MUSE: Benchmarking Manufacturable, Functional, and Assemblable Text-to-CAD Generation
Pith reviewed 2026-06-29 11:50 UTC · model grok-4.3
The pith
MUSE shows LLMs generate CAD code and geometry but rarely meet criteria for functional, manufacturable assemblies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that Text-to-CAD must be judged by whether generated models satisfy practical design intent through a three-stage protocol of code check, geometric check, and rubric-based alignment on manufacturability, functionality, and assemblability; experiments demonstrate a failure cascade in which even strong LLMs achieve only limited success on the final engineering criteria.
What carries the argument
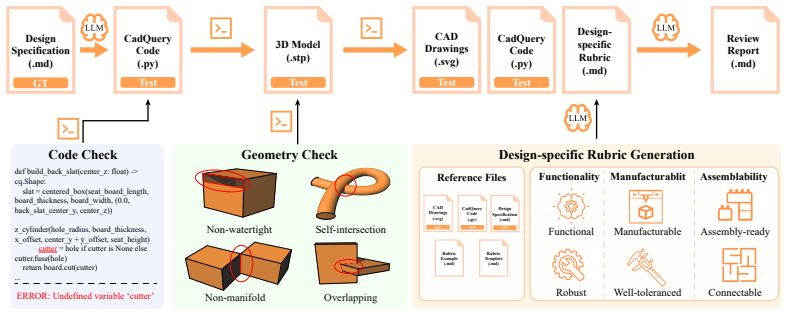
Three-stage evaluation protocol that ends with design-specific rubrics scored by a VLM judge to measure alignment with functionality, manufacturability, and assemblability.
If this is right
- Text-to-CAD systems must incorporate engineering constraints during generation rather than relying on post-hoc geometric fixes.
- Benchmarks should shift from single-part shape matching to multi-part assemblies with explicit design specifications.
- Progress metrics should track success rates on fine-grained criteria such as assemblability instead of overall geometric similarity.
- Evaluation frameworks need scalable judges that can be trusted on domain-specific rubrics.
Where Pith is reading between the lines
- Training pipelines for CAD LLMs may need explicit feedback loops that simulate manufacturing and assembly checks.
- The benchmark could be adapted to test specific manufacturing methods such as injection molding or CNC machining constraints.
- Future work might explore whether adding simulation-based rewards during generation closes the observed failure cascade.
Load-bearing premise
The rubric-based VLM judge gives assessments of functionality, manufacturability, and assemblability that match human judgments.
What would settle it
A follow-up study in which human experts score a representative sample of generated models on the same rubrics and obtain substantially different pass rates from the VLM.
Figures


read the original abstract
Large language models (LLMs) have recently advanced text-driven 3D generation, yet Text-to-CAD remains far from supporting industrial product design. Existing benchmarks focus primarily on generating single-part CAD models and evaluate them using geometric similarity metrics that fail to capture functionality, manufacturability, and assemblability. To address this gap, we introduce MUSE, a Text-to-CAD benchmark focused on complex, editable boundary representation (B-Rep) assemblies. MUSE pairs practical design instances with structured Design Specifications and evaluates generated models through a three-stage protocol: code check, geometric check, and design-intent alignment. The final stage uses design-specific rubrics to assess functionality, manufacturability, and assemblability, moving beyond shape matching toward practical design quality. To enable scalable evaluation, we use a rubric-based visual language model (VLM) judge and validate its reliability through human annotation. Experiments on closed-source and open-source LLMs reveal a clear failure cascade from executable code to valid geometry and finally to engineering-ready design, with even the strongest models achieving limited success on fine-grained engineering criteria. Together, MUSE provides a realistic benchmark and evaluation framework for advancing Text-to-CAD from geometric generation toward true engineering design. Our project website, including the leaderboard, dataset, and code, is available at https://dong7313.github.io/muse-benchmark/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MUSE, a benchmark for text-to-CAD generation targeting complex, editable B-Rep assemblies. It pairs design instances with structured specifications and evaluates outputs via a three-stage protocol (code check, geometric check, design-intent alignment) that uses rubric-based VLM scoring for functionality, manufacturability, and assemblability. The VLM judge is validated by human annotation. Experiments on closed- and open-source LLMs demonstrate a failure cascade, with even strong models showing limited success on fine-grained engineering criteria. The work releases dataset, code, and leaderboard.
