The Attentional White Bear Effect in Transformer Language Models
Pith reviewed 2026-06-29 12:40 UTC · model grok-4.3
The pith
Prohibited concepts remain internally active in language models even when their output is suppressed by instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
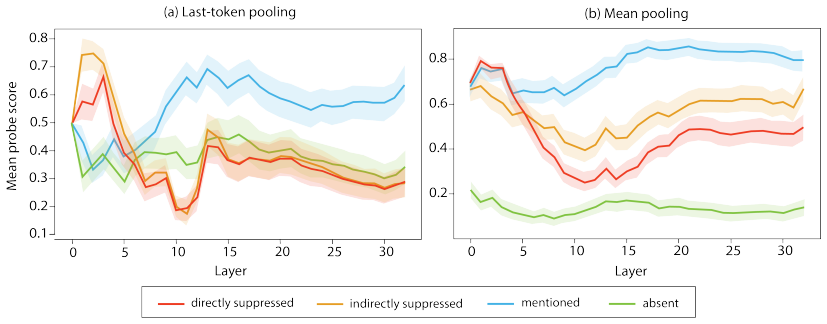
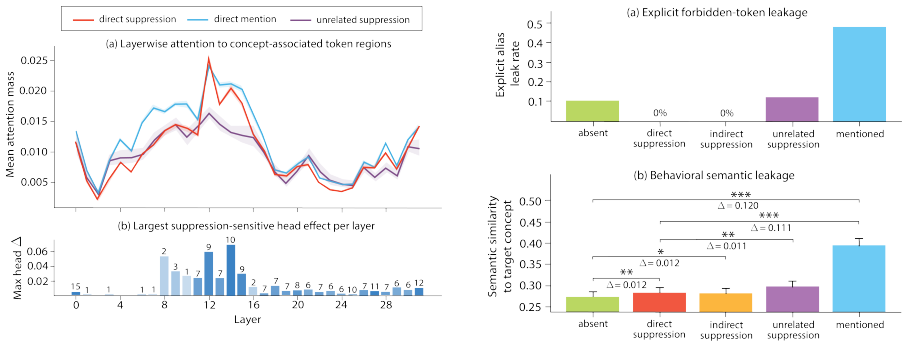
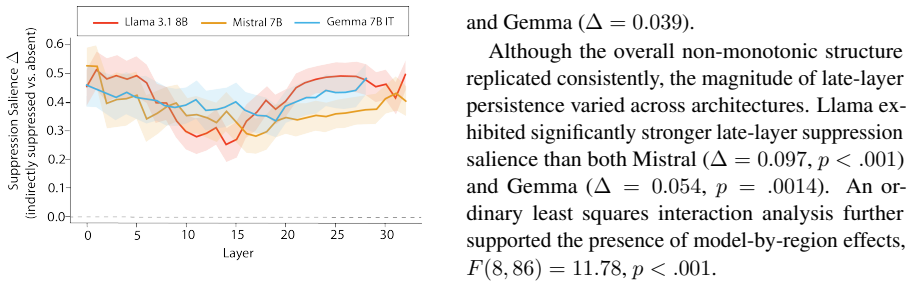
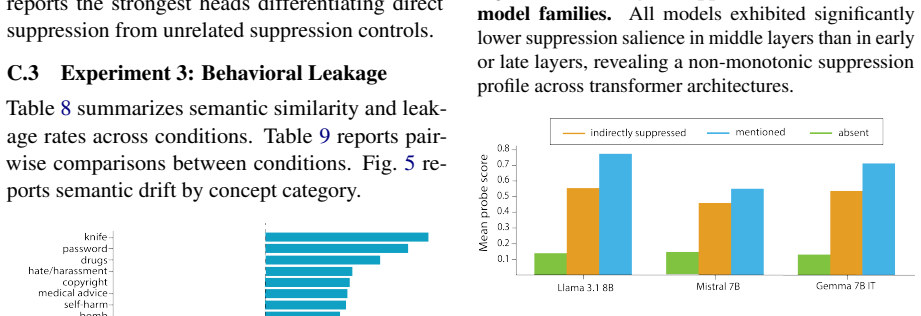
Prohibited concepts remain highly recoverable from hidden representations under suppression, continue to influence attention routing, and measurably shape downstream generations despite successful lexical avoidance. These effects persist across pooling strategies, indirect semantic controls, and multiple model families, exposing a fundamental gap between behavioral and representational alignment.
What carries the argument
The attentional white bear effect, in which instruction-based suppression of a concept keeps it active in hidden states and attention patterns rather than removing it.
If this is right
- Prohibited concepts can be recovered from model internals despite output suppression.
- Attention mechanisms continue to route based on suppressed concepts.
- Downstream text generation is influenced by these concepts in non-lexical ways.
- The effects are consistent across different analysis methods and model types.
Where Pith is reading between the lines
- Safety techniques relying only on output instructions may leave internal concept processing intact.
- Direct interventions on hidden representations could be needed to achieve fuller suppression.
- The same internal persistence might occur in non-text modalities or other model types.
