empirical model training and real-robot evaluation on newly collected dataset
full rationale
The paper introduces Mag-VLA by adapting an external Qwen2.5-VL backbone with LoRA, adding a motion-aware phase classifier and phase-conditioned ACT decoder, training on a teleoperated dataset constructed for this work, and reporting direct experimental success rates (90% approach, 80/70/50% transport) in real-robot tests. No equations, fitted parameters renamed as predictions, self-definitional relations, or load-bearing self-citations appear in the derivation or evaluation chain. Ablations compare decoder variants on the same data, but the central claims rest on independent experimental outcomes rather than reductions to inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Medical micro- robots,
V . Iacovacci, E. Diller, D. Ahmed, and A. Menciassi, “Medical micro- robots,”Annual Review of Biomedical Engineering, vol. 26, no. 1, pp. 561–591, 2024
2024
-
[2]
Advanced medical micro-robotics for early diagnosis and therapeutic interventions,
D. Zhang, T. E. Gorochowski, L. Marucci, H.-T. Lee, B. Gil, B. Li, S. Hauert, and E. Yeatman, “Advanced medical micro-robotics for early diagnosis and therapeutic interventions,”Frontiers in Robotics and AI, vol. 9, p. 1086043, 2023
2023
-
[3]
External field-driven untethered microrobots for targeted cargo delivery,
S. Zhu, Y . Chen, G. Liu, H. Qian, F. Niu, Y . Wang, Y . Zhao, T. Luo, and R. Yang, “External field-driven untethered microrobots for targeted cargo delivery,”Advanced Materials Technologies, vol. 7, no. 5, p. 2101256, 2022
2022
-
[4]
Magnetic microrobots for in vivo cargo delivery: A review,
J. Lin, Q. Cong, and D. Zhang, “Magnetic microrobots for in vivo cargo delivery: A review,”Micromachines, vol. 15, no. 5, p. 664, 2024
2024
-
[5]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[6]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
π0.5: a vision- language-action model with open-world generalization,
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Gallikeret al., “ π0.5: a vision- language-action model with open-world generalization,” in9th Annual Conference on Robot Learning, 2025
2025
-
[8]
R. Tang, C. K. Ng, K. Wu, L. Bai, G. Wang, Y . Huang, Y . Wang, and H. Ren, “Tmr-vla: Vision-language-action model for magnetic motion control of tri-leg silicone-based soft robot,”arXiv preprint arXiv:2603.00420, 2026
-
[9]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine- grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
A computer-aided teleoperation system for intuitively controlling the behavior of a magnetic millirobot within a stomach phantom,
R. Liu, Y . Xiang, Z. Wei, and J. Zhang, “A computer-aided teleoperation system for intuitively controlling the behavior of a magnetic millirobot within a stomach phantom,”Advanced Intelligent Systems, vol. 6, no. 2, p. 2300325, 2024
2024
-
[11]
Scheduling adaptive imitation learning for long-horizon dexterous robot micromanipulation of deformable cell,
Y . Zhang, X. Shen, C. Wang, F. Wang, A. Zhao, Y . Lyu, A. Knoll, Y . Liu, Y . Ying, and M. Zhou, “Scheduling adaptive imitation learning for long-horizon dexterous robot micromanipulation of deformable cell,” IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 41–48, 2025
2025
-
[12]
Context-aware adaptive shared control for magnetically-driven bimanual dexterous micromanipulation,
Y . Wang, K. Lu, L. Wei, and D. Zhang, “Context-aware adaptive shared control for magnetically-driven bimanual dexterous micromanipulation,” arXiv preprint arXiv:2603.14388, 2026
-
[13]
An automatic navigation framework for magnetic fish-like millirobot in uncertain dynamic environments,
C. Tian, X. Fan, J. Jia, Z. Yang, and H. Xie, “An automatic navigation framework for magnetic fish-like millirobot in uncertain dynamic environments,”IEEE Robotics and Automation Letters, vol. 10, no. 3, pp. 2422–2429, 2025
2025
-
[14]
Robust 3-d path following control framework for magnetic helical millirobots subject to fluid flow and input saturation,
Z. Qi, M. Cai, B. Hao, Y . Cao, L. Su, X. Liu, K. F. Chan, C. Yang, and L. Zhang, “Robust 3-d path following control framework for magnetic helical millirobots subject to fluid flow and input saturation,”IEEE transactions on cybernetics, vol. 54, no. 12, pp. 7629–7641, 2024
2024
-
[15]
Deep reinforcement learning-based semi- autonomous control for magnetic micro-robot navigation with immersive manipulation,
Y . Mao and D. Zhang, “Deep reinforcement learning-based semi- autonomous control for magnetic micro-robot navigation with immersive manipulation,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 9088–9094
2025
-
[16]
Autonomous navigation of magnetic microrobots with improved planning and control in complex environments,
Y . Liu, H. Wang, X. Wu, J. Qu, X. Liu, and Q. Fan, “Autonomous navigation of magnetic microrobots with improved planning and control in complex environments,”IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 2421–2432, 2024
2024
-
[17]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[18]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
- [21]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.