Significance. If the VLM validation and failure-cascade results hold, MUSE supplies a needed shift from geometric similarity metrics to practical engineering criteria, which could steer Text-to-CAD research toward industrially relevant outputs. The release of the dataset, code, and leaderboard is a concrete strength that supports reproducibility and community follow-up.
major comments (2)
- [Evaluation Protocol / VLM Judge Validation] The design-intent alignment stage (final stage of the three-stage protocol) relies on rubric-based VLM scoring of functionality, manufacturability, and assemblability; the manuscript asserts this judge is validated by human annotation, yet provides no quantitative details on sample size, inter-rater agreement (e.g., Cohen’s kappa or percentage agreement), or coverage of edge cases such as tolerance stack-up and assembly kinematics. Because the reported “limited success on fine-grained engineering criteria” and the failure-cascade conclusion rest directly on these scores, the validation evidence must be expanded to confirm the judge does not introduce systematic bias.
- [Experiments] The abstract and high-level description state that experiments reveal a clear failure cascade, but the provided text supplies no quantitative tables or per-stage success rates (e.g., percentage of models passing code check vs. geometric check vs. design-intent alignment). Without these numbers and error bars, it is impossible to verify the magnitude or statistical significance of the cascade or to compare closed- versus open-source models on the engineering criteria.
minor comments (2)
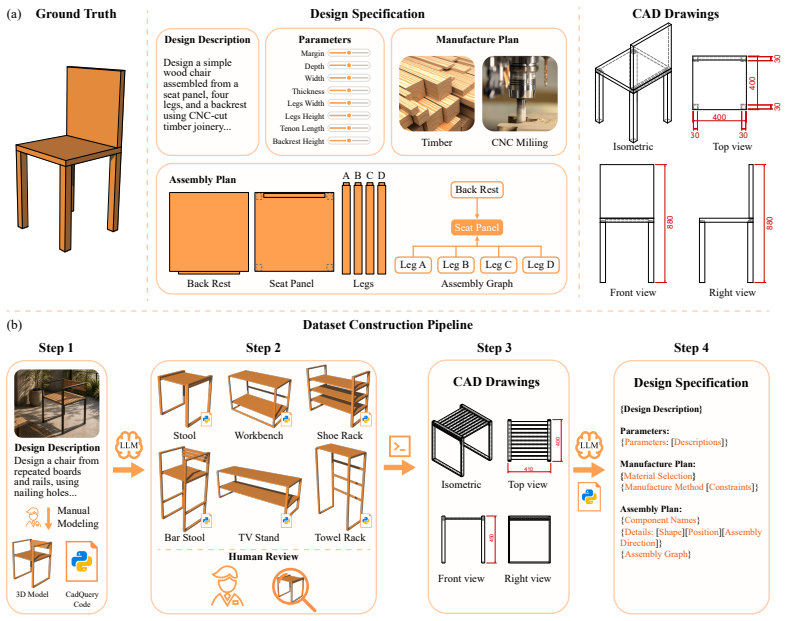
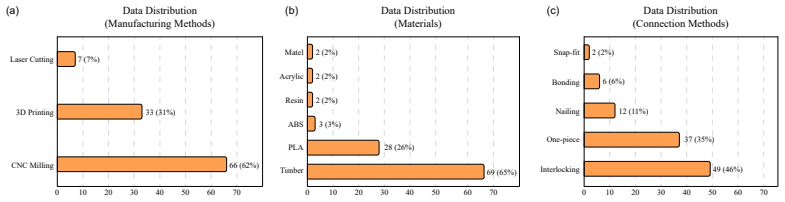
- [Benchmark Construction] The abstract refers to “practical design instances” and “structured Design Specifications” without defining the source or construction process of the benchmark instances; a short paragraph or table in §3 would clarify dataset provenance.
- Figure captions and the project website URL are mentioned but not cross-referenced in the text; ensure every figure is cited at the point of first discussion.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the clarity and rigor of our work. We address each major comment below and have revised the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: The design-intent alignment stage (final stage of the three-stage protocol) relies on rubric-based VLM scoring of functionality, manufacturability, and assemblability; the manuscript asserts this judge is validated by human annotation, yet provides no quantitative details on sample size, inter-rater agreement (e.g., Cohen’s kappa or percentage agreement), or coverage of edge cases such as tolerance stack-up and assembly kinematics. Because the reported “limited success on fine-grained engineering criteria” and the failure-cascade conclusion rest directly on these scores, the validation evidence must be expanded to confirm the judge does not introduce systematic bias.