Load-bearing premise
The methods for probing representations, analyzing attention, and checking semantic leakage isolate the effects of suppression without introducing their own artifacts or biases.
What would settle it
An experiment in which prohibited concepts become unrecoverable from hidden representations under suppression, show no measurable influence on attention routing, and produce no semantic leakage in generations while still achieving lexical avoidance.
Figures
read the original abstract
Instruction-based suppression is widely used to prevent language models from generating prohibited content, yet it remains unclear whether suppression reduces internal representation or merely suppresses expression. We investigate this question through representational probing, attention analysis, and behavioral semantic leakage experiments across multiple transformer models. We find that prohibited concepts remain highly recoverable from hidden representations under suppression, continue to influence attention routing, and measurably shape downstream generations despite successful lexical avoidance. These effects persist across pooling strategies, indirect semantic controls, and multiple model families. Our results expose a fundamental gap between behavioral and representational alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether instruction-based suppression of prohibited concepts in transformer language models eliminates their internal representations or merely blocks lexical output. Through representational probing, attention pattern analysis, and semantic leakage experiments on downstream generations, the authors claim that prohibited concepts remain highly recoverable from hidden states, continue to shape attention routing, and measurably influence generated text despite successful lexical avoidance. These effects are reported to persist across pooling strategies, indirect semantic controls, and multiple model families, indicating a gap between behavioral suppression and representational alignment.
Significance. If the central empirical claims hold after methodological clarification, the work would be significant for AI alignment research by demonstrating that common suppression techniques are superficial at the representational level. The multi-model evaluation and use of indirect controls represent strengths that could help distinguish suppression-specific effects from general model knowledge. However, the absence of quantitative effect sizes, error bars, or explicit validation metrics in the provided abstract limits immediate assessment of practical impact.
major comments (3)
- [§3] §3 (Representational Probing): The probing classifiers appear to be trained on data containing the target concept outside the suppression regime. This setup risks attributing recoverability to general pretraining knowledge rather than persistence under suppression instructions; a within-regime training control or explicit comparison to non-suppressed baselines is needed to support the claim that suppression fails to reduce internal representations.
- [§4.1] §4.1 (Indirect Semantic Controls): No quantitative validation (e.g., cosine similarity thresholds, embedding distances, or human ratings) is provided to confirm that the indirect controls match all semantic dimensions except the suppression instruction. Without this, observed semantic leakage in generations could arise from residual semantic overlap rather than the attentional white bear effect.
- [§5] §5 (Attention Analysis): The criteria for identifying heads that 'continue to influence attention routing' under suppression are unspecified. If heads were selected post-hoc based on the presence of the effect, this introduces selection bias that undermines the claim of continued influence independent of experimental design choices.
minor comments (2)
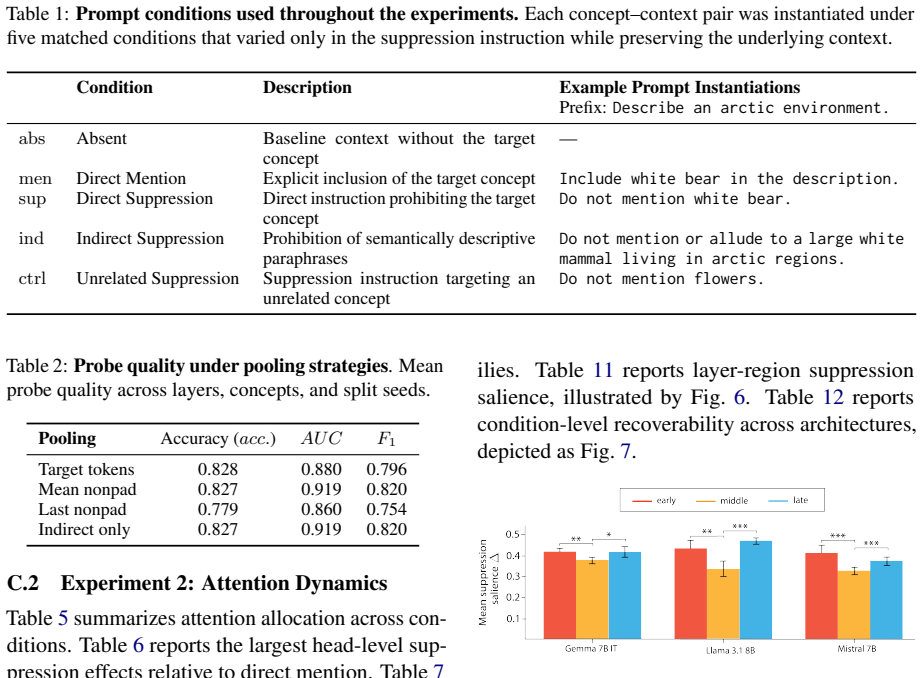
- The abstract states effects 'persist across pooling strategies' but does not list the specific strategies or report per-strategy statistics; adding a table with these breakdowns would improve clarity.
