MaskClaw: Edge-Side Personalized Privacy Arbitration for GUI Agents with Behavior-Driven Skill Evolution
Pith reviewed 2026-06-29 11:34 UTC · model grok-4.3
The pith
MaskClaw performs Allow/Mask/Ask privacy decisions for GUI agent screenshots locally on the edge using visual evidence and policy memory retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
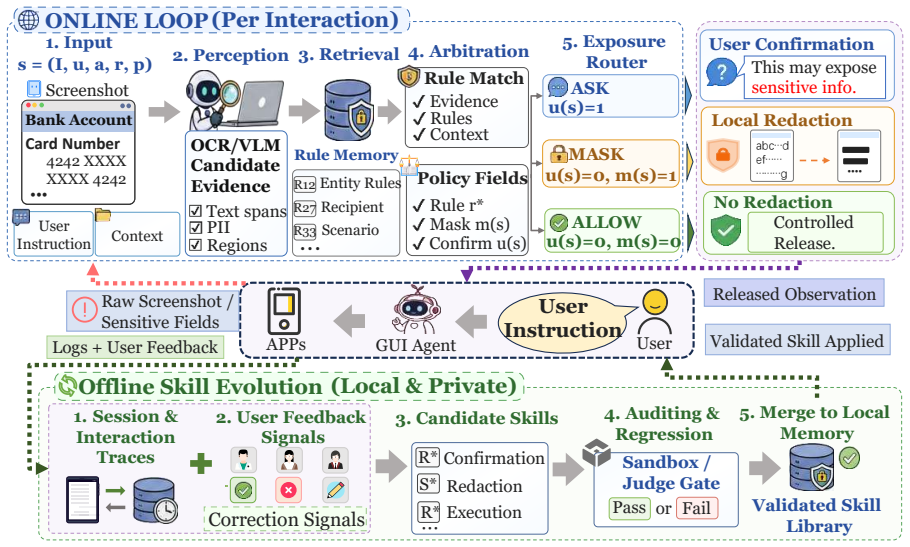
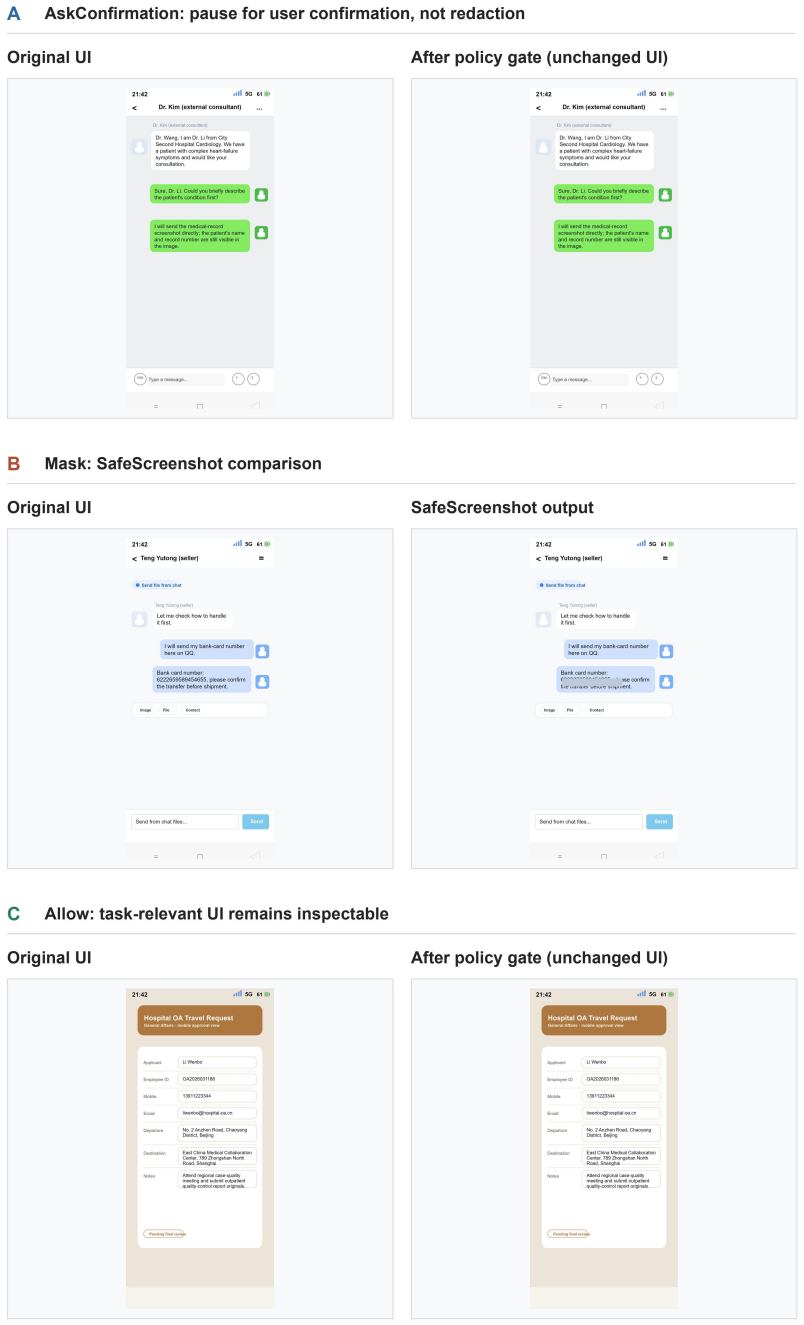
MaskClaw is an edge-side privacy arbitrator that extracts local visual evidence, retrieves user- and task-specific policy memory, and decides Allow, Mask, or Ask before raw screenshots leave a trusted user- or organization-controlled environment. It turns corrections, cancellations, and edits into reusable privacy skills checked by a sandbox gate in five designed skill-evolution scenarios and is evaluated on the P-GUI-Evo benchmark.
What carries the argument
MaskClaw arbitration pipeline that pairs local visual evidence extraction with policy memory retrieval to produce Allow/Mask/Ask decisions, plus behavior-driven skill evolution stored behind a sandbox gate.
If this is right
- Raw screenshots never leave the trusted environment before a privacy decision is reached.
- User corrections and edits are converted into stored, sandbox-checked privacy skills for later reuse.
- Pattern matching, cloud reasoning, and routing alone produce more over-confirmations, over-masking, or raw exposures under the same protocol.
- Decisions incorporate task, recipient, application state, and user role through retrieved policy memory.
Where Pith is reading between the lines
- The approach could be applied to non-GUI agent interfaces that also consume visual input.
- Evolved skills might be shared or versioned across users or organizations while remaining local.
Load-bearing premise
Local visual evidence plus retrieved policy memory is sufficient for accurate Allow/Mask/Ask decisions across applications and roles without cloud reasoning, and user corrections reliably produce reusable skills that generalize.
What would settle it