Authors: We agree that the validation of the VLM judge requires quantitative support. In the revised manuscript we expand the validation subsection to report the human annotation sample size, inter-rater agreement statistics (Cohen’s kappa and percentage agreement), and explicit coverage of edge cases including tolerance stack-up and assembly kinematics. These additions demonstrate that the VLM scores align with human judgments and do not introduce systematic bias. revision: yes
-
Referee: The abstract and high-level description state that experiments reveal a clear failure cascade, but the provided text supplies no quantitative tables or per-stage success rates (e.g., percentage of models passing code check vs. geometric check vs. design-intent alignment). Without these numbers and error bars, it is impossible to verify the magnitude or statistical significance of the cascade or to compare closed- versus open-source models on the engineering criteria.
Authors: We concur that per-stage quantitative results are essential for verifying the failure cascade. The revised manuscript now includes dedicated tables reporting success rates at each protocol stage (code check, geometric check, design-intent alignment) for all models, together with error bars. These tables enable direct assessment of the cascade magnitude, statistical significance, and closed- versus open-source model differences on the engineering criteria. revision: yes
Circularity Check
No circularity: benchmark and evaluation protocol are self-contained contributions
full rationale
The paper introduces MUSE as a new benchmark with a three-stage evaluation protocol (code check, geometric check, design-intent alignment via rubrics) and reports empirical results on LLMs. No equations, fitted parameters, or derived predictions exist that could reduce to inputs by construction. The VLM judge is presented as an external tool whose reliability is checked via separate human annotation, which is an independent empirical step rather than a self-referential loop. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. This matches the default case of a benchmark paper whose central claims rest on new data and protocol rather than internal re-derivation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
P3D-Bench is a benchmark with three task families that scores MLLMs on generating executable parametric 3D programs, finding failures in precise geometry and part assembly.
Reference graph
Works this paper leans on
-
[1]
Text2CAD: generating sequential cad designs from beginner-to-expert level text prompts.Advances in Neural Information Processing Systems, 37:7552–7579, 2024
Mohammad S Khan, Sankalp Sinha, Talha U Sheikh, Didier Stricker, Sk A Ali, and Muham- mad Z Afzal. Text2CAD: generating sequential cad designs from beginner-to-expert level text prompts.Advances in Neural Information Processing Systems, 37:7552–7579, 2024
2024
-
[2]
TripoSR: Fast 3D Object Reconstruction from a Single Image
Dmitry Tochilkin, David Pankratz, Zexiang Liu, Zixuan Huang, Adam Letts, Yangguang Li, Ding Liang, Christian Laforte, Varun Jampani, and Yan-Pei Cao. Triposr: fast 3d object reconstruction from a single image.arXiv preprint arXiv:2403.02151, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
SeparateGen: semantic component-based 3D character generation from single images.IEEE Transactions on Visualization and Computer Graphics, 2026
Dong-Yang Li, Yi-Long Liu, Zi-Xian Liu, Yan-Pei Cao, Meng-Hao Guo, and Shi-Min Hu. SeparateGen: semantic component-based 3D character generation from single images.IEEE Transactions on Visualization and Computer Graphics, 2026
2026
-
[4]
Text-to-CAD generation through infusing visual feedback in large language models
Ruiyu Wang, Yu Yuan, Shizhao Sun, and Jiang Bian. Text-to-CAD generation through infusing visual feedback in large language models. InProceedings of the International Conference on Machine Learning (ICML), 2025
2025
-
[5]
Creating novel furniture through topology optimization and advanced manufacturing.Rapid Prototyping Journal, 27(9):1749–1758, 2021
Jiaming Ma, Zhi Li, Zi-Long Zhao, and Yi Min Xie. Creating novel furniture through topology optimization and advanced manufacturing.Rapid Prototyping Journal, 27(9):1749–1758, 2021