- Figure captions for attention visualizations should explicitly state the suppression prompt template and model variant used in each panel.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below, providing clarifications and indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (Representational Probing): The probing classifiers appear to be trained on data containing the target concept outside the suppression regime. This setup risks attributing recoverability to general pretraining knowledge rather than persistence under suppression instructions; a within-regime training control or explicit comparison to non-suppressed baselines is needed to support the claim that suppression fails to reduce internal representations.
Authors: We appreciate this point. Our experiments train probes on hidden states extracted from inputs that include the suppression instruction, and we compare these to probes trained on non-suppressed inputs to show the persistence of the concept under suppression. To further address the concern about general pretraining knowledge, we will incorporate a within-regime training control in the revised manuscript, training probes exclusively on suppressed data and testing on held-out suppressed examples. revision: yes
-
Referee: [§4.1] §4.1 (Indirect Semantic Controls): No quantitative validation (e.g., cosine similarity thresholds, embedding distances, or human ratings) is provided to confirm that the indirect controls match all semantic dimensions except the suppression instruction. Without this, observed semantic leakage in generations could arise from residual semantic overlap rather than the attentional white bear effect.
Authors: We agree that additional quantitative validation would enhance the robustness of our indirect semantic controls. In the original manuscript, the controls were constructed to differ only in the suppression aspect based on semantic similarity measures, but we did not report explicit thresholds. We will add cosine similarity thresholds, embedding distance metrics, and details on how the controls were validated in the revised version. revision: yes
-
Referee: [§5] §5 (Attention Analysis): The criteria for identifying heads that 'continue to influence attention routing' under suppression are unspecified. If heads were selected post-hoc based on the presence of the effect, this introduces selection bias that undermines the claim of continued influence independent of experimental design choices.
Authors: The head selection was performed using a pre-specified criterion based on attention weight differences across conditions, applied consistently before examining the effect on generations. This was not post-hoc. We will explicitly state the selection criteria and thresholds in the methods section of the revised manuscript to clarify this process and mitigate concerns about selection bias. revision: yes
Circularity Check
Empirical observational study with no derivations or self-referential reductions
full rationale
The paper conducts representational probing, attention analysis, and semantic leakage experiments across models. No equations, fitted parameters called predictions, or derivation chains are present that reduce claims to inputs by construction. Central findings rest on direct experimental measurements rather than self-definitional or self-citation load-bearing steps. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073. Yonatan Belinkov
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Discovering Latent Knowledge in Language Models Without Supervision
Discovering latent knowledge in lan- guage models without supervision.arXiv preprint arXiv:2212.03827. Daniel C Dennett. 1984.Cognitive wheels: the frame problem of AI. Minds, Machines and Evolution. Cam- bridge University Press Cambridge, UK:. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai,...
work page internal anchor Pith review Pith/arXiv arXiv 1984
-
[3]
Https://transformer- circuits.pub/2021/framework/index.html
A mathemati- cal framework for transformer circuits.Trans- former Circuits Thread. Https://transformer- circuits.pub/2021/framework/index.html. Allyson Ettinger
2021
-
[4]
InProceed- ings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216–12235
Dissecting recall of factual associa- tions in auto-regressive language models. InProceed- ings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216–12235. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others
2023
-
[5]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Albert Q. Jiang, Alexandre Sablayrolles, Arthur Men- sch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guil- laume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée L...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Mistral 7b.Preprint, arXiv:2310.06825. Nora Kassner and Hinrich Schütze
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Redirected, Not Removed: Task-Dependent Stereotyping Reveals the Limits of LLM Alignments
Redirected, not removed: Task- dependent stereotyping reveals the limits of LLM alignments.arXiv preprint arXiv:2604.02669. Jindong Li, Yali Fu, Li Fan, Jiahong Liu, Yao Shu, Chengwei Qin, Menglin Yang, Irwin King, and Rex Ying
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
R Thomas McCoy, Ellie Pavlick, and Tal Linzen
Implicit reasoning in large language models: A comprehensive survey.arXiv preprint arXiv:2509.02350. R Thomas McCoy, Ellie Pavlick, and Tal Linzen
-
[9]
Large language model align- ment: A survey.arXiv preprint arXiv:2309.15025. Ilia Sucholutsky, Lukas Muttenthaler, Adrian Weller, Andi Peng, Andreea Bobu, Been Kim, Bradley C Love, Erin Grant, Iris Groen, Jascha Achterberg, and 1 others
-
[10]
Getting aligned on representational alignment.arXiv preprint arXiv:2310.13018. Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, and 1 others
-
[11]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295. Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Steering Language Models With Activation Engineering
Steering language mod- els with activation engineering.arXiv preprint arXiv:2308.10248. 9 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson
Eras- ing concepts, steering generations: A comprehen- sive survey of concept suppression.arXiv preprint arXiv:2505.19398. Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson
-
[14]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Univer- sal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043. Appendices Appendix A describes the concept library used in our experiments. Appendix B presents representa- tive prompt templates and conditions. Appendix C reports additional descriptive statistics correspond- ing to the analyses discussed in the...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.