A new UI pattern or role outside the five scenarios and P-GUI-Evo benchmark where MaskClaw outputs an incorrect Allow, Mask, or Ask decision, or where a correction fails to produce a skill that applies to a later similar case.
Figures

read the original abstract
GUI agents rely on screenshots to infer intent and operate across applications, but these screenshots often contain private messages, medical records, payment credentials, and workplace-specific workflows. Privacy decisions in this setting depend on task, recipient, application state, and user role, yet static PII detectors miss these boundaries and cloud-side VLM reasoning can upload the raw screen before deciding what should be protected. We present MaskClaw, an edge-side privacy arbitrator for GUI agents. MaskClaw extracts local visual evidence, retrieves user- and task-specific policy memory, and decides Allow, Mask, or Ask before raw screenshots leave a trusted user- or organization-controlled environment. In five designed skill-evolution scenarios, it turns corrections, cancellations, and edits into reusable privacy skills checked by a sandbox gate. We introduce P-GUI-Evo, a benchmark built from real UI patterns, reconstructed HTML screens, and sanitized labels. Experiments show that pattern matching, cloud reasoning, and routing alone tend to over-confirm, over-mask, or expose raw screenshots under the same protocol. The artifact is available at https://github.com/Theodora-Y/MaskClaw.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MaskClaw, an edge-side privacy arbitrator for GUI agents. It extracts local visual evidence from screenshots, retrieves user- and task-specific policy memory, and outputs Allow/Mask/Ask decisions before raw screenshots leave a trusted environment. The system evolves reusable privacy skills from user corrections, cancellations, and edits via a sandbox gate. Evaluation occurs on five designed skill-evolution scenarios using the new P-GUI-Evo benchmark (real UI patterns, reconstructed HTML, sanitized labels). Experiments indicate that pattern matching, cloud reasoning, and routing baselines over-confirm, over-mask, or expose raw data under the same protocol.