2021
-
[6]
DeepCAD: A deep generative network for computer-aided design models
Rundi Wu, Chang Xiao, and Changxi Zheng. DeepCAD: A deep generative network for computer-aided design models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6772–6782, October 2021
2021
-
[7]
Text2CAD: generating sequential CAD models from beginner-to- expert level text prompts
Mohammad Sadil Khan, Sankalp Sinha, Talha Uddin Sheikh, Didier Stricker, Sk Aziz Ali, and Muhammad Zeshan Afzal. Text2CAD: generating sequential CAD models from beginner-to- expert level text prompts. InAdvances in Neural Information Processing Systems (NeurIPS), pages 7552–7579, 2024
2024
-
[8]
CAD- GPT: synthesising CAD construction sequence with spatial reasoning-enhanced multimodal LLMs
Siyu Wang, Cailian Chen, Xinyi Le, Qimin Xu, Lei Xu, Yanzhou Zhang, and Jie Yang. CAD- GPT: synthesising CAD construction sequence with spatial reasoning-enhanced multimodal LLMs. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7880–7888, 2025
2025
-
[9]
CAD translator: an effective drive for text to 3D parametric computer-aided design generative modeling
Xueyang Li, Yu Song, Yunzhong Lou, and Xiangdong Zhou. CAD translator: an effective drive for text to 3D parametric computer-aided design generative modeling. InProceedings of the ACM International Conference on Multimedia (ACM MM 2024), Poster, 2024
2024
-
[10]
ArtiCAD: Articulated CAD Assembly Design via Multi-Agent Code Generation
Yuan Shui, Yandong Guan, Zhanwei Zhang, Juncheng Hu, Jing Zhang, Dong Xu, and Qian Yu. ArtiCAD: articulated CAD assembly design via multi-agent code generation.arXiv preprint arXiv:2604.10992, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
MLLM-as-a-Judge: Assessing multimodal LLM-as-a-judge with vision-language benchmark
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yinuo Liu, Yaochen Wang, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. MLLM-as-a-Judge: Assessing multimodal LLM-as-a-judge with vision-language benchmark. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[12]
Wentao Ge, Shunian Chen, Guiming Hardy Chen, et al. MLLM-Bench: evaluating multimodal LLMs with per-sample criteria.arXiv preprint arXiv:2311.13951, 2024. 10
-
[13]
Md Tahmid Rahman Laskar, Mohammed Saidul Islam, Ridwan Mahbub, Ahmed Masry, Miza- nur Rahman, Amran Bhuiyan, Mir Tafseer Nayeem, Shafiq Joty, Enamul Hoque, and Jimmy Huang. Judging the judges: Can large vision-language models fairly evaluate chart compre- hension and reasoning? InProceedings of the 63rd Annual Meeting of the Association for Computational ...
2025
-
[14]
Prometheus-vision: Vision-language model as a judge for fine-grained evaluation
Seongyun Lee, Seungone Kim, Sue Park, Geewook Kim, and Minjoon Seo. Prometheus-vision: Vision-language model as a judge for fine-grained evaluation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11286–11315, 2024
2024
-
[15]
Runzhou Liu, Hailey Weingord, Sejal Mittal, et al. Human-Aligned MLLM judges for fine- grained image editing evaluation: a benchmark, framework, and analysis.arXiv preprint arXiv:2602.13028, 2026
-
[16]
Yukang Feng, Jianwen Sun, Chuanhao Li, et al. A high-quality dataset and reliable evaluation for interleaved image-text generation.arXiv preprint arXiv:2506.09427, 2025
-
[17]
Ruihang Li, Leigang Qu, Jingxu Zhang, Dongnan Gui, Mengde Xu, Xiaosong Zhang, Han Hu, Wenjie Wang, and Jiaqi Wang. Genarena: How can we achieve human-aligned evaluation for visual generation tasks?arXiv preprint arXiv:2602.06013, 2026
-
[18]
K-Sort eval: efficient preference evaluation for visual generation via corrected VLM-as-a-Judge
Zhikai Li, Jiatong Li, Xuewen Liu, et al. K-Sort eval: efficient preference evaluation for visual generation via corrected VLM-as-a-Judge. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[19]
Llava-critic: Learning to evaluate multimodal models
Tianyi Xiong, Xiyao Wang, Dong Guo, Qinghao Ye, Haoqi Fan, Quanquan Gu, Heng Huang, and Chunyuan Li. Llava-critic: Learning to evaluate multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13618–13628, 2025
2025
-
[20]
Zeyu Chen, Huanjin Yao, Ziwang Zhao, and Min Yang. Advancing multimodal judge models through a capability-oriented benchmark and mcts-driven data generation.arXiv preprint arXiv:2603.00546, 2026
-
[21]
Tianyi Xiong, Yi Ge, Ming Li, et al. Multi-Crit: Benchmarking multimodal judges on pluralistic criteria-following.arXiv preprint arXiv:2511.21662, 2025
-
[22]
CADSmith: Multi-Agent CAD Generation with Programmatic Geometric Validation,
Jesse Barkley, Rumi Loghmani, and Amir Barati Farimani. Cadsmith: Multi-agent cad genera- tion with programmatic geometric validation.arXiv preprint arXiv:2603.26512, 2026
-
[24]
Codegen-3d: A benchmark for evaluating llms in zero-shot and iterative 3d modeling in blender.IEEE Access, 2026
Hao Ji, Kotha Aditya, Sebastian Escalante, and Yunjian Qiu. Codegen-3d: A benchmark for evaluating llms in zero-shot and iterative 3d modeling in blender.IEEE Access, 2026
2026
-
[26]
EvoCAD: evolutionary CAD code generation with vision language models
Tobias Preintner, Weixuan Yuan, Adrian König, Thomas Bäck, Elena Raponi, and Niki Van Stein. EvoCAD: evolutionary CAD code generation with vision language models. In2025 IEEE 37th International Conference on Tools with Artificial Intelligence (ICTAI), pages 504–511. IEEE, 2025
2025
-
[27]
Generating CAD code with vision-language models for 3D designs.arXiv preprint arXiv:2410.05340, 2024
Kamel Alrashedy, Pradyumna Tambwekar, Zulfiqar Zaidi, Megan Langwasser, Wei Xu, and Matthew Gombolay. Generating CAD code with vision-language models for 3D designs.arXiv preprint arXiv:2410.05340, 2024
-
[28]
Pointer-CAD: Unifying B-Rep and Command Sequences via Pointer-based Edges & Faces Selection
Dacheng Qi, Chenyu Wang, Jingwei Xu, Tianzhe Chu, Zibo Zhao, Wen Liu, Wenrui Ding, Yi Ma, and Shenghua Gao. Pointer-CAD: unifying B-Rep and command sequences via pointer- based edges & faces selection.arXiv preprint arXiv:2603.04337, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Ruiyu Wang, Yu Yuan, Shizhao Sun, and Jiang Bian. Text-to-CAD generation through infusing visual feedback in large language models.arXiv preprint arXiv:2501.19054, 2025. 11
-
[30]
Jingwei Xu, Chenyu Wang, Zibo Zhao, Wen Liu, Yi Ma, and Shenghua Gao. CAD- MLLM: Unifying multimodality-conditioned CAD generation with MLLM.arXiv preprint arXiv:2411.04954, 2024
-
[31]
Automated CAD modeling sequence generation from text descriptions via transformer-based large language models
Jianxing Liao, Junyan Xu, Yatao Sun, Maowen Tang, Sicheng He, Jingxian Liao, Shui Yu, Yun Li, and Xiaohong Guan. Automated CAD modeling sequence generation from text descriptions via transformer-based large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 21720–21748, 2025
2025
-
[32]
Text2CAD: text to 3D CAD generation via technical drawings.arXiv preprint arXiv:2411.06206, 2024
Mohsen Yavartanoo, Sangmin Hong, Reyhaneh Neshatavar, and Kyoung Mu Lee. Text2CAD: text to 3D CAD generation via technical drawings.arXiv preprint arXiv:2411.06206, 2024
-
[33]
FLASK: Fine-grained language model evaluation based on alignment skill sets
Seonghyeon Ye, Doyoung Kim, Sungdong Kim, Sahana Hwang, Seungone Kim, Yongrae Jo, James Thorne, Juho Kim, and Minjoon Seo. FLASK: Fine-grained language model evaluation based on alignment skill sets. InICLR, 2024
2024
-
[34]
G-Eval: NLG evaluation using GPT-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment. InEMNLP, 2023
2023
-
[35]
Keep assembly split unchanged
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and chatbot arena. InNeurIPS Datasets and Benchmarks Track, 2023. A Engineering Knowledge Tables for Manufacturability To systematically eva...
2023
-
[36]
‘<Task_Doc>‘: the design specification, including design goals, component list, parameter ranges, and assembly graph
-
[37]
‘<Reference_Code>‘: the ground-truth CAD logic and spatial coordinates
-
[38]
Core Focus
‘<Reference_SVG>‘: the visual anchor / reference image. # Output Template Strictly follow the Markdown template below. You must use the exact terms ‘<Reference_SVG>‘ and ‘<Generated_SVG>‘ in the rubric. Write the instructions as if you are directly guiding the downstream judge. Do not include a separate "Core Focus" field. Instead, merge all necessary ins...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.