Significance. If the local extraction and policy retrieval produce accurate decisions without cloud reasoning and if corrections yield generalizable skills, the work would address a practical gap in privacy for GUI agents by avoiding raw screenshot uploads. The P-GUI-Evo benchmark and the artifact release are constructive contributions for future evaluation in this area.
major comments (3)
- [Abstract] Abstract: The central claim that local visual evidence plus retrieved policy memory suffices for correct Allow/Mask/Ask decisions across applications and roles rests on unshown mechanisms; no description is given of how context-dependent factors (recipient, application state, user role) are captured locally or how policy completeness is ensured to avoid both over-masking and under-protection.
- [Abstract] Abstract: The claim that corrections produce reusable skills that generalize is load-bearing for the 'behavior-driven skill evolution' contribution, yet the evaluation is limited to five designed scenarios on P-GUI-Evo with no reported metrics on transfer to unseen UI patterns, sandbox-gate enforcement details, or failure cases.
- [Abstract] Abstract: No quantitative results (accuracy, false-positive rates, comparison tables, or protocol details) are provided, so it is impossible to verify that the system outperforms the criticized baselines or that the edge-side guarantee holds.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript to improve clarity on mechanisms, evaluation details, and quantitative results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that local visual evidence plus retrieved policy memory suffices for correct Allow/Mask/Ask decisions across applications and roles rests on unshown mechanisms; no description is given of how context-dependent factors (recipient, application state, user role) are captured locally or how policy completeness is ensured to avoid both over-masking and under-protection.
Authors: The full manuscript (Section 3) describes local extraction via UI element detection and OCR on screenshots to capture application state, while policy memory stores user-specific entries that encode roles, recipients, and task contexts. Completeness is maintained via the evolution loop from corrections. We agree the abstract is too concise and will expand it with a one-sentence summary of these mechanisms. revision: yes
-
Referee: [Abstract] Abstract: The claim that corrections produce reusable skills that generalize is load-bearing for the 'behavior-driven skill evolution' contribution, yet the evaluation is limited to five designed scenarios on P-GUI-Evo with no reported metrics on transfer to unseen UI patterns, sandbox-gate enforcement details, or failure cases.
Authors: The five scenarios test evolution under controlled conditions; the sandbox gate is described as a verification step prior to skill storage. We will add explicit details on gate enforcement and observed failure modes. Transfer metrics to unseen patterns are not currently reported and would require new experiments; we will either add preliminary results or note this as a limitation. revision: partial
-
Referee: [Abstract] Abstract: No quantitative results (accuracy, false-positive rates, comparison tables, or protocol details) are provided, so it is impossible to verify that the system outperforms the criticized baselines or that the edge-side guarantee holds.
Authors: The current text reports qualitative outcomes for the baselines under the shared protocol. We acknowledge the absence of numeric metrics and will insert accuracy, false-positive rates, comparison tables, and protocol details into the experiments section of the revision. revision: yes
Circularity Check
No significant circularity; system description and benchmark evaluation are self-contained.
full rationale
The paper describes an engineering system (MaskClaw) that performs local visual extraction, policy retrieval, and Allow/Mask/Ask decisions, then evaluates it on five designed skill-evolution scenarios using the introduced P-GUI-Evo benchmark. No equations, derivations, fitted parameters renamed as predictions, or self-referential definitions appear. Claims rest on empirical behavior in the provided scenarios and artifact rather than reducing to inputs by construction. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz. This is a standard non-circular system paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
CAPED: Context-Aware Privacy Exposure Defense for Mobile GUI Agents
CAPED reduces incidental visual privacy leakage in mobile GUI agents from 0.766 to 0.268 on seeded AndroidWorld tasks by selectively exposing only task-relevant screen content.
Reference graph
Works this paper leans on
-
[1]
Assessing Privacy Preservation and Utility in Online Vision-Language Models
Assessing Privacy Preservation and Util- ity in Online Vision-Language Models.Preprint, arXiv:2604.09695. Yining Chen, Jihao Zhao, Bo Tang, Haofen Wang, Yue Zhang, Fei Huang, Feiyu Xiong, and Zhiyu Li. 2026. MemPrivacy: Privacy-Preserving Personalized Mem- ory Management for Edge-Cloud Agents.Preprint, arXiv:2605.09530. Qingyan Guo, Rui Wang, Junliang Guo...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Privacy-Preserving Natural Language Process- ing. InProceedings of the 17th Conference of the European Chapter of the Association for Computa- tional Linguistics: Tutorial Abstracts, pages 27–30, Dubrovnik, Croatia. Association for Computational Linguistics. Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yu...
-
[3]
Autoglm: Autonomous foundation agents for guis
Curran Associates, Inc. Kevin Qinghong Lin, Siyuan Hu, Linjie Li, Zhengyuan Yang, Lijuan Wang, Philip Torr, and Mike Zheng Shou. 2025. Computer-Use Agents as Judges for Generative User Interface.arXiv preprint. Xiao Liu, Bo Qin, Dongzhu Liang, Guang Dong, Hanyu Lai, Hanchen Zhang, Hanlin Zhao, Iat Long Iong, Jiadai Sun, Jiaqi Wang, Junjie Gao, Jun- jun Sh...
-
[4]
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Jiadai Sun, Xinyue Yang, Yu Yang, Shuntian Yao, Wei Xu, Jie Tang, and Yuxiao Dong
MemGPT: Towards LLMs as Operating Sys- tems.arXiv preprint. Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Jiadai Sun, Xinyue Yang, Yu Yang, Shuntian Yao, Wei Xu, Jie Tang, and Yuxiao Dong. 2025. We- bRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning.Inter- national Conference on Learning Representations, 2...
2025
-
[5]
Mobile-Agent: Autonomous Multi-Modal Mo- bile Device Agent with Visual Perception.arXiv preprint. Shouju Wang, Fenglin Yu, Xirui Liu, Xiaoting Qin, Jue Zhang, Qingwei Lin, Dongmei Zhang, and Sara- van Rajmohan. 2025a. Privacy in Action: Towards Realistic Privacy Mitigation and Evaluation for LLM- Powered Agents.Preprint, arXiv:2509.17488. Shuai Wang, Weiw...
-
[6]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Large Language Models as Optimizers.In- ternational Conference on Learning Representations, 2024:12028–12068. Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chun- yuan Li, and Jianfeng Gao. 2023. Set-of-Mark Prompting Unleashes Extraordinary Visual Ground- ing in GPT-4V. https://arxiv.org/abs/2310.11441v2. Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Ferret-UI: Grounded mobile UI understanding with multimodal LLMs, 2024
MiniCPM-V: A GPT-4V Level MLLM on Your Phone.arXiv preprint. Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, and Zhe Gan. 2024. Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs.Preprint, arXiv:2404.05719. Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guest...
-
[8]
AppAgent: Multimodal Agents as Smartphone Users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25, pages 1–20, New York, NY , USA. Association for Computing Machinery. Jie Zhang, Xiangkui Cao, Zhouyu Han, Shiguang Shan, and Xilin Chen. 2026. Multi-PA: A Multi- perspective Benchmark on Privacy Assessment for Large Vis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.